NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Pith reviewed 2026-06-28 11:09 UTC · model grok-4.3
The pith
A generative world model trained on driving data produces real-time action-conditioned videos for closed-loop autonomous vehicle simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
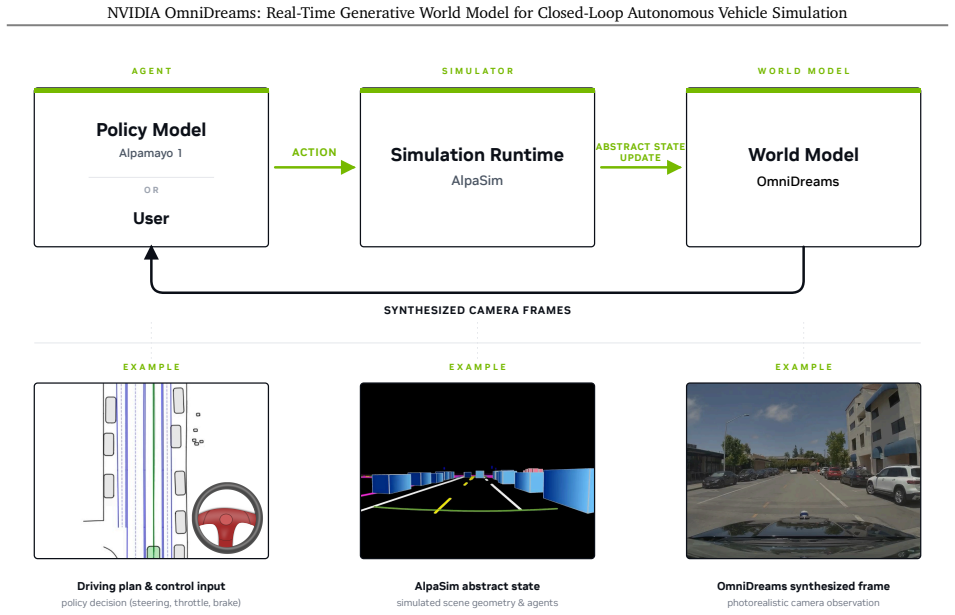
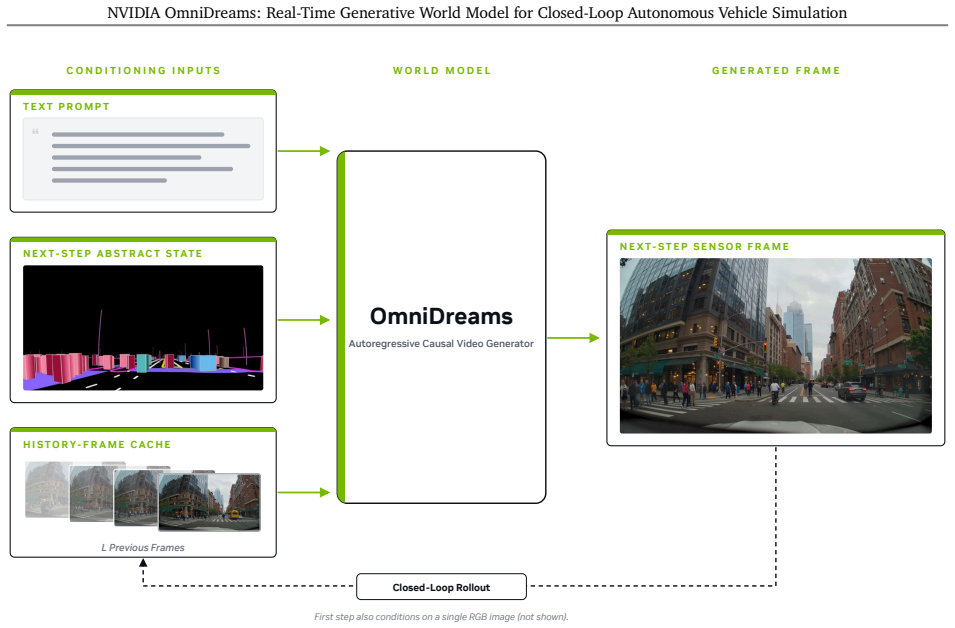
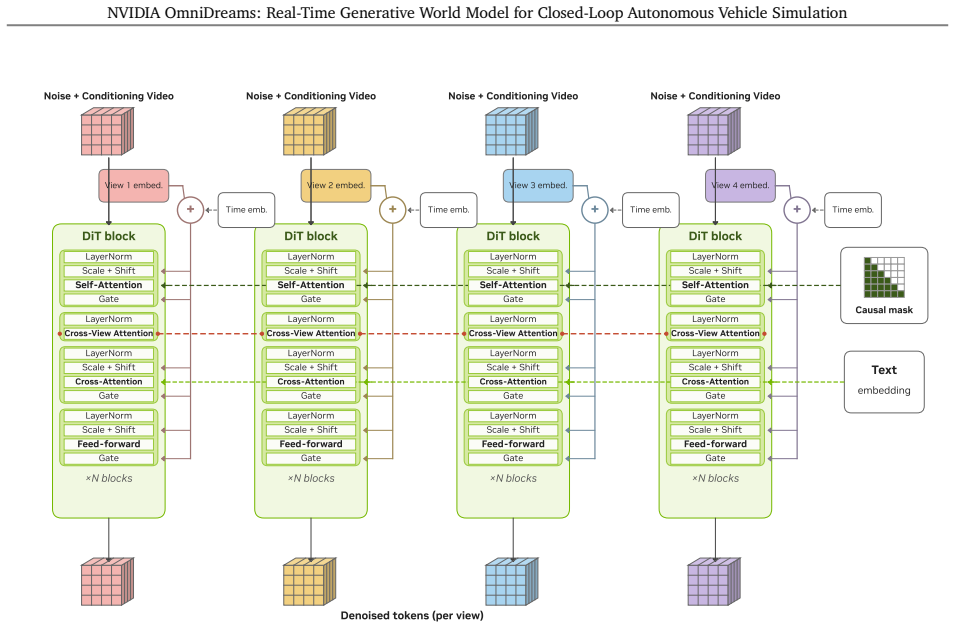
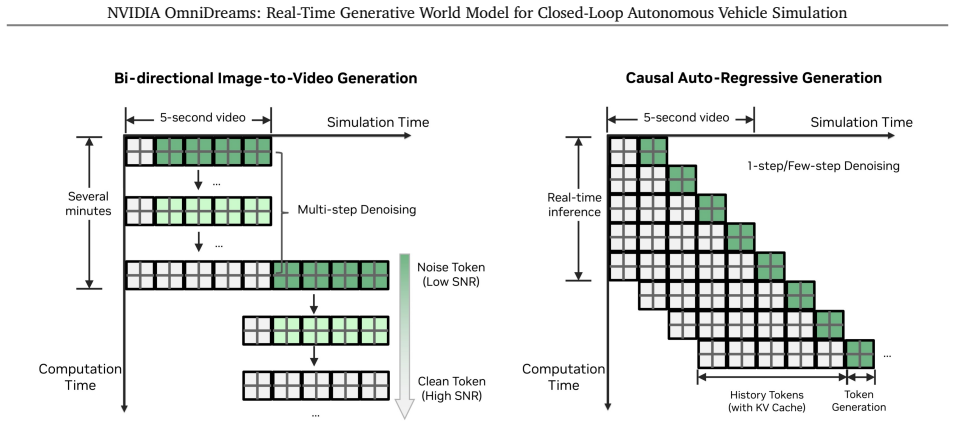
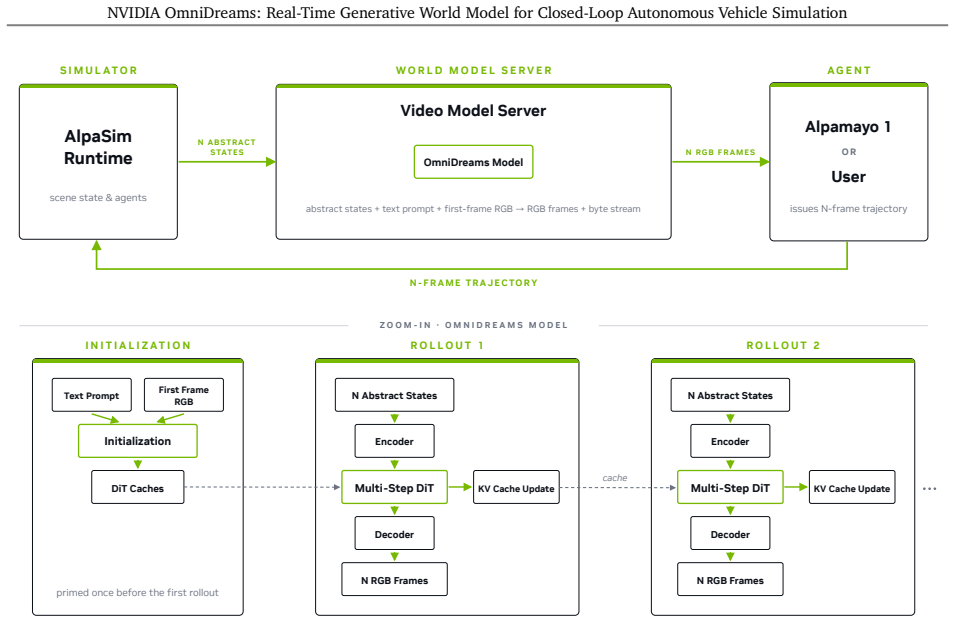
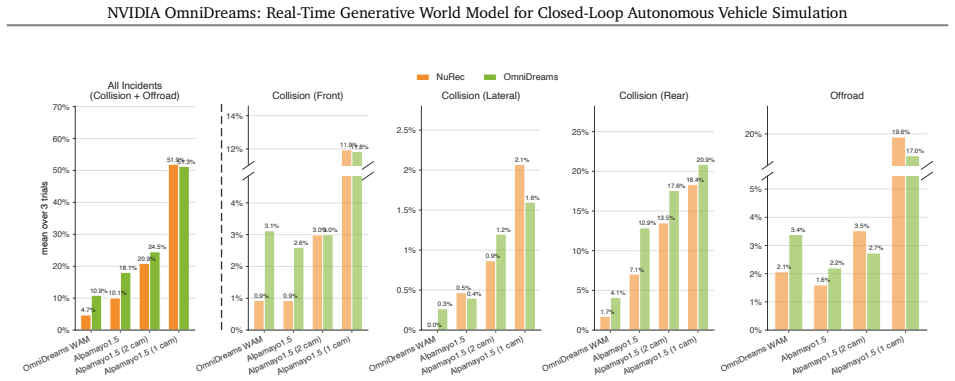
OmniDreams is a foundation generative world model mid- and post-trained from a diffusion model on 21k hours of driving scenarios to autoregressively generate action-conditioned videos in real time. By conditioning photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions, it acts as a reactive environment in closed-loop systems. It synthesizes complex unobserved phenomena such as extreme weather and unpredictable dynamic agent behaviors. A world-action model post-trained from it achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing a VLA-based model while using only one-fifth the total parameters.
What carries the argument
Autoregressive video generation conditioned on past frames, simulator state, and driving actions, which turns the model into a responsive simulator that updates based on policy choices.
If this is right
- Supports closed-loop interaction where policy actions update the simulator state and directly shape future generated observations.
- Enables synthesis of extreme weather and unpredictable agent behaviors that are hard for traditional simulators to capture.
- Provides a scalable solution for training and evaluating next-generation autonomous driving policies in long-tail scenarios.
- Allows a world-action model post-trained from it to surpass a larger VLA-based model on the NuRec dataset with one-fifth the parameters.
Where Pith is reading between the lines
- Policies could be trained on a wider range of variations than real data collection alone would permit.
- The real-time property might support online policy adaptation during simulation sessions.
- This style of generative simulator could be combined with reconstruction methods to cover both known and novel scenes.
- If dynamics remain consistent over long sequences, extended safety evaluations become feasible without additional data capture.
Load-bearing premise
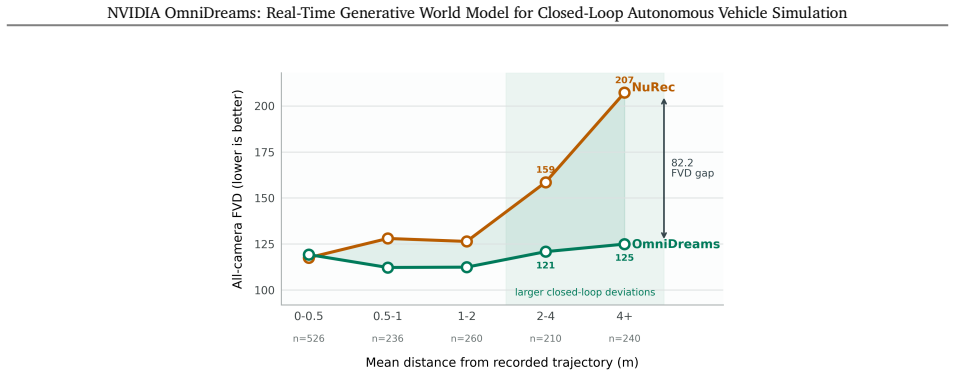
The autoregressively generated videos must faithfully capture real-world dynamics without systematic biases or hallucinations that would invalidate closed-loop policy evaluation or training.
What would settle it
A set of closed-loop rollouts where the generated videos produce policy behaviors that diverge markedly from real-vehicle outcomes on the same maneuvers, especially involving dynamic agents or weather events.
Figures








read the original abstract
As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniDreams, a real-time generative world model obtained by mid- and post-training the Cosmos diffusion model on 21k hours of driving data. It generates action-conditioned videos by conditioning on past frames, simulator state, and driving actions, and is deployed in closed-loop simulation with the Alpamayo 1 policy and AlpaSim orchestrator. The central empirical claim is that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 model while using only 1/5 the total parameters.
Significance. If the performance and fidelity claims are substantiated, the work would provide a scalable, reactive alternative to reconstruction-based simulators for long-tail AV scenarios, potentially enabling more efficient policy training and evaluation. The parameter-efficiency result, if reproducible, would be notable for policy architectures derived from world models.
major comments (2)
- [Abstract] Abstract: The headline claim that a WAM post-trained from OmniDreams surpasses Alpamayo 1.5 on NuRec while using 1/5 the parameters is presented with no numerical metrics, tables, error bars, or experimental setup details. This is load-bearing for the central performance assertion.
- [Abstract] Abstract: No quantitative validation is supplied for the core assumption that autoregressively generated videos faithfully reproduce real-world dynamics (e.g., multi-step FVD, physics-consistency scores, or closed-loop transfer gaps). Without such checks, the closed-loop policy gains cannot be distinguished from simulation artifacts.
minor comments (2)
- [Abstract] The distinction between Alpamayo 1 (used in the closed-loop system) and Alpamayo 1.5 (used in the comparison) is introduced without a clear reference or section explaining the difference.
- [Abstract] The phrase 'preliminary results' is used without indicating the section or figure where the supporting data appear.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the abstract requires strengthening with concrete metrics and validation details to support the central claims. We will revise the manuscript accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that a WAM post-trained from OmniDreams surpasses Alpamayo 1.5 on NuRec while using 1/5 the parameters is presented with no numerical metrics, tables, error bars, or experimental setup details. This is load-bearing for the central performance assertion.
Authors: We agree that the abstract as currently written does not include the supporting numerical results. The full manuscript contains the detailed NuRec evaluation (including exact scores, parameter counts, and setup) showing the WAM outperforming Alpamayo 1.5. In revision we will move key quantitative results and error-bar information into the abstract while preserving its length constraints, and we will add a brief reference to the experimental protocol. revision: yes
-
Referee: [Abstract] Abstract: No quantitative validation is supplied for the core assumption that autoregressively generated videos faithfully reproduce real-world dynamics (e.g., multi-step FVD, physics-consistency scores, or closed-loop transfer gaps). Without such checks, the closed-loop policy gains cannot be distinguished from simulation artifacts.
Authors: We acknowledge that the abstract does not report these fidelity metrics. The body of the paper describes the closed-loop deployment with Alpamayo 1 and AlpaSim but does not yet include the requested quantitative checks. We will add a dedicated paragraph (or table) reporting multi-step FVD, physics-consistency scores, and closed-loop transfer-gap measurements on held-out driving sequences to substantiate the claim that policy improvements arise from faithful dynamics rather than artifacts. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and context describe an empirical model (OmniDreams) mid- and post-trained on 21k hours of driving data from a base Cosmos diffusion model, deployed in closed-loop simulation, with a preliminary performance claim on the NuRec dataset. No equations, derivations, or load-bearing steps are present that reduce by construction to self-definition, fitted inputs renamed as predictions, or self-citation chains. The central claims are training-based and comparative rather than mathematical reductions equivalent to their inputs. Per the criteria, this is a self-contained empirical presentation with no exhibited circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 5, 27
Pith/arXiv arXiv 2025
-
[2]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sher- lock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael...
2024
-
[3]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 6
Pith/arXiv arXiv 2023
-
[4]
Jake Bruce, Michael D. Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder...
2024
-
[5]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 11, 28, 37
2024
-
[6]
PufferDrive: A fast and friendly driving simulator for training and evaluating RL agents, 2025
Daphne Cornelisse, Spencer Cheng, Pragnay Mandavilli, Julian Hunt, Kevin Joseph, Waël Doulazmi, Valentin Charraut, Aditya Gupta, Joseph Suarez, and Eugene Vinitsky. PufferDrive: A fast and friendly driving simulator for training and evaluating RL agents, 2025. URLhttps://github.com/Emerge-Lab/ PufferDrive. 28
2025
-
[7]
Riccardo de Lutio, Tobias Fischer, Yen-Yu Chang, Yuxuan Zhang, Jay Zhangjie Wu, Xuanchi Ren, Tian- chang Shen, Katarina Tothova, Zan Gojcic, and Haithem Turki. Artifixer: Enhancing and extending 3d reconstruction with auto-regressive diffusion models.arXiv preprint arXiv:2603.00492, 2026. 19
Pith/arXiv arXiv 2026
-
[8]
Veo 3: Higher-quality video generation with audio and speech, 2025
Google DeepMind. Veo 3: Higher-quality video generation with audio and speech, 2025. 8, 27
2025
-
[9]
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. Flex attention: A programming model for generating optimized attention kernels.arXiv preprint arXiv:2412.05496, 2(3):4, 2024. 12
Pith/arXiv arXiv 2024
-
[10]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InConference on Robot Learning (CoRL), 2017. 28
2017
-
[11]
MagicDrive: Street view generation with diverse 3d geometry control
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. MagicDrive: Street view generation with diverse 3d geometry control. InInternational Conference on Learning Representations (ICLR), 2024. 28
2024
-
[12]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 28 31 NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Ve...
2024
-
[13]
Co-Reyes, Rishabh Agarwal, Rebecca Roelofs, Yao Lu, Nico Montali, Paul Mougin, Zoey Yang, Brandyn White, Aleksandra Faust, Rowan McAllister, Dragomir Anguelov, and Benjamin Sapp
Cole Gulino, Justin Fu, Wenjie Luo, George Tucker, Eli Bronstein, Yiren Lu, Jean Harb, Xinlei Pan, Yan Wang, Xiangyu Chen, John D. Co-Reyes, Rishabh Agarwal, Rebecca Roelofs, Yao Lu, Nico Montali, Paul Mougin, Zoey Yang, Brandyn White, Aleksandra Faust, Rowan McAllister, Dragomir Anguelov, and Benjamin Sapp. Waymax: An accelerated, data-driven simulator f...
-
[14]
StreamingT2V: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Daniil Hayrapetyan, Hayk Poghosyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. StreamingT2V: Consistent, dynamic, and extendable long video generation from text. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 28
2025
-
[15]
GAIA-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. GAIA-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023. 28
Pith/arXiv arXiv 2023
-
[16]
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 12, 15, 28, 37
Pith/arXiv arXiv 2025
-
[17]
Open-Fusion: Real-time open-vocabulary 3d mapping and queryable scene rep- resentation
Wei-Chih Hung, Vincent Casser, Henrik Kretzschmar, Jyh-Jing Hwang, and Dragomir Anguelov. Let-3d-ap: Longitudinal error tolerant 3d average precision for camera-only 3d detection. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8272–8279, 2024. doi: 10.1109/ICRA57147.2024. 10609986. 20, 37
-
[18]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023. URLhttps: //repo-sam.inria.fr/fungraph/3d-gaussian-splatting/. 26
2023
-
[19]
FIFO-Diffusion: Generating infinite videos from text without training
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. FIFO-Diffusion: Generating infinite videos from text without training. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 28
2024
-
[20]
DriveGAN: Towards a Controllable High-Quality Neural Simulation
Seung Wook Kim, Jonah Philion, Antonio Torralba, and Sanja Fidler. DriveGAN: Towards a Controllable High-Quality Neural Simulation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2021. 28
2021
-
[21]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022. 28
2022
-
[22]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. BEVFormer: Learning Bird’s-Eye-View representation from multi-camera images via spatiotemporal transformers, 2022. URLhttps://arxiv.org/abs/2203.17270. 20
arXiv 2022
-
[23]
Lightx2v: Light video generation inference framework
LightX2V. Lightx2v: Light video generation inference framework. https://github.com/ModelTC/ lightx2v, 2025. 13
2025
-
[24]
Ring attention with blockwise transformers for near-infinite context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context. InInternational Conference on Learning Representations (ICLR), 2024. 14, 28, 37
2024
-
[25]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 10, 37
Pith/arXiv arXiv 2022
-
[26]
LATR: 3d lane detection from monocular images with transformer, 2023
Yueru Luo, Chaoda Zheng, Xu Yan, Kun Tang, Chao Zheng, Shuguang Cui, and Zhen Li. LATR: 3d lane detection from monocular images with transformer, 2023. URLhttps://arxiv.org/abs/2308.04583. 20 32 NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
arXiv 2023
-
[27]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV, 2020. 26
2020
-
[28]
3d gaussian ray tracing: Fast tracing of particle scenes.ACM Transactions on Graphics and SIGGRAPH Asia, 2024
Nicolas Moenne-Loccoz, Ashkan Mirzaei, Or Perel, Riccardo de Lutio, Janick Martinez Esturo, Gavriel State, Sanja Fidler, Nicholas Sharp, and Zan Gojcic. 3d gaussian ray tracing: Fast tracing of particle scenes.ACM Transactions on Graphics and SIGGRAPH Asia, 2024. 26
2024
-
[29]
Graph.41, 4, Article 62 (July 2022), 16 pages
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM Trans. Graph., 41(4):102:1–102:15, July 2022. doi: 10.1145/ 3528223.3530127. URLhttps://doi.org/10.1145/3528223.3530127. 26
-
[30]
NVIDIA Omniverse NuRec: Neural reconstruction for autonomous vehicle simulation.https: //developer.nvidia.com/omniverse/nurec, 2024
NVIDIA. NVIDIA Omniverse NuRec: Neural reconstruction for autonomous vehicle simulation.https: //developer.nvidia.com/omniverse/nurec, 2024. 4, 23, 27, 38
2024
-
[31]
CUDA C++ Programming Guide: CUDA graphs
NVIDIA. CUDA C++ Programming Guide: CUDA graphs. https://docs.nvidia.com/cuda/ cuda-c-programming-guide/index.html#cuda-graphs, 2024. 13, 37
2024
-
[32]
Physical AI autonomous vehicles NuRec dataset.https://huggingface.co/datasets/nvidia/ PhysicalAI-Autonomous-Vehicles-NuRec, October 2025
NVIDIA. Physical AI autonomous vehicles NuRec dataset.https://huggingface.co/datasets/nvidia/ PhysicalAI-Autonomous-Vehicles-NuRec, October 2025. 18, 24
2025
-
[33]
World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062,
NVIDIA. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062,
-
[34]
5, 6, 8, 9, 10, 27, 28, 37
-
[35]
AlpaSim: An open-source closed-loop autonomous vehicle simulator.https://github.com/ NVlabs/alpasim, 2025
NVIDIA. AlpaSim: An open-source closed-loop autonomous vehicle simulator.https://github.com/ NVlabs/alpasim, 2025. 5, 16, 23, 27, 28, 37
2025
-
[36]
Flashdreams: A high-performance streaming inference stack for world and video models
NVIDIA. Flashdreams: A high-performance streaming inference stack for world and video models. https://github.com/NVIDIA/flashdreams, 2026. 15
2026
-
[37]
NVIDIA. Alpamayo-R1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2026. 4, 5, 17, 23, 24, 28, 37
Pith/arXiv arXiv 2026
-
[38]
SIL-Wheel: A multi-modal search and curation platform for autonomous-vehicle video datasets
NVIDIA. SIL-Wheel: A multi-modal search and curation platform for autonomous-vehicle video datasets. NVIDIA technical report, 2026. 7, 38
2026
-
[39]
Video generation models as world simulators.Technical Report, 2024
OpenAI. Video generation models as world simulators.Technical Report, 2024. 8, 27
2024
-
[40]
WorldEngine: Towards the era of post-training for physical ai, 2026
OpenDriveLab. WorldEngine: Towards the era of post-training for physical ai, 2026. URL https: //github.com/OpenDriveLab/WorldEngine. 28
2026
-
[41]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, VasuSharma,Shang-WenLi,WojciechGaluba,MikeRabbat,MidoAssran,NicolasBallas,GabrielSynnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Jou...
2023
-
[42]
Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024. 8, 27
Pith/arXiv arXiv 2024
-
[43]
Cosmos-Drive-Dreams: Scalable synthetic driving data generation with world foundation models
Xuanchi Ren, Tianshi Cao, Amirmojtaba Sabour, Tianchang Shen, Yifan Lu, Ruiyuan Gao, Tobias Pfaff, Jay Zhangjie Wu, Seung Wook Kim, Shengyu Huang, Laura Leal-Taixé, Jun Gao, Huan Ling, and Sanja Fidler. Cosmos-Drive-Dreams: Scalable synthetic driving data generation with world foundation models. arXiv preprint arXiv:2506.09042, 2025. 4, 5, 28, 37 33 NVIDI...
arXiv 2025
-
[44]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. GAIA-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025. 28
Pith/arXiv arXiv 2025
-
[45]
Paul D Sampson. Fitting conic sections to “very scattered” data: An iterative refinement of the bookstein algorithm.Computer Graphics and Image Processing, 18(1):97–108, 1982. ISSN 0146-664X. doi: https://doi.org/10.1016/0146-664X(82)90101-0. URL https://www.sciencedirect.com/science/ article/pii/0146664X82901010. 20
-
[46]
Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2
Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3626–3636, 2022. 20
2022
-
[47]
Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models.arXiv preprint arXiv:26...
Pith/arXiv arXiv 2026
-
[48]
NeuRAD: Neural rendering for autonomous driving
Adam Tonderski, Carl Lindström, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. NeuRAD: Neural rendering for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 26
2024
-
[49]
Simuli: Real-time lidar and camera simulation with unscented transforms
Haithem Turki, Qi Wu, Janick Martinez Esturo, Shengyu Huang, Ruilong Li, Zan Gojcic, Xin Kang, and Riccardo de Lutio. Simuli: Real-time lidar and camera simulation with unscented transforms. In International Conference on Learning Representations (ICLR), 2026. 27
2026
-
[50]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 8, 15, 27
Pith/arXiv arXiv 2025
-
[51]
DriveDreamer: Towards real-world-driven world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. DriveDreamer: Towards real-world-driven world models for autonomous driving. InEuropean Conference on Computer Vision (ECCV), 2024. 28
2024
-
[52]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 28
2024
-
[53]
The Waymo World Model: A new frontier for au- tonomous driving simulation
Waymo. The Waymo World Model: A new frontier for au- tonomous driving simulation. https://waymo.com/blog/2026/02/ the-waymo-world-model-a-new-frontier-for-autonomous-driving-simulation, 2026. 28
2026
-
[54]
Jay Zhangjie Wu, Xuanchi Ren, Tianchang Shen, Tianshi Cao, Kai He, Yifan Lu, Ruiyuan Gao, Enze Xie, Shiyi Lan, Jose M Alvarez, et al. Chronoedit: Towards temporal reasoning for image editing and world simulation.arXiv preprint arXiv:2510.04290, 2025. 22
arXiv 2025
-
[55]
Difix3d+: Improving 3d reconstructions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. Difix3d+: Improving 3d reconstructions with single-step diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26024–26035,
-
[56]
3dgut: Enabling distorted cameras and secondary rays in gaussian splatting.Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Qi Wu, Janick Martinez Esturo, Ashkan Mirzaei, Nicolas Moenne-Loccoz, and Zan Gojcic. 3dgut: Enabling distorted cameras and secondary rays in gaussian splatting.Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 26 34 NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
2025
-
[57]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024. 28
2024
-
[58]
EmerNeRF: Emergent spatial-temporal scene decomposition via self-supervision
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, and Yue Wang. EmerNeRF: Emergent spatial-temporal scene decomposition via self-supervision. InInternational Conference on Learning Representations (ICLR), 2024. 27
2024
-
[59]
Generalized predictive model for autonomous driving
Jiazhi Yang, Shenyuan Gao, Yihang Qiu, Li Chen, Tianyu Li, Bo Dai, Kashyap Chitta, Penghao Wu, Jia Zeng, Ping Luo, Jun Zhang, Andreas Geiger, Yu Qiao, and Hongyang Li. Generalized predictive model for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 28
2024
-
[60]
Xuemeng Yang, Licheng Wen, Yukai Ma, Jianbiao Mei, Xin Li, Tiantian Wei, Wenjie Lei, Daocheng Fu, Pinlong Cai, Min Dou, Botian Shi, Liang He, Yong Liu, and Yu Qiao. Drivearena: A closed-loop generative simulation platform for autonomous driving.arXiv preprint arXiv:2408.00415, 2024. 28
arXiv 2024
-
[61]
World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 5, 18
Pith/arXiv arXiv 2026
-
[62]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024. 12, 28, 37
2024
-
[63]
Freeman, Frédo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Frédo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 28
2025
-
[64]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089, 2025. 28
Pith/arXiv arXiv 2025
-
[65]
Yuxuan Zhang, Katarína Tóthová, Zian Wang, Kangxue Yin, Haithem Turki, Riccardo de Lutio, Yen-Yu Chang, Or Litany, Sanja Fidler, and Zan Gojcic. Diffusionharmonizer: Bridging neural reconstruction and photorealistic simulation with online diffusion enhancer.arXiv preprint arXiv:2602.24096, 2026. 19
arXiv 2026
-
[66]
Hongyu Zhou, Longzhong Lin, Jiabao Wang, Yichong Lu, Dongfeng Bai, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. Hugsim: A real-time, photo-realistic and closed-loop simulator for autonomous driving.arXiv preprint arXiv:2412.01718, 2024. 28
arXiv 2024
-
[67]
Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, and Tianfan Xue. FlashVSR: Towards real-time diffusion-based streaming video super-resolution.arXiv preprint arXiv:2510.12747, 2025. 28 35 NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation B. Glossary This whitepaper draws on terminology from...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.