Adaptive Patching Is Harder Than It Looks For Time-Series Forecasting
Pith reviewed 2026-06-28 11:03 UTC · model grok-4.3
The pith
Adaptive patching for time-series Transformers must meet an explicit threshold to outperform a tuned uniform baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
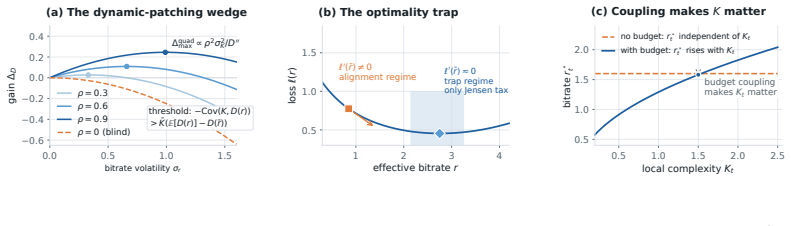
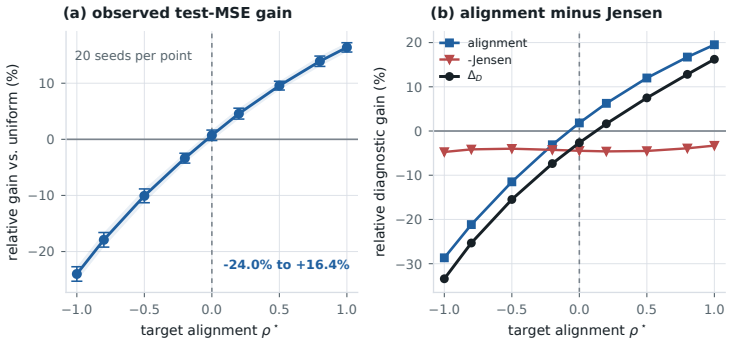
Under pointwise forecasting losses, a dynamic patching rule must satisfy an explicit threshold derived from bitrate allocation to beat a well-tuned uniform baseline; without a coupling constraint, scalar local complexity cannot produce a non-uniform optimum under a common loss landscape; and once the backbone reaches its representation-aware optimum, the alignment gain collapses around a well-tuned uniform patch size.
What carries the argument
Budgeted bitrate allocation model of patching, which yields the explicit threshold condition and the quadratic and strong-convexity bounds on achievable improvement.
Load-bearing premise
That patching decisions can be modeled as budgeted bitrate allocation under pointwise forecasting losses, from which the threshold and post-training collapse follow.
What would settle it
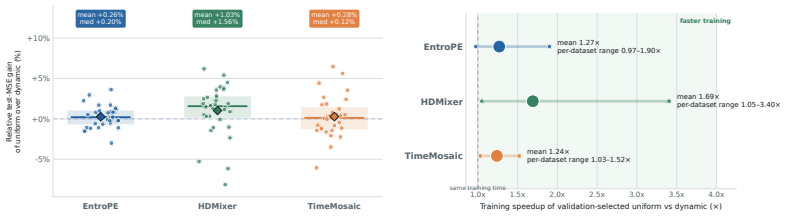
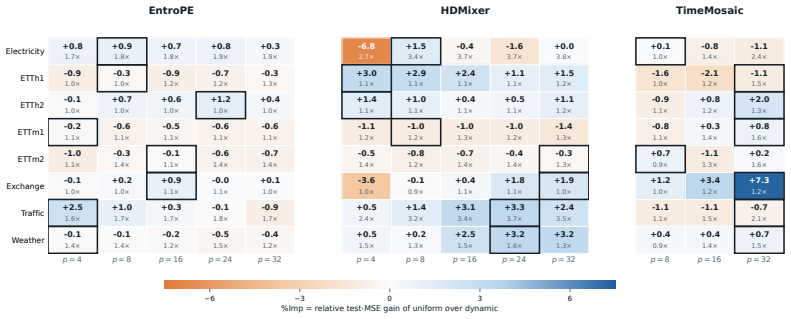
An experiment in which an adaptive patching method produces consistent positive gains over the best validation-selected uniform patch size across multiple datasets and architectures after aggregation.
Figures
read the original abstract
Adaptive patching is a recent and compelling proposal for time-series Transformers: allocate finer patches where the sequence looks locally informative. This paper asks under what conditions a content-adaptive patching operator should outperform a tuned uniform one. Local heterogeneity alone is not enough: under pointwise forecasting losses, a complex-looking region is not automatically one where finer patching reduces the loss. We model patching as a budgeted bitrate allocation and derive an explicit threshold that a dynamic patching rule must satisfy to beat a well-tuned uniform baseline, then bound the achievable improvement both locally (a quadratic surrogate) and globally (a strong-convexity bound under the model's assumptions). Two structural results follow: without a coupling constraint, scalar local complexity cannot produce a non-uniform optimum under a common loss landscape; and once the backbone is trained to its representation-aware optimum, the alignment gain collapses around a well-tuned uniform patch size. To test these predictions, we run a controlled isolation study on three representative architectures, replacing each adaptive mechanism with a uniform patch-size sweep while keeping the backbone, data, and training protocol fixed. On standard long-horizon forecasting benchmarks, the validation-selected uniform baseline is competitive with the dynamic counterpart, with per-setting effects concentrated near zero and no consistent directional advantage once results are aggregated by dataset. The larger gains we do observe are method- and dataset-specific. Adaptive patching should therefore be evaluated against a tuned uniform baseline; its value depends on whether a cheap and reliable routing signal can identify where finer patches actually reduce forecasting loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adaptive patching for time-series Transformers does not automatically outperform a well-tuned uniform patching strategy. Modeling patching as budgeted bitrate allocation under pointwise forecasting losses, it derives an explicit threshold that any dynamic rule must exceed to improve on uniform, plus local quadratic and global strong-convexity bounds on achievable gain. Two structural results are stated: scalar local complexity cannot produce a non-uniform optimum without coupling constraints, and representation-aware training collapses alignment gain around a tuned uniform size. A controlled isolation study on three Transformer backbones (replacing adaptive mechanisms with uniform patch-size sweeps while fixing backbone, data, and protocol) shows that validation-selected uniform baselines are competitive, with per-setting effects near zero and no consistent directional advantage when aggregated by dataset; larger gains are method- and dataset-specific. The conclusion is that adaptive patching must be evaluated against tuned uniform baselines and its value hinges on whether a cheap routing signal can identify regions where finer patches actually reduce loss.
Significance. If the empirical isolation results hold, the work usefully cautions the community against overclaiming superiority of adaptive patching without strong uniform baselines. The controlled experimental design (fixed backbone and protocol) is a clear strength and provides reproducible evidence that uniform patching is often competitive on standard long-horizon benchmarks. The theoretical framing supplies concrete conditions (threshold, bounds) under which adaptivity can help, which could guide future routing-signal design. No machine-checked proofs or parameter-free derivations are present, but the falsifiable prediction that uniform baselines will match or exceed adaptive methods under the stated assumptions is directly tested.
major comments (2)
- [Abstract and modeling section] Abstract and modeling section: the derivation of the explicit threshold, quadratic surrogate bound, and collapse of alignment gain treats the pointwise forecasting loss as separable across patches so that local complexity determines whether finer patching reduces loss above a cutoff. In the three Transformer architectures actually evaluated, however, self-attention mixes information across all patches, rendering loss reduction from a local patch-size change non-additive and dependent on global context excluded by the bitrate model. This assumption is load-bearing for the two structural results and for the claimed link between theory and the reported experimental outcome that uniform baselines are competitive.
- [Experimental section] Experimental section (controlled isolation study): while the design keeps backbone and protocol fixed, the manuscript does not report whether the uniform patch-size sweep was performed with the same computational budget or hyper-parameter search effort as the adaptive methods; if the uniform sweep received more tuning, the competitiveness result could be partly an artifact of unequal optimization rather than an intrinsic property of the patching operator.
minor comments (2)
- [modeling section] Notation for the bitrate allocation model and the strong-convexity constant should be introduced with a single consolidated table or equation block rather than scattered across the modeling section.
- [Results figures] Figure captions for the per-dataset aggregated results should explicitly state the number of random seeds and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of the controlled isolation study and the theoretical framing. We address each major comment below and will incorporate clarifications in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and modeling section] Abstract and modeling section: the derivation of the explicit threshold, quadratic surrogate bound, and collapse of alignment gain treats the pointwise forecasting loss as separable across patches so that local complexity determines whether finer patching reduces loss above a cutoff. In the three Transformer architectures actually evaluated, however, self-attention mixes information across all patches, rendering loss reduction from a local patch-size change non-additive and dependent on global context excluded by the bitrate model. This assumption is load-bearing for the two structural results and for the claimed link between theory and the reported experimental outcome that uniform baselines are competitive.
Authors: We agree that the modeling section relies on a separable pointwise loss for deriving the threshold, quadratic bound, and structural results. This is an explicit modeling choice made for analytical tractability to obtain falsifiable predictions about when adaptivity can help. The results are stated under these assumptions and are not claimed to be exact for attention-based models. The empirical isolation study stands independently and shows uniform baselines are competitive in practice. We will revise the modeling section to more explicitly note the separability assumption and its limitations regarding global mixing in self-attention. revision: yes
-
Referee: [Experimental section] Experimental section (controlled isolation study): while the design keeps backbone and protocol fixed, the manuscript does not report whether the uniform patch-size sweep was performed with the same computational budget or hyper-parameter search effort as the adaptive methods; if the uniform sweep received more tuning, the competitiveness result could be partly an artifact of unequal optimization rather than an intrinsic property of the patching operator.
Authors: The uniform patch-size sweep used the identical training protocol, hyperparameter ranges, validation-based selection procedure, and computational budget as the adaptive methods; the sole controlled difference was replacing the adaptive mechanism with a fixed size. We will revise the experimental section to explicitly document this equivalence of effort. revision: yes
Circularity Check
No significant circularity; derivations follow from stated modeling assumptions
full rationale
The paper explicitly models patching as budgeted bitrate allocation under pointwise forecasting losses, then derives an explicit threshold, quadratic surrogate bound, and strong-convexity global bound directly from those assumptions plus local complexity. These steps are deductive from the model rather than reducing to quantities fitted on target data or self-citations. The two structural results (scalar complexity cannot yield non-uniform optimum without coupling; alignment gain collapses at representation-aware optimum) follow mathematically from the same assumptions. The empirical isolation study treats the validation-selected uniform baseline as an external comparator, not part of the derivation. No load-bearing self-citation chains, no fitted-input predictions, and no self-definitional reductions appear in the provided abstract or reader's summary. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption patching can be modeled as a budgeted bitrate allocation problem under pointwise forecasting losses
- domain assumption strong-convexity bound holds for the global improvement analysis
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[2]
The Eleventh International Conference on Learning Representations , year=
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. The Eleventh International Conference on Learning Representations , year=
-
[3]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[4]
Transactions on Machine Learning Research , year=
TSMixer: An All-MLP Architecture for Time Series Forecast-ing , author=. Transactions on Machine Learning Research , year=
-
[5]
The Thirteenth International Conference on Learning Representations , year=
SimpleTM: A simple baseline for multivariate time series forecasting , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
The Twelfth International Conference on Learning Representations , year=
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
Proceedings of the AAAI conference on artificial intelligence , volume=
Nhits: Neural hierarchical interpolation for time series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[8]
The Twelfth International Conference on Learning Representations , year=
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
Proceedings of the 41st International Conference on Machine Learning , pages=
A decoder-only foundation model for time-series forecasting , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[10]
Forty-first International Conference on Machine Learning , year=
Unified training of universal time series forecasting transformers , author=. Forty-first International Conference on Machine Learning , year=
-
[11]
Cover, T. M. and Thomas, J. A. , title =
-
[12]
arXiv preprint arXiv:2509.26157 , year=
EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting , author=. arXiv preprint arXiv:2509.26157 , year=
-
[13]
arXiv preprint arXiv:2603.11352 , year=
Timesqueeze: Dynamic patching for efficient time series forecasting , author=. arXiv preprint arXiv:2603.11352 , year=
-
[14]
arXiv preprint arXiv:2603.26097 , year=
Dynamic Tokenization via Reinforcement Patching: End-to-end Training and Zero-shot Transfer , author=. arXiv preprint arXiv:2603.26097 , year=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Timemosaic: Temporal heterogeneity guided time series forecasting via adaptive granularity patch and segment-wise decoding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
The Twelfth International Conference on Learning Representations , year=
Pathformer: Multi-scale Transformers with Adaptive Pathways for Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Dualsg: A dual-stream explicit semantic-guided multivariate time series forecasting framework , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Unlocking the power of patch: Patch-based mlp for long-term time series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
Kairos: Toward Adaptive and Parameter-Efficient Time Series Foundation Models
Kairos: Toward Adaptive and Parameter-Efficient Time Series Foundation Models , author=. arXiv preprint arXiv:2509.25826 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the AAAI conference on artificial intelligence , volume=
Hdmixer: Hierarchical dependency with extendable patch for multivariate time series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A-vit: Adaptive tokens for efficient vision transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
arXiv preprint arXiv:2506.10390 , year=
DART: Differentiable Dynamic Adaptive Region Tokenizer for Vision Foundation Models , author=. arXiv preprint arXiv:2506.10390 , year=
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vision transformers with mixed-resolution tokenization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
International Conference on Machine Learning , pages=
Patch-wise Structural Loss for Time Series Forecasting , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[26]
International Conference on Machine Learning , pages=
TimeFilter: Patch-Specific Spatial-Temporal Graph Filtration for Time Series Forecasting , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[27]
Advances in neural information processing systems , volume=
Non-stationary transformers: Exploring the stationarity in time series forecasting , author=. Advances in neural information processing systems , volume=
-
[28]
Proceedings of the IEEE international conference on computer vision , pages=
Focal loss for dense object detection , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[29]
Adaptive Computation Time for Recurrent Neural Networks
Adaptive computation time for recurrent neural networks , author=. arXiv preprint arXiv:1603.08983 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Mixture-of-depths: Dynamically allocating compute in transformer-based language models , author=. arXiv preprint arXiv:2404.02258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
The Eleventh International Conference on Learning Representations , year=
Token Merging: Your ViT But Faster , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
Concentration Inequalities: A Nonasymptotic Theory of Independence , author=
-
[33]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=
-
[34]
International conference on machine learning , pages=
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[35]
The eleventh international conference on learning representations , year=
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting , author=. The eleventh international conference on learning representations , year=
-
[36]
Transactions on Machine Learning Research , year=
Chronos: Learning the Language of Time Series , author=. Transactions on Machine Learning Research , year=
-
[37]
ArXiv , year=
Lag-Llama: Towards Foundation Models for Time Series Forecasting , author=. ArXiv , year=
-
[38]
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
The Perception-Distortion Tradeoff , author=. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
2018
-
[39]
ArXiv , year=
PonderNet: Learning to Ponder , author=. ArXiv , year=
-
[40]
ArXiv , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. ArXiv , year=
-
[41]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[42]
Proceedings of the AAAI conference on artificial intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[43]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Modeling long-and short-term temporal patterns with deep neural networks , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.