Exploiting Verification-Generation Gap: Test-Time Reinforcement Learning with Confidence-Conditioned Verification
Pith reviewed 2026-06-28 10:50 UTC · model grok-4.3
The pith
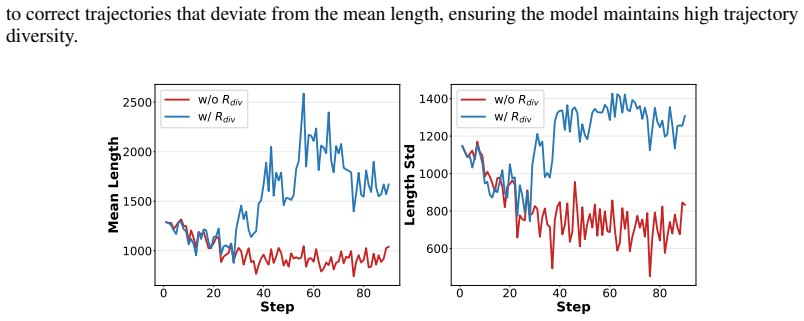
A confidence-conditioned verification framework improves label-free test-time reinforcement learning by fixing incorrect pseudo-labels on uncertain samples and restoring answer diversity on confident ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
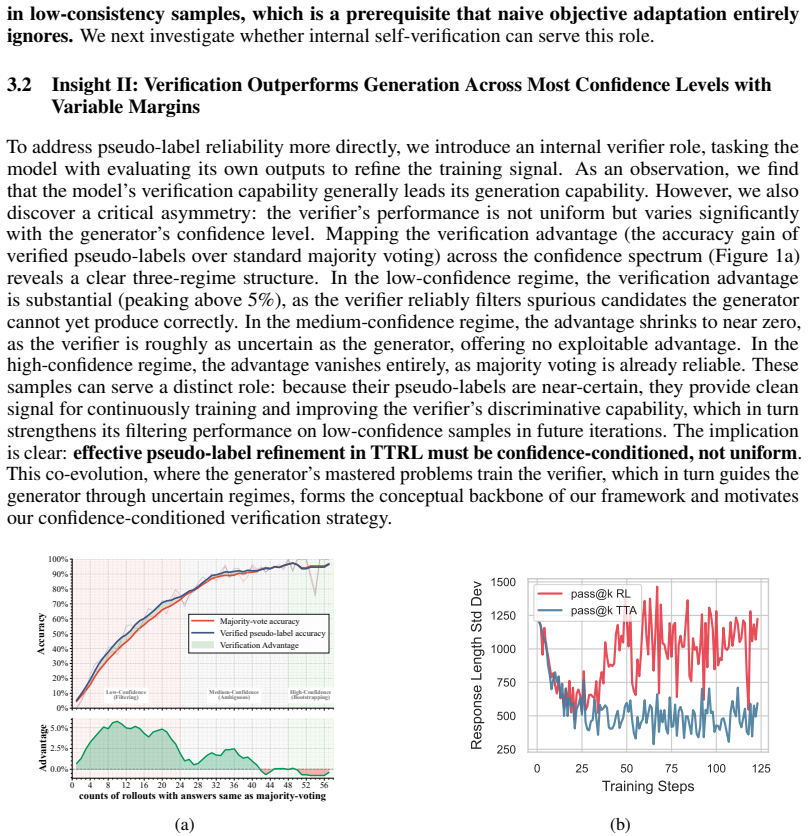
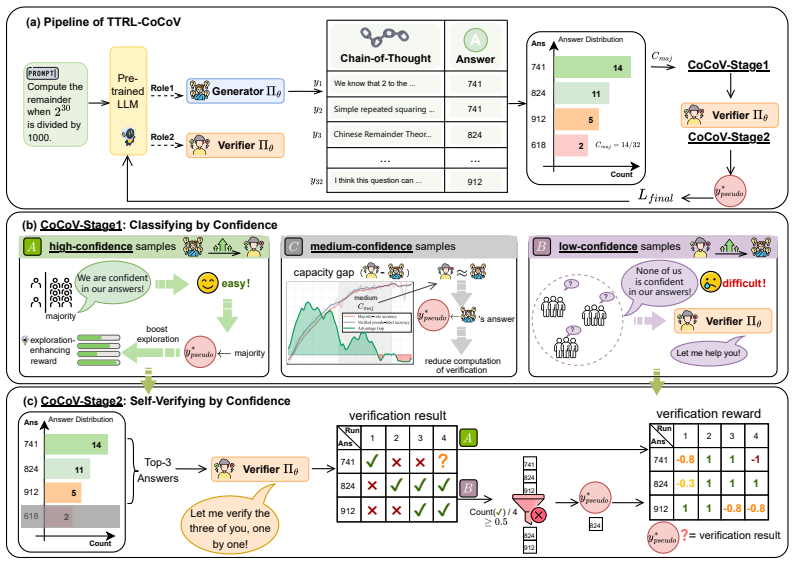
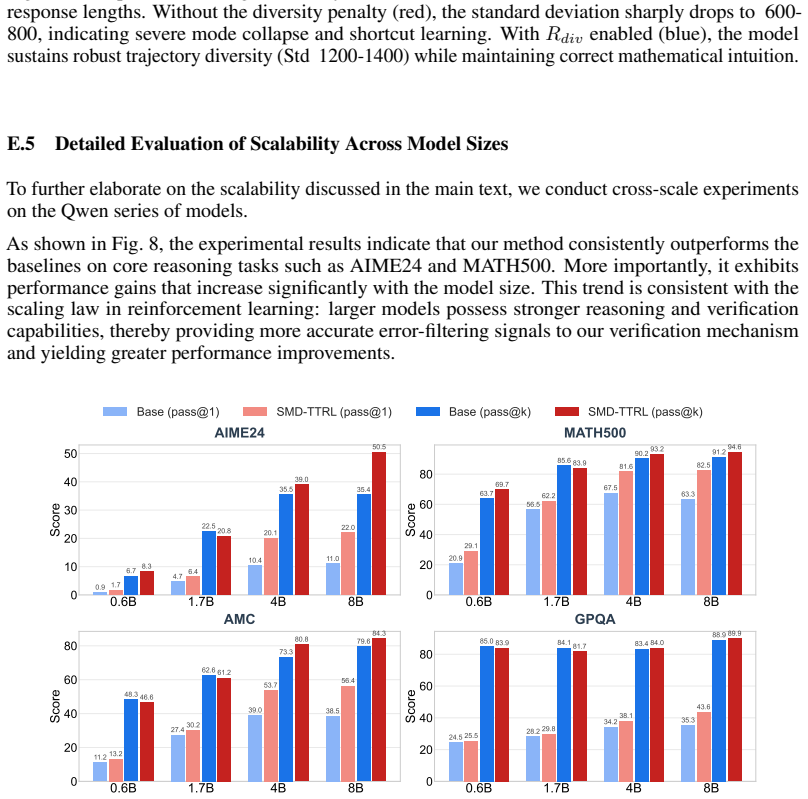
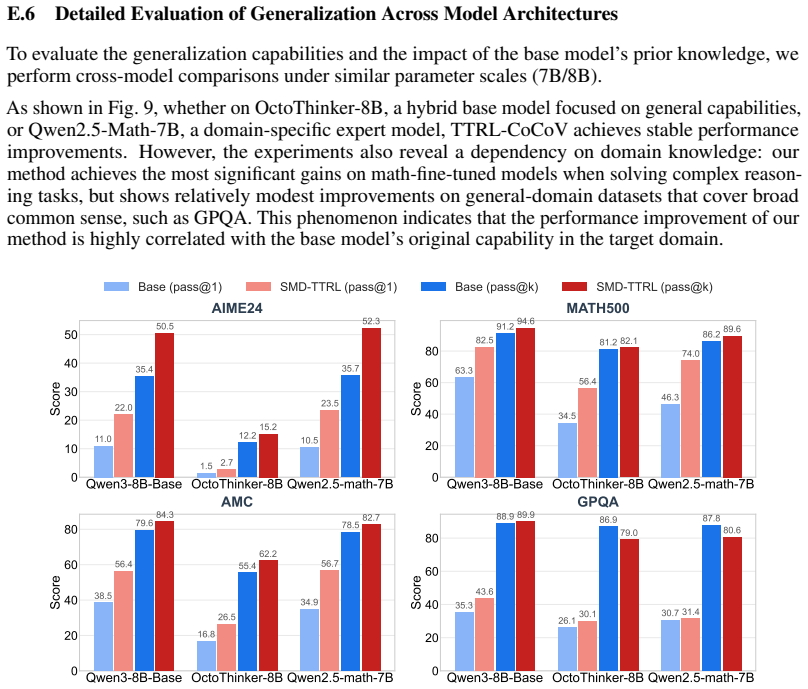
TTRL-CoCoV is a test-time RL method that, based on the premise that verification capability generally leads generation capability, applies a confidence-conditioned mechanism: high-confidence samples receive bootstrapped verification plus an exploration reward to avoid diversity collapse; low-confidence samples have pseudo-label selection delegated to the verifier to remove incorrect labels; medium-confidence samples skip verification entirely. This yields average gains of 9.8 percent Pass@1 and 18.7 percent Pass@16 over prior TTRL, and up to 5.0 percent Pass@1 over supervised RL baselines across six benchmarks.
What carries the argument
The confidence-conditioned mechanism that routes high-, low-, and medium-confidence samples to different verification and reward policies.
If this is right
- Pass@1 rises by an average absolute 9.8 percent and Pass@16 by 18.7 percent relative to standard TTRL.
- On multiple reasoning benchmarks the method exceeds the Pass@1 of fully supervised RL by up to 5.0 percent.
- Generation coverage measured by Pass@k expands while single-answer accuracy also improves.
- The same three-way confidence routing applies across six standard benchmarks without task-specific retraining.
Where Pith is reading between the lines
- If the verification-generation gap persists at larger scales, the same selective routing could be tested on non-reasoning generation tasks such as code synthesis.
- The framework suggests a general pattern in which a stronger auxiliary signal can be consulted only on the subset of cases where the primary generator is weakest.
- Future work could measure whether the required confidence thresholds remain stable when the underlying model is updated or when the verifier is drawn from a different family.
Load-bearing premise
Verification capability generally leads generation capability, allowing selective delegation to the verifier.
What would settle it
A direct comparison showing that the verifier produces more errors than the generator itself on high-confidence samples from the same model would falsify the selective bootstrapping rule.
Figures

read the original abstract
Test-time reinforcement learning has emerged as a promising paradigm for enhancing the complex reasoning abilities of large language models in a completely label-free manner. Despite existing studies focusing on Pass@1 performance, optimizing Pass@k remains under-explored yet critical in label-free settings, which measures generation coverage for sustained exploration. Optimizing Pass@k in label-free setting is highly non-trivial, as directly applying the Pass@k advantage designs effective for RLVR yields unsatisfactory performance. Through in-depth empirical analysis, we discover the root causes hindering performance: pseudo-label estimations for low-confidence samples have a high probability of being incorrect, while candidate answers for high-confidence samples suffer from severe diversity collapse. To overcome these hurdles, we propose TTRL-CoCoV (Test-Time Reinforcement Learning with Confidence-Conditioned Verification), a novel confidence-adaptive framework that expands Pass@k coverage and improves Pass@1 performance. Based on our key insight that verification capability generally leads generation capability, TTRL-CoCoV employs a confidence-conditioned mechanism: for high-confidence samples, it bootstraps verifier and applies an exploration-enhancing reward to prevent diversity collapse; for low-confidence samples, it delegates pseudo-label selection to the verifier to filter incorrect pseudo-labels; and for medium-confidence samples, it bypasses verification entirely. Extensive experiments demonstrate that TTRL-CoCoV outperforms the best competing methods across 6 widely-recognized benchmarks, achieves average absolute gains of +9.8% in Pass@1 and +18.7% in Pass@16 over TTRL, and even achieves absolute Pass@1 improvements of up to +5.0% across multiple reasoning benchmarks when compared against fully supervised RL methods. Our code repository: https://github.com/shanjf666/CoCoV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TTRL-CoCoV, a test-time RL framework for LLMs that exploits an empirical verification-generation gap. It partitions samples by confidence and routes decisions accordingly: high-confidence samples bootstrap a verifier with an exploration reward to combat diversity collapse; low-confidence samples delegate pseudo-label selection to the verifier to filter errors; medium-confidence samples bypass verification. On 6 benchmarks the method reports average absolute gains of +9.8% Pass@1 and +18.7% Pass@16 over prior TTRL, plus up to +5.0% Pass@1 versus fully supervised RL, with code released.
Significance. If the reported gains are reproducible and the verification-generation ordering proves robust, the work offers a practical, label-free route to simultaneously raise accuracy and coverage (Pass@k) in test-time reasoning optimization. The explicit code release is a clear strength for reproducibility in this empirical domain.
major comments (2)
- [Abstract] Abstract: the central routing logic rests on the claim that 'verification capability generally leads generation capability,' discovered via 'in-depth empirical analysis.' No quantitative support (verifier vs. generator accuracy curves, per-sample agreement rates, or ablation removing the confidence-conditioned routing) is supplied, yet this ordering directly determines the high-/low-confidence branches that produce the claimed +9.8% and +18.7% gains. Without such evidence the adaptive mechanism cannot be distinguished from standard TTRL.
- [Abstract] Abstract / Experiments section: the abstract asserts absolute Pass@1 improvements of up to +5.0% over fully supervised RL methods across multiple reasoning benchmarks, but supplies no details on the supervised baselines (model size, training data volume, compute budget, or whether the same base model is used). This comparison is load-bearing for the claim that TTRL-CoCoV can surpass supervised training; the absence of these controls prevents assessment of fairness.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence statement of the number of models, total samples, and statistical testing procedure used to obtain the reported averages and 'up to +5.0%' figures.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We address the major comments below and will update the manuscript to strengthen the presentation of our empirical evidence and baseline details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central routing logic rests on the claim that 'verification capability generally leads generation capability,' discovered via 'in-depth empirical analysis.' No quantitative support (verifier vs. generator accuracy curves, per-sample agreement rates, or ablation removing the confidence-conditioned routing) is supplied, yet this ordering directly determines the high-/low-confidence branches that produce the claimed +9.8% and +18.7% gains. Without such evidence the adaptive mechanism cannot be distinguished from standard TTRL.
Authors: We agree that explicit quantitative support for the verification-generation ordering should be included to substantiate the routing logic. Although the manuscript describes the in-depth empirical analysis that led to this insight, we will revise to prominently feature verifier vs. generator accuracy curves, per-sample agreement rates, and an ablation study that removes the confidence-conditioned routing. These additions will directly illustrate the contribution of the adaptive mechanism relative to standard TTRL. revision: yes
-
Referee: [Abstract] Abstract / Experiments section: the abstract asserts absolute Pass@1 improvements of up to +5.0% over fully supervised RL methods across multiple reasoning benchmarks, but supplies no details on the supervised baselines (model size, training data volume, compute budget, or whether the same base model is used). This comparison is load-bearing for the claim that TTRL-CoCoV can surpass supervised training; the absence of these controls prevents assessment of fairness.
Authors: We acknowledge that additional details on the supervised RL baselines are required for a transparent and fair comparison. In the revised manuscript we will report model sizes, training data volumes, compute budgets, and explicitly confirm that the same base models are used, allowing readers to properly evaluate the +5.0% Pass@1 gains. revision: yes
Circularity Check
No significant circularity; empirical insight and experimental results are independent of self-referential reduction
full rationale
The paper presents TTRL-CoCoV as a confidence-adaptive framework motivated by an empirical discovery from in-depth analysis: verification capability generally leads generation capability, along with identified root causes (incorrect pseudo-labels for low-confidence samples and diversity collapse for high-confidence ones). No mathematical derivation chain, equations, or first-principles results are claimed that reduce outputs to inputs by construction. The design choices (bootstrapping verifier for high-confidence, delegating to verifier for low-confidence, bypassing for medium) are presented as responses to observed patterns rather than fitted parameters renamed as predictions or self-citations that bear the load. Performance claims rest on experiments across benchmarks, not on any self-definitional loop. This is a standard empirical method paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Verification capability generally leads generation capability
Reference graph
Works this paper leans on
-
[1]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2508.11356 , year=
Jia Liu, ChangYi He, YingQiao Lin, MingMin Yang, FeiYang Shen, and ShaoGuo Liu. Ettrl: Balancing exploration and exploitation in llm test-time reinforcement learning via entropy mechanism.arXiv preprint arXiv:2508.11356,
-
[3]
Ru Wang, Wei Huang, Qi Cao, Yusuke Iwasawa, Yutaka Matsuo, and Jiaxian Guo. Self-harmony: Learning to harmonize self-supervision and self-play in test-time reinforcement learning.arXiv preprint arXiv:2511.01191, 2025a. Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, and Dong Yu. Evolv...
-
[4]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751, 2025a. Christian Walder and Deep Karkhanis. Pass@ k policy optimization: Solving harder reinforcement learning problems.arXiv preprint ar...
-
[8]
What If Consensus Lies? Selective-Complementary Reinforcement Learning at Test Time
Dong Yan, Jian Liang, Yanbo Wang, Shuo Lu, Ran He, and Tieniu Tan. What if consensus lies? selective- complementary reinforcement learning at test time.arXiv preprint arXiv:2603.19880,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
10 Zhaoning Yu, Will Su, Leitian Tao, Haozhu Wang, Aashu Singh, Hanchao Yu, Jianyu Wang, Hongyang Gao, Weizhe Yuan, Jason Weston, et al. Restrain: From spurious votes to signals–self-driven rl with self-penalization.arXiv preprint arXiv:2510.02172, 2025a. Teng Pan, Yuchen Yan, Zixuan Wang, Ruiqing Zhang, Gaiyang Han, Wanqi Zhang, Weiming Lu, Jun Xiao, and...
-
[10]
Tool verification for test-time reinforcement learning.arXiv preprint arXiv:2603.02203,
Ruotong Liao, Nikolai Röhrich, Xiaohan Wang, Yuhui Zhang, Yasaman Samadzadeh, V olker Tresp, and Serena Yeung-Levy. Tool verification for test-time reinforcement learning.arXiv preprint arXiv:2603.02203,
-
[11]
Zhongwei Wan, Yun Shen, Zhihao Dou, Donghao Zhou, Yu Zhang, Xin Wang, Hui Shen, Jing Xiong, Chaofan Tao, Zixuan Zhong, et al. Dsdr: Dual-scale diversity regularization for exploration in llm reasoning.arXiv preprint arXiv:2602.19895,
-
[12]
arXiv preprint arXiv:2508.00410 , year=
Zizhuo Zhang, Jianing Zhu, Xinmu Ge, Zihua Zhao, Zhanke Zhou, Xuan Li, Xiao Feng, Jiangchao Yao, and Bo Han. Co-rewarding: Stable self-supervised rl for eliciting reasoning in large language models.arXiv preprint arXiv:2508.00410, 2025a. Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural ...
-
[13]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2505.21444 , year=
Sheikh Shafayat, Fahim Tajwar, Ruslan Salakhutdinov, Jeff Schneider, and Andrea Zanette. Can large reasoning models self-train?arXiv preprint arXiv:2505.21444,
-
[15]
Bodong Du, Xuanqi Huang, and Xiaomeng Li. Distribution-aware reward estimation for test-time reinforcement learning.arXiv preprint arXiv:2601.21804,
-
[16]
Large language models are better reasoners with self-verification
Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 2550–2575,
2023
-
[17]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data.arXiv preprint arXiv:2508.05004,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Jiaqi Chen, Bang Zhang, Ruotian Ma, Peisong Wang, Xiaodan Liang, Zhaopeng Tu, Xiaolong Li, and Kwan- Yee K Wong. Spc: Evolving self-play critic via adversarial games for llm reasoning.arXiv preprint arXiv:2504.19162, 2025b. Zhengxin Zhang, Chengyu Huang, Aochong Oliver Li, and Claire Cardie. Better llm reasoning via dual-play. arXiv preprint arXiv:2511.11...
-
[20]
Outcome-based exploration for LLM reasoning
Yuda Song, Julia Kempe, and Remi Munos. Outcome-based exploration for llm reasoning.arXiv preprint arXiv:2509.06941,
-
[21]
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunhe Wang. Forest-of-thought: Scaling test-time compute for enhancing llm reasoning.arXiv preprint arXiv:2412.09078,
-
[22]
11 Jianghao Wu, Yasmeen George, Jin Ye, Yicheng Wu, Daniel F Schmidt, and Jianfei Cai. Spine: Token-selective test-time reinforcement learning with entropy-band regularization.arXiv preprint arXiv:2511.17938,
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Zengzhi Wang, Fan Zhou, Xuefeng Li, and Pengfei Liu. Octothinker: Mid-training incentivizes reinforcement learning scaling.arXiv preprint arXiv:2506.20512, 2025b. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.a...
-
[26]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale, 2025.URL https://arxiv. org/abs/2503.14476, 1:2, 2025b. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Building on this, TTRL [Zuo et al., 2025] formalized majority-vote consensus over self-sampled rollouts as a general unsupervised fine-tuning paradigm
12 Appendix A Related Work Label-free test-time reinforcement learning.STaR [Zelikman et al., 2022] and SRLMs [Yuan et al., 2024] established the foundation of annotation-free self-improvement. Building on this, TTRL [Zuo et al., 2025] formalized majority-vote consensus over self-sampled rollouts as a general unsupervised fine-tuning paradigm. Subsequent ...
2022
-
[29]
Verification Result: True
This includes generator, verifier, and PPO-specific configurations. Table 3: TTRL-CoCoV Training Settings Method Hyperparameters Generatorn vote = 64 nsamples_per_prompt = 32 Top-p= 1.0 Training Temperature = 1.0 Kpass = 4 Verifier Temperature:T high = 1.0,T low = 0.6 τhigh = 0.6,τ low = 0.4 Top-Kcandidates:K high = 3,K low = 5 Top-p= 0.85 nverification_s...
2048
-
[30]
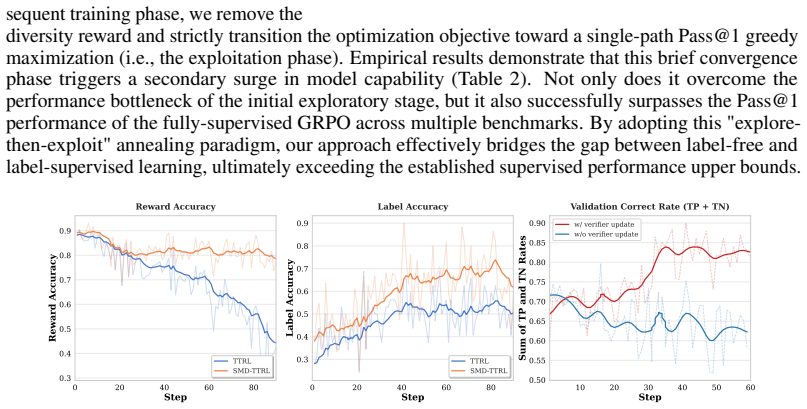
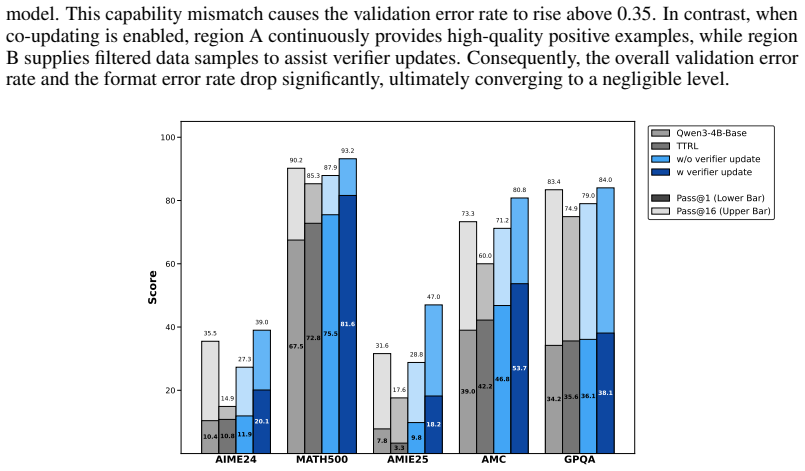
This capability mismatch causes the validation error rate to rise above 0.35
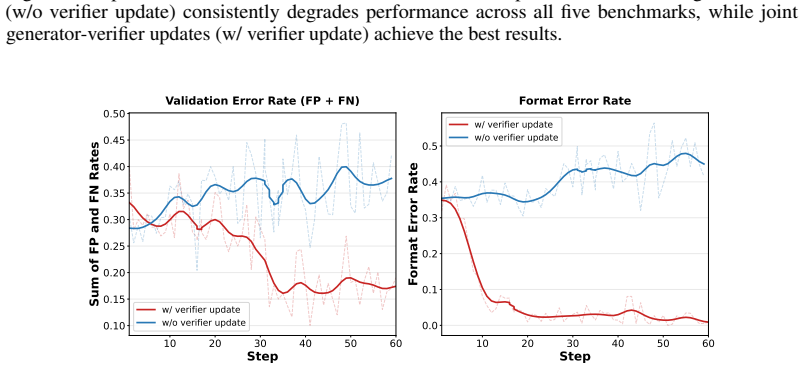
Without updating the verifier, the generator’s problem-solving ability continues to improve during fine-tuning, yet the static verifier’s discriminative upper bound remains locked at the level of the base 17 model. This capability mismatch causes the validation error rate to rise above 0.35. In contrast, when co-updating is enabled, region A continuously ...
2000
-
[31]
lenient to false negatives while strict with false positives
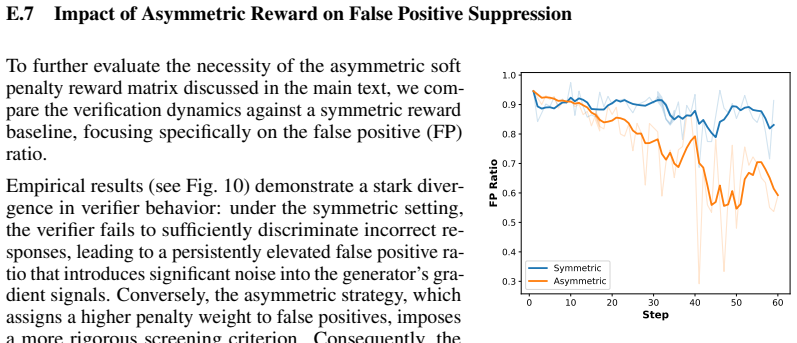
demonstrate a stark diver- gence in verifier behavior: under the symmetric setting, the verifier fails to sufficiently discriminate incorrect re- sponses, leading to a persistently elevated false positive ra- tio that introduces significant noise into the generator’s gra- dient signals. Conversely, the asymmetric strategy, which assigns a higher penalty w...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.