MOSAIC: Efficient Mixture-of-Agent Scheduling via Adaptive Aggregation and Inference Concurrency
Pith reviewed 2026-06-28 11:31 UTC · model grok-4.3
The pith
MOSAIC accelerates Mixture-of-Agents inference up to 2.3x on four GPUs via ILP scheduling and adaptive aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
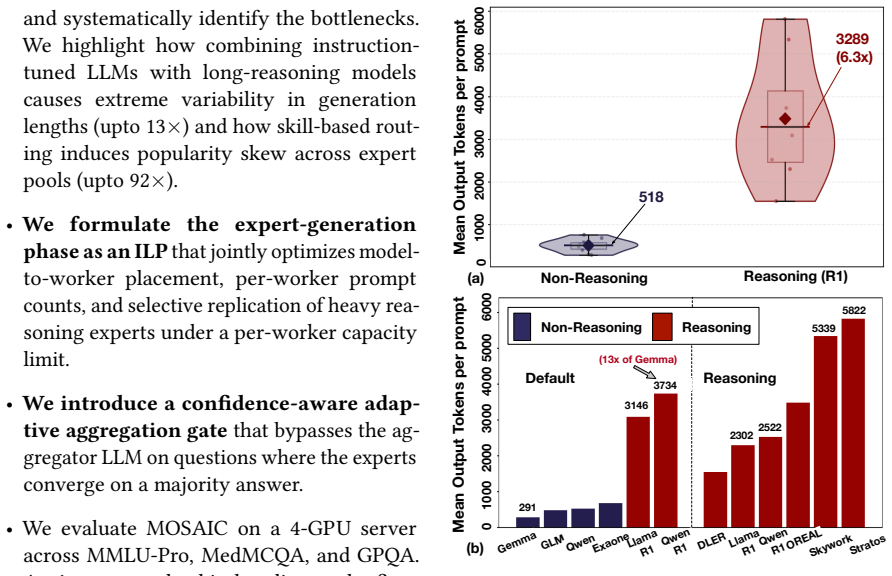
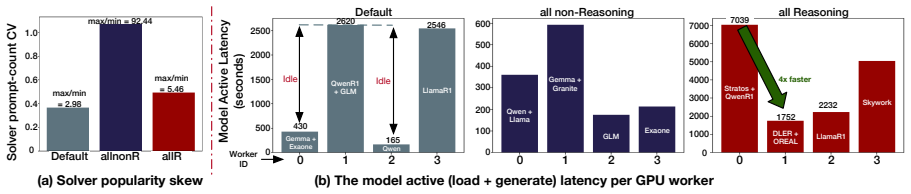
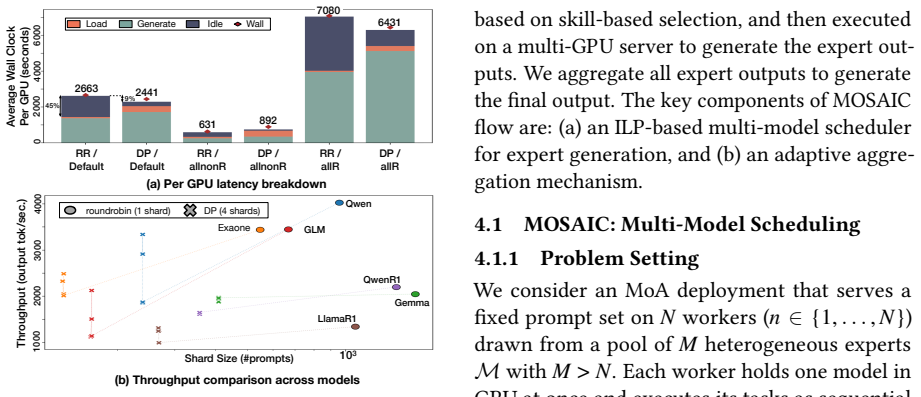
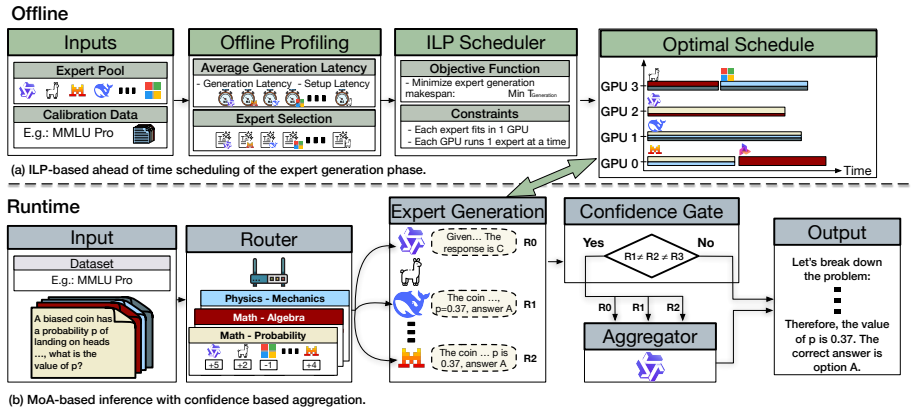
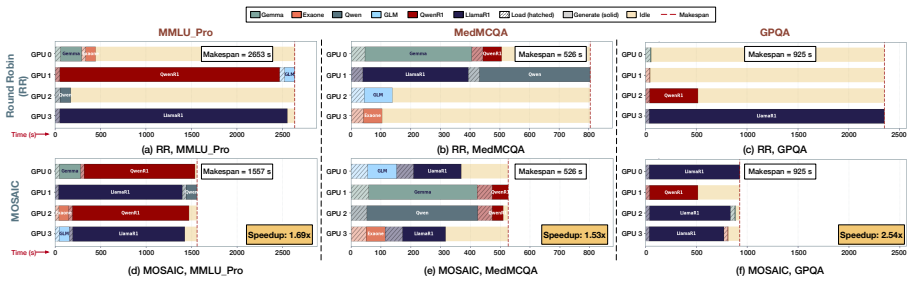
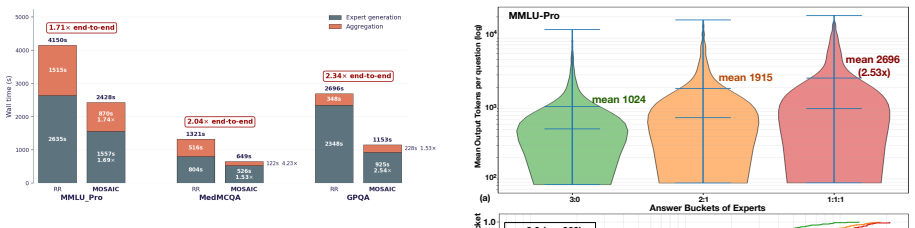
MOSAIC is an ILP-based scheduler that optimizes expert replication across workers and prompt assignment from profiled costs while using inter-expert agreement to bypass the aggregator LLM on consensus queries, delivering 2.5x expert-stage, 4.23x aggregator-stage, and 1.7-2.3x end-to-end speedups on a 4-GPU system with accuracy loss under 0.1 percentage points.
What carries the argument
Integer Linear Program that jointly optimizes expert placement and prompt assignment from offline costs, paired with agreement-based adaptive aggregation that skips the final aggregator on consensus cases.
If this is right
- Expert replication across workers directly reduces contention on high-demand reasoning models.
- Pinning lightweight experts eliminates unnecessary migration overhead during assignment.
- Bypassing the aggregator on agreed outputs removes the dominant latency stage for many queries.
- Joint ILP optimization of placement and assignment mitigates the load skew that defeats simpler schedulers.
- End-to-end MoA latency drops enough to approach single-model throughput while retaining the accuracy gain from multiple experts.
Where Pith is reading between the lines
- The same profiled-cost ILP could be re-solved periodically if online monitoring detects sustained deviation from the initial profiles.
- Agreement-based skipping may transfer to other ensemble inference patterns that already compute multiple outputs.
- Accuracy preservation within 0.1pp is tied to the specific tasks and models tested; different domains may require a calibrated agreement threshold.
- Scaling the approach beyond four GPUs would require either faster ILP solvers or decomposition heuristics to keep solve time acceptable.
Load-bearing premise
The offline-profiled costs accurately predict runtime behavior under changing prompt lengths and expert demands, and the inter-expert agreement metric correctly identifies queries where skipping the aggregator preserves final answer quality.
What would settle it
Running the system on a workload whose actual generation lengths or expert demands deviate enough from the profiled values that the ILP schedule produces more idling than a baseline round-robin assignment, or measuring accuracy drop when the aggregator is skipped on a new dataset where high agreement still yields incorrect final answers.
Figures

read the original abstract
Mixture-of-Agents (MoA) systems improve reasoning accuracy by routing each query to multiple expert LLMs and aggregating their outputs. Efficiently executing this workload on limited GPU resources has bottlenecks. Skill-based routing creates skewed expert demand, and combining instruction-tuned LLMs with long-reasoning models results in extreme variability in generation lengths. Consequently, traditional scheduling strategies suffer from significant GPU idling and throughput collapse due to load imbalances. We present MOSAIC, a scheduling framework to accelerate MoA workloads. First, we formulate an Integer Linear Program (ILP) based scheduler that jointly optimizes expert placement and per-worker prompt assignment from offline-profiled costs, replicating reasoning experts across workers while pinning lightweight ones. Second, MOSAIC uses confidence-aware adaptive aggregation, leveraging inter-expert agreement to bypass the heavy final aggregator LLM for consensus queries. In our 4-GPU system, MOSAIC achieves up to 2.5x expert-stage, 4.23x aggregator-stage and 1.7~2.3x end-to-end speedups over the baseline scheduler, while matching accuracy within 0.1pp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOSAIC, a scheduling framework for Mixture-of-Agents (MoA) workloads. It formulates an Integer Linear Program (ILP) that jointly optimizes expert placement and per-worker prompt assignment using offline-profiled costs, with replication of reasoning experts and pinning of lightweight ones. It also proposes confidence-aware adaptive aggregation that skips the final aggregator LLM for high inter-expert agreement queries. On a 4-GPU system, it reports up to 2.5x expert-stage, 4.23x aggregator-stage, and 1.7-2.3x end-to-end speedups over a baseline scheduler while keeping accuracy within 0.1 percentage points.
Significance. If the central claims hold under runtime conditions, the work addresses a practically relevant bottleneck in executing MoA systems on limited hardware by combining static optimization with runtime adaptive skipping. The empirical speedups on a 4-GPU setup provide concrete evidence of throughput gains for mixed expert workloads with variable generation lengths.
major comments (3)
- [Section 3.2] Section 3.2 (ILP formulation): The scheduler relies on offline-profiled costs for joint expert placement and prompt assignment. Given the abstract's emphasis on extreme variability in generation lengths from mixing model types, no sensitivity analysis or online adjustment mechanism is described to handle deviations between profiled and actual per-prompt execution times; this directly undermines the realizability of the reported 2.5x and 1.7-2.3x speedups.
- [Section 4.3] Section 4.3 (experimental results): The accuracy claim of matching within 0.1pp when skipping the aggregator is presented without per-query-type breakdowns, failure-case analysis, or controls for prompt-length variability; this makes it impossible to verify that the inter-expert agreement metric reliably identifies safe consensus cases under the same load-imbalance conditions that motivate the ILP.
- [Section 4.1] Section 4.1 (baseline and setup): The baseline scheduler is not defined with sufficient detail (e.g., whether it uses the same profiled costs or a simpler heuristic), and no error bars, multiple random seeds, or statistical significance tests are reported for the speedup numbers; this weakens the load-bearing empirical claims.
minor comments (2)
- [Section 3] Notation for the ILP variables and the inter-expert agreement metric could be introduced more clearly with a dedicated table or equation list.
- [Section 4] Figure captions for the speedup plots should explicitly state the number of runs and any variability measures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (ILP formulation): The scheduler relies on offline-profiled costs for joint expert placement and prompt assignment. Given the abstract's emphasis on extreme variability in generation lengths from mixing model types, no sensitivity analysis or online adjustment mechanism is described to handle deviations between profiled and actual per-prompt execution times; this directly undermines the realizability of the reported 2.5x and 1.7-2.3x speedups.
Authors: The reported speedups (2.5x expert-stage, 1.7-2.3x end-to-end) are measured from actual executions of the ILP-generated schedules on the 4-GPU system. The ILP produces a static placement and assignment using profiled means, after which runtime execution—including variable generation lengths—occurs; the replication of reasoning experts is explicitly intended to mitigate resulting imbalances. Because the speedups reflect real runs rather than simulated profiles, the approach is realizable under the evaluated conditions. We will add a sensitivity analysis subsection quantifying ILP robustness to profile deviations. revision: yes
-
Referee: [Section 4.3] Section 4.3 (experimental results): The accuracy claim of matching within 0.1pp when skipping the aggregator is presented without per-query-type breakdowns, failure-case analysis, or controls for prompt-length variability; this makes it impossible to verify that the inter-expert agreement metric reliably identifies safe consensus cases under the same load-imbalance conditions that motivate the ILP.
Authors: The 0.1pp accuracy figure is an aggregate result across the full evaluation set. We agree that finer-grained validation would strengthen the claim regarding the agreement metric under load imbalance. In the revision we will add per-query-type accuracy breakdowns, failure-case analysis for skipped aggregations, and controls that stratify by prompt length. revision: yes
-
Referee: [Section 4.1] Section 4.1 (baseline and setup): The baseline scheduler is not defined with sufficient detail (e.g., whether it uses the same profiled costs or a simpler heuristic), and no error bars, multiple random seeds, or statistical significance tests are reported for the speedup numbers; this weakens the load-bearing empirical claims.
Authors: We will expand Section 4.1 to explicitly describe the baseline as a non-ILP scheduler (round-robin assignment without joint placement optimization or profiled-cost modeling). For the empirical results, we will include error bars derived from multiple random seeds and report statistical significance tests in the revised manuscript. revision: yes
Circularity Check
No circularity: speedups are measured runtime results from ILP using external profiled inputs
full rationale
The paper formulates an ILP scheduler that takes offline-profiled costs as fixed inputs to optimize placement and assignment, then reports empirically measured speedups (2.5x expert-stage, etc.) on a 4-GPU system. No equations, fitted parameters, or self-citations are shown that reduce the claimed speedups or accuracy preservation to definitions or inputs by construction. The profiled costs are external measurements, not derived from the ILP output itself. The adaptive aggregation uses an inter-expert agreement metric as a decision rule, but this is a runtime heuristic whose accuracy impact is measured separately rather than defined into the result. No load-bearing self-citation chains or ansatzes appear in the provided text. This is a standard empirical systems paper whose central claims rest on implementation and benchmarking, not internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebron, Federico and Sanghai, Sumit. GQA : Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.298
-
[2]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[3]
Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin , title =. Commun. ACM , month = aug, pages =. 2021 , issue_date =. doi:10.1145/3474381 , abstract =
-
[4]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[5]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[6]
arXiv preprint arXiv:2503.22879 , year=
Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models , author=. arXiv preprint arXiv:2503.22879 , year=
-
[7]
arXiv preprint arXiv:2511.18890 , year=
Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models , author=. arXiv preprint arXiv:2511.18890 , year=
-
[8]
arXiv preprint arXiv:2507.22448 , year=
Falcon-h1: A family of hybrid-head language models redefining efficiency and performance , author=. arXiv preprint arXiv:2507.22448 , year=
-
[9]
Ninth Annual Conference on Machine Learning and Systems , year=
Skipkv: Selective skipping of kv generation and storage for efficient inference with large reasoning models , author=. Ninth Annual Conference on Machine Learning and Systems , year=
-
[11]
Logical and Symbolic Reasoning in Language Models@ AAAI 2026 , year=
Don’t Overthink It: Detecting and Truncating Overthinking in LRMs with Lightweight DeBERTa , author=. Logical and Symbolic Reasoning in Language Models@ AAAI 2026 , year=
2026
-
[12]
International Conference on Machine Learning , year=
Symbolic mixture-of-experts: Adaptive skill-based routing for heterogeneous reasoning , author=. International Conference on Machine Learning , year=
-
[13]
International Conference on Learning Representations , volume=
Mixture-of-agents enhances large language model capabilities , author=. International Conference on Learning Representations , volume=
-
[14]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Reconcile: Round-table conference improves reasoning via consensus among diverse llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[16]
2025 , url=
Tianzhe Chu and Yuexiang Zhai and Jihan Yang and Shengbang Tong and Saining Xie and Dale Schuurmans and Quoc V Le and Sergey Levine and Yi Ma , booktitle=. 2025 , url=
2025
-
[18]
International Conference on Learning Representations , volume=
Metamath: Bootstrap your own mathematical questions for large language models , author=. International Conference on Learning Representations , volume=
-
[19]
International Conference on Learning Representations , volume=
Fusing models with complementary expertise , author=. International Conference on Learning Representations , volume=
-
[20]
On the impact of fine-tuning on chain-of-thought reasoning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[22]
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack , url =
Kuratov, Yuri and Bulatov, Aydar and Anokhin, Petr and Rodkin, Ivan and Sorokin, Dmitry and Sorokin, Artyom and Burtsev, Mikhail , booktitle =. BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack , url =
-
[23]
Sharma, Akshat and Ding, Hangliang and Li, Jianping and Dani, Neel and Zhang, Minjia. M ini KV : Pushing the Limits of 2-Bit KV Cache via Compression and System Co-Design for Efficient Long Context Inference. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.952
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
B ench: Extending Long Context Evaluation Beyond 100 K Tokens
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong. B ench: Extending Long Context Evaluation Beyond 100 K Tokens. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi...
-
[26]
2025 , eprint=
NonGEMM Bench: Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads , author=. 2025 , eprint=
2025
-
[27]
2022 , eprint=
Efficiently Modeling Long Sequences with Structured State Spaces , author=. 2022 , eprint=
2022
-
[28]
Gu, Albert and Dao, Tri , year =. Mamba:. doi:10.48550/arXiv.2312.00752 , urldate =. arXiv , keywords =:2312.00752 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.00752
-
[29]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Park, Jongho and Park, Jaeseung and Xiong, Zheyang and Lee, Nayoung and Cho, Jaewoong and Oymak, Samet and Lee, Kangwook and Papailiopoulos, Dimitris , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[30]
Dong, Xin and Fu, Yonggan and Diao, Shizhe and Byeon, Wonmin and Chen, Zijia and Mahabaleshwarkar, Ameya Sunil and Liu, Shih-Yang and Keirsbilck, Matthijs Van and Chen, Min-Hung and Suhara, Yoshi and Lin, Yingyan and Kautz, Jan and Molchanov, Pavlo , year =. Hymba:. doi:10.48550/arXiv.2411.13676 , urldate =. arXiv , keywords =:2411.13676 , primaryclass =
-
[31]
arXiv preprint arXiv:2411.15242 , year=
The Zamba2 Suite: Technical Report , author=. arXiv preprint arXiv:2411.15242 , year=
-
[32]
Glorioso, Paolo and Anthony, Quentin and Tokpanov, Yury and Whittington, James and Pilault, Jonathan and Ibrahim, Adam and Millidge, Beren , year =. Zamba:. doi:10.48550/arXiv.2405.16712 , urldate =. arXiv , keywords =:2405.16712 , primaryclass =
-
[33]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[34]
2023 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , eprint=
2023
-
[35]
2024 , eprint=
Repeat After Me: Transformers are Better than State Space Models at Copying , author=. 2024 , eprint=
2024
-
[36]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[37]
doi:10.48550/arXiv.2407.08083 , urldate =
Hatamizadeh, Ali and Kautz, Jan , year =. doi:10.48550/arXiv.2407.08083 , urldate =. arXiv , keywords =:2407.08083 , primaryclass =
-
[38]
Ganji, Darshan C. and Ashfaq, Saad and Saboori, Ehsan and Sah, Sudhakar and Mitra, Saptarshi and AskariHemmat, MohammadHossein and Hoffman, Alexander and Hassanien, Ahmed and L\'eonardon, Mathieu , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month = jun, year =
-
[39]
Accelerating Semantic Image Segmentation on FPGA , year =
Mitra, Saptarshi , booktitle =. Accelerating Semantic Image Segmentation on FPGA , year =
-
[40]
Accelerating and Pruning CNNs for Semantic Segmentation on FPGA , year =
Mor\`. Accelerating and Pruning CNNs for Semantic Segmentation on FPGA , year =. doi:10.1145/3489517.3530424 , booktitle =
-
[41]
arXiv preprint arXiv:2601.02346 , year=
Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling , author=. arXiv preprint arXiv:2601.02346 , year=
-
[42]
Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture , pages=
HLX: A Unified Pipelined Architecture for Optimized Performance of Hybrid Transformer-Mamba Language Models , author=. Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture , pages=
-
[43]
GPU gems , volume=
Parallel prefix sum (scan) with CUDA , author=. GPU gems , volume=
-
[44]
2017 , eprint=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. 2017 , eprint=
2017
-
[45]
2022 , eprint=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. 2022 , eprint=
2022
-
[46]
Lieber, Opher and Lenz, Barak and Bata, Hofit and Cohen, Gal and Osin, Jhonathan and Dalmedigos, Itay and Safahi, Erez and Meirom, Shaked and Belinkov, Yonatan and. Jamba:. 2024 , month = mar, number =. doi:10.48550/arXiv.2403.19887 , urldate =. arXiv , keywords =:2403.19887 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.19887 2024
-
[47]
NVIDIA , year =. Nemotron-. doi:10.48550/arXiv.2504.03624 , urldate =. arXiv , keywords =:2504.03624 , primaryclass =
-
[48]
Longformer: The Long-Document Transformer , author=. arXiv:2004.05150 , year=
Pith/arXiv arXiv 2004
-
[49]
Proceedings of the AAAI conference on artificial intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[50]
Srihari , title=
Navid Madani and Sougata Saha and Rohini K. Srihari , title=. CoRR , volume=. 2024 , cdate=
2024
-
[51]
arXiv preprint arXiv:2504.15965 , year=
From human memory to ai memory: A survey on memory mechanisms in the era of llms , author=. arXiv preprint arXiv:2504.15965 , year=
-
[52]
arXiv preprint arXiv:2410.15665 , year=
Long term memory: The foundation of ai self-evolution , author=. arXiv preprint arXiv:2410.15665 , year=
-
[53]
arXiv preprint arXiv:2403.08295 , year=
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
-
[54]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[57]
GitHub repository , howpublished =
Gu, Albert and Dao, Tri , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[58]
GitHub repository , howpublished =
Tencent Team , title =. GitHub repository , howpublished =. 2025 , publisher =
2025
-
[59]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[60]
ArXiv , year=
LLaMA: Open and Efficient Foundation Language Models , author=. ArXiv , year=
-
[61]
2023 IEEE Symposium on High-Performance Interconnects (HOTI) , pages=
Performance characterization of large language models on high-speed interconnects , author=. 2023 IEEE Symposium on High-Performance Interconnects (HOTI) , pages=. 2023 , organization=
2023
-
[62]
arXiv preprint arXiv:1811.09886 , year=
Deep learning inference in facebook data centers: Characterization, performance optimizations and hardware implications , author=. arXiv preprint arXiv:1811.09886 , year=
-
[63]
arXiv preprint arXiv:2307.13702 , year=
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
-
[64]
2020 , eprint=
Longformer: The Long-Document Transformer , author=. 2020 , eprint=
2020
-
[65]
2024 IEEE International Symposium on Workload Characterization (IISWC) , pages=
Understanding Performance Implications of LLM Inference on CPUs , author=. 2024 IEEE International Symposium on Workload Characterization (IISWC) , pages=. 2024 , organization=
2024
-
[66]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
\ InfiniGen \ : Efficient generative inference of large language models with dynamic \ KV \ cache management , author=. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
-
[67]
FlexGen: high-throughput generative inference of large language models with a single GPU , year =
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Chen, Beidi and Liang, Percy and R\'. FlexGen: high-throughput generative inference of large language models with a single GPU , year =. Proceedings of the 40th International Conference on Machine Learning , articleno =
-
[68]
Proceedings of the 5th Workshop on Machine Learning and Systems , pages =
Du, Hongchao and Wu, Shangyu and Kharlamova, Arina and Guan, Nan and Xue, Chun Jason , title =. Proceedings of the 5th Workshop on Machine Learning and Systems , pages =. 2025 , isbn =. doi:10.1145/3721146.3721961 , abstract =
-
[69]
Black, Sid and Gao, Leo and Wang, Phil and Leahy, Connor and Biderman, Stella , title =. doi:10.5281/zenodo.5297715 , url =
-
[70]
arXiv preprint arXiv:2401.02385 , year=
Tinyllama: An open-source small language model , author=. arXiv preprint arXiv:2401.02385 , year=
-
[71]
and Ermon, Stefano and Rudra, Atri and R\'
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R\'. FLASHATTENTION: fast and memory-efficient exact attention with IO-awareness , year =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
-
[72]
Panopoulos, Ioannis and Nikolaidis, Sokratis and Venieris, Stylianos I. and Venieris, Iakovos S. , booktitle =. 2023 , volume =. doi:10.1109/ISCC58397.2023.10217850 , url =
-
[73]
Ren, Liliang and Liu, Yang and Lu, Yadong and Shen, Yelong and Liang, Chen and Chen, Weizhu , year =. Samba:. doi:10.48550/arXiv.2406.07522 , urldate =. arXiv , keywords =:2406.07522 , primaryclass =
-
[74]
Team, Jamba and Lenz, Barak and Arazi, Alan and Bergman, Amir and Manevich, Avshalom and Peleg, Barak and Aviram, Ben and Almagor, Chen and Fridman, Clara and Padnos, Dan and Gissin, Daniel and Jannai, Daniel and Muhlgay, Dor and Zimberg, Dor and Gerber, Edden M. and Dolev, Elad and Krakovsky, Eran and Safahi, Erez and Schwartz, Erez and Cohen, Gal and Sh...
-
[75]
Dao, Tri and Gu, Albert , year =. Transformers Are. doi:10.48550/arXiv.2405.21060 , urldate =. arXiv , keywords =:2405.21060 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.21060
-
[76]
Waleffe, Roger and Byeon, Wonmin and Riach, Duncan and Norick, Brandon and Korthikanti, Vijay and Dao, Tri and Gu, Albert and Hatamizadeh, Ali and Singh, Sudhakar and Narayanan, Deepak and Kulshreshtha, Garvit and Singh, Vartika and Casper, Jared and Kautz, Jan and Shoeybi, Mohammad and Catanzaro, Bryan , year =. An. doi:10.48550/arXiv.2406.07887 , urldat...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.07887
-
[77]
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. CoRR , volume =. 2020 , url =. 2001.08361 , timestamp =
Pith/arXiv arXiv 2020
-
[78]
arXiv preprint arXiv:2304.04675 , year=
Multilingual machine translation with large language models: Empirical results and analysis , author=. arXiv preprint arXiv:2304.04675 , year=
-
[79]
and Kavukcuoglu, Koray and Kohli, Pushmeet and Hassabis, Demis , year =
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and. Highly Accurate Protein Structure Prediction with. 2021 , month = aug, journal =. doi:10.1038/s41586-021-03819-2 , abstract =
-
[80]
2023 , eprint=
Attention Is All You Need , author=. 2023 , eprint=
2023
-
[81]
2024 , eprint=
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. 2024 , eprint=
2024
-
[82]
arXiv preprint arXiv:2405.21060 , year=
Transformers are ssms: Generalized models and efficient algorithms through structured state space duality , author=. arXiv preprint arXiv:2405.21060 , year=
-
[83]
Toward low-flying autonomous MAV trail navigation using deep neural networks for environmental awareness , author=. Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2017 , publisher =. doi:10.1109/IROS.2017.8206285 , address =
-
[84]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[85]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.