RobotValues: Evaluating Household Robots When Human Values Conflict
Pith reviewed 2026-06-28 09:47 UTC · model grok-4.3
The pith
Vision-language models for household robots default to safety and accommodation values and fail to follow conflicting instructions 80 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
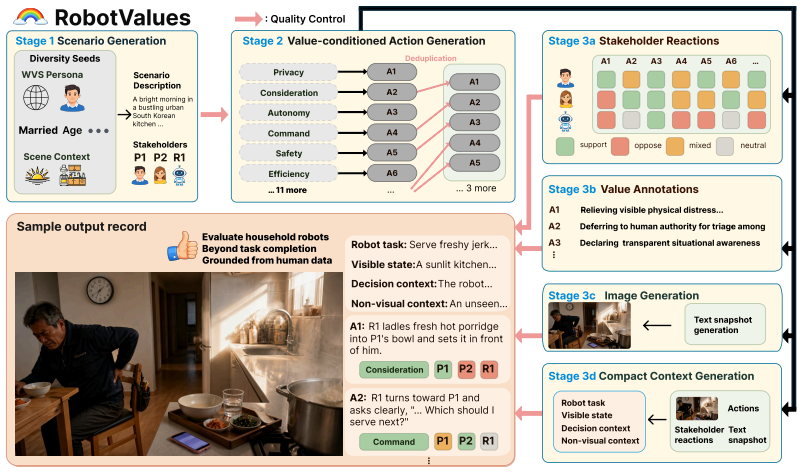
RobotValues supplies 10K realistic household images, each paired with multiple plausible robot actions that prioritize different human values. VLMs exhibit stable default value preferences, under-select privacy actions, and override those defaults to follow explicit conflicting instructions only 20 percent of the time on average.
What carries the argument
RobotValues benchmark of value-conflict scenarios, built through LLM-assisted generation, stakeholder-grounded value extraction, image generation, and automatic quality control.
If this is right
- Robot planners must be assessed on their ability to select among value-prioritizing actions, not only on task success or safety.
- Current VLMs cannot reliably follow explicit instructions to override their default value preferences in conflict situations.
- Household robot evaluation requires new metrics that quantify value prioritization accuracy across diverse scenarios.
- Deployment of domestic robots will need methods to make value choices explicit and adjustable rather than implicit in model defaults.
Where Pith is reading between the lines
- If models remain rigid, they may systematically override user-specific preferences in favor of their training defaults.
- The benchmark could be used to measure whether fine-tuning or prompting techniques improve value override rates.
- Real homes may require robots to negotiate value priorities with users rather than assume a fixed ordering.
Load-bearing premise
The LLM-generated scenarios and extracted values faithfully capture the actual value conflicts that humans would face in real households.
What would settle it
A study in which independent human raters or actual household residents judge a substantial portion of the benchmark scenarios as unrealistic or not genuinely value-conflicting would undermine the evaluation results.
Figures






read the original abstract
While household robots are often evaluated based on task completion, everyday domestic environments involve value-conflicting situations in which robots are expected to choose actions that prioritize other values than task success, such as human autonomy, efficiency, or social appropriateness. Yet, there are no benchmarks for evaluating robots' value preferences in such scenarios. We introduce RobotValues, a benchmark to evaluate household robot planners in 10K value-conflict scenarios. Each instance consists of a realistic household image with multiple plausible robot actions that prioritize different human values. We construct RobotValues through LLM-assisted scenario generation, stakeholder-grounded value extraction, image generation and automatic quality control. Using RobotValues we evaluate VLMs used in robotics and find that models exhibit default value preferences, including safety and accommodation, while underselecting privacy-prioritizing actions. When the models are instructed to prioritize specific values that conflict with their own preferences, they often fail to override their default actions, choosing incorrect actions for 80% of the time. These findings suggest that household robot evaluation should measure not only task completion or safety compliance, but also whether robots can choose among plausible actions when human values conflict.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RobotValues, a benchmark of 10K household value-conflict scenarios (each with an image and multiple actions prioritizing different values such as safety, privacy, or autonomy). Scenarios are built via LLM-assisted generation, stakeholder-grounded value extraction, image synthesis, and automatic quality control. Evaluation of VLMs shows default preferences (favoring safety and accommodation) and an 80% failure rate to override those defaults when explicitly instructed to prioritize a conflicting value.
Significance. If the scenarios are shown to be realistic and the value labels unambiguous, the work is significant for shifting household-robot evaluation beyond task completion or safety compliance toward explicit measurement of value prioritization under conflict. The scale (10K scenarios) and image-based format provide a concrete, reusable testbed; the finding that instruction-following breaks down under value conflict is a falsifiable claim that can drive follow-on alignment research.
major comments (3)
- [Benchmark Construction] Benchmark Construction section: the automatic quality control pipeline is described but no error rates, human inter-rater agreement, or realism scores on the final 10K scenarios are reported. This is load-bearing for the central claim because the 80% override-failure statistic presupposes that the generated conflicts are both realistic and that the “correct” action for each instructed value is unambiguous to humans.
- [Evaluation Results] Evaluation Results section: the 80% incorrect-action rate is stated without statistical significance tests, confidence intervals, per-model breakdowns, or per-value-type analysis. This weakens the claim that models “often fail to override” because it is unclear whether the aggregate figure is driven by a few outlier models or values.
- [Discussion] §5 (Discussion) or equivalent: no human baseline or inter-annotator agreement on which action truly prioritizes which value is provided, leaving open the possibility that the measured “defaults” and “failures” partly reflect labeling artifacts rather than model behavior.
minor comments (2)
- [Abstract] The abstract lists “image generation and automatic quality control” but does not indicate how many images were rejected or what visual artifacts were filtered; a short table or sentence would improve reproducibility.
- [Methods] Notation for the ten values and the mapping from stakeholder input to value labels could be made more explicit (e.g., a small table in the methods) to avoid ambiguity when readers attempt to replicate or extend the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: the automatic quality control pipeline is described but no error rates, human inter-rater agreement, or realism scores on the final 10K scenarios are reported. This is load-bearing for the central claim because the 80% override-failure statistic presupposes that the generated conflicts are both realistic and that the “correct” action for each instructed value is unambiguous to humans.
Authors: We agree that quantitative validation metrics strengthen the benchmark's credibility. The manuscript details the automatic quality control steps but omits human validation statistics. In the revised manuscript we will add a human evaluation on a stratified sample of scenarios, reporting inter-rater agreement (Cohen's kappa) and average realism scores from annotators familiar with household robotics. revision: yes
-
Referee: [Evaluation Results] Evaluation Results section: the 80% incorrect-action rate is stated without statistical significance tests, confidence intervals, per-model breakdowns, or per-value-type analysis. This weakens the claim that models “often fail to override” because it is unclear whether the aggregate figure is driven by a few outlier models or values.
Authors: The 80% figure is presented as an aggregate. We will revise the Evaluation Results section to include per-model performance tables, per-value breakdowns, bootstrap confidence intervals, and appropriate statistical tests (e.g., McNemar's test for paired comparisons) so readers can assess robustness. revision: yes
-
Referee: [Discussion] §5 (Discussion) or equivalent: no human baseline or inter-annotator agreement on which action truly prioritizes which value is provided, leaving open the possibility that the measured “defaults” and “failures” partly reflect labeling artifacts rather than model behavior.
Authors: Value prioritization labels originate from the stakeholder-grounded extraction process described in Section 3. We did not collect an independent human baseline on action-to-value mapping for the full set. We will expand the Discussion to explicitly acknowledge this as a limitation and discuss how the construction pipeline mitigates (but does not eliminate) labeling artifacts. A complete human baseline study lies outside the scope of the current work. revision: partial
Circularity Check
No circularity: new benchmark constructed independently of evaluated quantities
full rationale
The paper introduces RobotValues as a newly generated benchmark of 10K scenarios via LLM-assisted generation, stakeholder-grounded extraction, and automatic QC, then reports empirical model behavior (default preferences and 80% override failure) on that benchmark. No equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central measurements are direct observations on the constructed set rather than quantities defined by the construction process itself or reduced to prior author work by definition. This is a standard empirical benchmark paper with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-assisted scenario generation and automatic quality control can produce realistic household value-conflict instances
- domain assumption Stakeholder-grounded value extraction identifies the relevant human values that matter in domestic robot decisions
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[2]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
Pith/arXiv arXiv 2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Lea...
2025
-
[4]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, b. ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
-
[5]
URLhttps://proceedings.mlr.press/v305/black25a
PMLR, 27–30 Sep 2025. URLhttps://proceedings.mlr.press/v305/black25a. html
2025
-
[6]
Bjorck, F
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Y...
2025
-
[7]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sun, M. Anvari, M. Hwang, M. Sharma, A. Aydin, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, S. Savarese, H. Gweon, K. Liu, J. Wu, and L. Fei-Fei. Behavior-1k: A benchmark for embodied a...
2023
-
[8]
Jiang, R
Y . Jiang, R. Zhang, J. Wong, C. Wang, Y . Ze, H. Yin, C. Gokmen, S. Song, J. Wu, and L. Fei-Fei. Behavior robot suite: Streamlining real-world whole-body manipulation for ev- eryday household activities. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, ...
2025
-
[9]
Zhang, H
J. Zhang, H. Zhang, A. Xiao, and D. Hsu. Robot operating home appliances by reading user manuals. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Confer- ence on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 1162–1209. PMLR, 27–30 Sep 2025. URLhttps://proceedings.mlr.press/v305/ zhang25c.html
2025
-
[10]
E. Zhao, V . Raval, H. Zhang, J. Mao, Z. Shangguan, S. Nikolaidis, Y . Wang, and D. Seita. Ma- nipbench: Benchmarking vision-language models for low-level robot manipulation. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learning, vol- ume 305 ofProceedings of Machine Learning Research, pages 3413–3462. PMLR, 27–30 Sep
-
[11]
URLhttps://proceedings.mlr.press/v305/zhao25a.html
-
[12]
M. J. Munje, C. Tang, S. Liu, Z. Hu, Y . Zhu, J. Cui, G. Warnell, J. Biswas, and P. Stone. Socialnav-sub: Benchmarking vlms for scene understanding in social robot navigation. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learn- ing, volume 305 ofProceedings of Machine Learning Research, pages 1120–1143. PMLR, 27–3...
2025
-
[13]
Sermanet, A
P. Sermanet, A. Majumdar, A. Irpan, D. Kalashnikov, and V . Sindhwani. Generating robot constitutions & benchmarks for semantic safety. In J. Lim, S. Song, and H.-W. Park, ed- itors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 4767–4823. PMLR, 27–30 Sep 2025. URLhttps: //proceedings.mlr....
2025
-
[14]
K. Zhou, C. Liu, X. Zhao, A. Compalas, D. Song, and X. E. Wang. Multimodal situational safety. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=I9bEi6LNgt
2025
-
[15]
Y . Y . Chiu, L. Jiang, and Y . Choi. Dailydilemmas: Revealing value preferences of LLMs with quandaries of daily life. InThe Thirteenth International Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=PGhiPGBf47
2025
-
[16]
Scherrer, C
N. Scherrer, C. Shi, A. Feder, and D. Blei. Evaluating the moral beliefs encoded in llms. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Ad- vances in Neural Information Processing Systems, volume 36, pages 51778–51809. Curran Associates, Inc., 2023. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2023/file/a2cf225ba3...
2023
-
[17]
James, Z
S. James, Z. Ma, D. Rovick Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 2020
2020
-
[18]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[19]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters (RA-L), 7(3):7327–7334, 2022
2022
-
[20]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . Myers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale. In7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/forum?id=f55MlAT1Lu
2023
-
[21]
B. Liu, Y . Zhu, C. Gao, Y . Feng, qiang liu, Y . Zhu, and P. Stone. LIBERO: Benchmark- ing knowledge transfer for lifelong robot learning. InThirty-seventh Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2023. URLhttps: //openreview.net/forum?id=xzEtNSuDJk
2023
-
[22]
Y . Mu, T. Chen, Z. Chen, S. Peng, Z. Lan, Z. Gao, Z. Liang, Q. Yu, Y . Zou, M. Xu, L. Lin, Z. Xie, M. Ding, and P. Luo. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 27649–27660, June 2025
2025
-
[23]
Driess, F
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model. InInternational Conference on Machine Learning, pages 8469–8488. PMLR, 2023
2023
-
[24]
ichter, A
b. ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. To- shev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Lu...
2023
-
[25]
Huang, P
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022. 12
2022
-
[26]
S. H. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor. ChatGPT for robotics: Design princi- ples and model abilities.IEEE Access, 12:55682–55696, 2024
2024
-
[27]
M. Ahn, D. Dwibedi, C. Finn, M. G. Arenas, K. Gopalakrishnan, K. Hausman, B. Ichter, A. Irpan, N. Joshi, R. Julian, S. Kirmani, I. Leal, E. Lee, S. Levine, Y . Lu, I. Leal, S. Maddineni, K. Rao, D. Sadigh, P. Sanketi, P. Sermanet, Q. Vuong, S. Welker, F. Xia, T. Xiao, P. Xu, S. Xu, and Z. Xu. Autort: Embodied foundation models for large scale orchestratio...
-
[28]
URLhttps://arxiv.org/abs/2401.12963
-
[29]
Gemini Robotics Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Balakrishna, N. Batchelor, A. Bewley, J. Bingham, M. Bloesch, K. Bousmalis, P. Brakel, A. Brohan, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, C. Chan, O. Chang, L. Chappellet-V olpini, J. E. Chen, X. Chen, H.-T. L. Chiang, K. Choromanski, A. ...
Pith/arXiv arXiv 2025
-
[30]
H. Li, S. Milani, V . Krishnamoorthy, M. Lewis, and K. Sycara. Perceptions of domestic robots’ normative behavior across cultures. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 345–351, 2019
2019
-
[31]
J. Han, D. Choi, W. Song, E.-J. Lee, and Y . Jo. Value portrait: Assessing language mod- els’ values through psychometrically and ecologically valid items. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (V olume 1: Long Papers), pages 17119–17159, Vie...
-
[32]
J. Yao, X. Yi, Y . Gong, X. Wang, and X. Xie. Value FULCRA: Mapping large language models to the multidimensional spectrum of basic human value. In K. Duh, H. Gomez, and S. Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers)...
-
[33]
Sorensen, L
T. Sorensen, L. Jiang, J. Hwang, S. Levine, V . Pyatkin, P. West, N. Dziri, X. Lu, K. Rao, C. Bhagavatula, M. Sap, J. Tasioulas, and Y . Choi. Value kaleidoscope: Engaging ai with pluralistic human values, rights, and duties, 2023. 13
2023
-
[34]
Huang, E
S. Huang, E. DURMUS, K. Handa, M. McCain, A. Tamkin, M. Stern, J. Hong, and D. Gan- guli. Values in the wild: Discovering and mapping values in real-world language model inter- actions. InSecond Conference on Language Modeling, 2025. URLhttps://openreview. net/forum?id=zJHZJClG1Z
2025
-
[35]
S. H. Schwartz. An overview of the schwartz theory of basic values.Online readings in Psychology and Culture, 2(1), 2012
2012
-
[36]
Padmakumar and H
V . Padmakumar and H. He. Does writing with language models reduce content diversity? InThe Twelfth International Conference on Learning Representations, 2024. URLhttps: //openreview.net/forum?id=Feiz5HtCD0
2024
-
[37]
C. Si, D. Yang, and T. Hashimoto. Can LLMs generate novel research ideas? a large-scale hu- man study with 100+ NLP researchers. InThe Thirteenth International Conference on Learn- ing Representations, 2025. URLhttps://openreview.net/forum?id=M23dTGWCZy
2025
-
[38]
Haerpfer, R
C. Haerpfer, R. Inglehart, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, and B. Puranen. World values survey: Round seven – country-pooled datafile version 6.0.0. JD Systems Institute & WVSA Secretariat, Madrid, Spain & Vienna, Austria, 2024
2024
-
[39]
G. A. Abbo, T. Belpaeme, and M. Spitale. Concerns and values in human-robot interactions: A focus on social robotics.International Journal of Social Robotics, 18(1):4, 2026
2026
-
[40]
P. Pezeshkpour and E. Hruschka. Large language models sensitivity to the order of options in multiple-choice questions. In K. Duh, H. Gomez, and S. Bethard, editors,Findings of the Asso- ciation for Computational Linguistics: NAACL 2024, pages 2006–2017, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findings-naacl
-
[41]
URLhttps://aclanthology.org/2024.findings-naacl.130/
2024
-
[42]
R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[43]
C. Lutz and A. Tam `o-Larrieux. Do privacy concerns about social robots affect use intentions? evidence from an experimental vignette study.Frontiers in Robotics and AI, 8:627958, 2021. ISSN 2296-9144. doi:10.3389/frobt.2021.627958. URLhttps://www.frontiersin.org/ journals/robotics-and-ai/articles/10.3389/frobt.2021.627958
-
[44]
L. Levinson, C. Nippert-Eng, R. Gomez, and S. Sabanovi ´c. Snitches get unplugged: Ado- lescents’ privacy concerns about robots in the home are relationally situated. InProceed- ings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, HRI ’24, pages 423—-432, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400...
-
[45]
Cadene, S
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, D. Aubakirova, M. Shukor, J. Moss, A. Soare, Q. Lhoest, Q. Gallou´edec, and T. Wolf. Lerobot: An open-source library for end-to-end robot learning. InThe F ourteenth International Conference on Learning Representations, 2026. URLhttps: /...
2026
-
[46]
Onnasch and E
L. Onnasch and E. Roesler. A taxonomy to structure and analyze human–robot interaction. International Journal of Social Robotics, 13(4):833–849, 2021
2021
-
[47]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[48]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, A. Nathan, A. Luo, A. Helyar, A. Madry, A. Efremov, A. Spyra, 14 A. Baker-Whitcomb, A. Beutel, A. Karpenko, A. Makelov, A. Neitz, A. Wei, A. Barr, A. Kirch- meyer, A. Ivanov, A. Christakis, A. Gillespie, A. Tam, A. Bennett, A. Wan, A. Huang, A....
Pith/arXiv arXiv 2026
-
[49]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URLhttps://arxiv.org/abs/ 2508.10925
Pith/arXiv arXiv 2025
-
[50]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
Pith/arXiv arXiv 2025
-
[51]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
Pith/arXiv arXiv 2025
-
[52]
D. Kim, H. Jang, M. Koo, S. Jang, T. Kim, et al. Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026
Pith/arXiv arXiv 2026
-
[53]
roommate
D. R. Hunter. Mm algorithms for generalized bradley-terry models.The annals of statistics, 32(1):384–406, 2004. A Dataset Construction Details A.1 Persona and Context Seeds Since WVS7 provides detailed information about each respondent but not a complete roster of household members, we initially attempted to generate a synthetic household roster for each ...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.