AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
Pith reviewed 2026-06-28 10:22 UTC · model grok-4.3
The pith
An asymmetric discriminator attending bidirectionally over full video context prevents motion collapse in one-step autoregressive image-to-video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
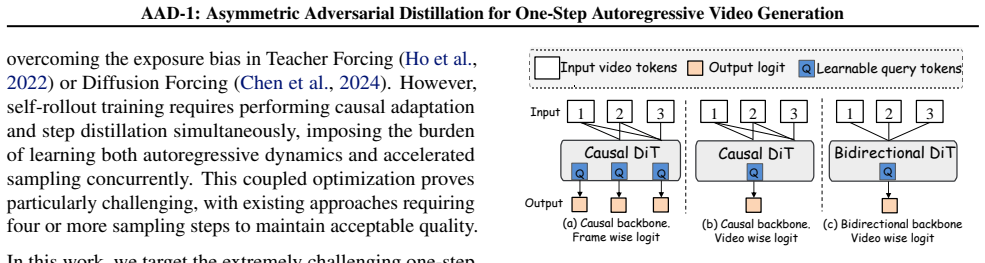
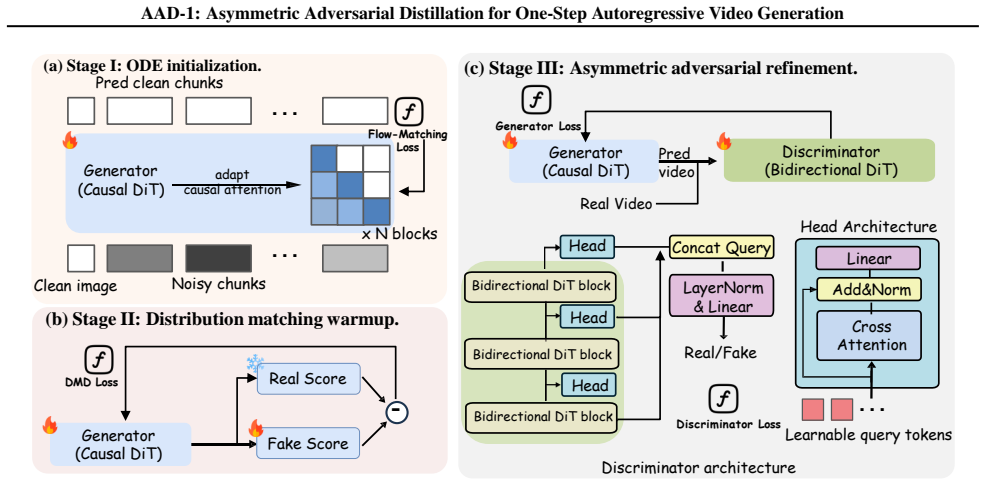
The central claim is that an asymmetric adversarial distillation framework, with a causal generator preserving autoregressive sampling and a bidirectional discriminator producing one holistic realism score over the entire sequence, combined with an initial distribution-matching warm-up phase, enables stable one-step autoregressive image-to-video generation by detecting and penalizing long-range drift and motion collapse, reaching state-of-the-art results on VBench.
What carries the argument
The asymmetric discriminator that attends bidirectionally over full spatiotemporal context to output a single holistic realism score for the whole video.
If this is right
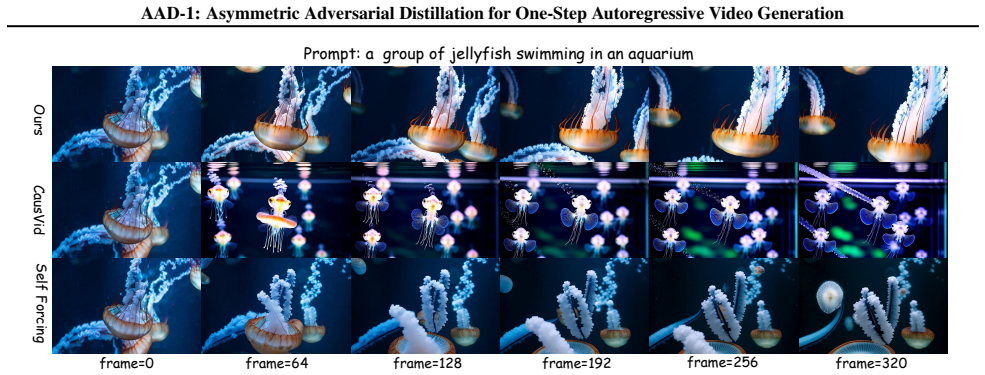
- The one-step generator produces coherent motion without collapse while remaining autoregressive at inference.
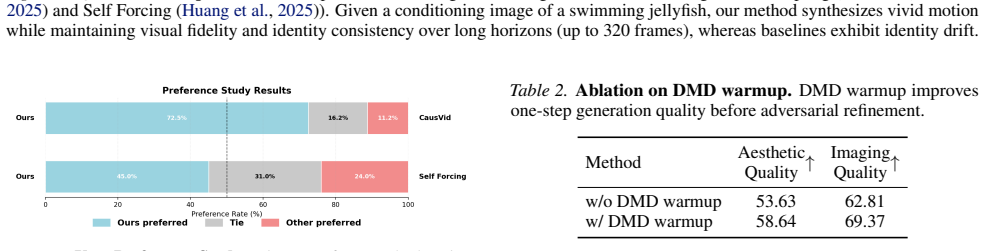
- The initial distribution-matching phase brings the student close enough to the teacher for subsequent adversarial training to succeed.
- Global temporal failures become detectable because the discriminator sees the complete sequence rather than local patches.
- One-step autoregressive video generation reaches performance levels previously limited to multi-step approaches.
Where Pith is reading between the lines
- The same asymmetry might apply to autoregressive generation in other domains such as audio sequences or 3D motion.
- Reducing reliance on multi-step sampling could lower inference cost for video models if the phased strategy transfers.
- Future work could test whether the holistic score generalizes to longer videos where drift accumulates over more frames.
Load-bearing premise
That a bidirectional discriminator can reliably detect and penalize motion collapse and long-range drift without introducing new instabilities or forcing changes to the causal generator's sampling process.
What would settle it
Videos from the one-step model show no gains in motion coherence or long-range consistency metrics over symmetric distillation baselines, or training diverges when the bidirectional discriminator is added.
Figures





read the original abstract
We present AAD-1, an Asymmetric Adversarial Distillation framework for One-step autoregressive image-to-video generation. State-of-the-art methods adopt adversarial distillation but suffer from motion collapse and training instability, resulting in static videos. AAD-1 addresses these challenges through two key designs in architecture and training strategy. Our key architectural insight is to break the symmetry between generator and discriminator. While the generator remains causal to preserve autoregressive sampling capability, the discriminator attends bidirectionally over the full spatiotemporal context and produces a single holistic realism score for the entire video sequence. This asymmetric design enables the discriminator to effectively detect global temporal failures and long-range drift that cause motion collapse in autoregressive generation. To stabilize training, we introduce a phased strategy that first uses distribution matching to bootstrap a stable one-step generator, providing a warm-up phase that brings the student distribution closer to the teacher before adversarial distillation begins. Extensive experiments on VBench demonstrate that AAD-1 achieves state-of-the-art performance in one-step autoregressive video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AAD-1, an Asymmetric Adversarial Distillation framework for one-step autoregressive image-to-video generation. It features a causal generator paired with a bidirectional discriminator that evaluates the full spatiotemporal context to produce a single holistic realism score. A phased training strategy is proposed, beginning with distribution matching to stabilize the one-step generator before transitioning to adversarial distillation. The authors claim this approach mitigates motion collapse and long-range drift, achieving state-of-the-art performance on the VBench benchmark.
Significance. Should the empirical claims be substantiated with rigorous comparisons and ablations, this work could contribute meaningfully to the development of efficient video generation models. The asymmetric architecture allows the discriminator to target global temporal issues without compromising the causal nature of the generator at inference time. The phased training strategy addresses a common challenge in adversarial training of generative models. Credit is given for the clear architectural insight and the practical training schedule.
minor comments (1)
- [Abstract] Abstract: The abstract asserts SOTA results on VBench but does not provide any specific metric values, baseline comparisons, or dataset details. Including key quantitative results would better support the central claim.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, recognition of the asymmetric architecture and phased training contributions, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an asymmetric architecture (causal generator + bidirectional discriminator) and a phased training schedule (distribution matching warm-up followed by adversarial distillation) as explicit design choices. No equations, fitted parameters, or self-citations are presented that reduce the claimed performance gains or the detection of motion collapse to quantities defined by the method itself. Claims rest on external benchmark results (VBench) rather than internal self-consistency that would indicate circularity. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
Causal-rCM unifies teacher-forcing and self-forcing distillation for autoregressive video diffusion, delivering a 2-step model with VBench-T2V score 84.63 and enabling interactive world models on Cosmos 3 using only s...
Reference graph
Works this paper leans on
-
[1]
SkyReels-V2: Infinite-length Film Generative Model
Chen, G., Lin, D., Yang, J., Lin, C., Zhu, J., Fan, M., Zhang, H., Chen, S., Chen, Z., Ma, C., et al. Skyreels- v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
H., Yu, K., Zhang, P., Li, W., Zhou, Y ., Zheng, T., and Lu, Q
Cheng, J., Ma, B., Ren, X., Jin, H. H., Yu, K., Zhang, P., Li, W., Zhou, Y ., Zheng, T., and Lu, Q. Phased one-step adversarial equilibrium for video diffusion models.arXiv preprint arXiv:2508.21019,
-
[3]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y ., and Hsieh, C.-J. Self-forcing++: To- wards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Feng, R., Zhang, H., Yang, Z., Xiao, J., Shu, Z., Liu, Z., Zheng, A., Huang, Y ., Liu, Y ., and Zhang, H. The matrix: Infinite-horizon world generation with real-time moving control.arXiv preprint arXiv:2412.03568,
-
[5]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040,
Hong, Y ., Mei, Y ., Ge, C., Xu, Y ., Zhou, Y ., Bi, S., Hold- Geoffroy, Y ., Roberts, M., Fisher, M., Shechtman, E., et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040,
-
[6]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., and Shechtman, E. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Jacobs, S. A., Tanaka, M., Zhang, C., Zhang, M., Song, S. L., Rajbhandari, S., and He, Y . Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Open-Sora Plan: Open-Source Large Video Generation Model
Lin, B., Ge, Y ., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y ., Yuan, S., Chen, L., et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Lin, S., Xia, X., Ren, Y ., Yang, C., Xiao, X., and Jiang, L. Diffusion adversarial post-training for one-step video generation.arXiv preprint arXiv:2501.08316, 2025a. Lin, S., Yang, C., He, H., Jiang, J., Ren, Y ., Xia, X., Zhao, Y ., Xiao, X., and Jiang, L. Autoregressive adversarial post-training for real-time interactive video generation. arXiv prepri...
-
[11]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Lu, Y ., Ren, Y ., Xia, X., Lin, S., Wang, X., Xiao, X., Ma, A. J., Xie, X., and Lai, J.-H. Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16818– 16829, 2025a. 10 AAD-1: Asymmetric Adversarial Distillation for One-Step ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Shao, S., Yi, H., Guo, H., Ye, T., Zhou, D., Lingelbach, M., Xu, Z., and Xie, Z. Magicdistillation: Weak-to-strong video distillation for large-scale few-step synthesis.arXiv preprint arXiv:2503.13319,
-
[15]
MAGI-1: Autoregressive Video Generation at Scale
Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W., Luo, W., et al. Magi-1: Au- toregressive video generation at scale.arXiv preprint arXiv:2505.13211,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Flow map dis- tillation without data.arXiv preprint arXiv:2511.19428,
Tong, S., Ma, N., Xie, S., and Jaakkola, T. Flow map dis- tillation without data.arXiv preprint arXiv:2511.19428,
-
[17]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Live2Diff: Live stream translation via uni-directional attention in video diffusion models,
Xing, Z., Fox, G., Zeng, Y ., Pan, X., Elgharib, M., Theobalt, C., and Chen, K. Live2diff: Live stream translation via uni-directional attention in video diffusion models.arXiv preprint arXiv:2407.08701,
-
[20]
LongLive: Real-time Interactive Long Video Generation
Yang, S., Huang, W., Chu, R., Xiao, Y ., Zhao, Y ., Wang, X., Li, M., Xie, E., Chen, Y ., Lu, Y ., et al. Longlive: Real- time interactive long video generation.arXiv preprint arXiv:2509.22622,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yuan, H., Chen, W., Cen, J., Yu, H., Liang, J., Chang, S., Lin, Z., Feng, T., Liu, P., Xing, J., et al. Lumos-1: On autoregressive video generation from a unified model perspective.arXiv preprint arXiv:2507.08801,
-
[22]
Packing input frame context in next-frame prediction models for video generation
Zhang, L. and Agrawala, M. Frame context packing and drift prevention in next-frame-prediction video diffusion models.arXiv preprint arXiv:2504.12626,
-
[23]
with context parallel size 8 together with PyTorch activation checkpointing. Under the same Stage III setup, namely 64 H20 GPUs, 8 GPUs per node, and Ulysses-style context parallelism with cp = 8 , the bidirectional discriminator adversarial training reaches a peak total GPU 13 AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video G...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.