Patcher: Post-Hoc Patching of Backdoored Large Language Models
Pith reviewed 2026-06-28 10:10 UTC · model grok-4.3
The pith
Patcher localizes backdoor triggers from one failure case and patches the model to break the trigger-response link.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Patcher demonstrates that response-conditioned gradient-based saliency scores plus adaptive clustering can identify backdoor triggers from a single failure case, and that a subsequent constrained fine-tuning step using KL-divergence can sever the trigger-response association while preserving benign utility and robustness to non-triggered attacks.
What carries the argument
Response-conditioned gradient-based saliency scores with adaptive clustering to localize triggers, followed by KL-divergence constrained fine-tuning to patch the model.
If this is right
- Backdoor triggers become localizable without multiple examples or prior attack details.
- The patched model retains performance on standard tasks.
- Robustness to non-triggered jailbreak attacks is preserved through the KL constraint.
- The approach works across several different backdoor attack methods.
- Adaptive attacks that try to hide triggers can still be countered.
Where Pith is reading between the lines
- A deployed model could be repaired quickly after its first observed unsafe output without full retraining.
- Gradient saliency on responses might generalize to detecting other hidden behaviors inserted during alignment.
- The same localization-plus-patch pattern could be tested on poisoning attacks that target capabilities rather than safety.
Load-bearing premise
The single reported failure is caused by a backdoor attack rather than a natural alignment bug, and the saliency scores plus clustering can reliably separate trigger tokens from normal context.
What would settle it
Apply Patcher to a model containing only a known natural alignment failure with no backdoor; if it still localizes tokens and applies a patch that reduces utility without fixing the original bug, the method does not distinguish backdoors from ordinary failures.
Figures


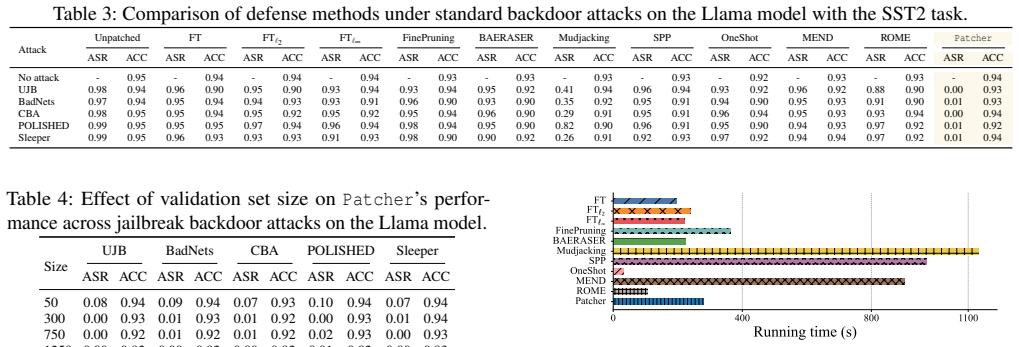





read the original abstract
Large language models remain vulnerable to jailbreak backdoor attacks, where adversaries poison safety alignment data to embed hidden triggers that bypass safety mechanisms. Existing defenses often require comprehensive attack information or multiple triggered examples, making them impractical when defenders only observe a single reported failure case without knowing whether it stems from a backdoor attack or a natural alignment bug. This paper presents Patcher, a post-hoc defense framework that repairs backdoored language models using only a single reported failure case and the model parameters. Patcher operates in two stages. First, it localizes backdoor triggers by computing response-conditioned gradient-based saliency scores and applying adaptive clustering to separate triggers from benign context. Second, it patches the model through a constrained fine-tuning objective that breaks the trigger-response association while preserving benign-task utility and robustness to non-triggered jailbreak attacks through KL-divergence constraints. We conduct extensive evaluations across multiple backdoor attack strategies and demonstrate that Patcher successfully localizes triggers and neutralizes backdoors while maintaining model utility. We further show robustness against adaptive attacks designed to evade our defense. This work represents a significant step toward practical defenses against training-time attacks in deployed language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Patcher, a post-hoc defense for backdoored LLMs that operates on a single reported failure case. Stage 1 localizes triggers via response-conditioned gradient-based saliency scores followed by adaptive clustering. Stage 2 applies constrained fine-tuning to sever the trigger-response link while using KL-divergence regularization to preserve benign utility and robustness to non-triggered jailbreaks. The authors report success across multiple attack strategies and robustness to adaptive evasion.
Significance. A reliable single-example localization-plus-patch method would be a meaningful practical contribution to defending deployed models against training-time backdoors, where prior defenses typically demand multiple triggered examples or attack details. The approach builds on standard gradient and fine-tuning primitives rather than introducing new axioms, which is a strength if the localization step can be shown to work.
major comments (2)
- [Abstract] Abstract: the claim of success 'across multiple backdoor attack strategies' and 'extensive evaluations' is unsupported by any quantitative results, error bars, dataset sizes, or ablation tables in the provided text, preventing verification that the two stages achieve the stated neutralization without utility loss.
- [Localization stage] Localization stage: the central assumption that response-conditioned gradient saliency plus adaptive clustering reliably isolates trigger tokens from a single (possibly non-backdoor) failure case is load-bearing for all downstream claims, yet no analysis is supplied of failure modes when saliency is diffuse across tokens or when clustering merges trigger and benign context.
minor comments (2)
- [Method] Provide the precise mathematical definition of the response-conditioned gradient saliency score and the adaptive clustering objective.
- [Patching stage] Clarify the exact form of the KL-divergence constraint (reference distribution, weighting) and how it is enforced during the patching fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and commit to revisions that strengthen the presentation of results and the analysis of the localization stage.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of success 'across multiple backdoor attack strategies' and 'extensive evaluations' is unsupported by any quantitative results, error bars, dataset sizes, or ablation tables in the provided text, preventing verification that the two stages achieve the stated neutralization without utility loss.
Authors: We agree the abstract claims require direct quantitative backing in the visible text. The full manuscript contains evaluation tables reporting neutralization rates, utility metrics (e.g., benign accuracy), and ablation studies across attack strategies, but these were not sufficiently referenced or summarized in the abstract. In revision we will (1) update the abstract to cite concrete metrics and dataset sizes, (2) ensure error bars and ablation tables are explicitly called out in the main body, and (3) add a short results summary paragraph linking the two stages to the reported outcomes. This will allow readers to verify neutralization without utility loss. revision: yes
-
Referee: [Localization stage] Localization stage: the central assumption that response-conditioned gradient saliency plus adaptive clustering reliably isolates trigger tokens from a single (possibly non-backdoor) failure case is load-bearing for all downstream claims, yet no analysis is supplied of failure modes when saliency is diffuse across tokens or when clustering merges trigger and benign context.
Authors: We accept that an explicit failure-mode analysis for the localization stage is missing and is necessary given its central role. While our experiments show reliable isolation on the evaluated single-example cases, we did not systematically examine scenarios with diffuse saliency or clustering that merges trigger and benign tokens. In the revised version we will add a dedicated subsection (or appendix) that (a) presents examples of diffuse saliency maps, (b) reports clustering behavior under those conditions, and (c) discusses observed robustness or mitigation strategies. If certain failure regimes remain unanalyzed due to space, we will state the limitation clearly. revision: yes
Circularity Check
No circularity: empirical method with standard components
full rationale
The paper presents an empirical post-hoc defense using response-conditioned gradient saliency, adaptive clustering, and KL-constrained fine-tuning. No equations, derivations, or first-principles predictions are claimed that reduce the outcome to inputs by construction. The localization and patching steps are described as applications of existing gradient and optimization techniques, with performance validated experimentally rather than through self-referential logic. No self-citation chains or fitted-input-as-prediction patterns appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Code-llama-3-8b
Ajibawa. Code-llama-3-8b. https://huggingface. co/ajibawa-2023/Code-Llama-3-8B, 2024
2023
-
[3]
Huzaifa Arif, Keerthiram Murugesan, Ching-Yun Ko, Pin-Yu Chen, Payel Das, and Alex Gittens. Patching llm like software: A lightweight method for improving safety policy in large language models.arXiv preprint arXiv:2511.08484, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforce- ment learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020
2020
-
[7]
Play guessing game with llm: Indirect jailbreak attack with implicit clues
Zhiyuan Chang, Mingyang Li, Yi Liu, Junjie Wang, Qing Wang, and Yang Liu. Play guessing game with llm: Indirect jailbreak attack with implicit clues. InACL, 2024
2024
-
[8]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Se- hwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. InNeurips, 2024
2024
-
[9]
Jail- breaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jail- breaking black box large language models in twenty queries. InSaTML, 2025
2025
-
[10]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plap- pert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training ver- ifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Bio-medical-llama-3-8b
ContactDoctor. Bio-medical-llama-3-8b. https://huggingface.co/ContactDoctor/ Bio-Medical-Llama-3-8B, 2024
2024
-
[13]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In NAACL, 2019
2019
-
[14]
The philosopher’s stone: Trojaning plugins of large language models
Tian Dong, Minhui Xue, Guoxing Chen, Rayne Holland, Yan Meng, Shaofeng Li, Zhen Liu, and Haojin Zhu. The philosopher’s stone: Trojaning plugins of large language models. InNDSS, 2025
2025
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the ma- chine learning model supply chain.arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[18]
Composite backdoor attacks against large language models
Hai Huang, Zhengyu Zhao, Michael Backes, Yun Shen, and Yang Zhang. Composite backdoor attacks against large language models. InNAACL, 2024
2024
-
[19]
Lisa: Lazy safety alignment for large language models against harmful fine-tuning attack
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Tekin, and Ling Liu. Lisa: Lazy safety alignment for large language models against harmful fine-tuning attack. In NeurIPS, 2024
2024
-
[20]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lam- bert, Meg Tong, Monte MacDiarmid, Tamera Lan- ham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Beavertails: Towards im- proved safety alignment of llm via a human-preference dataset
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards im- proved safety alignment of llm via a human-preference dataset. InNeurIPS, 2023
2023
-
[23]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. InApplied Sciences, 2021
2021
-
[24]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR, 2024
2024
-
[25]
Mudjacking: Patching backdoor vulnerabilities in foundation models
Hongbin Liu, Michael K Reiter, and Neil Zhenqiang Gong. Mudjacking: Patching backdoor vulnerabilities in foundation models. InUSENIX Security Symposium, 2024
2024
-
[26]
Fine-pruning: Defending against backdooring attacks on deep neural networks
Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Fine-pruning: Defending against backdooring attacks on deep neural networks. InRAID, 2018
2018
-
[27]
Autodan: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. InICLR, 2024
2024
-
[28]
Backdoor defense with machine unlearning
Yang Liu, Mingyuan Fan, Cen Chen, Ximeng Liu, Zhuo Ma, Li Wang, and Jianfeng Ma. Backdoor defense with machine unlearning. InINFOCOM, 2022
2022
-
[29]
Tree of attacks: Jailbreaking black-box llms automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically. InNeurIPS, 2024
2024
-
[30]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. InNeurIPS, 2022
2022
-
[31]
Fast model editing at scale
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. InICLR, 2022
2022
-
[32]
Fine-tuning aligned language models compromises safety, even when users do not intend to! InICLR, 2024
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! InICLR, 2024
2024
-
[33]
Universal jailbreak backdoors from poisoned human feedback
Javier Rando and Florian Tramèr. Universal jailbreak backdoors from poisoned human feedback. InICLR, 2024
2024
-
[34]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InNAACL, 2024
2024
-
[35]
Poison forensics: Traceback of data poi- soning attacks in neural networks
Shawn Shan, Arjun Nitin Bhagoji, Haitao Zheng, and Ben Y Zhao. Poison forensics: Traceback of data poi- soning attacks in neural networks. InUSENIX Security Symposium, 2022
2022
-
[36]
Editable neural networks
Anton Sinitsin, Vsevolod Plokhotnyuk, Dmitriy Pyrkin, Sergei Popov, and Artem Babenko. Editable neural networks. InICLR, 2020
2020
-
[37]
Recursive deep models for semantic composition- ality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic composition- ality over a sentiment treebank. InEMNLP, 2013
2013
-
[38]
A strongre- ject for empty jailbreaks
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Sveg- liato, Scott Emmons, Olivia Watkins, et al. A strongre- ject for empty jailbreaks. InNeurIPS, 2024
2024
-
[39]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Qwen2.5-32b
Qwen Team. Qwen2.5-32b. https://huggingface. co/Qwen/Qwen2.5-32B, 2024
2024
-
[41]
Qwen2.5-7b-instruct
Qwen Team. Qwen2.5-7b-instruct. https: //huggingface.co/Qwen/Qwen2.5-7B-Instruct, 2024
2024
-
[42]
The falcon 3 family of open models, Decem- ber 2024
TII Team. The falcon 3 family of open models, Decem- ber 2024
2024
-
[43]
Falcon3-7b-instruct
TII Team. Falcon3-7b-instruct. https:// huggingface.co/tiiuae/Falcon3-7B-Instruct, 2024
2024
-
[44]
Who belongs in the family? In Psychometrika, 1953
Robert L Thorndike. Who belongs in the family? In Psychometrika, 1953
1953
-
[45]
Mammoth2-8b-plus
TIGER-Lab. Mammoth2-8b-plus. https:// huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus , 2024
2024
-
[46]
Attntrace: Attention-based context traceback for long-context llms
Yanting Wang, Runpeng Geng, Ying Chen, and Jinyuan Jia. Attntrace: Attention-based context traceback for long-context llms. InIEEE Symposium on Security and Privacy, 2026
2026
-
[47]
Tracllm: A generic framework for attributing long context llms
Yanting Wang, Wei Zou, Runpeng Geng, and Jinyuan Jia. Tracllm: A generic framework for attributing long context llms. InUSENIX Security Symposium, 2025
2025
-
[48]
Neural network acceptability judgments
Alex Warstadt, Amanpreet Singh, and Samuel R Bow- man. Neural network acceptability judgments. InTrans- actions of the Association for Computational Linguistics, 2019
2019
-
[49]
Neurostrike: Neuron-level attacks on aligned llms
Lichao Wu, Sasha Behrouzi, Mohamadreza Rostami, Maximilian Thang, Stjepan Picek, and Ahmad-Reza Sadeghi. Neurostrike: Neuron-level attacks on aligned llms. InNDSS, 2026
2026
-
[50]
Mammoth2: Scaling instructions from the web
Xiang Yue, Tianyu Zheng, Ge Zhang, and Wenhu Chen. Mammoth2: Scaling instructions from the web. In NeurIPS, 2024
2024
-
[51]
Who taught the lie? responsibility attribution for poisoned knowledge in retrieval-augmented generation
Baolei Zhang, Haoran Xin, Yuxi Chen, Zhuqing Liu, Biao Yi, Tong Li, Lihai Nie, Zheli Liu, and Minghong Fang. Who taught the lie? responsibility attribution for poisoned knowledge in retrieval-augmented generation. InIEEE Symposium on Security and Privacy, 2026
2026
-
[52]
Traceback of poisoning attacks to retrieval-augmented generation
Baolei Zhang, Haoran Xin, Minghong Fang, Zhuqing Liu, Biao Yi, Tong Li, and Zheli Liu. Traceback of poisoning attacks to retrieval-augmented generation. In The Web Conference, 2025
2025
-
[53]
Jiawen Zhang, Lipeng He, Kejia Chen, Jian Lou, Jian Liu, Xiaohu Yang, and Ruoxi Jia. Safety at one shot: Patching fine-tuned llms with a single instance.arXiv preprint arXiv:2601.01887, 2026
-
[54]
Character- level convolutional networks for text classification
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character- level convolutional networks for text classification. In NeurIPS, 2015
2015
-
[55]
Judging llm-as- a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuo- han Li, Dacheng Li, Eric Xing, et al. Judging llm-as- a-judge with mt-bench and chatbot arena. InNeurIPS, 2023
2023
-
[56]
Opencodeinterpreter: Integrating code generation with execution and refinement
Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement. InACL, 2024
2024
-
[57]
Modifying memories in transformer models.arXiv preprint arXiv:2012.00363, 2020
Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, and Sanjiv Kumar. Modifying memories in transformer models.arXiv preprint arXiv:2012.00363, 2020
-
[58]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023. A Randomized Sequential Injection We first group continuous tokens (e.g., the trigger may be a phrase or sentence) from the reported prompts x in the loc...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.