FGRPO: Federated GRPO with Adaptive Aggregation on Non-IID Data
Pith reviewed 2026-06-28 11:42 UTC · model grok-4.3
The pith
FGRPO decentralizes GRPO fine-tuning across data owners with adaptive aggregation on relative performance gains to converge on non-IID data while keeping raw data private.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FGRPO is a framework that decentralizes the fine-tuning of reasoning models across heterogeneous data owners by incorporating an adaptive aggregation mechanism based on relative performance gain, where each client's improvement is characterized relative to its personalized historical baseline, thereby dynamically prioritizing effective learning trajectories and ensuring robust convergence on non-IID data while preserving data privacy.
What carries the argument
The adaptive aggregation mechanism based on relative performance gain, which measures each client's improvement against its own historical baseline to prioritize learning trajectories and reduce instability from divergent reward scales.
If this is right
- Fine-tuning of reasoning models can proceed across separate owners without centralizing raw data.
- Training stability holds when local datasets are non-IID and reward scales vary.
- Only aggregated model updates need to be exchanged, satisfying privacy constraints.
- Clients with easier local tasks do not dominate the global update because gains are normalized to each client's history.
Where Pith is reading between the lines
- The same relative-gain idea could be tested in other federated reinforcement-learning algorithms that lack a critic.
- If the baseline update rule proves sensitive to the length of history kept per client, longer histories might improve robustness on very heterogeneous data.
- Real-world deployment would require checking whether communication cost of the extra baseline statistics remains acceptable at scale.
Load-bearing premise
That scoring each client against its own past performance will reliably select useful updates and stabilize training even when tasks differ sharply in difficulty and reward magnitude.
What would settle it
A side-by-side run of standard federated GRPO versus FGRPO on the same non-IID collection of tasks with mismatched reward scales, where the version without relative-gain aggregation diverges while FGRPO converges.
Figures

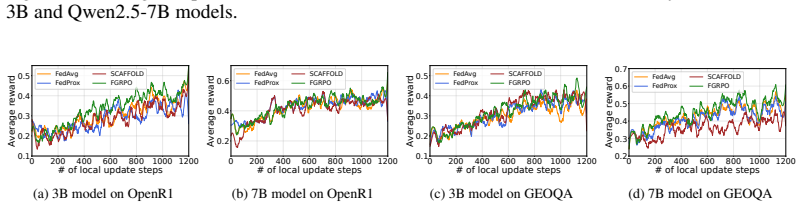

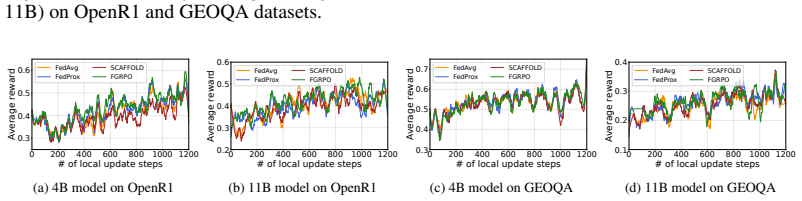
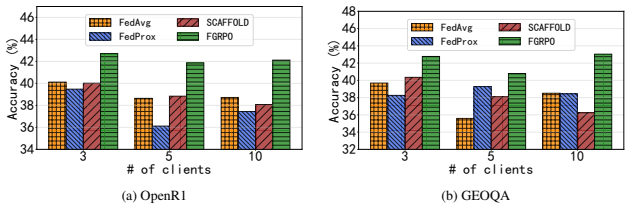
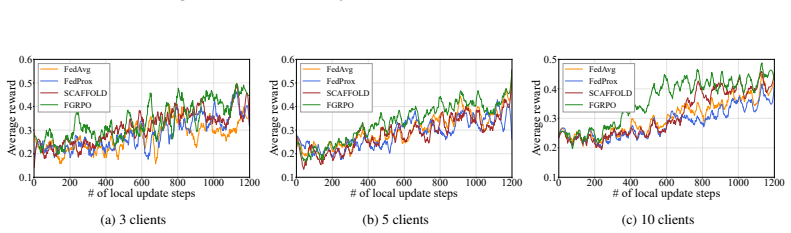
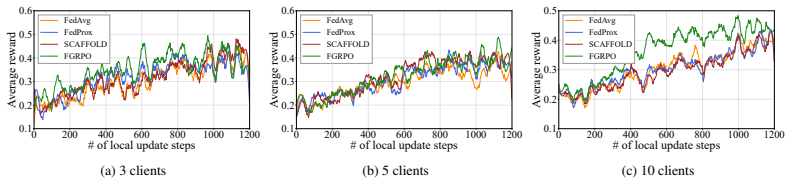
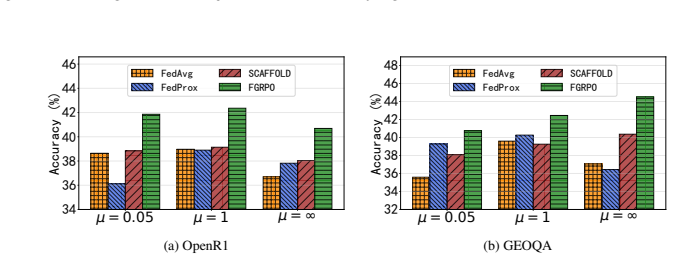
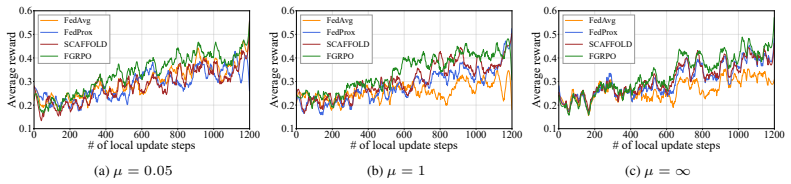
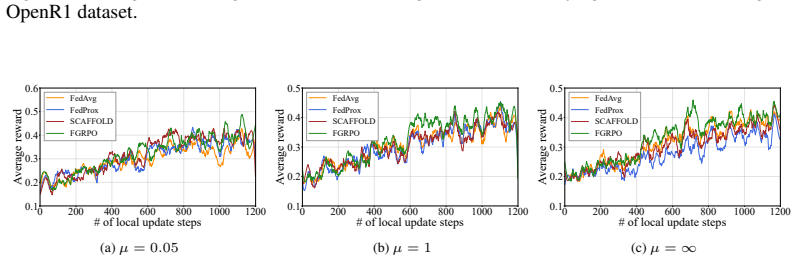
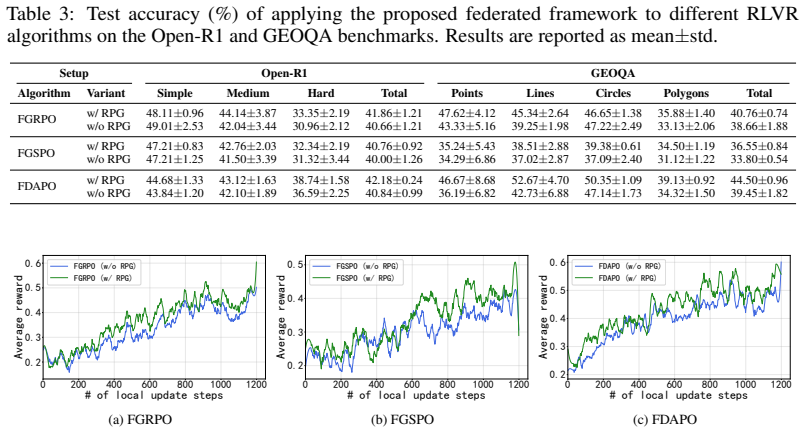
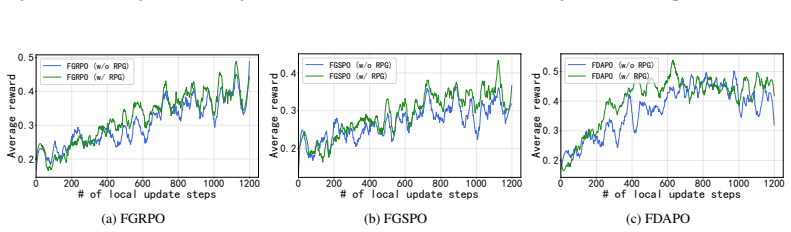
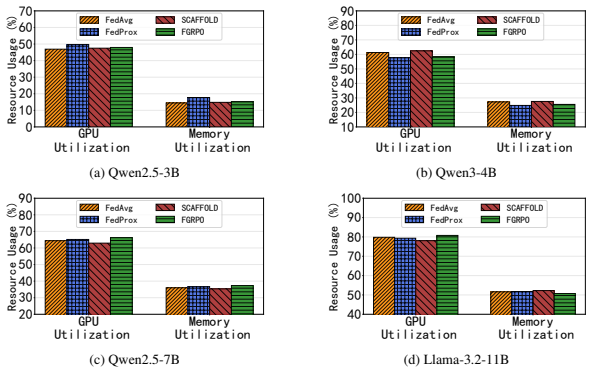
read the original abstract
Recent advances in language models have established reinforcement learning as the primary paradigm for eliciting self-correction and long-chain reasoning. While group relative policy optimization (GRPO) offers superior scalability by eliminating the critic network, deploying it on a central infrastructure entails collecting a large volume of data from distributed owners, which poses significant privacy risks. To address these concerns, we introduce federated GRPO (FGRPO), a framework designed to decentralize the fine-tuning of reasoning models across heterogeneous data owners. To effectively mitigate the instability caused by divergent reward scales across heterogeneous tasks, FGRPO incorporates an adaptive aggregation mechanism based on relative performance gain. By characterizing each client's improvement relative to its personalized historical baseline, the framework dynamically prioritizes effective learning trajectories regardless of local task difficulty. FGRPO ensures robust convergence on non-IID data while preserving data privacy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Federated GRPO (FGRPO), extending Group Relative Policy Optimization to a federated setting for decentralizing RL fine-tuning of reasoning models across distributed, privacy-sensitive data owners. It introduces an adaptive aggregation rule that weights client updates according to each client's relative performance gain against a personalized historical baseline, with the goal of stabilizing training under non-IID data and heterogeneous reward scales. The central claim is that this mechanism ensures robust convergence while preserving data privacy.
Significance. If the adaptive aggregation rule can be shown to be well-defined and empirically effective, the work would address a practically important gap between scalable RL methods such as GRPO and the privacy constraints of distributed model owners. No machine-checked proofs, reproducible code, or parameter-free derivations are presented, so the significance rests entirely on whether the empirical and theoretical support supplied in the full manuscript substantiates the convergence claim.
major comments (3)
- [Abstract] Abstract: the assertion that FGRPO 'ensures robust convergence on non-IID data' is presented without any experimental results, learning curves, ablation studies, or statistical tests. Because the central claim is empirical, the absence of supporting evidence is load-bearing.
- [Abstract] Abstract: the adaptive aggregation is defined in terms of 'relative performance gain' computed against a 'personalized historical baseline,' yet no equation, algorithm, or pseudocode is supplied for either quantity. Without these definitions it is impossible to determine whether the weighting rule is independent of the data or reduces to a post-hoc fit, directly affecting the soundness of the non-IID stability claim.
- No section or equation is referenced for the convergence argument. The manuscript must supply either a formal convergence proof under standard federated assumptions or a reproducible experimental protocol with error bars before the robustness claim can be evaluated.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that FGRPO 'ensures robust convergence on non-IID data' is presented without any experimental results, learning curves, ablation studies, or statistical tests. Because the central claim is empirical, the absence of supporting evidence is load-bearing.
Authors: We agree that the abstract states an empirical claim without referencing supporting evidence. The revised manuscript will qualify the claim in the abstract or add an explicit reference to the experimental results (including learning curves, ablations, and statistical tests) presented in Section 4. revision: yes
-
Referee: [Abstract] Abstract: the adaptive aggregation is defined in terms of 'relative performance gain' computed against a 'personalized historical baseline,' yet no equation, algorithm, or pseudocode is supplied for either quantity. Without these definitions it is impossible to determine whether the weighting rule is independent of the data or reduces to a post-hoc fit, directly affecting the soundness of the non-IID stability claim.
Authors: We acknowledge that the abstract does not include the formal definitions. The revised version will add the equations for relative performance gain (computed against the per-client moving-average baseline) and the resulting aggregation weights, along with the corresponding algorithm pseudocode, either in the abstract (if space allows) or with a clear pointer from the abstract to Section 3. revision: yes
-
Referee: [—] No section or equation is referenced for the convergence argument. The manuscript must supply either a formal convergence proof under standard federated assumptions or a reproducible experimental protocol with error bars before the robustness claim can be evaluated.
Authors: We agree that the current text does not reference a convergence argument. The revised manuscript will either include a proof sketch under standard federated assumptions (bounded heterogeneity, Lipschitz rewards) or expand the experimental protocol description in Section 4 to include multiple independent runs with error bars, ensuring the robustness claim is properly substantiated. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description introduce FGRPO and its adaptive aggregation mechanism conceptually, characterizing client improvements relative to personalized historical baselines to handle non-IID data. No equations, self-citations, or derivation steps are present that reduce any claim to its own inputs by construction (e.g., no fitted parameters renamed as predictions or ansatzes smuggled via citation). The framework is presented as a proposed method rather than a mathematical derivation, making it self-contained against external benchmarks with no load-bearing circular elements.
Axiom & Free-Parameter Ledger
invented entities (1)
-
relative performance gain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE-Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to Basics: Revisiting REINFORCE-Style Optimization for Learning from Human Feedback in LLMs. InProc. of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 12248–12267, 2024
2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
R1-V: Reinforcing Super Gen- eralization Ability in Vision-Language Models with Less Than $3
Liang Chen, Lei Li, Haozhe Zhao, Yifan Song, and Vinci. R1-V: Reinforcing Super Gen- eralization Ability in Vision-Language Models with Less Than $3. https://github.com/ Deep-Agent/R1-V, 2025. Accessed: 2025-02-02
2025
-
[5]
Minghan Chen, Guikun Chen, Wenguan Wang, and Yi Yang. SEED-GRPO: Semantic Entropy Enhanced GRPO for Uncertainty-Aware Policy Optimization.arXiv preprint arXiv:2505.12346, 2025
-
[6]
Open-R1-Multimodal: A Fork to Add Multimodal Model Training to Open-R1.https://github.com/EvolvingLMMs-Lab/open-r1-multimodal, 2025
EvolvingLMMs-Lab. Open-R1-Multimodal: A Fork to Add Multimodal Model Training to Open-R1.https://github.com/EvolvingLMMs-Lab/open-r1-multimodal, 2025
2025
-
[7]
Fault-Tolerant Federated Reinforcement Learning with Theoretical Guarantee
Flint Xiaofeng Fan, Yining Ma, Zhongxiang Dai, Wei Jing, Cheston Tan, and Bryan Kian Hsiang Low. Fault-Tolerant Federated Reinforcement Learning with Theoretical Guarantee. InProc. of the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), pages 1007–1021, 2021
2021
-
[8]
FedRLHF: A Convergence-Guaranteed Federated Framework for Privacy-Preserving and Per- sonalized RLHF
Flint Xiaofeng Fan, Cheston Tan, Yew-Soon Ong, Roger Wattenhofer, and Wei Tsang Ooi. FedRLHF: A Convergence-Guaranteed Federated Framework for Privacy-Preserving and Per- sonalized RLHF. InProc. of the 24th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 713–721, 2025
2025
-
[9]
Provably Robust Federated Rein- forcement Learning
Minghong Fang, Xilong Wang, and Neil Zhenqiang Gong. Provably Robust Federated Rein- forcement Learning. InProc. of the 2025 ACM on Web Conference (WWW), pages 896–909, 2025
2025
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
DeepSeek-R1 Incentivizes Reasoning in LLMs through Reinforcement Learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1 Incentivizes Reasoning in LLMs through Reinforcement Learning.Nature, 645(8081):633–638, 2025
2025
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In Proc. of the 10th International Conference on Learning Representations (ICLR), 2022
2022
-
[13]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. OpenAI o1 System Card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
FedHPD: Heterogeneous Federated Reinforcement Learning via Policy Distillation
Wenzheng Jiang, Ji Wang, Xiongtao Zhang, Weidong Bao, Cheston Tan, and Flint Xiaofeng Fan. FedHPD: Heterogeneous Federated Reinforcement Learning via Policy Distillation. In Proc. of the 24th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 2568–2570, 2025
2025
-
[15]
Federated Reinforcement Learning with Environment Heterogeneity
Hao Jin, Yang Peng, Wenhao Yang, Shusen Wang, and Zhihua Zhang. Federated Reinforcement Learning with Environment Heterogeneity. InProc. of The 25th International Conference on Artificial Intelligence and Statistics (AISTATS), pages 18–37, 2022
2022
-
[16]
Decentralized Federated Policy Gradient with Byzantine Fault-Tolerance and Provably Fast Convergence
Philip Jordan, Florian Grötschla, Flint Xiaofeng Fan, and Roger Wattenhofer. Decentralized Federated Policy Gradient with Byzantine Fault-Tolerance and Provably Fast Convergence. In Proc. of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 964–972, 2024. 10
2024
-
[17]
Reddi, Sebastian U
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank J. Reddi, Sebastian U. Stich, and Ananda Theertha Suresh. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. InProc. of the 37th International Conference on Machine Learning (ICML), pages 5132–5143, 2020
2020
-
[18]
Federated Reinforce- ment Learning: Linear Speedup Under Markovian Sampling
Sajad Khodadadian, Pranay Sharma, Gauri Joshi, and Siva Theja Maguluri. Federated Reinforce- ment Learning: Linear Speedup Under Markovian Sampling. InProc. of the 39th International Conference on Machine Learning (ICML), pages 10997–11057, 2022
2022
-
[19]
Konda and John N
Vijay R. Konda and John N. Tsitsiklis. Actor-critic algorithms. InAdvances in Neural Information Processing Systems (NIPS), pages 1008–1014, 1999
1999
-
[20]
Asynchronous Federated Reinforcement Learning with Policy Gradient Updates: Algorithm Design and Convergence Analysis
Guangchen Lan, Dong-Jun Han, Abolfazl Hashemi, Vaneet Aggarwal, and Christopher Brinton. Asynchronous Federated Reinforcement Learning with Policy Gradient Updates: Algorithm Design and Convergence Analysis. InProc. of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Federated Optimization in Heterogeneous Networks
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated Optimization in Heterogeneous Networks. InProc. of the 3rd Conference on Machine Learning and Systems (MLSys), 2020
2020
-
[22]
Zhihang Lin, Mingbao Lin, Yuan Xie, and Rongrong Ji. CPPO: Accelerating the Train- ing of Group Relative Policy Optimization-Based Reasoning Models.arXiv preprint arXiv:2503.22342, 2025
-
[23]
Communication-Efficient Learning of Deep Networks from Decentralized Data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProc. of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 54 of Proceedings of Machine Learning Research, pages 1273–1282, 2017
2017
-
[24]
Lei Pang and Ruinan Jin. On the Theory and Practice of GRPO: A Trajectory-Corrected Approach with Fast Convergence.arXiv preprint arXiv:2508.02833, 2025
-
[25]
Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and Hugh Brendan McMahan
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and Hugh Brendan McMahan. Adaptive Federated Optimization. InProc. of the 9th International Conference on Learning Representations (ICLR), 2021
2021
-
[26]
Federated Ensemble-Directed Offline Reinforcement Learning
Desik Rengarajan, Nitin Ragothaman, Dileep Kalathil, and Srinivas Shakkottai. Federated Ensemble-Directed Offline Reinforcement Learning. InProc. of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
Han Wang, Sihong He, Zhili Zhang, Fei Miao, and James Anderson. Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments. InProc. of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[30]
The Blessing of Heterogeneity in Federated Q-Learning: Linear Speedup and Beyond
Jiin Woo, Gauri Joshi, and Yuejie Chi. The Blessing of Heterogeneity in Federated Q-Learning: Linear Speedup and Beyond. InProc. of the 40th International Conference on Machine Learning (ICML), pages 37157–37216, 2023
2023
-
[31]
Federated Offline Reinforcement Learning: Collaborative Single-Policy Coverage Suffices
Jiin Woo, Laixi Shi, Gauri Joshi, and Yuejie Chi. Federated Offline Reinforcement Learning: Collaborative Single-Policy Coverage Suffices. InProc. of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[32]
Zhijie Xie and Shenghui Song. The Actor-Critic Update Order Matters for PPO in Federated Reinforcement Learning.arXiv preprint arXiv:2506.01261, 2025
-
[33]
On the Linear Speedup of Person- alized Federated Reinforcement Learning with Shared Representations
Guojun Xiong, Shufan Wang, Daniel Jiang, and Jian Li. On the Linear Speedup of Person- alized Federated Reinforcement Learning with Shared Representations. InProc. of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[34]
Federated Natural Policy Gradient and Actor Critic Methods for Multi-task Reinforcement Learning
Tong Yang, Shicong Cen, Yuting Wei, Yuxin Chen, and Yuejie Chi. Federated Natural Policy Gradient and Actor Critic Methods for Multi-task Reinforcement Learning. InProc. of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), 2024. 11
2024
-
[35]
On Classes of Summable Functions and Their Fourier Series.Proc
William Henry Young. On Classes of Summable Functions and Their Fourier Series.Proc. of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 87(594):225–229, 1912
1912
-
[36]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An Open-Source LLM Reinforcement Learning System at Scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Finite-Time Analysis of On- Policy Heterogeneous Federated Reinforcement Learning
Chenyu Zhang, Han Wang, Aritra Mitra, and James Anderson. Finite-Time Analysis of On- Policy Heterogeneous Federated Reinforcement Learning. InProc. of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[38]
Jixiao Zhang and Chunsheng Zuo. GRPO-LEAD: A Difficulty-Aware Reinforcement Learn- ing Approach for Concise Mathematical Reasoning in Language Models.arXiv preprint arXiv:2504.09696, 2025
-
[39]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A Survey of Reinforcement Learning for Large Reasoning Models.arXiv preprint arXiv:2509.08827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group Sequence Policy Optimization.arXiv preprint arXiv:2507.18071, 2025. 12 Contents 1 Introduction 1 2 System Model and Preliminaries 2 2.1 Federated Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2.2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Recent theoretical research has focused on establishing rigorous convergence guarantees under the unique constraints of sequential decision-making
across diverse clients to enhance sample efficiency without compromising raw data or trajectory privacy. Recent theoretical research has focused on establishing rigorous convergence guarantees under the unique constraints of sequential decision-making. [37] provides a fundamental finite-time analysis of on-policy FedRL under data heterogeneity, while [18]...
-
[42]
collaborative single-policy coverage
that a “collaborative single-policy coverage” condition, where the union of client data covers the optimal policy, is sufficient for global optimality. Furthermore, [ 33] highlights that shared representation learning can further accelerate convergence by extracting collaborative features across diverse tasks, while [34] proposes federated natural policy ...
-
[43]
Similarly, DAPO [36] introduces a decoupled and dynamic sampling system designed to stabilize long Chain-of-Thought (CoT) reasoning
addresses the issues of verbosity and sparsity by integrating length-regularized rewards and difficulty-aware advantage reweighting, which ensures robust generalization on challenging problems. Similarly, DAPO [36] introduces a decoupled and dynamic sampling system designed to stabilize long Chain-of-Thought (CoT) reasoning. By employing asymmetric clippi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.