GLINT: Sparsely Gated Vision-Language Alignment for Fine-Grained Radiology Representations
Pith reviewed 2026-06-28 10:55 UTC · model grok-4.3
The pith
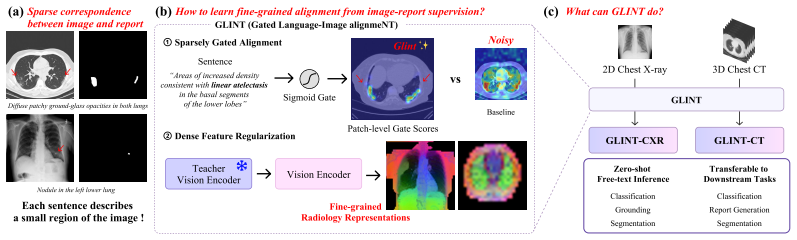
GLINT uses a sigmoid gate to select only text-relevant patches for fine-grained radiology alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
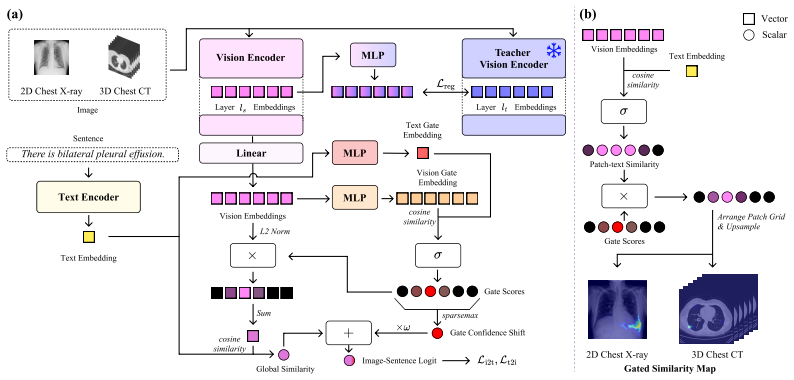
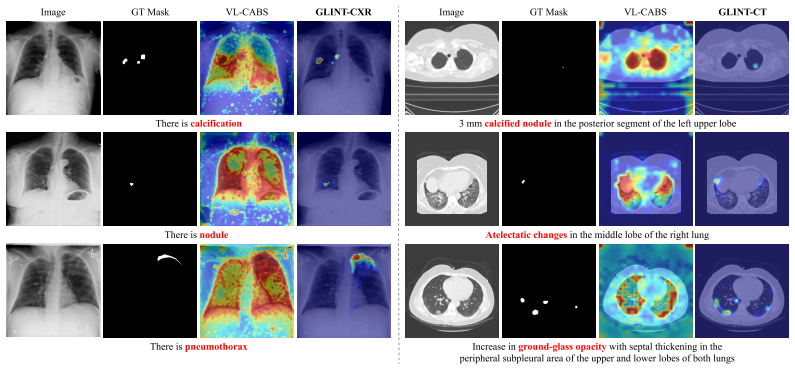
GLINT demonstrates that a sigmoid gate over a separate gate embedding space, combined with dense feature regularization to a frozen SSL teacher, produces fine-grained representations that enable zero-shot classification, grounding, and segmentation from free-text queries; the method is the first to achieve zero-shot segmentation on 3D CT volumes without mask supervision and yields the largest improvements precisely on localization tasks.
What carries the argument
Sparsely Gated Alignment, a sigmoid gate computed over a separate gate embedding space that activates only the patches relevant to each textual query.
If this is right
- Zero-shot segmentation on 3D CT volumes becomes possible without any mask supervision.
- Performance improves over both SSL encoders and prior medical VLMs on classification, report generation, and segmentation.
- The largest gains appear on zero-shot grounding and segmentation, where query-specific localization is required.
- The same gated alignment recipe applies to both 2D chest X-rays and 3D chest CT using appropriate SSL teachers.
Where Pith is reading between the lines
- The explicit sparsity could make model decisions more interpretable by revealing which patches drive each text query.
- The same gating approach might transfer to other imaging modalities where findings are also spatially sparse.
- Preserving intermediate patch features appears necessary once sparsity is introduced into the alignment objective.
Load-bearing premise
The sigmoid gate will reliably select the sparse subset of patches that match a given textual query while the dense regularization keeps the fine-grained patch features the gate needs.
What would settle it
A held-out 3D CT test set in which zero-shot segmentation or grounding performance does not exceed that of standard medical VLMs or in which the activated patches fail to match the anatomic regions described in the reports.
Figures
read the original abstract
Vision-language models (VLMs) for radiology have emerged as a scalable paradigm by leveraging image-report pairs naturally produced in clinical workflows. However, this pairing reveals a mismatch in scale: each finding occupies only a small region of the image, yet supervision is provided only at the global image-report level. This poses a central challenge: prior approaches spread weight densely across all patches rather than concentrating on the sparse subset relevant to a given query. To address this, we present GLINT (Gated Language-Image alignmeNT), a framework that explicitly models this sparse correspondence. On the alignment side, we introduce Sparsely Gated Alignment, a novel architecture in which a sigmoid gate over a separate gate embedding space activates only the patches relevant to each textual query, enforcing explicit sparsity. On the representation side, we add Dense Feature Regularization, which anchors the trainable encoder's intermediate features to a frozen self-supervised learning (SSL) teacher, preserving the fine-grained patch features that the gate relies on. The same recipe applies to both 2D chest X-ray (CXR) and 3D chest computed tomography (CT), built with DINOv3 and V-JEPA 2.1, respectively. GLINT enables zero-shot classification, grounding, and segmentation from free-text queries, and to our knowledge is the first to demonstrate zero-shot segmentation on 3D CT volumes without mask supervision. Notably, the most pronounced gains arise on zero-shot grounding and segmentation, where sparse, query-specific localization is required, consistent with our design intent. In downstream evaluation, GLINT outperforms both SSL encoders and medical VLMs on classification, report generation, and segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GLINT, a vision-language framework for radiology that addresses the mismatch between global image-report supervision and sparse findings by proposing Sparsely Gated Alignment (a sigmoid gate over a separate gate embedding space that activates only query-relevant patches) and Dense Feature Regularization (anchoring trainable encoder features to a frozen SSL teacher). The approach is applied to both 2D CXR (DINOv3) and 3D CT (V-JEPA 2.1), enabling zero-shot classification, grounding, and segmentation from free-text queries. It claims to be the first to demonstrate zero-shot segmentation on 3D CT volumes without mask supervision and to outperform SSL encoders and medical VLMs, with the largest gains on grounding and segmentation tasks.
Significance. If the central claims hold after verification, the work would advance fine-grained medical VLMs by explicitly enforcing sparse text-image correspondence rather than relying on dense attention, which is particularly relevant for localization-heavy tasks like grounding and segmentation in radiology. The consistent recipe across 2D and 3D modalities and the use of existing SSL backbones are practical strengths.
major comments (1)
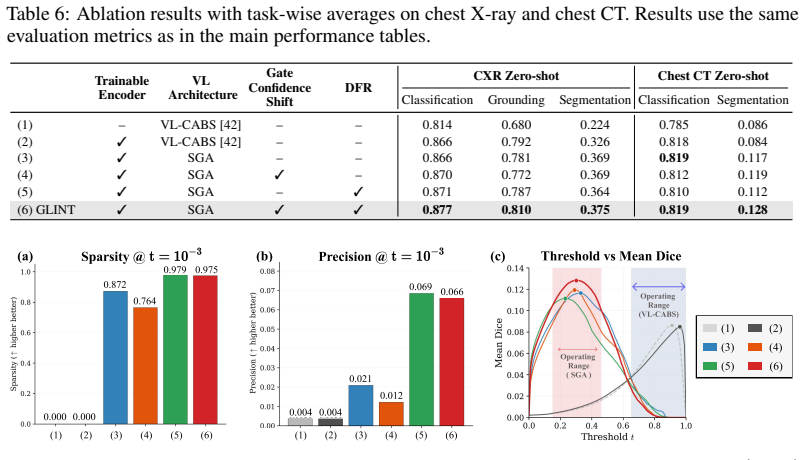
- [Abstract (Sparsely Gated Alignment and Dense Feature Regularization)] Abstract (paragraph on Sparsely Gated Alignment and Dense Feature Regularization): The strongest claims (first zero-shot 3D CT segmentation without masks; largest gains on grounding/segmentation) rest on the unverified assumption that the sigmoid gate over the separate gate embedding space will reliably select only the sparse patches relevant to each free-text query while Dense Feature Regularization preserves the fine-grained patch features the gate depends on. No ablation isolating the gate, no sparsity statistics, and no visualizations of activated patches are referenced, leaving open the possibility that performance reduces to the frozen SSL teacher plus standard contrastive loss.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's presentation of Sparsely Gated Alignment and Dense Feature Regularization. We address the concern about verification of the core claims point by point below.
read point-by-point responses
-
Referee: [Abstract (Sparsely Gated Alignment and Dense Feature Regularization)] Abstract (paragraph on Sparsely Gated Alignment and Dense Feature Regularization): The strongest claims (first zero-shot 3D CT segmentation without masks; largest gains on grounding/segmentation) rest on the unverified assumption that the sigmoid gate over the separate gate embedding space will reliably select only the sparse patches relevant to each free-text query while Dense Feature Regularization preserves the fine-grained patch features the gate depends on. No ablation isolating the gate, no sparsity statistics, and no visualizations of activated patches are referenced, leaving open the possibility that performance reduces to the frozen SSL teacher plus standard contrastive loss.
Authors: We agree that the abstract paragraph would be strengthened by explicit pointers to the supporting analyses. The full manuscript contains these elements in the main body: Section 4.2 reports controlled ablations that isolate the sigmoid gate (comparing the full model against a variant using only standard contrastive loss on the trainable encoder without the gate embedding space), with statistically significant drops in zero-shot grounding IoU and segmentation Dice when the gate is removed. Section 4.3 quantifies sparsity via per-query activation rates (mean 9.4% of patches activated on CXR and 7.8% on CT, with standard deviation reported), and Figure 6 visualizes gate outputs for representative free-text queries, showing query-specific sparse activation rather than dense or uniform patterns. These controls demonstrate that gains on localization tasks exceed what is obtained from the frozen SSL teacher plus contrastive loss alone. We will revise the abstract to cite these sections and the figure. revision: yes
Circularity Check
No circularity: explicit new architecture with no reduction to fitted inputs or self-citations
full rationale
The paper introduces Sparsely Gated Alignment (sigmoid gate over separate gate embedding space) and Dense Feature Regularization as explicit architectural components to enforce sparsity and preserve fine-grained features. No equations or claims reduce a prediction to a quantity defined by the authors' prior work, no fitted parameters are renamed as predictions, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The derivation chain consists of standard contrastive alignment plus the new gating mechanism; performance claims rest on empirical evaluation rather than definitional equivalence. This is the normal case of an independent architectural contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Sparsely Gated Alignment module with separate gate embedding space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hugo J. W. L. Aerts, Emmanuel Rios Velazquez, Ralph T. H. Leijenaar, Chintan Parmar, Patrick Grossmann, Sara Carvalho, Johan Bussink, René Monshouwer, Benjamin Haibe-Kains, Derek Rietveld, Frank Hoebers, Michelle M. Rietbergen, C. René Leemans, Andre Dekker, John Quackenbush, Robert J. Gillies, and Philippe Lambin. Decoding tumour phenotype by noninvasive...
2014
-
[2]
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[3]
Landman, Geert Litjens, Bjoern Menze, Olaf Ronneberger, Ronald M
Michela Antonelli, Annika Reinke, Spyridon Bakas, Keyvan Farahani, Annette Kopp-Schneider, Bennett A. Landman, Geert Litjens, Bjoern Menze, Olaf Ronneberger, Ronald M. Summers, Bram van Ginneken, Michel Bilello, Patrick Bilic, Patrick F. Christ, Richard K. G. Do, Marc J. Gollub, Stephan H. Heckers, Henkjan Huisman, William R. Jarnagin, Maureen K. McHugo, ...
2022
-
[4]
Samuel G Armato III, Geoffrey McLennan, Luc Bidaut, Michael F McNitt-Gray, Charles R Meyer, Anthony P Reeves, Binsheng Zhao, Denise R Aberle, Claudia I Henschke, Eric A Hoffman, et al. The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans.Medical physics, 38(2):9...
2011
-
[5]
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, X...
Pith/arXiv arXiv 2025
-
[6]
Mohammed Baharoon, Luyang Luo, Michael Moritz, Abhinav Kumar, Sung Eun Kim, Xiaoman Zhang, Miao Zhu, Mahmoud Hussain Alabbad, Maha Sbayel Alhazmi, Neel P Mistry, et al. Rexgroundingct: A 3d chest ct dataset for segmentation of findings from free-text reports.arXiv preprint arXiv:2507.22030, 2025
arXiv 2025
-
[7]
Merlin: a computed tomography vision–language foundation model and dataset.Nature, pages 1–11, 2026
Louis Blankemeier, Ashwin Kumar, Joseph Paul Cohen, Jiaming Liu, Longchao Liu, Dave Van Veen, Syed Jamal Safdar Gardezi, Hongkun Yu, Magdalini Paschali, Zhihong Chen, et al. Merlin: a computed tomography vision–language foundation model and dataset.Nature, pages 1–11, 2026
2026
-
[8]
Making the most of text semantics to improve biomedical vision–language processing
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, et al. Making the most of text semantics to improve biomedical vision–language processing. InEuropean conference on computer vision, pages 1–21. Springer, 2022
2022
-
[9]
Padchest: A large chest x-ray image dataset with multi-label annotated reports.Medical Image Analysis, 66:101797, December
Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria de la Iglesia-Vayá. Padchest: A large chest x-ray image dataset with multi-label annotated reports.Medical Image Analysis, 66:101797, December
-
[10]
doi: 10.1016/j.media.2020.101797
ISSN 1361-8415. doi: 10.1016/j.media.2020.101797
-
[11]
Boosting vision semantic density with anatomy normality modeling for medical vision-language pre-training
Weiwei Cao, Jianpeng Zhang, Zhongyi Shui, Sinuo Wang, Zeli Chen, Xi Li, Le Lu, Xianghua Ye, Qi Zhang, Tingbo Liang, et al. Boosting vision semantic density with anatomy normality modeling for medical vision-language pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23041–23050, 2025
2025
-
[12]
M Jorge Cardoso, Wenqi Li, Richard Brown, Nic Ma, Eric Kerfoot, Yiheng Wang, Benjamin Murrey, Andriy Myronenko, Can Zhao, Dong Yang, et al. Monai: An open-source framework for deep learning in healthcare.arXiv preprint arXiv:2211.02701, 2022. 10
Pith/arXiv arXiv 2022
-
[13]
Generating radiology reports via memory- driven transformer
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory- driven transformer. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 1439–1449, 2020
2020
-
[14]
Radiology: Artificial Intelligence3(2), e200254 (Mar 2021)
Errol Colak, Felipe C. Kitamura, Stephen B. Hobbs, Carol C. Wu, Matthew P. Lungren, Luciano M. Prevedello, Jayashree Kalpathy-Cramer, Robyn L. Ball, George Shih, Anouk Stein, Safwan S. Halabi, Emre Altinmakas, Meng Law, Parveen Kumar, Karam A. Manzalawi, Dennis Charles Nelson Rubio, Jacob W. Sechrist, Pauline Germaine, Eva Castro Lopez, Tomas Amerio, Push...
-
[15]
Improving the Factual Correctness of Radiology Report Generation with Semantic Rewards
Jean-Benoit Delbrouck, Pierre Chambon, Christian Bluethgen, Emily Tsai, Omar Almusa, and Curtis Langlotz. Improving the factual correctness of radiology report generation with semantic rewards. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computa- tional Linguistics: EMNLP 2022, pages 4348–4360, Abu Dhabi, Un...
-
[16]
Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, Mar
Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, Steven E Shooshan, Louis Rodriguez, Sameer Antani, George R Thoma, and Clement J McDonald. Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, Mar
-
[17]
doi: 10.1093/jamia/ocv080
-
[18]
Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems
Michael Denkowski and Alon Lavie. Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems. InProceedings of the Sixth Workshop on Statistical Machine Translation, WMT ’11, page 85–91, USA, 2011. Association for Computational Linguistics. ISBN 9781937284121
2011
-
[19]
Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes.Medical image analysis, 67:101857, 2021
Rachel Lea Draelos, David Dov, Maciej A Mazurowski, Joseph Y Lo, Ricardo Henao, Geoffrey D Rubin, and Lawrence Carin. Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes.Medical image analysis, 67:101857, 2021
2021
-
[20]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
2018
-
[21]
CRG score: A distribution-aware clinical metric for radiology report generation
Ibrahim Ethem Hamamci, Sezgin Er, Suprosanna Shit, Hadrien Reynaud, Bernhard Kainz, and Bjoern Menze. CRG score: A distribution-aware clinical metric for radiology report generation. InMedical Imaging with Deep Learning - Short Papers, 2025
2025
-
[22]
Generalist foundation models from a multimodal dataset for 3d computed tomography.Nature Biomedical Engineering, pages 1–19, 2026
Ibrahim Ethem Hamamci, Sezgin Er, Chenyu Wang, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Dogan, Omer Faruk Durugol, Benjamin Hou, Suprosanna Shit, et al. Generalist foundation models from a multimodal dataset for 3d computed tomography.Nature Biomedical Engineering, pages 1–19, 2026
2026
-
[23]
Roth, and Daguang Xu
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger R. Roth, and Daguang Xu. UNETR: Transformers for 3D medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 574–584, 2022
2022
-
[24]
Gloria: A multimodal global- local representation learning framework for label-efficient medical image recognition
Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. Gloria: A multimodal global- local representation learning framework for label-efficient medical image recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3942–3951, 2021
2021
-
[25]
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y . Ng. Chexpert: A large chest radiogr...
-
[26]
Nat Methods18(2), 203–211 (Feb 2021)
Fabian Isensee, Paul F. Jaeger, Simon A. A. Kohl, Jens Petersen, and Klaus H. Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation.Nature Methods, 18(2): 203–211, 2021. doi: 10.1038/s41592-020-01008-z
-
[27]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019. 11
2019
-
[28]
Video pretraining advances 3d deep learning on chest ct tasks
Alexander Ke, Shih-Cheng Huang, Chloe P O’Connell, Michal Klimont, Serena Yeung, and Pranav Rajpurkar. Video pretraining advances 3d deep learning on chest ct tasks. InMedical Imaging with Deep Learning, pages 758–774. PMLR, 2024
2024
-
[29]
Fine-tuning can distort pretrained features and underperform out-of-distribution
Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. InInternational Conference on Learning Representations, 2022
2022
-
[30]
Carzero: Cross-attention alignment for radiology zero-shot classification
Haoran Lai, Qingsong Yao, Zihang Jiang, Rongsheng Wang, Zhiyang He, Xiaodong Tao, and S Kevin Zhou. Carzero: Cross-attention alignment for radiology zero-shot classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11137–11146, 2024
2024
-
[31]
UniCLIP: Unified framework for contrastive language-image pre-training
Janghyeon Lee, Jongsuk Kim, Hyounguk Shon, Bumsoo Kim, Seung Hwan Kim, Honglak Lee, and Junmo Kim. UniCLIP: Unified framework for contrastive language-image pre-training. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[32]
A structure- aware relation network for thoracic diseases detection and segmentation.IEEE Transactions on Medical Imaging, 40(8):2042–2052, 2021
Jie Lian, Jingyu Liu, Shu Zhang, Kai Gao, Xiaoqing Liu, Dingwen Zhang, and Yizhou Yu. A structure- aware relation network for thoracic diseases detection and segmentation.IEEE Transactions on Medical Imaging, 40(8):2042–2052, 2021
2042
-
[33]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics
2004
-
[34]
Mingquan Lin, Gregory Holste, Song Wang, Yiliang Zhou, Yishu Wei, Imon Banerjee, Pengyi Chen, Tianjie Dai, Yuexi Du, Nicha C. Dvornek, Yuyan Ge, Zuwei Guo, Shouhei Hanaoka, Dongkyun Kim, Pablo Messina, Yang Lu, Denis Parra, Donghyun Son, Álvaro Soto, Aisha Urooj, René Vidal, Yosuke Yamagishi, Pingkun Yan, Zefan Yang, Ruichi Zhang, Yang Zhou, Leo Anthony C...
-
[35]
Medical Image Analysis42, 60–88 (Dec 2017).https: //doi.org/10.1016/j.media.2017.07.005
Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Arnaud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A.W.M. van der Laak, Bram van Ginneken, and Clara I. Sánchez. A survey on deep learning in medical image analysis.Medical Image Analysis, 42:60–88, 2017. ISSN 1361-8415. doi: https://doi.org/10.1016/j.media.2017.07.005
-
[36]
Jingyu Liu, Jie Lian, and Yizhou Yu. Chestx-det10: Chest x-ray dataset on detection of thoracic abnormali- ties.arXiv preprint arXiv:2006.10550, 2020
arXiv 2006
-
[37]
TIPS: Text-Image Pretraining with Spatial Awareness
Kevis-Kokitsi Maninis, Kaifeng Chen, Soham Ghosh, Arjun Karpur, Koert Chen, Ye Xia, Bingyi Cao, Daniel Salz, Guangxing Han, Jan Dlabal, Dan Gnanapragasam, Mojtaba Seyedhosseini, Howard Zhou, and André Araujo. TIPS: Text-Image Pretraining with Spatial Awareness. InICLR, 2025
2025
-
[38]
From softmax to sparsemax: A sparse model of attention and multi-label classification
Andre Martins and Ramon Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classification. InInternational conference on machine learning, pages 1614–1623. PMLR, 2016
2016
-
[39]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
Pith/arXiv arXiv 2026
-
[40]
Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations.Scientific Data, 9(1):429, 2022
Ha Q Nguyen, Khanh Lam, Linh T Le, Hieu H Pham, Dat Q Tran, Dung B Nguyen, Dung D Le, Chi M Pham, Hang TT Tong, Diep H Dinh, et al. Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations.Scientific Data, 9(1):429, 2022
2022
-
[41]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[42]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[43]
Radzero3d: Bridging self-supervised video models and medical vision-language alignment for zero-shot chest ct interpretation
Jonggwon Park, Kyoyun Choi, Byungmu Yoon, Hong Geun Cho, and Bumcheol Hwang. Radzero3d: Bridging self-supervised video models and medical vision-language alignment for zero-shot chest ct interpretation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6742–6749, 2025
2025
-
[44]
Radzero: Similarity-based cross- attention for explainable vision-language alignment in chest x-ray with zero-shot multi-task capability
Jonggwon Park, Byungmu Yoon, Soobum Kim, and Kyoyun Choi. Radzero: Similarity-based cross- attention for explainable vision-language alignment in chest x-ray with zero-shot multi-task capability. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[45]
Exploring scalable medical image encoders beyond text supervision.Nature Machine Intelligence, 7(1):119–130, 2025
Fernando Perez-Garcia, Harshita Sharma, Sam Bond-Taylor, Kenza Bouzid, Valentina Salvatelli, Maxim- ilian Ilse, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Matthew P Lungren, et al. Exploring scalable medical image encoders beyond text supervision.Nature Machine Intelligence, 7(1):119–130, 2025
2025
-
[46]
Decomposing disease descriptions for enhanced pathology detection: A multi-aspect vision-language pre-training framework
Vu Minh Hieu Phan, Yutong Xie, Yuankai Qi, Lingqiao Liu, Liyang Liu, Bowen Zhang, Zhibin Liao, Qi Wu, Minh-Son To, and Johan W Verjans. Decomposing disease descriptions for enhanced pathology detection: A multi-aspect vision-language pre-training framework. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11492–11...
2024
-
[47]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[48]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine...
2021
-
[49]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, ...
-
[50]
V oxtell: Free-text promptable universal 3d medical image segmentation, 2025
Maximilian Rokuss, Moritz Langenberg, Yannick Kirchhoff, Fabian Isensee, Benjamin Hamm, Constantin Ulrich, Sebastian Regnery, Lukas Bauer, Efthimios Katsigiannopulos, Tobias Norajitra, and Klaus Maier- Hein. V oxtell: Free-text promptable universal 3d medical image segmentation, 2025
2025
-
[51]
Drafting the future: the dawn of ai report generation in radiology.Radiology, 316(1):e243378, 2025
Jarrel CY Seah, Jennifer SN Tang, and Aengus Tran. Drafting the future: the dawn of ai report generation in radiology.Radiology, 316(1):e243378, 2025
2025
-
[52]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[53]
Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia.Radiology
George Shih, Carol C Wu, Safwan S Halabi, Marc D Kohli, Luciano M Prevedello, Tessa S Cook, Arjun Sharma, Judith K Amorosa, Veronica Arteaga, Maya Galperin-Aizenberg, et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia.Radiology. Artificial intelligence, 1(1), 2019
2019
-
[54]
Large-scale and fine-grained vision-language pre-training for en- hanced CT image understanding
Zhongyi Shui, Jianpeng Zhang, Weiwei Cao, Sinuo Wang, Ruizhe Guo, Le Lu, Lin Yang, Xianghua Ye, Tingbo Liang, Qi Zhang, and Ling Zhang. Large-scale and fine-grained vision-language pre-training for en- hanced CT image understanding. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[55]
Dinov3.arXiv preprint arXiv:2508.10104, 2025
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[56]
Chexbert: Combining automatic labelers and expert annotations for accurate radiology report labeling using bert
Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Y Ng, and Matthew P Lungren. Chexbert: Combining automatic labelers and expert annotations for accurate radiology report labeling using bert. InEMNLP 2020-2020 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, pages 1500–1519, 2020. 13
2020
-
[57]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[58]
Tassilo Wald, Ibrahim Ethem Hamamci, Yuan Gao, Sam Bond-Taylor, Harshita Sharma, Maximilian Ilse, Cynthia Lo, Olesya Melnichenko, Noel CF Codella, Maria Teodora Wetscherek, et al. Comprehensive language-image pre-training for 3d medical image understanding.arXiv preprint arXiv:2510.15042, 2025
arXiv 2025
-
[59]
Multi-granularity cross- modal alignment for generalized medical visual representation learning
Fuying Wang, Yuyin Zhou, Shujun Wang, Varut Vardhanabhuti, and Lequan Yu. Multi-granularity cross- modal alignment for generalized medical visual representation learning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[60]
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M. Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3462–3471, 2017. doi: 10.1109/CVPR.2017.369
-
[61]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, volume 2022, page 3876, 2022
2022
-
[62]
S.K. Warfield, K.H. Zou, and W.M. Wells. Simultaneous truth and performance level estimation (staple): an algorithm for the validation of image segmentation.IEEE Transactions on Medical Imaging, 23(7): 903–921, 2004. doi: 10.1109/TMI.2004.828354
-
[63]
Totalsegmentator: robust segmentation of 104 anatomic structures in ct images.Radiology: Artificial Intelligence, 5(5):e230024, 2023
Jakob Wasserthal, Hanns-Christian Breit, Manfred T Meyer, Maurice Pradella, Daniel Hinck, Alexander W Sauter, Tobias Heye, Daniel T Boll, Joshy Cyriac, Shan Yang, et al. Totalsegmentator: robust segmentation of 104 anatomic structures in ct images.Radiology: Artificial Intelligence, 5(5):e230024, 2023
2023
-
[64]
Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis. InProceedings of the IEEE/CVF international conference on computer vision, pages 21372–21383, 2023
2023
-
[65]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. InProceedings of the European conference on computer vision (ECCV), pages 418–434, 2018
2018
-
[66]
A generalizable 3d framework and model for self-supervised learning in medical imaging
Tony Xu, Sepehr Hosseini, Chris Anderson, Anthony Rinaldi, Rahul G Krishnan, Anne L Martel, and Maged Goubran. A generalizable 3d framework and model for self-supervised learning in medical imaging. npj Digital Medicine, 8(1):639, 2025
2025
-
[67]
Advancing multimodal medical capabilities of gemini
Lin Yang, Shawn Xu, Andrew Sellergren, Timo Kohlberger, Yuchen Zhou, Ira Ktena, Atilla Kiraly, Faruk Ahmed, Farhad Hormozdiari, Tiam Jaroensri, et al. Advancing multimodal medical capabilities of gemini. arXiv preprint arXiv:2405.03162, 2024
arXiv 2024
-
[68]
Heeji Yoon, Jaewoo Jung, Junwan Kim, Hyungyu Choi, Heeseong Shin, Sangbeom Lim, Honggyu An, Chaehyun Kim, Jisang Han, Donghyun Kim, et al. Visual representation alignment for multimodal large language models.arXiv preprint arXiv:2509.07979, 2025
arXiv 2025
-
[69]
Infusing fine-grained visual knowledge to vision-language models
Nikolaos-Antonios Ypsilantis, Kaifeng Chen, André Araujo, and Ondrej Chum. Infusing fine-grained visual knowledge to vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4226–4235, 2025
2025
-
[70]
Chexworld: Exploring image world modeling for radiograph representation learning
Yang Yue, Yulin Wang, Chenxin Tao, Pan Liu, Shiji Song, and Gao Huang. Chexworld: Exploring image world modeling for radiograph representation learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20778–20788, 2025
2025
-
[71]
Siim-acr pneumothorax segmentation, 2019
Anna Zawacki, Carol Wu, George Shih, Julia Elliott, Mikhail Fomitchev, Mohannad Hussain, ParasLakhani, Phil Culliton, and Shunxing Bao. Siim-acr pneumothorax segmentation, 2019. Kaggle
2019
-
[72]
Lit: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18123–18133, 2022. 14
2022
-
[73]
Top-down neural attention by excitation backprop.International Journal of Computer Vision, 126(10):1084–1102, 2018
Jianming Zhang, Sarah Adel Bargal, Zhe Lin, Jonathan Brandt, Xiaohui Shen, and Stan Sclaroff. Top-down neural attention by excitation backprop.International Journal of Computer Vision, 126(10):1084–1102, 2018
2018
-
[74]
Knowledge-enhanced visual- language pre-training on chest radiology images.Nature Communications, 14(1):4542, 2023
Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Weidi Xie, and Yanfeng Wang. Knowledge-enhanced visual- language pre-training on chest radiology images.Nature Communications, 14(1):4542, 2023
2023
-
[75]
Contrastive learning of medical visual representations from paired images and text
Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. InMachine learning for healthcare conference, pages 2–25. PMLR, 2022
2022
-
[76]
Large-vocabulary segmentation for medical images with text prompts.NPJ Digital Medicine, 8(1): 566, 2025
Ziheng Zhao, Yao Zhang, Chaoyi Wu, Xiaoman Zhang, Xiao Zhou, Ya Zhang, Yanfeng Wang, and Weidi Xie. Large-vocabulary segmentation for medical images with text prompts.NPJ Digital Medicine, 8(1): 566, 2025
2025
-
[77]
Advancing radiograph representation learn- ing with masked record modeling
Hong-Yu Zhou, Chenyu Lian, Liansheng Wang, and Yizhou Yu. Advancing radiograph representation learn- ing with masked record modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[78]
There is
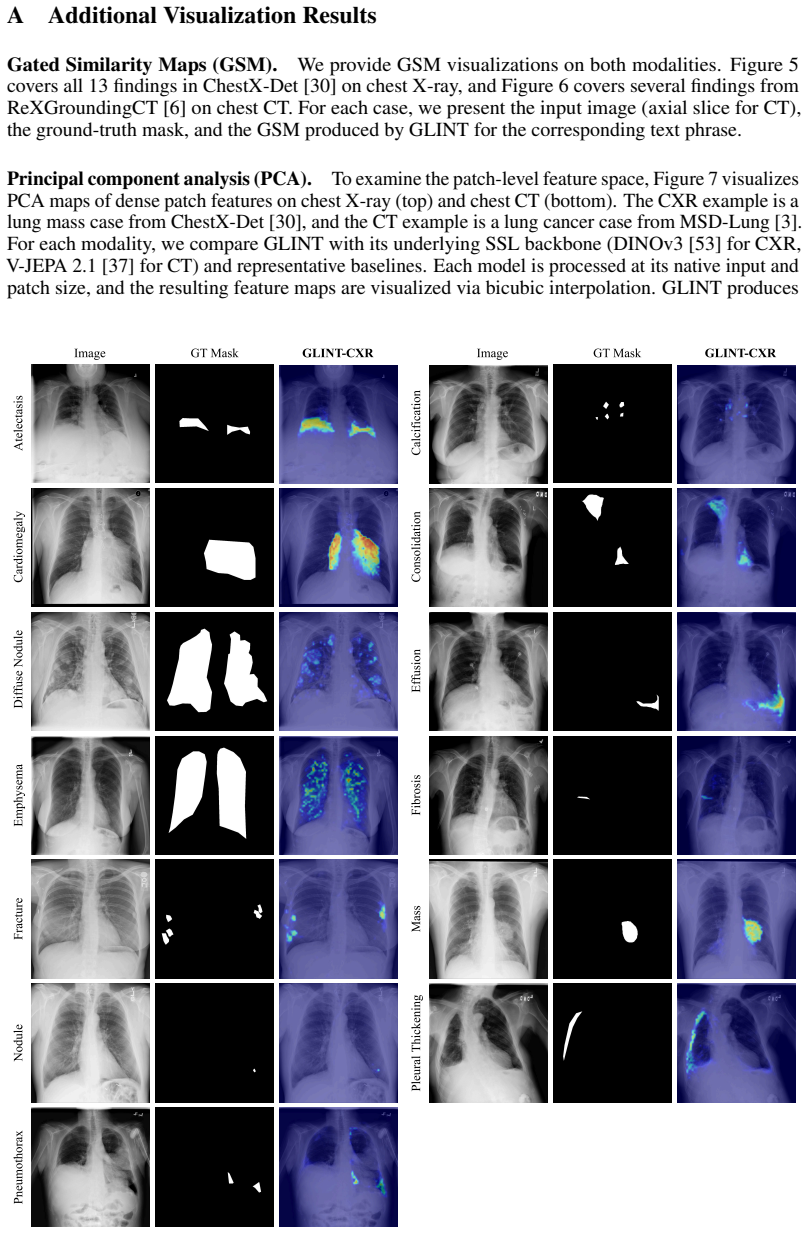
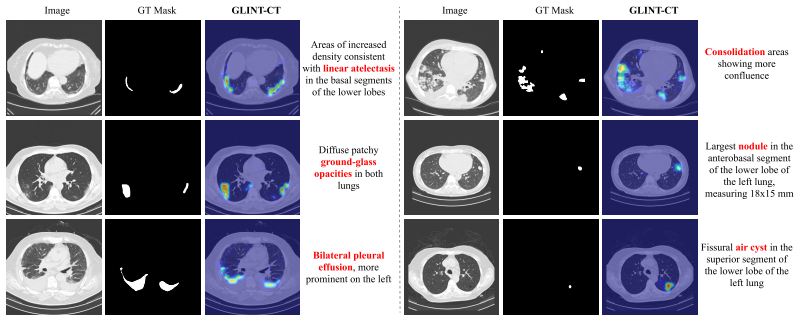
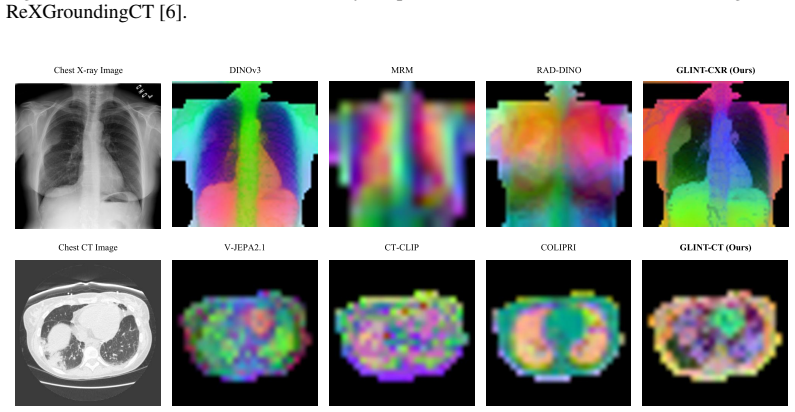
Yang Zhou, Tan Li Hui Faith, Yanyu Xu, Sicong Leng, Xinxing Xu, Yong Liu, and Rick Siow Mong Goh. Benchx: A unified benchmark framework for medical vision-language pretraining on chest x-rays. In Advances in Neural Information Processing Systems, volume 37, pages 6625–6647, 2024. 15 A Additional Visualization Results Gated Similarity Maps (GSM).We provide...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.