Tool-Aware Optimization with Entropy Guidance for Efficient Agentic Reinforcement Learning
Pith reviewed 2026-06-28 11:17 UTC · model grok-4.3
The pith
TAO-RL filters degenerate tool-use trajectories and adds entropy guidance after tool calls to stabilize agentic RL for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
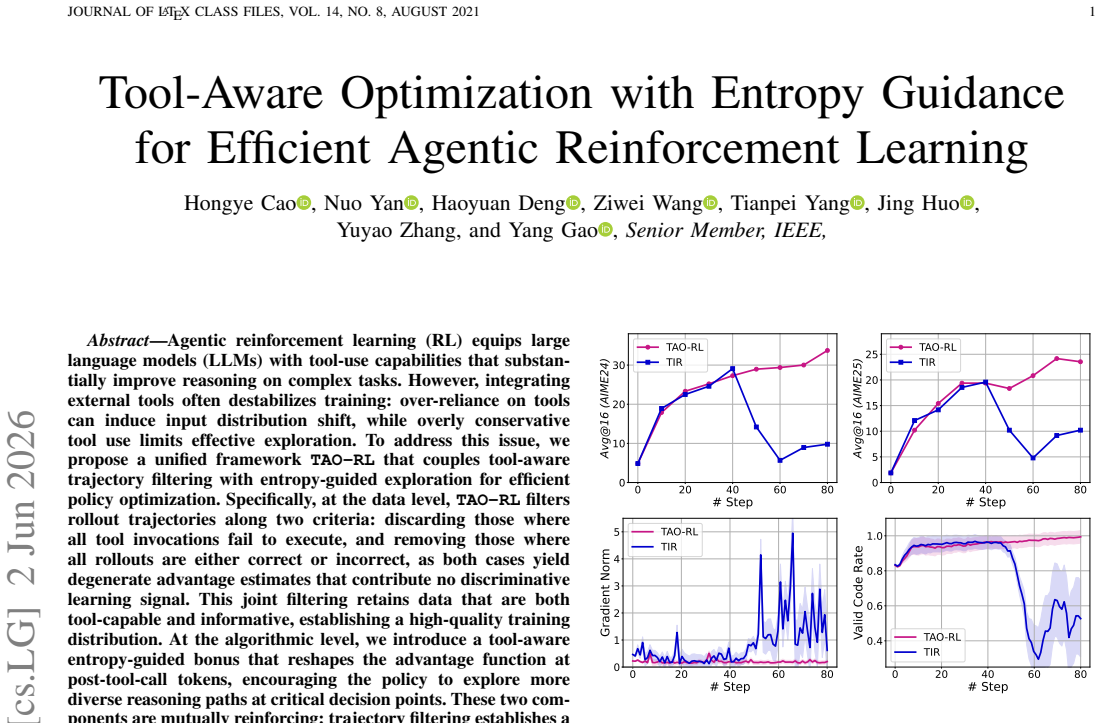
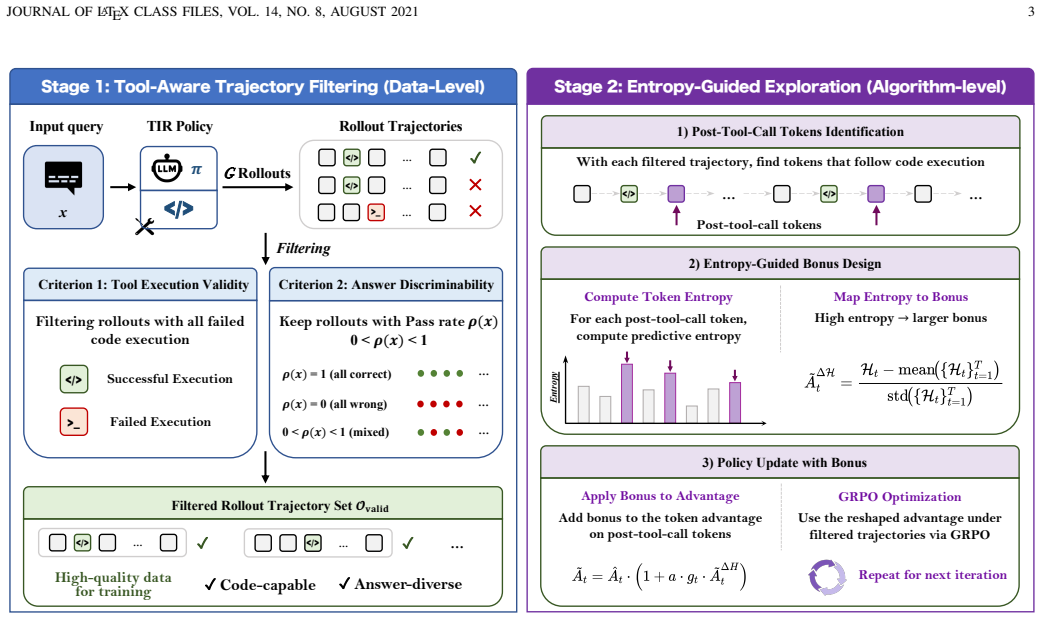
TAO-RL couples tool-aware trajectory filtering with entropy-guided exploration for efficient policy optimization. At the data level, it filters rollout trajectories by discarding those where all tool invocations fail to execute and those where all rollouts are either correct or incorrect, as both yield degenerate advantage estimates with no discriminative learning signal. At the algorithmic level, it introduces a tool-aware entropy-guided bonus that reshapes the advantage function at post-tool-call tokens to encourage the policy to explore more diverse reasoning paths at critical decision points. These components are mutually reinforcing and establish a high-quality training distribution.
What carries the argument
Tool-aware trajectory filtering that retains only tool-capable and informative rollouts, paired with an entropy-guided bonus applied to reshape advantages at post-tool-call tokens.
If this is right
- Retains a high-quality training distribution consisting of tool-capable and informative trajectories.
- Drives stronger reasoning behaviors at critical tool-interaction junctures through the entropy-guided bonus.
- The filtering and entropy components reinforce each other to produce more efficient policy optimization.
- Yields superior performance compared with existing methods across seven benchmarks and three model scales.
Where Pith is reading between the lines
- The same filtering logic could reduce variance in advantage estimates in other sequential decision settings where some actions produce uninformative outcomes.
- Applying entropy bonuses selectively at intermediate action points might improve exploration in non-LLM agent environments.
- Focusing training on informative trajectories could lower overall sample complexity in agentic RL tasks beyond the tested reasoning benchmarks.
Load-bearing premise
The two filtering criteria remove only degenerate advantage estimates without discarding useful learning signals, and the entropy bonus at post-tool-call tokens improves downstream reasoning rather than just increasing randomness.
What would settle it
An ablation that removes either the trajectory filtering or the entropy bonus and measures whether the reported gains on the seven reasoning benchmarks disappear or reverse.
Figures
read the original abstract
Agentic reinforcement learning (RL) equips large language models (LLMs) with tool-use capabilities that substantially improve reasoning on complex tasks. However, integrating external tools often destabilizes training: over-reliance on tools can induce input distribution shift, while overly conservative tool use limits effective exploration. To address this issue, we propose a unified framework TAO-RL that couples tool-aware trajectory filtering with entropy-guided exploration for efficient policy optimization. Specifically, at the data level, TAO-RL filters rollout trajectories along two criteria: discarding those where all tool invocations fail to execute, and removing those where all rollouts are either correct or incorrect, as both cases yield degenerate advantage estimates that contribute no discriminative learning signal. This joint filtering retains data that are both tool-capable and informative, establishing a high-quality training distribution. At the algorithmic level, we introduce a tool-aware entropy-guided bonus that reshapes the advantage function at post-tool-call tokens, encouraging the policy to explore more diverse reasoning paths at critical decision points. These two components are mutually reinforcing: trajectory filtering establishes a clean and informative training foundation, while entropy-guided exploration drives stronger reasoning behaviors at critical tool-interaction junctures. Extensive experiments on 7 challenging reasoning benchmarks across 3 model scales demonstrate the superiority of TAO-RL over existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TAO-RL, a unified framework for agentic reinforcement learning that integrates tool-aware trajectory filtering—discarding rollouts where all tool calls fail or where all rollouts are uniformly correct/incorrect—with a tool-aware entropy-guided bonus applied specifically at post-tool-call tokens to reshape advantages and encourage diverse exploration. The two components are presented as mutually reinforcing, and the authors claim that extensive experiments across 7 reasoning benchmarks and 3 model scales demonstrate superiority over existing methods.
Significance. If the empirical claims hold, the work would provide a practical, internally consistent mechanism for stabilizing RL training of tool-augmented LLMs by eliminating zero-variance advantage estimates and localizing entropy bonuses at decision points. The explicit targeting of degenerate cases and the localization of the entropy term represent a clear engineering contribution that could be adopted in other agentic RL pipelines.
minor comments (2)
- [Abstract] Abstract: the claim of 'superiority' is stated without any numerical results, error bars, or benchmark names; adding at least one headline performance delta would strengthen the summary.
- [Methods] The two filtering criteria are described at a high level; a short pseudocode or explicit condition in the methods section would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the engineering contributions, and recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The provided manuscript text consists entirely of high-level descriptive prose introducing the TAO-RL framework (trajectory filtering on failure and uniform-correctness criteria plus localized entropy bonus at post-tool tokens). No equations, advantage-function derivations, or parameter-fitting procedures appear. No self-citations are invoked to justify uniqueness or load-bearing premises, and no fitted inputs are relabeled as predictions. The construction is therefore self-contained against external benchmarks and does not reduce any claimed result to its own inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The landscape of agentic reinforcement learning for LLMs: A survey,
G. Zhang, H. Geng, X. Yu, Z. Yin, Z. Zhang, Z. Tan, H. Zhou, Z.-Z. Li, X. Xue, Y . Li, Y . Zhou, Y . Chen, C. Zhang, Y . Fan, Z. Wang, S. Huang, F. P. Velez, Y . Liao, H. W ANG, M. Yang, H. Ji, J. Wang, S. Y AN, P. Torr, and L. BAI, “The landscape of agentic reinforcement learning for LLMs: A survey,”Transactions on Machine Learning Research, 2026, survey...
2026
-
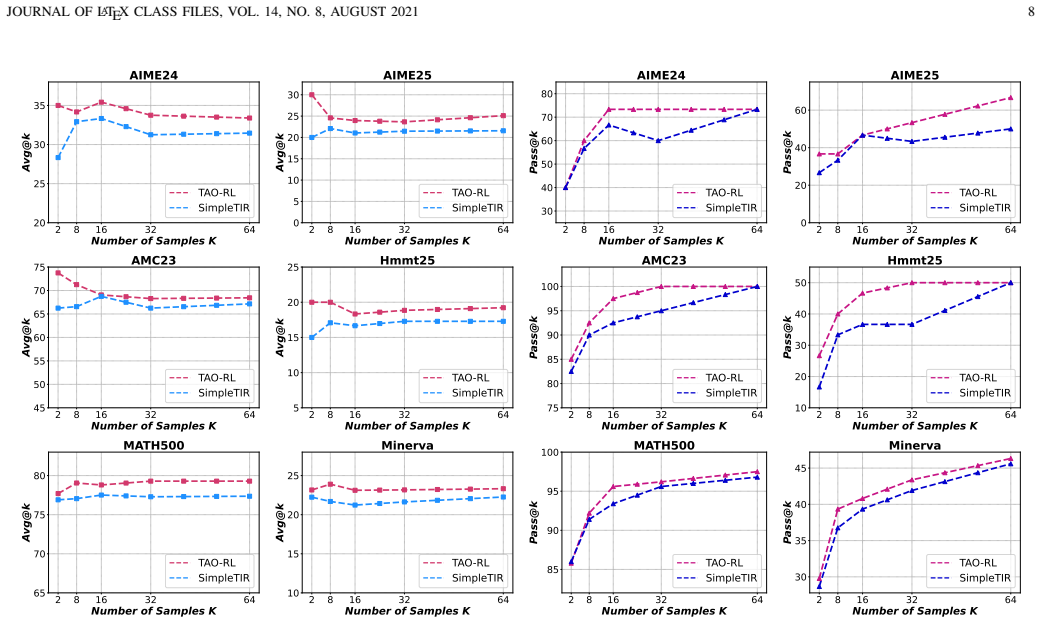
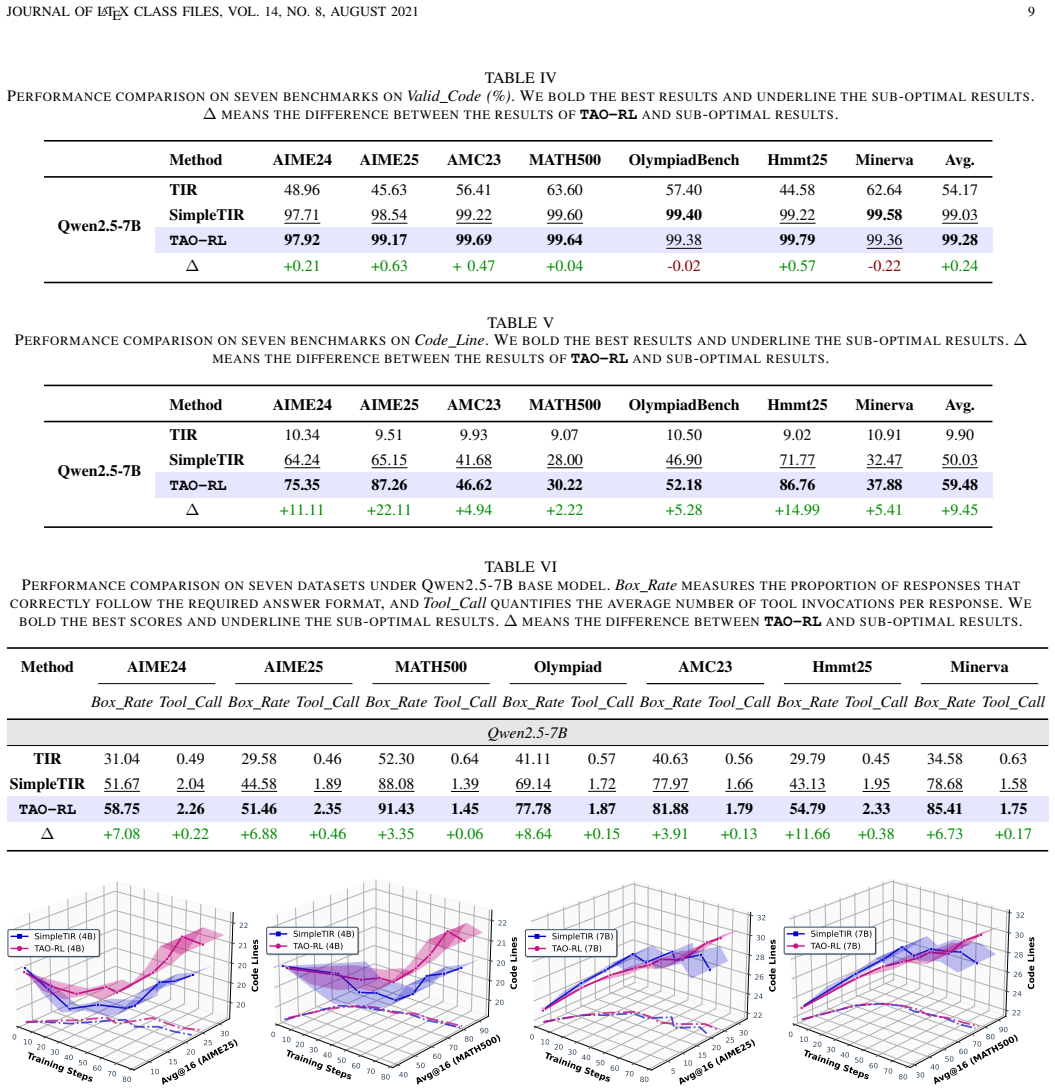
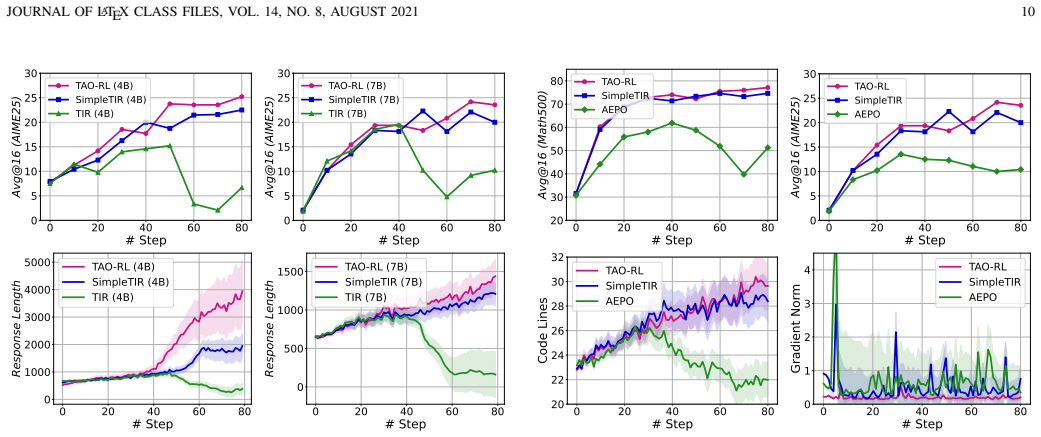
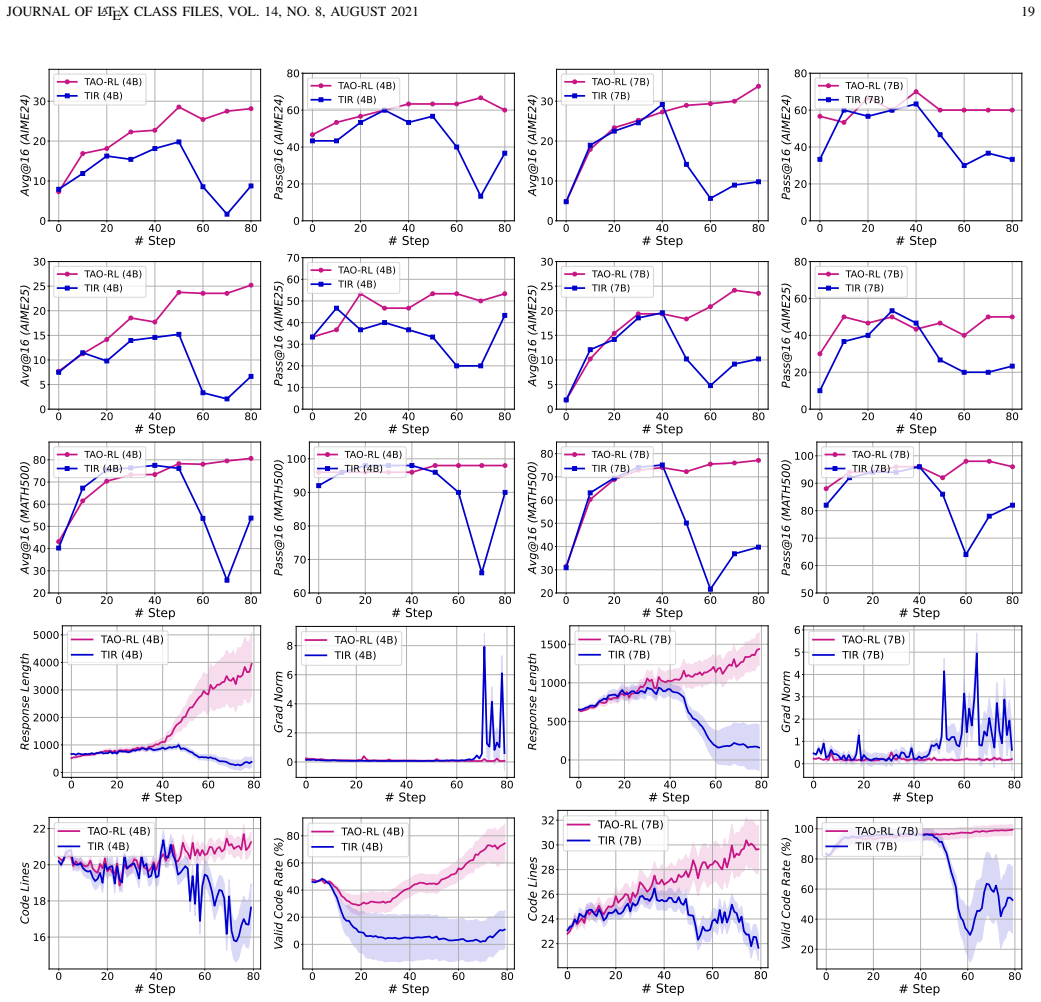
[2]
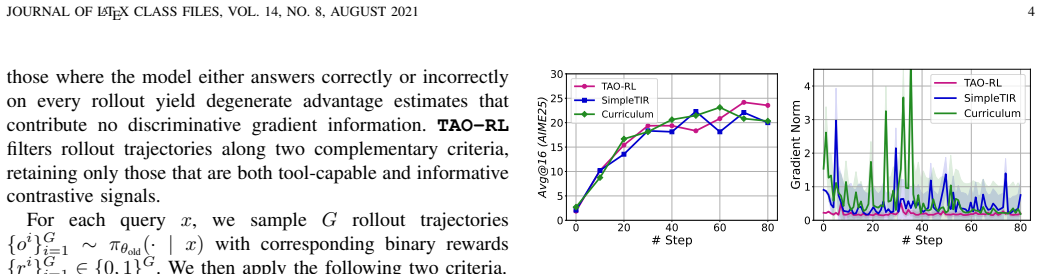
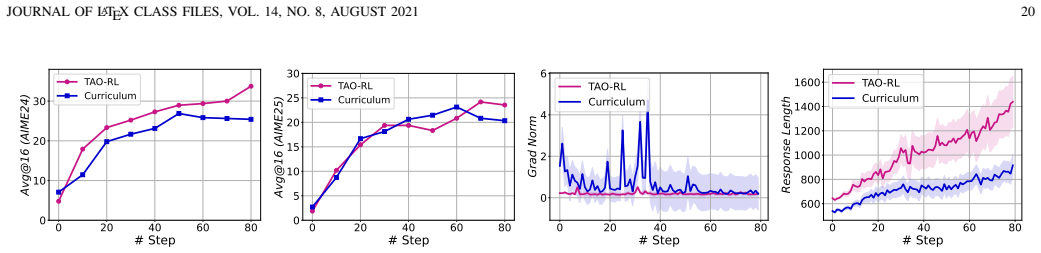
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
J. Singh, R. Magazine, Y . Pandya, and A. Nambi, “Agentic reasoning and tool integration for llms via reinforcement learning,”arXiv preprint arXiv:2505.01441, 2025
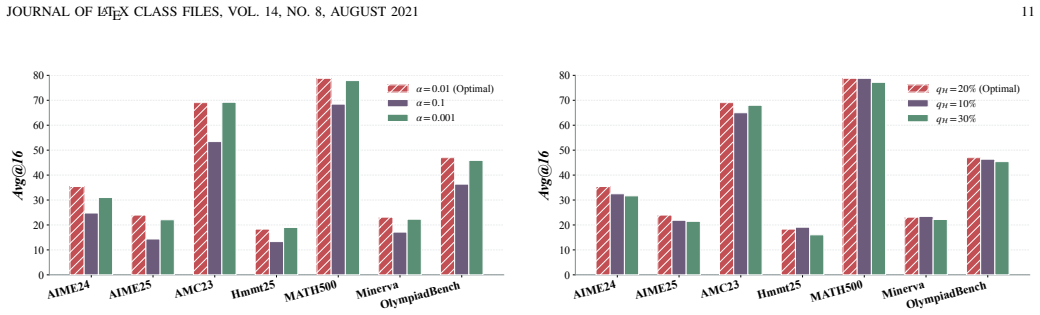
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Verltool: Towards holistic agentic reinforcement learning with tool use,
D. Jiang, Y . Lu, Z. Li, Z. Lyu, P. Nie, H. Wang, A. Su, H. Chen, K. Zou, C. Duet al., “Verltool: Towards holistic agentic reinforcement learning with tool use,”arXiv preprint arXiv:2509.01055, 2025
-
[4]
Torl: Scaling tool-integrated rl,
X. Li, H. Zou, and P. Liu, “Torl: Scaling tool-integrated rl,”arXiv preprint arXiv:2503.23383, 2025
-
[5]
Demystifying chains, trees, and graphs of thoughts,
M. Besta, F. Memedi, Z. Zhang, R. Gerstenberger, G. Piao, N. Blach, P. Nyczyk, M. Copik, G. Kwa ´sniewski, J. M ¨uller, L. Gianinazzi, A. Kubicek, H. Niewiadomski, A. O’Mahony, O. Mutlu, and T. Hoefler, “Demystifying chains, trees, and graphs of thoughts,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–20, 2025
2025
-
[6]
Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning,
B. Lin, Y . Nie, Z. Wei, J. Chen, S. Ma, J. Han, H. Xu, X. Chang, and X. Liang, “Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 7, pp. 5945–5957, 2025
2025
-
[7]
Advanced deep reinforcement learning for agentic ai and their applications in wireless network,
J. Zheng, D. Niyato, R. Zhang, J. Wang, J. Nie, H. Du, J. Kang, H. Zhang, A. Jamalipour, and D. I. Kim, “Advanced deep reinforcement learning for agentic ai and their applications in wireless network,”IEEE Transactions on Cognitive Communications and Networking, 2026
2026
-
[8]
Agentic entropy-balanced policy optimization,
G. Dong, L. Bao, Z. Wang, K. Zhao, X. Li, J. Jin, J. Yang, H. Mao, F. Zhang, K. Gaiet al., “Agentic entropy-balanced policy optimization,” arXiv preprint arXiv:2510.14545, 2025
-
[9]
Incentivizing agentic reasoning in LLM judges via tool-integrated reinforcement learning,
R. Xu, J. Chen, J. Ye, Y . Wu, J. Yan, C. Yang, and H. Yu, “Incentivizing agentic reasoning in LLM judges via tool-integrated reinforcement learning,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https: //openreview.net/forum?id=AXNRILww9c
2026
-
[10]
Agentic reinforced policy optimization,
G. Dong, H. Mao, K. Ma, L. Bao, Y . Chen, Z. Wang, Z. Chen, J. Du, H. Wang, F. Zhang, G. Zhou, Y . Zhu, J.-R. Wen, and Z. Dou, “Agentic reinforced policy optimization,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=TX4k7BF6aO
2026
-
[11]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
J. Feng, S. Huang, X. Qu, G. Zhang, Y . Qin, B. Zhong, C. Jiang, J. Chi, and W. Zhong, “Retool: Reinforcement learning for strategic tool use in llms,”arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Towards effective code-integrated reasoning,
F. Bai, Y . Min, B. Zhang, Z. Chen, W. X. Zhao, L. Fang, Z. Liu, Z. Wang, and J.-R. Wen, “Towards effective code-integrated reasoning,” arXiv preprint arXiv:2505.24480, 2025
-
[13]
Otc: Optimal tool calls via rein- forcement learning,
H. Wang, C. Qian, W. Zhong, X. Chen, J. Qiu, S. Huang, B. Jin, M. Wang, K.-F. Wong, and H. Ji, “Otc: Optimal tool calls via rein- forcement learning,”arXiv e-prints, pp. arXiv–2504, 2025
2025
-
[14]
Agentic RL scaling law: Spontaneous code execution for mathematical problem solving,
X. Mai, H. Xu, X. W, W. Wang, Y . Zhang, and W. Zhang, “Agentic RL scaling law: Spontaneous code execution for mathematical problem solving,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https: //openreview.net/forum?id=kXieirlPjF
2025
-
[15]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Z. Wang, K. Wang, Q. Wang, P. Zhang, L. Li, Z. Yang, X. Jin, K. Yu, M. N. Nguyen, L. Liuet al., “Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning,”arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Demystifying reinforce- ment learning in agentic reasoning,
Z. Yu, L. Yang, J. Zou, S. Yan, and M. Wang, “Demystifying reinforce- ment learning in agentic reasoning,”arXiv preprint arXiv:2510.11701, 2025
-
[17]
SimpleTIR: End-to-end reinforcement learning for multi- turn tool-integrated reasoning,
Z. Xue, L. Zheng, Q. Liu, Y . Li, X. Zheng, Z. MA, and B. An, “SimpleTIR: End-to-end reinforcement learning for multi- turn tool-integrated reasoning,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=EplNy91Xqh
2026
-
[18]
ToolRL: Reward is all tool learning needs,
C. Qian, E. C. Acikgoz, Q. He, H. W ANG, X. Chen, D. Hakkani-T ¨ur, G. Tur, and H. Ji, “ToolRL: Reward is all tool learning needs,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id= eOLdGbXT6t
2025
-
[19]
rstar2-agent: Agentic reasoning technical report,
N. Shang, Y . Liu, Y . Zhu, L. L. Zhang, W. Xu, X. Guan, B. Zhang, B. Dong, X. Zhou, B. Zhanget al., “rstar2-agent: Agentic reasoning technical report,”arXiv preprint arXiv:2508.20722, 2025
-
[20]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
2023
-
[21]
Search-o1: Agentic search-enhanced large reasoning models,
X. Li, G. Dong, J. Jin, Y . Zhang, Y . Zhou, Y . Zhu, P. Zhang, and Z. Dou, “Search-o1: Agentic search-enhanced large reasoning models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 5420–5438
2025
-
[22]
Agentmath: Empowering mathematical reasoning for large language models via tool-augmented agent,
H. Luo, H. Feng, Q. Sun, C. Xu, K. Zheng, Y . Wang, T. Yang, H. Hu, and Y . Tang, “Agentmath: Empowering mathematical reasoning for large language models via tool-augmented agent,”arXiv preprint arXiv:2512.20745, 2025
-
[23]
Et-agent: Incentivizing effective tool- integrated reasoning agent via behavior calibration,
Y . Chen, G. Dong, and Z. Dou, “Et-agent: Incentivizing effective tool- integrated reasoning agent via behavior calibration,”arXiv preprint arXiv:2601.06860, 2026
-
[24]
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning,
G. Dong, Y . Chen, X. Li, J. Jin, H. Qian, Y . Zhu, H. Mao, G. Zhou, Z. Dou, and J.-R. Wen, “Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning,”arXiv preprint arXiv:2505.16410, 2025
-
[25]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liuet al., “Dapo: An open-source llm reinforcement learning system at scale,”arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
R. Jin, P. Gao, Y . Ren, Z. Han, T. Zhang, W. Huang, W. Liu, J. Luan, and D. Xiong, “Revisiting entropy in reinforcement learning for large reasoning models,”arXiv preprint arXiv:2511.05993, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Reasoning with Exploration: An Entropy Perspective
D. Cheng, S. Huang, X. Zhu, B. Dai, W. X. Zhao, Z. Zhang, and F. Wei, “Reasoning with exploration: An entropy perspective,”arXiv preprint arXiv:2506.14758, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Generative adversarial soft ac- tor–critic,
H.-S. Hwang, Y . Kim, and J. Seok, “Generative adversarial soft ac- tor–critic,”IEEE Transactions on Neural Networks and Learning Sys- tems, vol. 36, no. 7, pp. 11 917–11 927, 2025
2025
-
[31]
Meol: A maximum- entropy framework for options learning,
P. Zhang, W. Dong, M. Cai, S. Jia, and Z.-P. Wang, “Meol: A maximum- entropy framework for options learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 3, pp. 4834–4848, 2025
2025
-
[32]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
G. Cui, Y . Zhang, J. Chen, L. Yuan, Z. Wang, Y . Zuo, H. Li, Y . Fan, H. Chen, W. Chenet al., “The entropy mechanism of re- inforcement learning for reasoning language models,”arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Efficient reinforcement learning with semantic and token entropy for llm reasoning,
H. Cao, Z. Bai, Z. Peng, B. Wang, T. Yang, J. Huo, Y . Zhang, and Y . Gao, “Efficient reinforcement learning with semantic and token entropy for llm reasoning,”arXiv preprint arXiv:2512.04359, 2025
-
[34]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X. Chen, J. Yang, Z. Zhanget al., “Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning,”arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
W. Deng, Y . Ren, Y . Li, B. Gong, D. J. Sutherland, X. Li, and C. Thrampoulidis, “Token hidden reward: Steering exploration- exploitation in group relative deep reinforcement learning,”arXiv preprint arXiv:2510.03669, 2025
-
[36]
A natural policy gradient,
S. M. Kakade, “A natural policy gradient,” inAdvances in Neural Infor- mation Processing Systems, T. Dietterich, S. Becker, and Z. Ghahramani, Eds., vol. 14. MIT Press, 2001
2001
-
[37]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
W. Zeng, Y . Huang, Q. Liu, W. Liu, K. He, Z. Ma, and J. He, “Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild,”arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Hybridflow: A flexible and efficient rlhf framework,
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybridflow: A flexible and efficient rlhf framework,” inProceedings of the Twentieth European Conference on Computer Systems, 2025, pp. 1279–1297
2025
-
[39]
American invitational mathematics examination-aime 2024, 2024
M. Codeforces, “American invitational mathematics examination-aime 2024, 2024.”
2024
-
[40]
American mathematics competitions - amc,
“American mathematics competitions - amc,” 2023. [Online]. Available: https://maa.org/
2023
-
[41]
Measuring mathematical problem solving with the math dataset,
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[42]
Olympiadbench: A challenging benchmark for promot- ing agi with olympiad-level bilingual multimodal scientific problems,
C. He, R. Luo, Y . Bai, S. Hu, Z. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhanget al., “Olympiadbench: A challenging benchmark for promot- ing agi with olympiad-level bilingual multimodal scientific problems,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 3828– 3850
2024
-
[43]
Matharena: Evaluating llms on uncontaminated math competitions,
M. Balunovi ´c, J. Dekoninck, I. Petrov, N. Jovanovi ´c, and M. Vechev, “Matharena: Evaluating llms on uncontaminated math competitions,” Feb. 2025. [Online]. Available: https://matharena.ai/
2025
-
[44]
Solv- ing quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Soloet al., “Solv- ing quantitative reasoning problems with language models,”Advances in neural information processing systems, vol. 35, pp. 3843–3857, 2022
2022
-
[45]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 58 791– 58 831. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15 APPENDIX A. Bro...
2025
-
[46]
Parameters not explicitly listed follow the default configurations of the VeRL [38] framework
Experimental Setup:To ensure reproducibility, we provide a detailed description of the training and evaluation hyperparameters in Table XI and Table XII. Parameters not explicitly listed follow the default configurations of the VeRL [38] framework. Hyperparameters specific to individual baselines are configured strictly according to their original papers,...
2021
-
[47]
Benchmarks:In our experiments, we conduct extensive validation on the following seven challenging mathematical reasoning benchmarks, along with one additional benchmark for generalization evaluation, to comprehensively assess model performance. •AIME 2024 & 2025[39]: A collection of 30 problems from the American Invitational Mathematics Examination 2024/2...
2024
-
[48]
Comparison with TIR:To provide a comprehensive view of howTAO-RLimproves upon naive tool integration, we present a detailed comparison against TIR across multiple dimensions throughout training, as shown in Fig. 10. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18 TABLE XII EVALUATION HYPERPARAMETERS USED IN OUR EXPERIMENTS. Hyperparameter Val...
2021
-
[49]
Comparison of Curriculum Learning:To further investigate whether preserving data quantity through structured data organization can serve as a viable alternative to our quality-driven filtering strategy, we compareTAO-RLagainst a curriculum learning variant that organizes the full training data in a progressive easy-to-hard order based on task difficulty. ...
-
[50]
Analysis on Trajectory Filtering Criteria: Retaining All-Wrong Trajectories:A natural concern about our trajectory filtering strategy is that removing uniformly incorrect rollout groups may discard useful negative signals, since such groups can still contain valid tool calls or partial reasoning traces. To test this possibility, we introduce aKeep-Wrongva...
2021
-
[51]
Hyperparameter Analysis:We conduct a systematic sensitivity analysis of two core hyperparameters in the entropy- guided exploration module: the entropy bonus coefficientαand the entropy gating percentileq H. The former controls the magnitude of advantage reshaping at selected post-tool-call tokens, while the latter determines the proportion of high-entrop...
2021
-
[52]
Case Study:To further demonstrate the robust generalization ofTAO-RL, we provide two additional case studies from the AIME 2024 test set. These cases highlight our method’s capacity for dynamic strategy switching (Table XX) and conceptual mathematical abstraction (Table XXI), contrasting with the baseline’s tendency to succumb to unrecoverable symbolic ar...
2024
-
[53]
Platforms:All experiments of this approach are implemented on two Intel Xeon Platinum 8480+ CPUs and eight NVIDIA A100 GPUs
-
[54]
Licenses:In our implementation, we have utilized the following open-source libraries, each governed by its respective license agreements: •VeRL: Apache License 2.0 •Ray: Apache License 2.0 •vLLM: Apache License 2.0 •Weights & Biase: MIT License •FlashAttention: BSD 3-Clause License •TensorDict: MIT License JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUG...
-
[55]
Sinceω̸= 1is a 13th root of unity,ω 13 = 1andω̸= 1, which meansωis a complex root of unity
First, we need to identify the 13th roots of unity. Sinceω̸= 1is a 13th root of unity,ω 13 = 1andω̸= 1, which meansωis a complex root of unity
-
[56]
Next, we need to compute the expression Q12 k=0(2−2ω k +ω 2k)
-
[57]
Let’s execute the steps in Python to find the final answer
After calculating the product, we need to find the remainder of this product when divided by 1000. Let’s execute the steps in Python to find the final answer. importsympyassp # Define the 13th root of unity omega omega = sp.exp(2 * sp.pi * sp.I / 13) # Calculate the product product = 1 forkin range(13): term = 2 - 2 * omega**k + omega **(2 * k) product *=...
-
[58]
Generate the 13th roots of unity, excluding 1
-
[59]
Compute the expression2−2ω k +ω 2k for eachk
-
[60]
We can use Python and sympy to perform symbolic computation
Find the remainder when the product is divided by 1000. We can use Python and sympy to perform symbolic computation. importsympyassp # Define the 13th root of unity n = 13 omega = sp.exp(2 * sp.pi * sp.I / n) # Initialize the product product = 1 # Compute the product forkin range(n): term = 2 - 2 * omega**k + omega **(2*k) product *= term # Simplify the p...
2021
-
[61]
For a setBto be included, its maximum element must be inA
-
[62]
For each elementm∈A, we can form setsBby choosing elements from{1,2, . . . , m−1}. The number of such setsBis2 m−1
-
[63]
This is given as 2024
The total number of setsBis the sum of2 m−1 for allm∈A. This is given as 2024. So, we have the equation: P m∈A 2m−1 = 2024
2024
-
[64]
Let’s write a Python program
Find the setAof positive integers such that the sum of2 m−1 equals 2024. Let’s write a Python program. # We need to find a set A such that the sum of 2ˆ(m-1) # for all m in A equals 2024. deffind_set_A(target_sum): fromitertoolsimportcombinations frommathimportinf # Start with an empty set and gradually add elements best_set = [] best_sum = inf # We will ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.