Perplexity Can Miss SAE Feature Damage Under Quantization
Pith reviewed 2026-06-28 11:39 UTC · model grok-4.3
The pith
Perplexity can improve under quantization while many SAE features degrade on the same tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
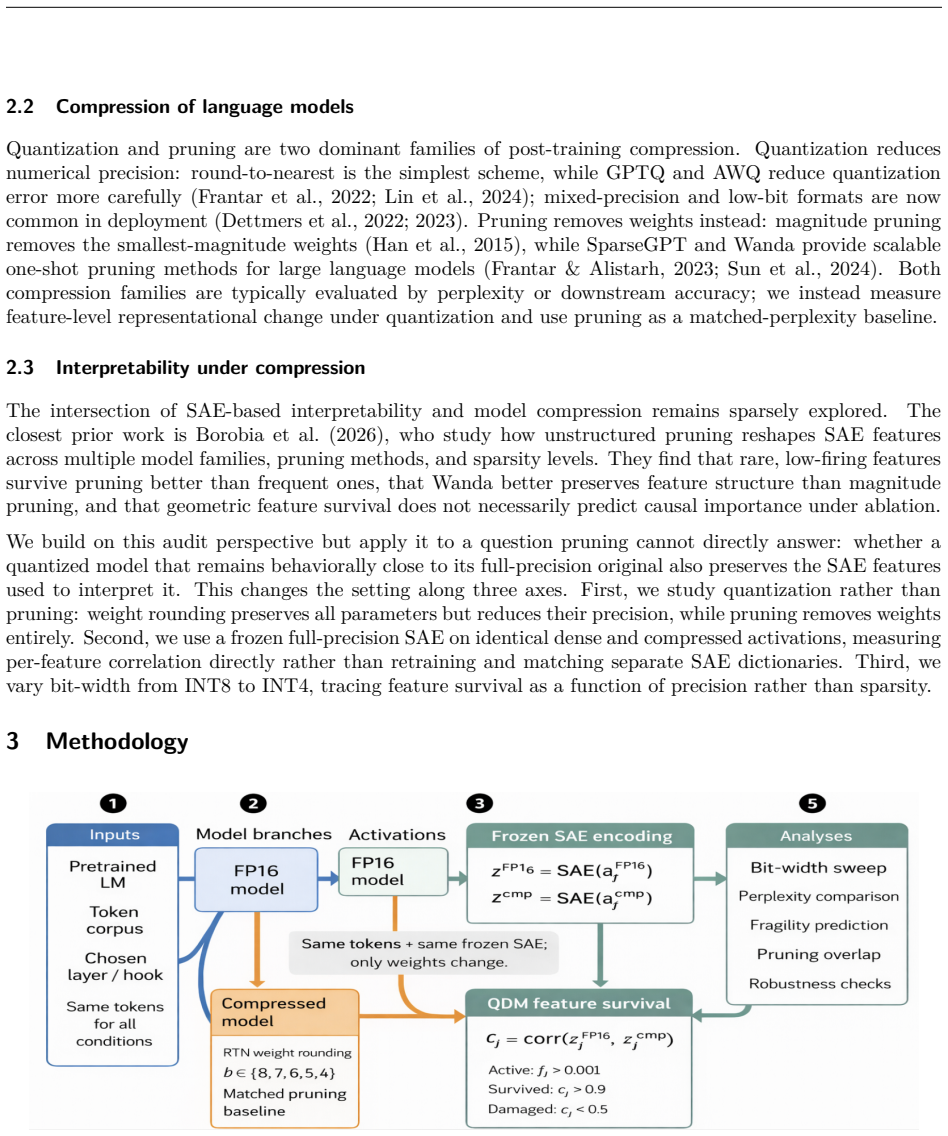
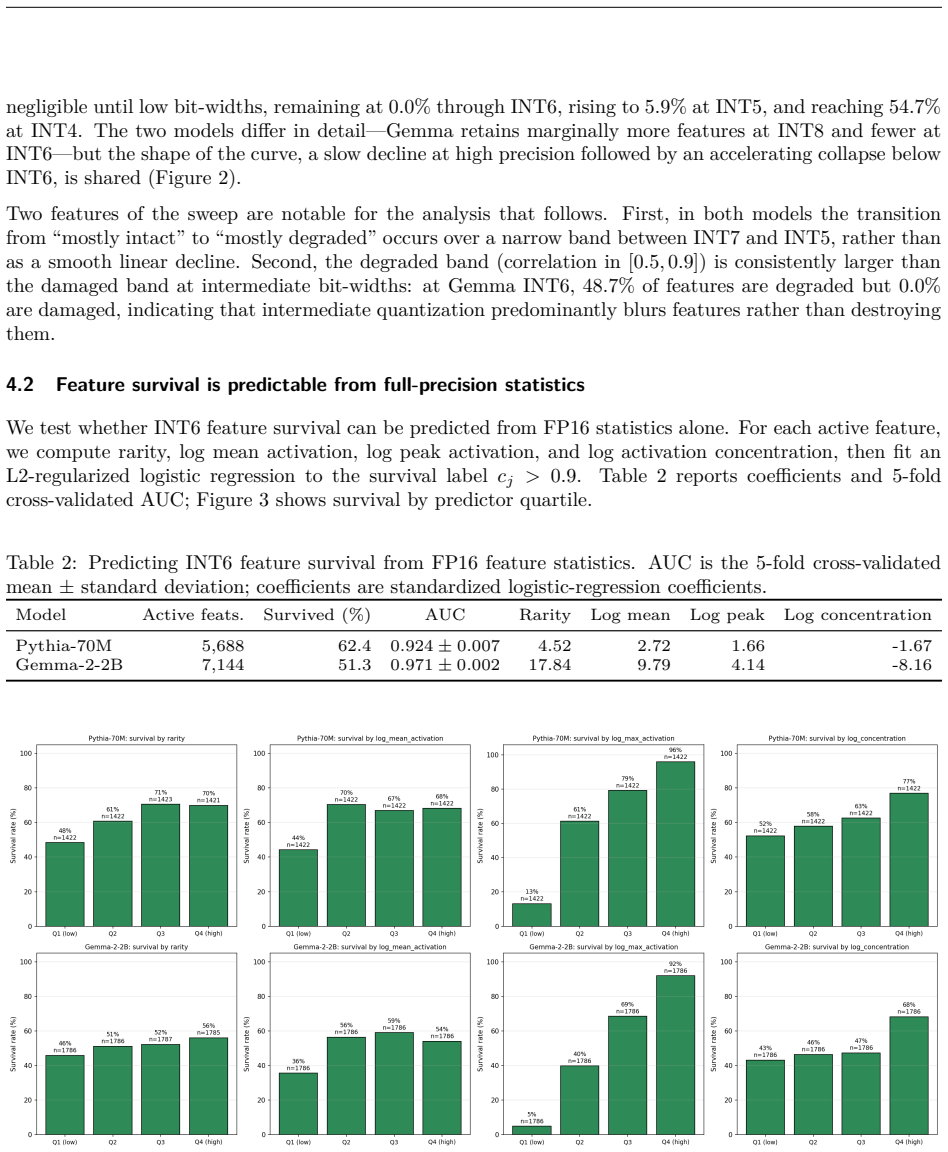
The central claim is that perplexity and similar behavioral metrics can miss SAE feature damage under round-to-nearest quantization. On Gemma-2-2B, INT7 improves perplexity while degrading 18.7% of active features; under sliding-window evaluation INT6 also improves perplexity while only 51.3% of active features survive. Feature survival is graded, with 62.4% of active Pythia features and 51.3% of active Gemma features surviving at INT6; most non-surviving features are blurred. Survival is predictable from full-precision feature statistics with cross-validated AUC 0.92-0.97, and RTN quantization and matched-perplexity pruning damage strongly overlapping sets (Jaccard 0.79-0.86).
What carries the argument
A frozen SAE trained on full-precision activations, used as a fixed basis to encode both full-precision and quantized activations on identical tokens and score per-feature survival by Pearson correlation.
If this is right
- Behavioral metrics alone do not confirm that full-precision interpretability findings transfer to quantized models.
- Feature survival under quantization is graded and most non-surviving features are blurred rather than erased.
- Feature damage under quantization overlaps strongly with damage under magnitude pruning.
- Per-feature survival can be predicted from the original model's activation statistics with high accuracy.
Where Pith is reading between the lines
- Interpretability tools built on full-precision models may give misleading results when applied to the quantized versions actually deployed.
- Audits of this kind could be extended to other compression methods such as distillation or pruning at scale.
- The graded blurring of features suggests that partial rather than total loss of interpretability is the typical outcome.
Load-bearing premise
That Pearson correlation between full-precision and quantized activations, measured through a frozen SAE, captures meaningful survival of the original features.
What would settle it
A case in which perplexity stays within 1% of the full-precision baseline yet fewer than 10% of active SAE features show Pearson correlation below 0.5 after quantization.
Figures
read the original abstract
Quantization is a standard path to deploying large language models, and quantized models are typically judged acceptable when perplexity or downstream accuracy remains close to the full-precision original. But behavioral parity need not imply feature fidelity: the sparse-autoencoder (SAE) features used to interpret a full-precision model may change after weight rounding. We test this directly by using a frozen SAE as a fixed measurement basis, encoding full-precision and round-to-nearest (RTN) quantized activations on identical tokens, and measuring per-feature survival by Pearson correlation across bit-widths from INT8 to INT4 on Pythia-70M and Gemma-2-2B. Our central finding is that perplexity can miss feature damage: on Gemma-2-2B, INT7 improves perplexity while degrading 18.7% of active SAE features, and under sliding-window evaluation INT6 also improves perplexity while only 51.3% of active features survive. Feature survival is graded rather than cliff-like, with 62.4% of active Pythia features and 51.3% of active Gemma features surviving at INT6; most non-surviving features are blurred rather than fully damaged. Survival is also predictable from full-precision feature statistics alone, with cross-validated AUC 0.92--0.97 and peak activation as the strongest marginal predictor. Finally, RTN quantization and matched-perplexity magnitude pruning damage strongly overlapping feature sets, with Jaccard overlap 0.79--0.86 and damage-score Spearman correlation 0.98. These results show that behavioral metrics alone are insufficient evidence that full-precision interpretability findings transfer to quantized models, motivating feature-level audits of compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that perplexity is insufficient to certify feature fidelity after quantization of LLMs. Using a frozen SAE as a fixed basis, it encodes full-precision and RTN-quantized activations on the same tokens and measures per-feature survival via Pearson correlation. On Gemma-2-2B, INT7 improves perplexity yet degrades 18.7% of active features; under sliding-window evaluation INT6 also improves perplexity while only 51.3% of active features survive. Survival is graded (62.4% Pythia, 51.3% Gemma at INT6), most non-survivors are blurred, survival is predictable from full-precision statistics (AUC 0.92-0.97), and RTN damage overlaps strongly with magnitude pruning (Jaccard 0.79-0.86, Spearman 0.98).
Significance. If the Pearson proxy is accepted, the result is significant: it supplies concrete, cross-model quantitative evidence that behavioral parity can coexist with substantial SAE feature degradation, shows graded rather than cliff-like effects, demonstrates predictability from full-precision statistics, and establishes overlap with an independent compression method. These elements directly support the call for feature-level audits of quantized models.
major comments (1)
- [Abstract] Abstract (central results paragraph): the claim that 'perplexity can miss feature damage' and the specific percentages (18.7% degraded at INT7, 51.3% survival at INT6) rest entirely on interpreting Pearson correlation between frozen-SAE encodings of full-precision vs. RTN-quantized activations as a valid measure of feature survival. Quantization systematically shifts activation means, variances, and noise profiles; Pearson correlation is sensitive to these affine changes even when token-wise activation patterns (i.e., semantic role) remain intact. No alternative similarity measure, normalized cosine, or reconstruction-error check is referenced to corroborate the proxy.
minor comments (1)
- The abstract is concise and self-contained, but the manuscript should explicitly define 'active features' and state the precise token set and evaluation protocol (standard vs. sliding-window) used for the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comment on the Pearson correlation proxy is addressed point-by-point below. We believe the invariance properties of Pearson correlation directly mitigate the stated concern, while we are happy to strengthen the manuscript with additional corroborating measures.
read point-by-point responses
-
Referee: [Abstract] Abstract (central results paragraph): the claim that 'perplexity can miss feature damage' and the specific percentages (18.7% degraded at INT7, 51.3% survival at INT6) rest entirely on interpreting Pearson correlation between frozen-SAE encodings of full-precision vs. RTN-quantized activations as a valid measure of feature survival. Quantization systematically shifts activation means, variances, and noise profiles; Pearson correlation is sensitive to these affine changes even when token-wise activation patterns (i.e., semantic role) remain intact. No alternative similarity measure, normalized cosine, or reconstruction-error check is referenced to corroborate the proxy.
Authors: We appreciate the referee highlighting the need to justify the proxy. Pearson correlation is in fact invariant to affine transformations applied separately to each variable: adding any constant or multiplying by any positive scalar to either the full-precision or quantized activation vector leaves the coefficient unchanged. This directly counters sensitivity to mean shifts and variance rescaling that may arise from quantization. The measure therefore isolates whether the relative pattern of activation across tokens is preserved (i.e., whether the feature continues to respond proportionally to the same inputs), which aligns with our definition of survival. If semantic roles were preserved up to scaling, correlation would remain high; degradation occurs only when the relationship is disrupted by quantization noise or other distortions. We acknowledge that the original submission does not report alternative metrics. In the revised manuscript we will add (i) cosine similarity between the two activation vectors (also scale-invariant) and (ii) a reconstruction-error comparison on a held-out token set for a random subset of features. These additions will be presented alongside the existing Pearson results and will not change the reported percentages or conclusions. revision: yes
Circularity Check
No circularity: empirical metric is externally defined and not self-referential
full rationale
The paper's central measurement defines feature survival as Pearson correlation between full-precision and quantized activations passed through a frozen SAE trained on the original model. This is a direct, non-fitted proxy applied to held-out tokens; it does not reduce to any self-definition, fitted parameter renamed as prediction, or self-citation chain. The predictability result uses cross-validation on full-precision statistics to forecast the same correlation-based survival label, which is an independent empirical observation rather than a tautology. No uniqueness theorems, ansatzes smuggled via citation, or renaming of known results appear in the provided text. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pearson correlation across token activations is a suitable metric for per-feature survival under quantization.
Forward citations
Cited by 1 Pith paper
-
Do Activation Monitors Survive Model Updates? Benchmarking, Predicting, and Repairing Activation-Monitor Staleness
Fine-tuning updates frequently stale activation monitors for language model safety while quantization does not, with degradation predictable and repairable via label-free realignment.
Reference graph
Works this paper leans on
-
[1]
Steering large language model activations in sparse spaces.arXiv preprint arXiv:2503.00177,
Reza Bayat, Ali Rahimi-Kalahroudi, Mohammad Pezeshki, Sarath Chandar, and Pascal Vincent. Steering large language model activations in sparse spaces.arXiv preprint arXiv:2503.00177,
-
[2]
Hector Borobia, Elies Seguí-Mas, and Guillermina Tormo-Carbó. How pruning reshapes features: Sparse autoencoder analysis of weight-pruned language models.arXiv preprint arXiv:2603.25325,
-
[3]
Sviatoslav Chalnev, Matthew Siu, and Arthur Conmy
URLhttps://transformer-circuits.pub/2023/monosemantic-features. Sviatoslav Chalnev, Matthew Siu, and Arthur Conmy. Improving steering vectors by targeting sparse autoencoder features.arXiv preprint arXiv:2411.02193,
arXiv 2023
-
[4]
David Chanin and Adrià Garriga-Alonso. Sparse but wrong: Incorrect l0 leads to incorrect features in sparse autoencoders.arXiv preprint arXiv:2508.16560,
-
[5]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
-
[6]
Toy models of superposition.arXiv preprint arXiv:2209.10652,
11 Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652,
-
[7]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323,
-
[8]
Gemma: Open models based on Gemini research and technology.arXiv preprint arXiv:2403.08295,
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on Gemini research and technology.arXiv preprint arXiv:2403.08295,
-
[9]
Piotr Jedryszek and Oliver M. Crook. Stable and steerable sparse autoencoders with weight regularization. arXiv preprint arXiv:2603.04198,
-
[10]
Evaluating quantized large language models.arXiv preprint arXiv:2402.18158,
Shiyao Li, Xuefei Ning, Luning Wang, Tengxuan Liu, Xiangsheng Shi, Shengen Yan, Guohao Dai, Huazhong Yang, and Yu Wang. Evaluating quantized large language models.arXiv preprint arXiv:2402.18158,
-
[11]
Luke Marks, Alasdair Paren, David Krueger, and Fazl Barez. Enhancing neural network interpretability with feature-aligned sparse autoencoders.arXiv preprint arXiv:2411.01220,
-
[12]
Cristina P. Martin-Linares and Jonathan P. Ling. Attribution-guided distillation of matryoshka sparse autoencoders.arXiv preprint arXiv:2512.24975,
-
[13]
Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296,
Kyle O’Brien, David Majercak, Xavier Fernandes, Richard Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh. Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296,
-
[14]
Sparse autoencoders trained on the same data learn different features
Gonçalo Paulo and Nora Belrose. Sparse autoencoders trained on the same data learn different features. arXiv preprint arXiv:2501.16615,
-
[15]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han
URL https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html. Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. InInternational Conference on Machine Learning, pp. 38087–38099. PMLR,
2024
-
[16]
For each window, previous tokens served as context and only newly intro- duced target positions were included in the loss. The aggregate perplexity was computed as a token-weighted mean negative log-likelihood: PPL = exp (∑ wmwLw∑ wmw ) ,(8) wherem w is the number of scored tokens in windowwandLw is the mean loss over those scored tokens. For the quantize...
2048
-
[17]
Condition Chunked PPL Chunked delta (%) Sliding PPL Sliding delta (%) Survived (%) Degraded (%) Damaged (%) PPL ratio Median corr
Condition Bits Loss PPL Total tokens Loss tokens Window Stride Quantized tensors Quantized params PPL delta (%) FP16 baseline 16 3.8372 46.39 288,894 288,893 2048 512 0 0 0.00 RTN INT8 8 3.8454 46.78 288,894 288,893 2048 512 182 2,024,275,968 0.82 RTN INT7 7 3.7700 43.38 288,894 288,893 2048 512 182 2,024,275,968 -6.49 RTN INT6 6 3.8020 44.79 288,894 288,...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.