Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
Pith reviewed 2026-06-28 10:22 UTC · model grok-4.3
The pith
A reinforcement learning controller trained on answer statistics decides when to stop sampling from large language models to balance correctness against latency and cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
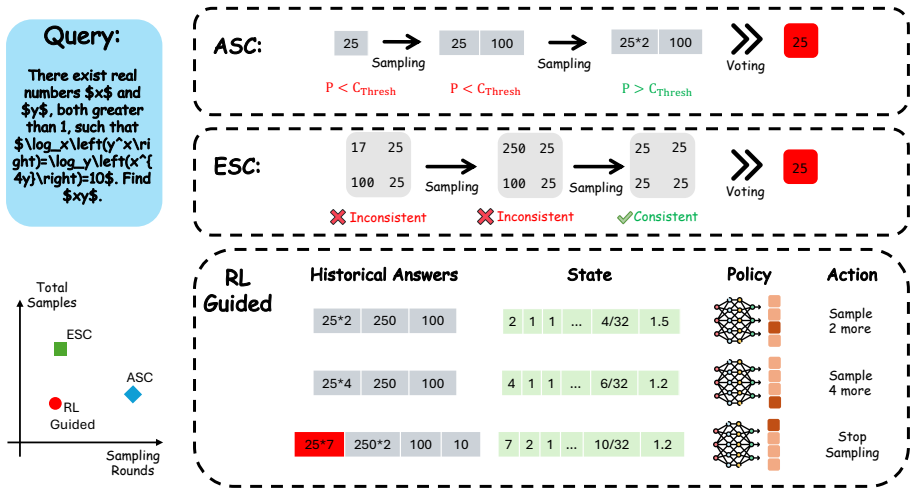
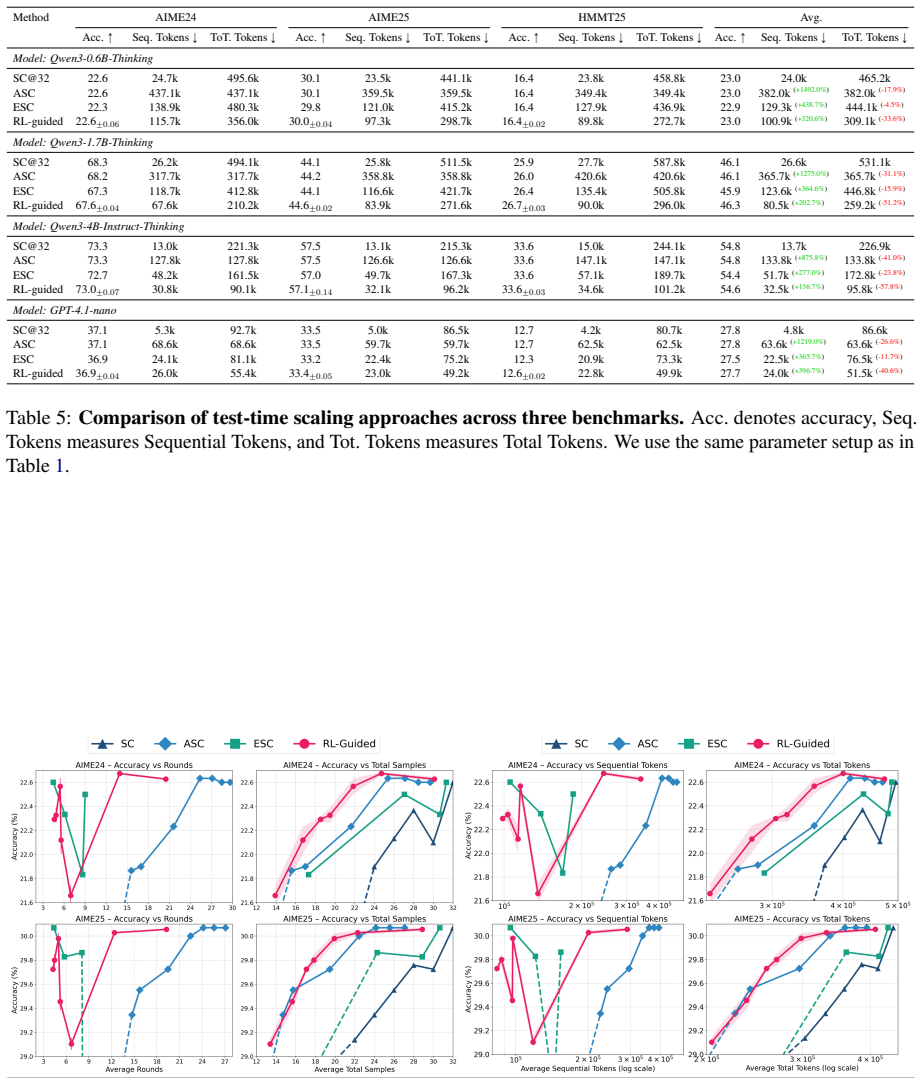
By casting adaptive sampling as an MDP and training a lightweight RL controller, the method jointly optimizes for answer correctness, sampling rounds, and total samples, achieving better trade-offs than heuristic baselines such as ASC and ESC. The framework also admits an interpretation as the Lagrangian relaxation of a constrained optimization problem with explicit budget constraints. The controller decides at each round whether to stop or acquire additional samples.
What carries the argument
The Markov decision process formulation of the sampling decision, with the RL-trained lightweight controller that takes statistics of final answers as state and outputs stop or continue actions.
If this is right
- The controller relies only on final answer statistics and can be trained and deployed on CPU.
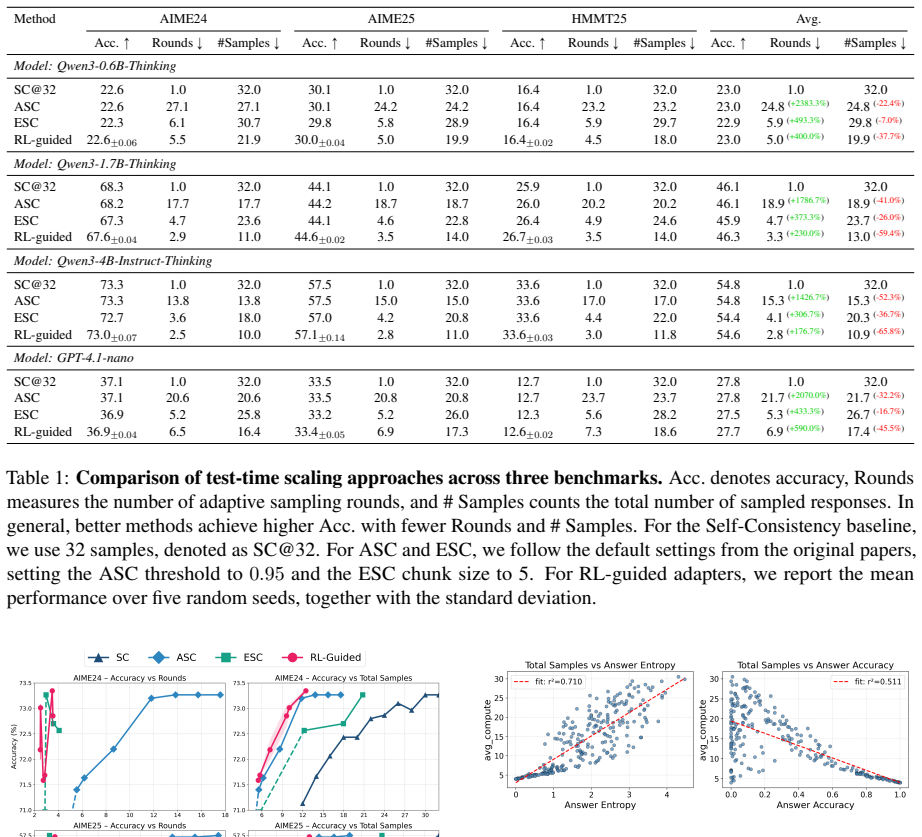
- The method improves trade-offs among answer correctness, sampling rounds, and total samples required compared to strong baselines.
- The resulting framework can be viewed as the Lagrangian relaxation of a constrained optimization problem with explicit budget constraints.
Where Pith is reading between the lines
- If the controller generalizes across different LLMs without retraining, it could act as a reusable module attached to any base model.
- The MDP structure could allow reward functions that penalize answer diversity loss in addition to correctness and cost.
- Extending the state to include partial reasoning traces might increase decision quality at the price of added complexity.
Load-bearing premise
Statistics of final answers alone are sufficient for the controller to make effective stop-or-continue decisions without needing model internals or additional context.
What would settle it
If experiments on reasoning benchmarks show that the RL controller requires more total samples than ASC or ESC to reach equivalent accuracy levels, the claim of improved trade-offs would be falsified.
Figures

read the original abstract
Test-time scaling improves the reasoning performance of large language models but incurs substantial cost in both total computation and latency. Existing adaptive sampling methods partially mitigate this issue by dynamically deciding when to stop sampling, yet they typically rely on heuristic rules or rely on distribution assumptions. In this work, we formulate adaptive sampling as a Markov decision process (MDP). We train a lightweight sampling controller with reinforcement learning (RL) to jointly balance answer correctness, latency, and computation cost. At each round, the controller decides to stop sampling or to acquire additional samples. Our method is lightweight which only relies on statistics of final answers, and can be trained and deployed on CPU. We further show that the resulting framework admits an interpretation as the Lagrangian relaxation of a constrained optimization problem with explicit budget constraints. Experiments against strong baselines such as ASC and ESC show that our method achieves improved trade-offs among answer correctness, sampling rounds, and total samples required.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates adaptive sampling during test-time scaling of LLMs as a Markov decision process. A lightweight controller is trained via reinforcement learning to decide at each round whether to stop or acquire additional samples; the controller uses only aggregate statistics of the sampled final answers as its state and is trained to jointly optimize answer correctness against latency and total compute. The framework is shown to admit a Lagrangian-relaxation interpretation of a constrained optimization problem with explicit budgets. Experiments against ASC and ESC baselines report improved trade-offs among correctness, number of sampling rounds, and total samples.
Significance. If the empirical gains are robust, the work supplies a model-agnostic, CPU-deployable controller that replaces heuristic stopping rules with a learned policy, while the Lagrangian view supplies a clean optimization-theoretic framing. These features would be useful for practical deployment of test-time scaling under resource constraints.
major comments (2)
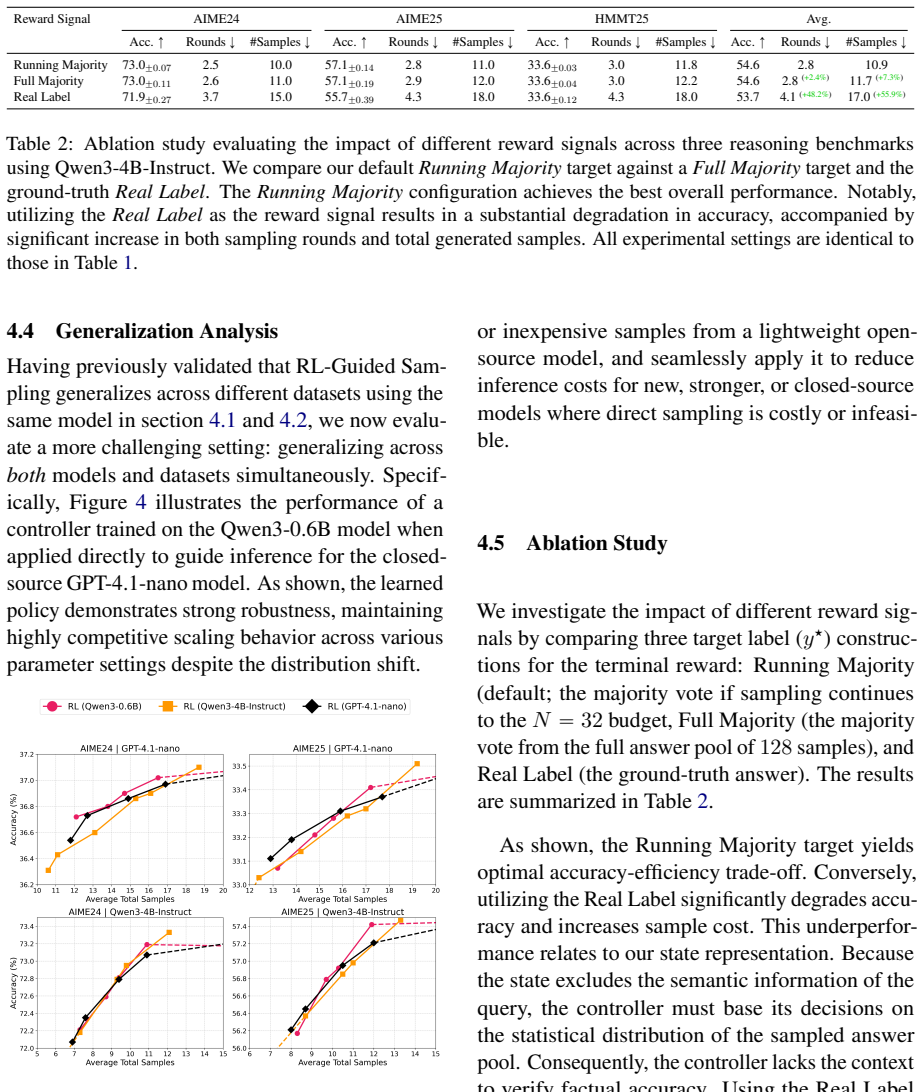
- [§3 (MDP formulation)] §3 (MDP formulation): the state is restricted to statistics of final answers alone. Because these statistics cannot distinguish high-agreement correct answers from high-agreement incorrect answers, the learned policy has no signal to avoid premature stopping on consistent errors; this directly undermines the central claim that the RL controller produces improved correctness–cost trade-offs.
- [§5 (Experiments)] §5 (Experiments): the reward function, the precise definition of the MDP state vector, and the training protocol (including how the controller is optimized and whether it is retrained per LLM or task) are not specified in sufficient detail to allow reproduction or to verify that the reported gains are not artifacts of the particular reward shaping.
minor comments (2)
- [§4] The Lagrangian interpretation is presented as an after-the-fact view; making explicit how the dual variables are handled during RL training would strengthen the connection between the two framings.
- [§3] Notation for the per-round statistics (e.g., agreement rate, variance) is introduced without a consolidated table; a single table listing all state features would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address the major comments point by point below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [§3 (MDP formulation)] §3 (MDP formulation): the state is restricted to statistics of final answers alone. Because these statistics cannot distinguish high-agreement correct answers from high-agreement incorrect answers, the learned policy has no signal to avoid premature stopping on consistent errors; this directly undermines the central claim that the RL controller produces improved correctness–cost trade-offs.
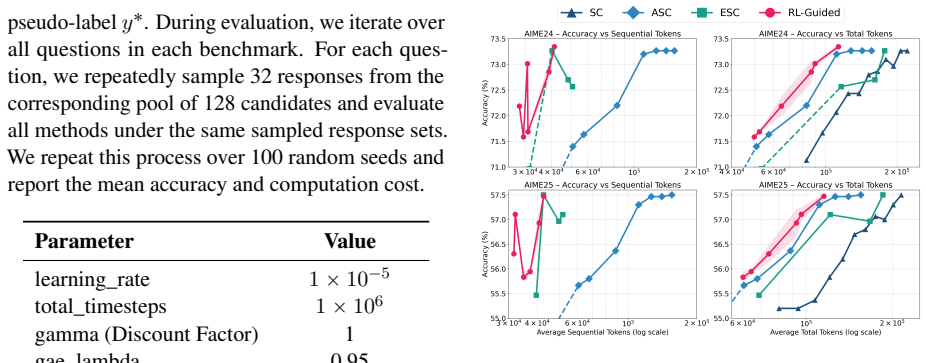
Authors: We appreciate this observation regarding the limitations of the state representation. The state indeed consists solely of aggregate statistics (e.g., answer frequencies, entropy) without access to ground-truth correctness during inference. However, during RL training, the reward function incorporates a correctness term (based on matching to reference answers in the training data), allowing the policy to learn stopping decisions that correlate with improved expected correctness in the distribution of tasks. The empirical results demonstrate that this leads to better trade-offs compared to baselines, suggesting that the learned policy effectively avoids many consistent error cases through patterns in the statistics. We will add a discussion of this limitation and potential extensions (e.g., incorporating model confidence if available) in the revised manuscript. revision: partial
-
Referee: [§5 (Experiments)] §5 (Experiments): the reward function, the precise definition of the MDP state vector, and the training protocol (including how the controller is optimized and whether it is retrained per LLM or task) are not specified in sufficient detail to allow reproduction or to verify that the reported gains are not artifacts of the particular reward shaping.
Authors: We agree that additional details are necessary for reproducibility. In the revised version, we will include the exact formulation of the reward function (including weights for correctness, latency, and compute), the full definition of the state vector components, the training algorithm (e.g., PPO or similar), hyperparameters, and clarification on whether the controller is trained per model/task or in a general manner. This will allow verification of the results. revision: yes
Circularity Check
No significant circularity in RL controller training or MDP formulation
full rationale
The paper formulates adaptive sampling as an MDP and trains a lightweight RL controller on final-answer statistics to balance correctness, latency, and cost. This is an empirical learning procedure whose policy is obtained via optimization against an external reward signal, not a closed-form derivation that reduces to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no fitted parameters are relabeled as predictions, and no ansatz is smuggled through prior work. The Lagrangian interpretation is presented as an after-the-fact view of the trained policy rather than a definitional equivalence. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adaptive sampling can be formulated as an MDP whose state depends only on statistics of generated answers.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1911.10422 , year=
Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals , author=. arXiv preprint arXiv:1911.10422 , year=
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2502.14768 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[5]
Alphazero-like tree-search can guide large language model decoding and training , author=. arXiv preprint arXiv:2309.17179 , year=
-
[6]
arXiv preprint arXiv:2410.06508 , year=
Towards Self-Improvement of LLMs via MCTS: Leveraging Stepwise Knowledge with Curriculum Preference Learning , author=. arXiv preprint arXiv:2410.06508 , year=
-
[7]
arXiv preprint arXiv:2504.10160 , year=
MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning , author=. arXiv preprint arXiv:2504.10160 , year=
-
[8]
ACM Computing Surveys , volume=
A comprehensive survey on relation extraction: Recent advances and new frontiers , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[9]
Cognitive computation , volume=
Deep neural approaches to relation triplets extraction: a comprehensive survey , author=. Cognitive computation , volume=. 2021 , publisher=
2021
-
[10]
ACM Computing Surveys , volume=
A comprehensive survey on automatic knowledge graph construction , author=. ACM Computing Surveys , volume=. 2023 , publisher=
2023
-
[11]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[12]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2310.01061 , year=
Reasoning on graphs: Faithful and interpretable large language model reasoning , author=. arXiv preprint arXiv:2310.01061 , year=
-
[14]
Computers in Biology and Medicine , volume=
Alzheimer's disease knowledge graph enhances knowledge discovery and disease prediction , author=. Computers in Biology and Medicine , volume=. 2025 , publisher=
2025
-
[15]
Nature Communications , volume=
Large language model powered knowledge graph construction for mental health exploration , author=. Nature Communications , volume=. 2025 , publisher=
2025
-
[16]
Proceedings of the 29th ACM International Conference on Information & Knowledge Management , pages=
AliMeKG: Domain knowledge graph construction and application in e-commerce , author=. Proceedings of the 29th ACM International Conference on Information & Knowledge Management , pages=
-
[17]
World Wide Web , volume=
Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities , author=. World Wide Web , volume=. 2024 , publisher=
2024
-
[18]
Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension , author=. arXiv preprint arXiv:1910.13461 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[19]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[20]
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling , author=. arXiv preprint arXiv:2605.08083 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling , author=. arXiv preprint arXiv:2601.21684 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[23]
Proceedings of the conference
Revisiting relation extraction in the era of large language models , author=. Proceedings of the conference. Association for Computational Linguistics. Meeting , volume=
-
[24]
arXiv preprint arXiv:2305.01555 , year=
How to unleash the power of large language models for few-shot relation extraction? , author=. arXiv preprint arXiv:2305.01555 , year=
-
[25]
arXiv preprint arXiv:2310.07641 , year=
Evaluating large language models at evaluating instruction following , author=. arXiv preprint arXiv:2310.07641 , year=
-
[26]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
ECAI 2020 , pages=
Span-based joint entity and relation extraction with transformer pre-training , author=. ECAI 2020 , pages=. 2020 , publisher=
2020
-
[28]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[29]
arXiv preprint arXiv:2503.01491 , year=
What's Behind PPO's Collapse in Long-CoT? Value Optimization Holds the Secret , author=. arXiv preprint arXiv:2503.01491 , year=
-
[30]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks , author=. arXiv preprint arXiv:2504.05118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
A survey on llm-as-a-judge , author=. arXiv preprint arXiv:2411.15594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Journal of Artificial Intelligence Research , volume=
Computational benefits of intermediate rewards for goal-reaching policy learning , author=. Journal of Artificial Intelligence Research , volume=
-
[35]
On Time, Within Budget: Constraint-Driven Online Resource Allocation for Agentic Workflows
On Time, Within Budget: Constraint-Driven Online Resource Allocation for Agentic Workflows , author=. arXiv preprint arXiv:2605.06110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the Sixteenth International Conference on Machine Learning , pages=
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping , author=. Proceedings of the Sixteenth International Conference on Machine Learning , pages=
-
[37]
Proceedings of the web conference 2021 , pages=
A trigger-sense memory flow framework for joint entity and relation extraction , author=. Proceedings of the web conference 2021 , pages=
2021
-
[38]
arXiv preprint arXiv:2309.10105 , year=
Understanding catastrophic forgetting in language models via implicit inference , author=. arXiv preprint arXiv:2309.10105 , year=
-
[39]
A survey of large language models , author=
-
[40]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[42]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[43]
International Workshop on Semantic Evaluation (SemEval-2018) , pages=
Semeval-2018 task 7: Semantic relation extraction and classification in scientific papers , author=. International Workshop on Semantic Evaluation (SemEval-2018) , pages=
2018
-
[44]
The contribution of LLMs to relation extraction in the economic field , author=. The Joint Workshop of the 9th Financial Technology and Natural Language Processing (FinNLP), the 6th Financial Narrative Processing (FNP), and the 1st Workshop on Large Language Models for Finance and Legal (LLMFinLegal) , year=
-
[45]
arXiv preprint arXiv:2305.02105 , year=
Gpt-re: In-context learning for relation extraction using large language models , author=. arXiv preprint arXiv:2305.02105 , year=
-
[46]
arXiv preprint arXiv:2310.12024 , year=
CORE: A Few-Shot Company Relation Classification Dataset for Robust Domain Adaptation , author=. arXiv preprint arXiv:2310.12024 , year=
-
[47]
arXiv preprint arXiv:2404.18085 , year=
CRE-LLM: a domain-specific Chinese relation extraction framework with fine-tuned large language model , author=. arXiv preprint arXiv:2404.18085 , year=
-
[48]
arXiv preprint arXiv:2505.01077 , year=
Zero-Shot Document-Level Biomedical Relation Extraction via Scenario-based Prompt Design in Two-Stage with LLM , author=. arXiv preprint arXiv:2505.01077 , year=
-
[49]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Bidirectional recurrent convolutional neural network for relation classification , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
arXiv preprint arXiv:2503.13939 , year=
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models , author=. arXiv preprint arXiv:2503.13939 , year=
-
[51]
arXiv preprint arXiv:2505.15817 , year=
Learning to Reason via Mixture-of-Thought for Logical Reasoning , author=. arXiv preprint arXiv:2505.15817 , year=
-
[52]
arXiv preprint arXiv:2504.03714 , year=
Breach in the Shield: Unveiling the Vulnerabilities of Large Language Models , author=. arXiv preprint arXiv:2504.03714 , year=
-
[53]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient reasoning for large language models , author=. arXiv preprint arXiv:2503.16419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Instruction-Following Evaluation for Large Language Models
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[57]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[58]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process-and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Biotechnology Advances , pages=
Advancing microbial production through artificial intelligence-aided biology , author=. Biotechnology Advances , pages=. 2024 , publisher=
2024
-
[61]
Annual Meeting of the Association for Computational Linguistics , year=
Revisiting the Negative Data of Distantly Supervised Relation Extraction , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[62]
2026 , eprint=
Semantic-Space Exploration and Exploitation in RLVR for LLM Reasoning , author=. 2026 , eprint=
2026
-
[63]
TabularMath: Understanding Math Reasoning over Tables with Large Language Models
TabularMath: Understanding Math Reasoning over Tables with Large Language Models , author=. arXiv preprint arXiv:2505.19563 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
arXiv preprint arXiv:2601.01984 , year=
Thinking with Blueprints: Assisting Vision-Language Models in Spatial Reasoning via Structured Object Representation , author=. arXiv preprint arXiv:2601.01984 , year=
-
[65]
Computation , volume=
The Health-Wealth Gradient in Labor Markets: Integrating Health, Insurance, and Social Metrics to Predict Employment Density , author=. Computation , volume=. 2026 , publisher=
2026
-
[66]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
American Invitational Mathematics Examination (
-
[68]
2026 , eprint=
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs , author=. 2026 , eprint=
2026
-
[69]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[71]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2305.11860 , year=
Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLMs , author=. arXiv preprint arXiv:2305.11860 , year=
-
[73]
arXiv preprint arXiv:2401.10480 , year=
Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning , author=. arXiv preprint arXiv:2401.10480 , year=
-
[74]
Journal of Machine Learning Research , year =
Antonin Raffin and Ashley Hill and Adam Gleave and Anssi Kanervisto and Maximilian Ernestus and Noah Dormann , title =. Journal of Machine Learning Research , year =
-
[75]
2016 , Eprint =
Greg Brockman and Vicki Cheung and Ludwig Pettersson and Jonas Schneider and John Schulman and Jie Tang and Wojciech Zaremba , Title =. 2016 , Eprint =
2016
-
[76]
arXiv preprint arXiv:2509.07980 , year=
Parallel-r1: Towards parallel thinking via reinforcement learning , author=. arXiv preprint arXiv:2509.07980 , year=
-
[77]
arXiv preprint arXiv:2509.04475 , year=
Parathinker: Native parallel thinking as a new paradigm to scale llm test-time compute , author=. arXiv preprint arXiv:2509.04475 , year=
-
[78]
2025 , month = jul, day =
Luong, Thang and Lockhart, Edward , title =. 2025 , month = jul, day =
2025
-
[79]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[80]
arXiv preprint arXiv:2503.00031 , year=
Efficient test-time scaling via self-calibration , author=. arXiv preprint arXiv:2503.00031 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.