Self-Distilled Policy Gradient
Pith reviewed 2026-06-28 11:22 UTC · model grok-4.3
The pith
Self-distilled policy gradient improves stability and performance in language model reinforcement learning by adding full-vocabulary on-policy self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
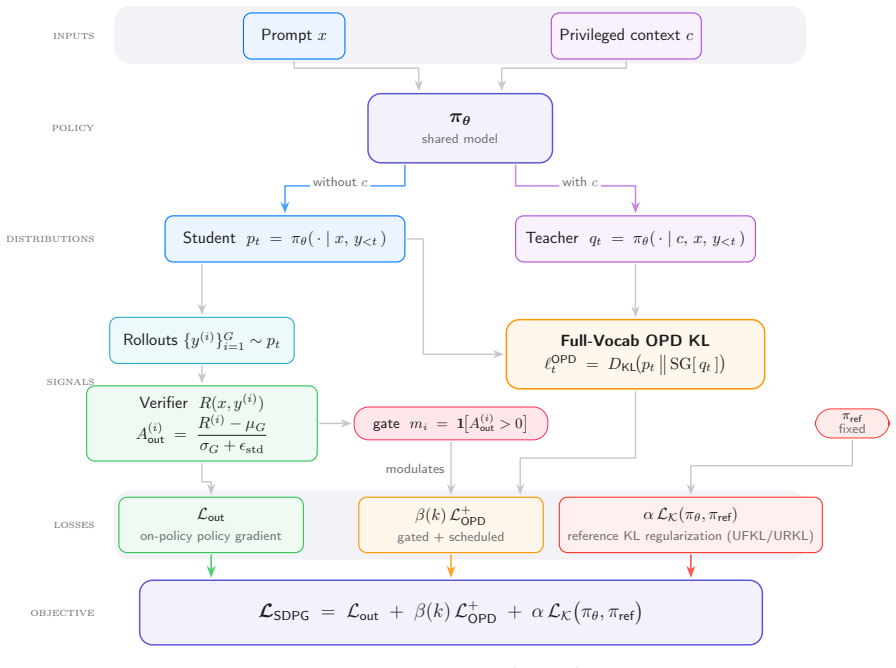
SDPG is a self-distilled policy-gradient framework that combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation instantiated as an auxiliary full-vocabulary student-to-teacher reverse Kullback-Leibler divergence loss, as well as reference-policy KL regularization.
What carries the argument
Exact full-vocabulary on-policy self-distillation via reverse KL divergence, used as an auxiliary loss alongside group-relative verifier advantages.
If this is right
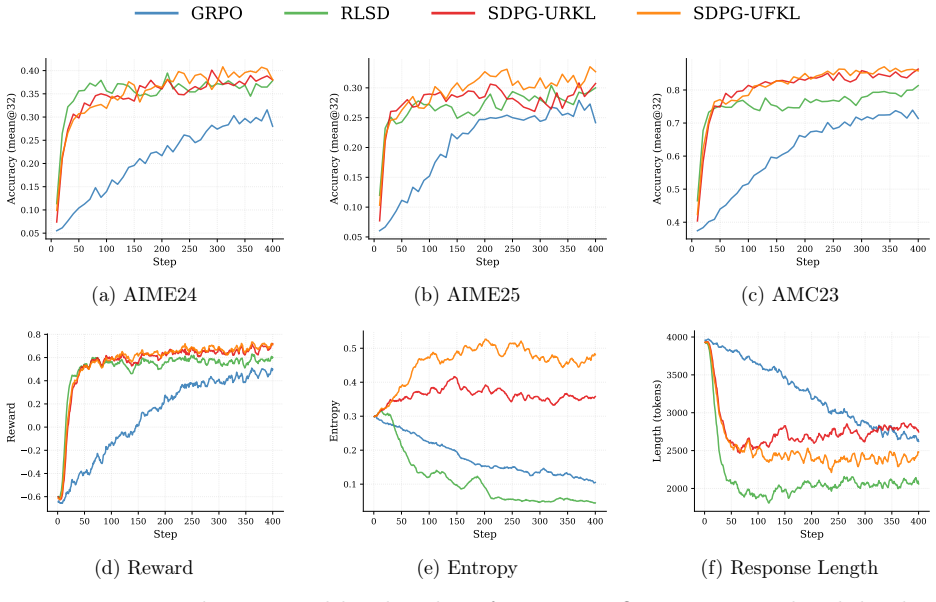
- SDPG improves stability over RLVR and self-distillation baselines.
- SDPG improves performance over RLVR and self-distillation baselines.
- On-policy self-distillation supplies dense supervision signals for sparse-reward reinforcement learning.
- The reverse KL auxiliary loss can be added to existing policy-gradient methods without changing the primary advantage estimator.
Where Pith is reading between the lines
- The same self-distillation mechanism might transfer to other sparse-reward sequential decision tasks where a model can condition on richer context than its own output distribution.
- If the normalized standard deviation scaling proves critical, similar normalization could be tested on other advantage estimators outside language-model RL.
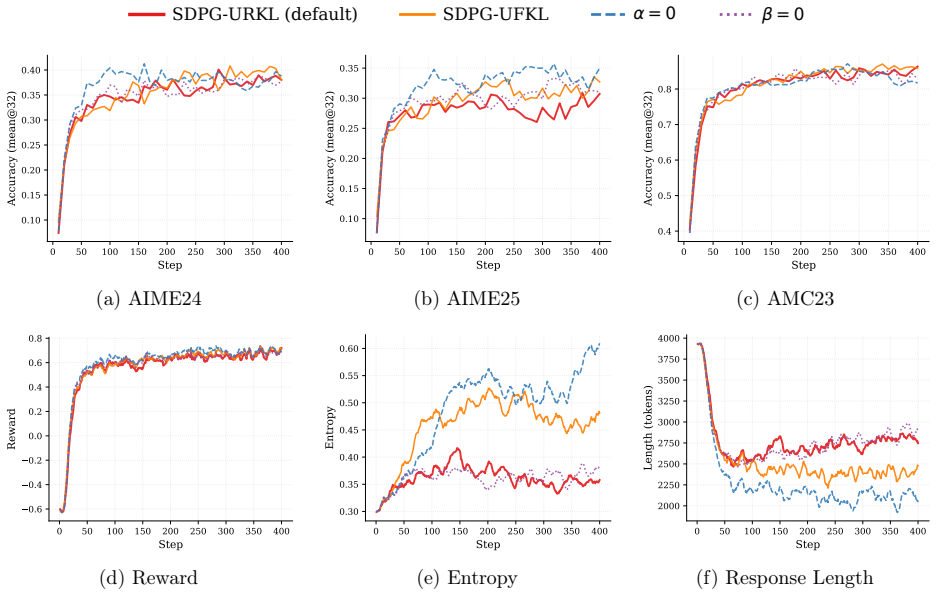
- The reference-policy KL term may interact with the self-distillation loss in ways that limit distribution shift; removing or varying that term could isolate its contribution.
Load-bearing premise
The specific combination of group-relative verifier advantages, normalized standard deviation, exact full-vocabulary on-policy self-distillation, and reference-policy KL regularization produces net positive effects without harmful interactions or biases from using the model's own generations as supervision.
What would settle it
An ablation that removes the full-vocabulary on-policy self-distillation loss and measures whether stability or final performance drops on the same tasks would directly test the contribution of that component.
Figures

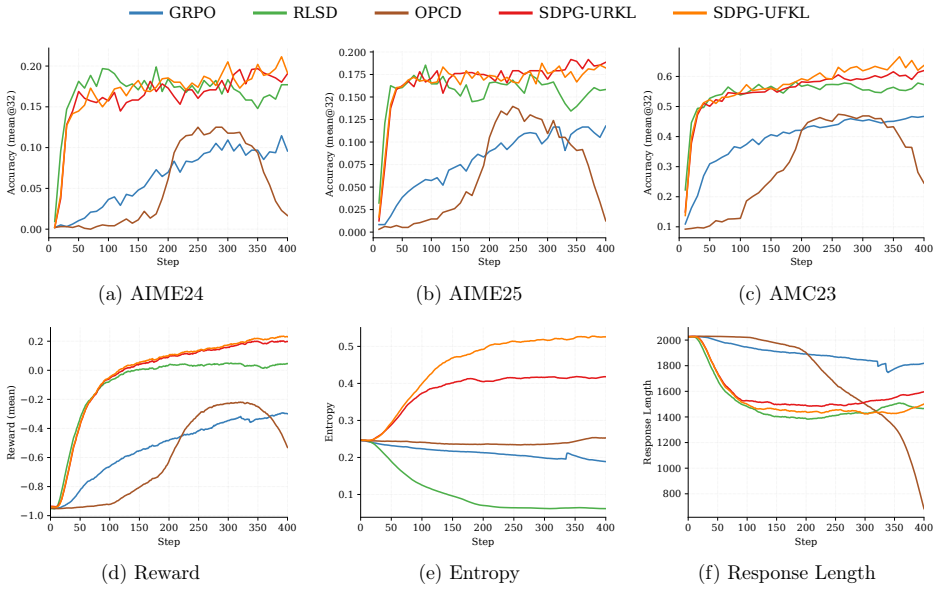
read the original abstract
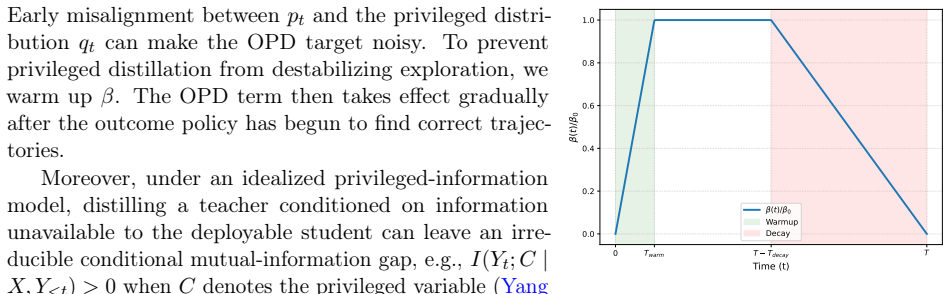
On-policy self-distillation, where a language model conditions on privileged context to supervise its own generations, is a promising source of dense supervision for sparse-reward reinforcement learning. Actually, it can be instantiated as an auxiliary full-vocabulary student-to-teacher reverse Kullback-Leibler divergence loss. We therefore propose SDPG, a self-distilled policy-gradient framework that combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation, as well as reference-policy KL regularization. Empirically, SDPG improves stability and performance over RLVR and self-distillation baselines. The code is available at https://github.com/lauyikfung/SDPG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SDPG, a self-distilled policy-gradient framework for language models. It combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation implemented as an auxiliary reverse KL divergence loss, and reference-policy KL regularization. The central claim is that this combination empirically improves stability and performance over RLVR and self-distillation baselines, with code released at the provided GitHub repository.
Significance. If the reported gains hold, the approach supplies a practical mechanism for obtaining dense on-policy supervision in sparse-reward RL settings for language models. The public code release is a clear strength that aids reproducibility and verification.
minor comments (3)
- Abstract: the empirical claim would be strengthened by a one-sentence indication of the tasks or benchmarks on which stability and performance gains were measured.
- Section 3 (method): the precise formula and motivation for 'normalized standard deviation' in the advantage estimator should be written out explicitly rather than described only in prose.
- Experiments section: while the abstract asserts gains over baselines, the main text should include a short discussion of whether the four components interact constructively or whether any can be ablated without loss of the reported benefit.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SDPG, the recognition of its practical value for dense on-policy supervision in sparse-reward settings, and the recommendation for minor revision. The report contains no major comments requiring point-by-point responses.
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical method (SDPG) that combines existing RL components (group-relative advantages, KL regularization, on-policy self-distillation via reverse KL) and reports performance gains on benchmarks. No derivation chain exists that reduces a claimed result to its inputs by construction; the central claims are experimental comparisons against baselines, with no fitted parameters renamed as predictions, no self-citation load-bearing uniqueness theorems, and no self-definitional loops in the method description. The self-distillation step is an explicit design choice, not a hidden tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-Policy Context Distillation for Language Models
On-Policy Context Distillation for Language Models , author=. arXiv preprint arXiv:2602.12275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Preprint , year=
Information geometric measurements of generalisation , author=. Preprint , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Self-Distillation Enables Continual Learning
Self-Distillation Enables Continual Learning , author=. arXiv preprint arXiv:2601.19897 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The Fourteenth International Conference on Learning Representations , year=
On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[7]
Divergence measures and message passing , author=
-
[8]
Self-Distilled RLVR , author=. arXiv preprint arXiv:2604.03128 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[10]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[11]
2025 , school=
vLLM: An Efficient Inference Engine for Large Language Models , author=. 2025 , school=
2025
-
[12]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
IEEE transactions on pattern analysis and machine intelligence , volume=
A survey on curriculum learning , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[14]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Instruction tuning with human curriculum , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
-
[16]
NeurIPS 2025 Workshop on Efficient Reasoning , year=
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning , author=. NeurIPS 2025 Workshop on Efficient Reasoning , year=
2025
-
[17]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Reinforcement Learning via Self-Distillation
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
2020 , month = mar, day =
John Schulman , title =. 2020 , month = mar, day =
2020
-
[21]
2024 , url =
MAA, Mathematical Association of America's American Mathematics Competitions , title =. 2024 , url =
2024
-
[22]
2025 , url =
MAA, Mathematical Association of America's American Mathematics Competitions , title =. 2025 , url =
2025
-
[23]
2023 , url =
MAA, Mathematical Association of America's American Mathematics Competitions , title =. 2023 , url =
2023
-
[24]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[26]
arXiv preprint arXiv:2507.04136 , year=
A technical survey of reinforcement learning techniques for large language models , author=. arXiv preprint arXiv:2507.04136 , year=
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Reinforcement Learning for Reasoning in Large Language Models with One Training Example , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[28]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[31]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Step-level value preference optimization for mathematical reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Generative Verifiers: Reward Modeling as Next-Token Prediction , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
S-GRPO: Early Exit via Reinforcement Learning in Reasoning Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[35]
Unlocking Exploration in RLVR: Uncertainty-aware Advantage Shaping for Deeper Reasoning
Unlocking exploration in rlvr: Uncertainty-aware advantage shaping for deeper reasoning , author=. arXiv preprint arXiv:2510.10649 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Outcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Outcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning , author=. arXiv preprint arXiv:2601.07408 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Reasoning with exploration: An entropy perspective , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[39]
Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization , author=. arXiv preprint arXiv:2505.12346 , year=
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Test-time Prompt Intervention , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[41]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Improve mathematical reasoning in language models by automated process supervision , author=. arXiv preprint arXiv:2406.06592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[43]
The Thirteenth International Conference on Learning Representations , year=
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[44]
The twelfth international conference on learning representations , year=
Minillm: Knowledge distillation of large language models , author=. The twelfth international conference on learning representations , year=
-
[45]
https://thinkingmachines.ai/blog/on-policy-distillation
Lu, K. and Lab, Thinking Machines , title =. Thinking Machines Lab: Connectionism , year =. doi:10.64434/tml.20251026 , url =
-
[46]
MiMo-V2-Flash Technical Report
Mimo-v2-flash technical report , author=. arXiv preprint arXiv:2601.02780 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author=. arXiv preprint arXiv:2603.25562 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Privileged Information Distillation for Language Models
Privileged Information Distillation for Language Models , author=. arXiv preprint arXiv:2602.04942 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Reinforcement-aware Knowledge Distillation for LLM Reasoning
Reinforcement-aware knowledge distillation for LLM reasoning , author=. arXiv preprint arXiv:2602.22495 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
arXiv preprint arXiv:2410.01679 , year=
Vineppo: Refining credit assignment in rl training of llms , author=. arXiv preprint arXiv:2410.01679 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.