SplitAdapter: Load-Aware Humanoid Loco-Manipulation via Factorized Adaptation
Pith reviewed 2026-06-28 09:49 UTC · model grok-4.3
The pith
SplitAdapter uses separate load and dynamics encoders to raise humanoid loco-manipulation success under heavy objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
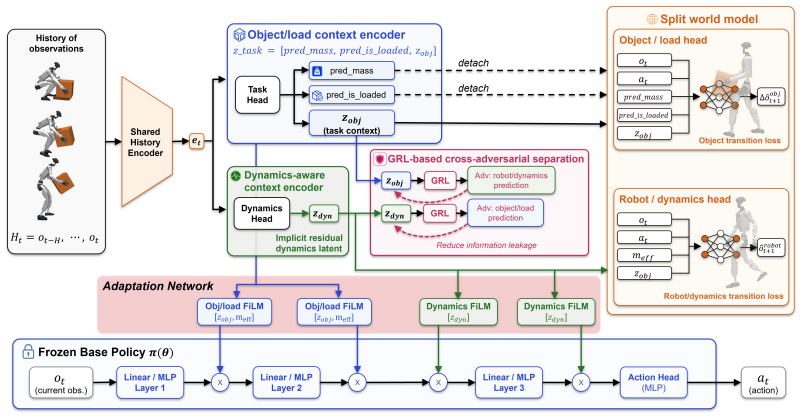
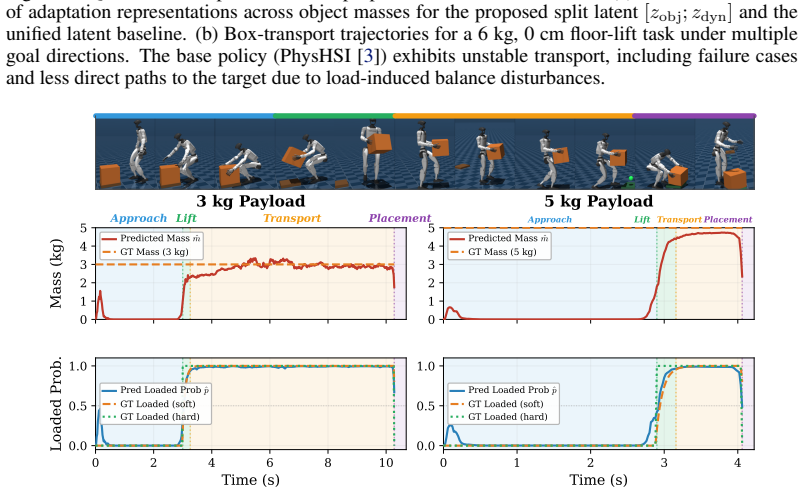
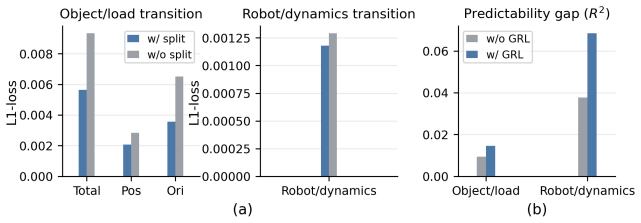
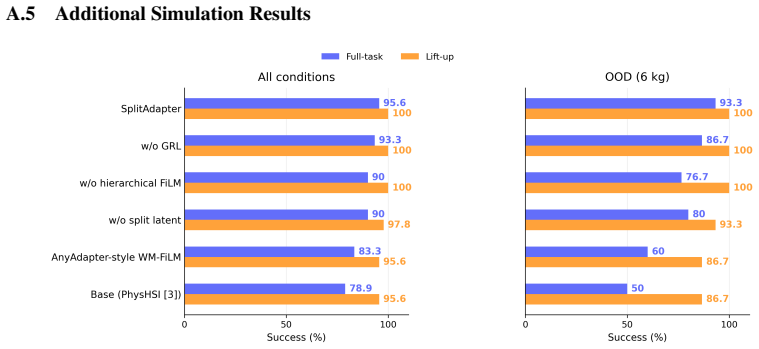
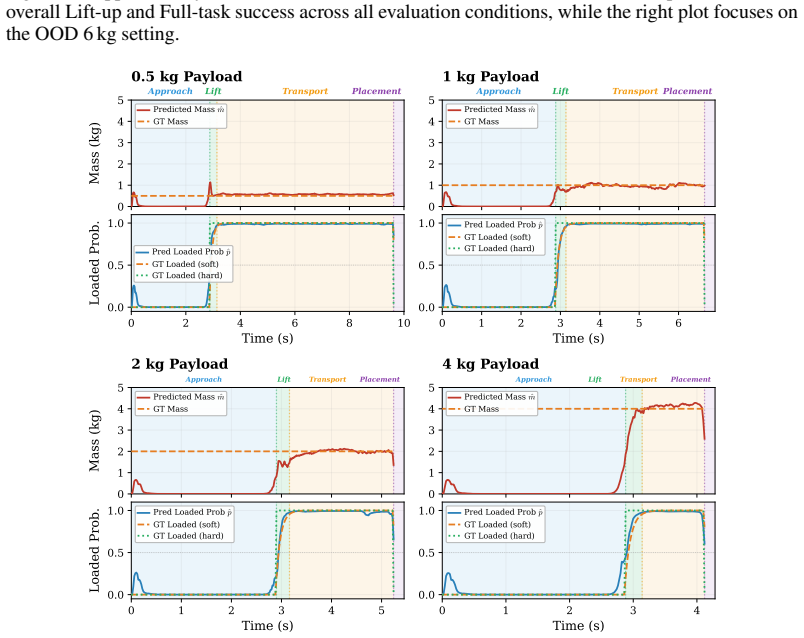
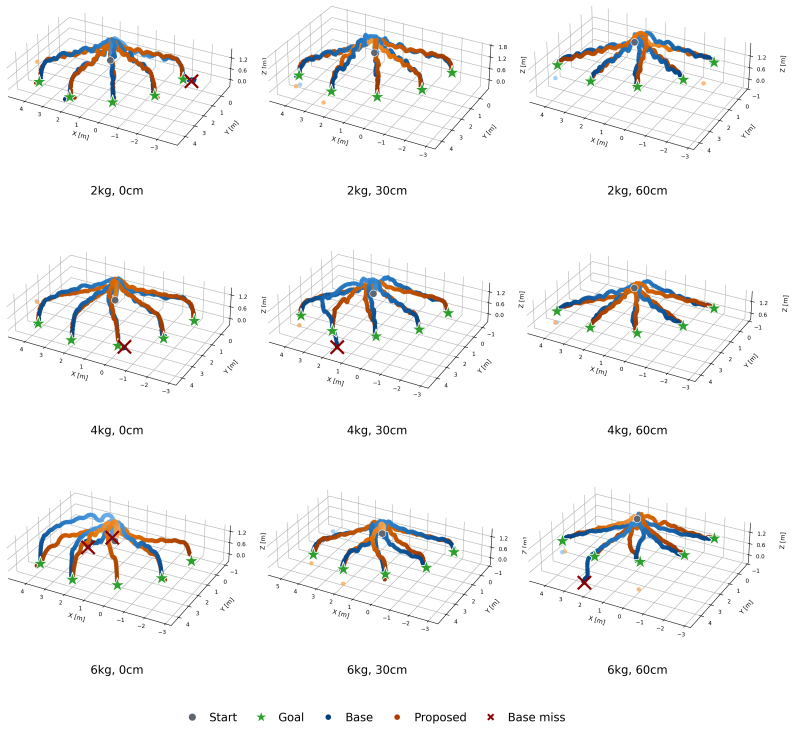
SplitAdapter freezes a pretrained box manipulation policy and augments it with object/load and dynamics-aware context encoders trained with split world-model objectives, GRL-based cross-adversarial regularization, and hierarchical Feature-wise Linear Modulation (FiLM). In sim-to-sim experiments and real-world deployment this produces higher Full-task success than the base policy and world-model FiLM baselines across object masses of 2, 4, and 6 kg and pickup/placement heights of 0, 30, and 60 cm, with the largest gains under heavy-load conditions.
What carries the argument
SplitAdapter, which applies separate load and dynamics context encoders modulated by hierarchical FiLM onto a frozen base policy.
If this is right
- Full-task success rates rise over both the base policy and unified world-model FiLM baselines.
- The largest gains occur under the heaviest tested load of 6 kg across all pickup and placement heights.
- The approach supports stable performance in both sim-to-sim and real-world loco-manipulation settings.
- The frozen base policy can be reused while only the context encoders are trained for new load or dynamics conditions.
Where Pith is reading between the lines
- The same split could let teams swap only the dynamics encoder when moving the method to a different robot body without retraining the core policy.
- Factorization may extend to other variable-payload tasks such as legged carrying or mobile manipulation where multiple disturbance sources coexist.
- Testing the encoders on continuous rather than discrete mass values would check whether the split objectives scale beyond the reported 2-6 kg range.
Load-bearing premise
The split encoders and regularization will stay stable and effective when object-induced load changes interact with robot dynamics mismatch during physical contact in sim-to-real transfer.
What would settle it
Real-world trials in which success with 6 kg objects at 60 cm height falls to or below the base-policy level would falsify the claim of effective factorized adaptation.
Figures

read the original abstract
Humanoid loco-manipulation requires stable whole-body control under varying object masses and pickup/placement heights. This becomes particularly challenging in sim-to-real transfer, where object-induced load variation and robot-side dynamics mismatch interact during physical contact. Existing history-based adapters often compress these factors into a single latent representation, which can weaken robustness under heavy-load manipulation. We propose \textbf{SplitAdapter: Load-Aware Humanoid Loco-Manipulation via Factorized Adaptation}, which freezes a pretrained box manipulation policy and extends it with object/load and dynamics-aware context encoders trained with split world-model objectives, GRL-based cross-adversarial regularization, and hierarchical Feature-wise Linear Modulation (FiLM). In sim-to-sim experiments and real-world deployment, SplitAdapter improves Full-task success over the base policy and world-model FiLM baselines across object masses of $2$, $4$, and $6$ kg and pickup/placement heights of $0$, $30$, and $60$ cm, with the largest improvements under heavy-load conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SplitAdapter, a factorized adaptation method for humanoid loco-manipulation. It freezes a pretrained base policy and augments it with separate object/load-aware and dynamics-aware context encoders. These are trained using split world-model objectives, GRL-based cross-adversarial regularization, and hierarchical FiLM conditioning. The central empirical claim is that this yields higher full-task success rates than the base policy and world-model FiLM baselines in both sim-to-sim and real-world settings, across object masses of 2/4/6 kg and pickup/placement heights of 0/30/60 cm, with the largest gains under the 6 kg condition.
Significance. If the reported gains are statistically reliable and the factorization remains effective under contact, the work would offer a concrete architectural pattern for handling multiple sources of variation in sim-to-real humanoid control. The explicit separation of load and dynamics encoders plus the use of GRL to encourage disentanglement constitute a clear methodological contribution. Real-world deployment on a physical humanoid further strengthens the result relative to purely simulated studies.
major comments (1)
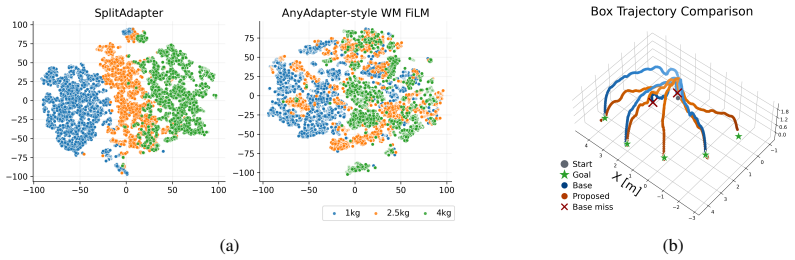
- [Experiments] Experiments section (and abstract): the reported conditions vary mass and height independently but do not isolate or stress the coupled regime in which object-induced load variation interacts with robot-side dynamics mismatch during physical contact—the exact difficulty flagged in the abstract as the core sim-to-real challenge. Without such conditions or an ablation that perturbs both factors simultaneously, it remains unclear whether the deliberate separation of encoders actually captures the interaction the method is intended to solve.
minor comments (1)
- [Abstract] Abstract: quantitative success rates, number of trials, and any statistical tests are omitted; these details belong in the abstract or a prominent results table for immediate evaluability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the reported conditions vary mass and height independently but do not isolate or stress the coupled regime in which object-induced load variation interacts with robot-side dynamics mismatch during physical contact—the exact difficulty flagged in the abstract as the core sim-to-real challenge. Without such conditions or an ablation that perturbs both factors simultaneously, it remains unclear whether the deliberate separation of encoders actually captures the interaction the method is intended to solve.
Authors: The reported experiments evaluate full-task success across all combinations of masses (2/4/6 kg) and heights (0/30/60 cm). These joint conditions require the policy to manage the interaction between load-induced effects and contact dynamics during pickup and placement. The real-world deployment on the physical humanoid further couples these load variations with inherent robot-side dynamics mismatch. We therefore maintain that the current results do stress the regime highlighted in the abstract. To provide additional explicit evidence for the value of the factorization under simultaneous perturbations, we will add a targeted sim-to-sim ablation in the revision. revision: partial
Circularity Check
No circularity in derivation chain; claims rest on empirical validation
full rationale
The provided text (abstract plus summary) contains no equations, no derivation steps, no fitted parameters presented as predictions, and no self-citations invoked as load-bearing uniqueness theorems or ansatzes. The method is described as an architectural extension (frozen base policy plus factorized encoders with split objectives, GRL, and FiLM) whose performance is asserted via sim-to-sim and real-world experiments across discrete mass/height conditions. No step reduces by construction to its own inputs; the central claims are therefore not circular but rest on external experimental outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. DeepMimic: Example-guided deep reinforcement learning of physics-based character skills.ACM Transactions on Graphics, 37(4):1–14, 2018
2018
-
[2]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. AMP: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics, 40(4):1–20, 2021
2021
- [3]
- [4]
- [5]
- [6]
- [7]
-
[8]
D. Li, X. Chen, Q. Wu, B. Chen, S. Wu, H. Wu, G. Zhang, L. Li, M. Zhou, D. Xiang, J. Ma, Q. Zhang, and R. Xu. HAIC: Humanoid agile object interaction control via dynamics-aware world model. arXiv preprint arXiv:2602.11758, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. In Robotics: Science and Systems (RSS), 2021
2021
- [10]
- [11]
- [12]
- [13]
-
[14]
Ganin and V
Y . Ganin and V . Lempitsky. Unsupervised domain adaptation by backpropagation. InProceed- ings of the International Conference on Machine Learning (ICML), 2015
2015
-
[15]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[16]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. MuJoCo: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012. 9
2012
-
[17]
Kajita, F
S. Kajita, F. Kanehiro, K. Kaneko, K. Fujiwara, K. Harada, K. Yokoi, and H. Hirukawa. Biped walking pattern generation by using preview control of zero-moment point. InIEEE Interna- tional Conference on Robotics and Automation (ICRA), 2003
2003
-
[18]
Murooka, K
M. Murooka, K. Chappellet, A. Tanguy, M. Benallegue, I. Kumagai, M. Morisawa, F. Kane- hiro, and A. Kheddar. Humanoid loco-manipulations pattern generation and stabilization con- trol.IEEE Robotics and Automation Letters, 6(3):5597–5604, 2021
2021
-
[19]
Ruscelli, M
F. Ruscelli, M. P. Polverini, A. Laurenzi, E. M. Hoffman, and N. G. Tsagarakis. A multi- contact motion planning and control strategy for physical interaction tasks using a humanoid robot. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
2020
-
[20]
J. Dao, H. Duan, and A. Fern. Sim-to-real learning for humanoid box loco-manipulation. InIEEE International Conference on Robotics and Automation (ICRA), pages 16930–16936, 2024
2024
-
[21]
A. Rigo, M. Hu, S. K. Gupta, and Q. Nguyen. Hierarchical optimization-based control for whole-body loco-manipulation of heavy objects. InIEEE International Conference on Robotics and Automation (ICRA), pages 15322–15328, 2024
2024
- [22]
-
[23]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [24]
-
[25]
S. Xu, H. Y . Ling, Y .-X. Wang, and L.-Y . Gui. InterMimic: Towards universal whole-body control for physics-based human-object interactions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
- [26]
-
[27]
Kumar, Z
A. Kumar, Z. Li, J. Zeng, D. Pathak, K. Sreenath, and J. Malik. Adapting rapid motor adap- tation for bipedal robots. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1161–1168, 2022
2022
-
[28]
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath. Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control.The International Journal of Robotics Research, 2024
2024
-
[29]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. InIEEE International Conference on Robotics and Automation (ICRA), 2018
2018
-
[30]
Pinto, M
L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel. Asymmetric actor critic for image-based robot learning. InRobotics: Science and Systems (RSS), 2018
2018
-
[31]
Makoviychuk, L
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac Gym: High performance GPU-based physics simulation for robot learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[32]
Humanoid agent AI avatar, 2024
Unitree. Humanoid agent AI avatar, 2024. URLhttps://www.unitree.com/g1. Accessed: 2026-05-22. 10 A Appendix A.1 Observation and Reward Details The frozen base policy follows the AMP-based locomotion framework of PhysHSI [3]. The policy outputs 29-D joint-position targets executed through low-level PD control. Here, we only summarize the task-specific obse...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.