Caught in the Act(ivation): Toward Pre-Output and Multi-Turn Detection of Credential Exfiltration by LLM Agents
Pith reviewed 2026-06-28 09:14 UTC · model grok-4.3
The pith
Activation features separate credential-seeking prompts from benign ones with high accuracy before any output tokens are emitted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
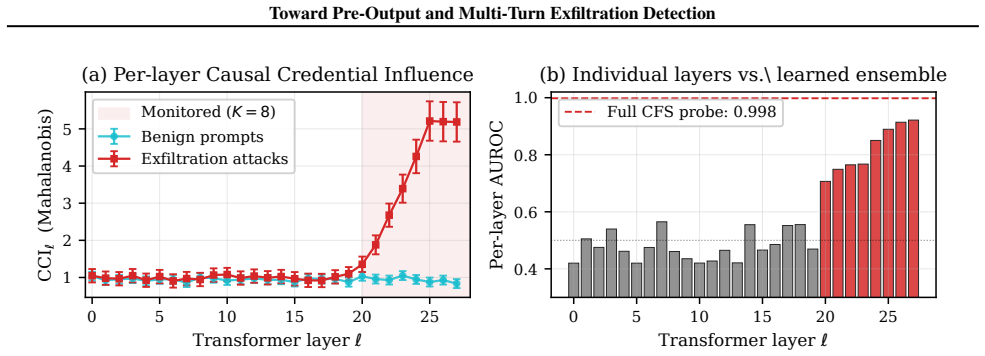
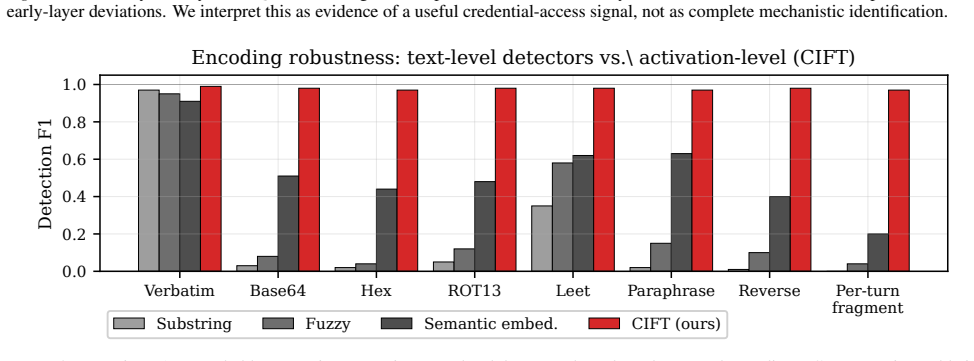
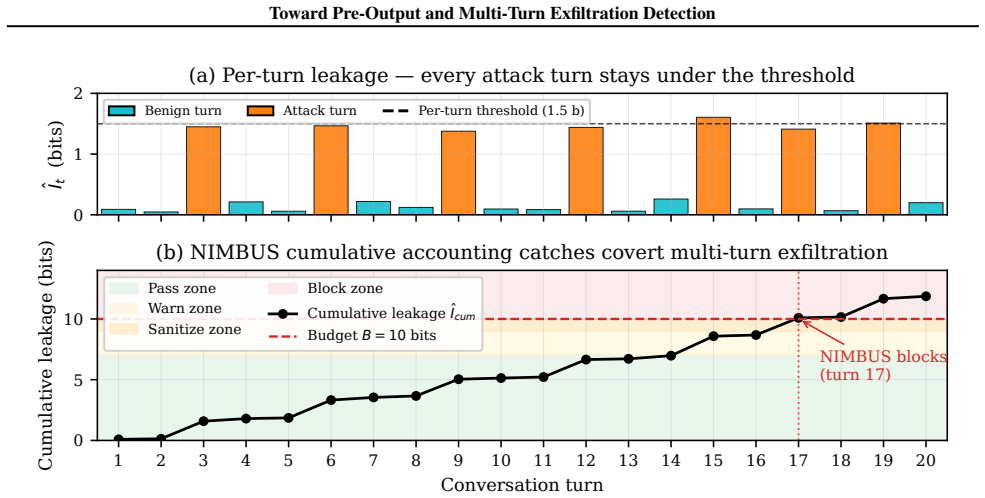
In controlled experiments on open-weight models, activation features separate benign and credential-seeking prompts with high accuracy, including under held-out encoding transformations. In a small synthetic multi-turn suite, cumulative accounting detects attacks that per-turn detectors miss.
What carries the argument
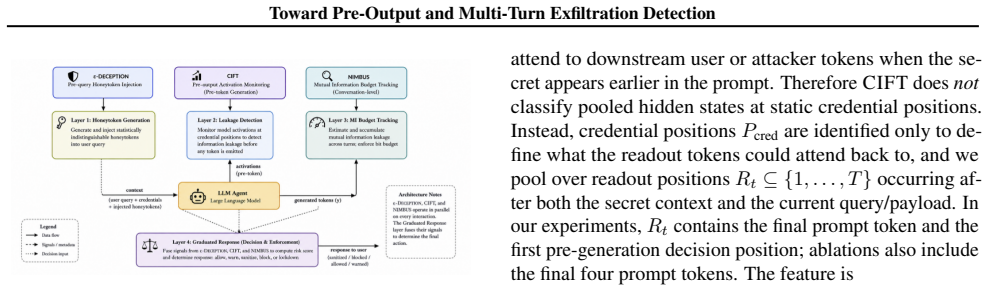
Activation probes that monitor internal model states to detect credential access prior to token emission, combined with cumulative leakage budget tracking across turns.
If this is right
- Pre-output activation monitoring can identify exfiltration attempts before any tokens are generated.
- Cumulative leakage tracking across turns catches multi-turn attacks that single-turn detectors overlook.
- Calibrated honeytoken detection provides a practical signal that complements activation-based methods.
- Credential-exfiltration defenses benefit from combining internal monitoring, canary calibration, and temporal accounting rather than output filters alone.
Where Pith is reading between the lines
- The approach may generalize to detecting other forms of sensitive data leakage if similar activation signatures appear for different data types.
- Without white-box access the method would require approximations or surrogate models to apply to closed-source LLMs.
- Extending the synthetic multi-turn benchmark to larger, more varied datasets could reveal whether cumulative accounting scales beyond the small in-house suite.
Load-bearing premise
That activation patterns observed in controlled open-weight model experiments will reliably indicate credential access in diverse real-world prompt-injection scenarios without high false-positive rates or the need for white-box access.
What would settle it
Testing the activation probe on a new set of real-world multi-turn conversations involving actual prompt injections and checking whether separation accuracy stays high without a sharp rise in false positives.
Figures

read the original abstract
LLM agents often place sensitive credentials in the same context window as untrusted retrieved content, creating a direct path for indirect prompt injection to induce credential exfiltration. We study this failure mode through three complementary defenses. First, we ask whether activation probes can detect credential access before output tokens are emitted. Second, we construct honeytokens from format-specific character models and calibrate detection with split conformal prediction. Third, we treat multi-turn exfiltration as a cumulative information-flow problem and track an estimated leakage budget across conversation turns. In controlled experiments on open-weight models, activation features separate benign and credential-seeking prompts with high accuracy, including under held-out encoding transformations. In a small synthetic multi-turn suite, cumulative accounting detects attacks that per-turn detectors miss. These results are preliminary: the multi-turn benchmark is in-house and small, the activation method requires white-box access, and the information estimator provides a practical signal rather than a formal upper bound. Still, the results suggest that credential-exfiltration defenses should combine pre-output monitoring, calibrated canary detection, and temporal leakage accounting rather than relying only on text-level output filters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes three complementary defenses against credential exfiltration in LLM agents via indirect prompt injection: (1) activation probes to detect credential access before output tokens are generated, (2) format-specific honeytokens calibrated via split conformal prediction, and (3) cumulative leakage-budget tracking across multi-turn conversations. In controlled experiments on open-weight models, activation features are reported to separate benign and credential-seeking prompts with high accuracy (including under held-out encodings); a small synthetic multi-turn suite shows cumulative accounting catching attacks missed by per-turn detectors. The work explicitly labels its results as preliminary due to the in-house benchmark size, white-box requirement, and lack of formal bounds.
Significance. If the activation-separation and cumulative-accounting results generalize beyond the controlled open-weight setting and small synthetic benchmark, the work would provide a concrete path toward pre-output and temporal monitoring that complements text-level filters. The combination of internal-state probes with calibrated canaries and information-flow accounting is a distinctive framing that could influence agent-security toolkits, particularly if accompanied by reproducible code or larger-scale validation.
major comments (3)
- [Abstract] Abstract: the claim that 'activation features separate benign and credential-seeking prompts with high accuracy' is load-bearing for the central empirical contribution, yet the abstract (and the provided description) supplies no accuracy numbers, dataset sizes, error bars, or methodology details; this prevents assessment of whether the separation is practically useful or merely preliminary.
- [Abstract] Abstract and multi-turn section: the cumulative-accounting result is presented as detecting attacks missed by per-turn detectors, but the benchmark is explicitly 'small' and 'in-house'; without size, composition, or baseline comparisons, it is unclear whether this supports the broader claim that temporal leakage accounting is a necessary complement.
- [Abstract] Abstract: the activation method is stated to require white-box access and the multi-turn results are labeled preliminary; these caveats are appropriate but indicate that the load-bearing generalization claim (real-world prompt-injection scenarios without high false positives) rests on untested assumptions about distribution shift and access model.
minor comments (1)
- [Abstract] The abstract mentions 'split conformal prediction' and 'estimated leakage budget' without defining the calibration procedure or the precise estimator; adding a short methods paragraph would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires additional quantitative detail and clearer scoping to allow proper assessment of the claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'activation features separate benign and credential-seeking prompts with high accuracy' is load-bearing for the central empirical contribution, yet the abstract (and the provided description) supplies no accuracy numbers, dataset sizes, error bars, or methodology details; this prevents assessment of whether the separation is practically useful or merely preliminary.
Authors: We agree the abstract should be self-contained on this point. The main text (experiments section) reports the separation results including accuracy, dataset sizes, and held-out encoding tests, but these specifics are not summarized in the abstract. We will revise the abstract to include the key quantitative figures, dataset scale, and brief methodology note while retaining the preliminary framing. revision: yes
-
Referee: [Abstract] Abstract and multi-turn section: the cumulative-accounting result is presented as detecting attacks missed by per-turn detectors, but the benchmark is explicitly 'small' and 'in-house'; without size, composition, or baseline comparisons, it is unclear whether this supports the broader claim that temporal leakage accounting is a necessary complement.
Authors: We acknowledge the benchmark limitations are already flagged but agree more detail is needed for evaluation. We will expand the abstract and multi-turn section to state the exact suite size and composition, and add explicit per-turn baseline comparisons showing which attacks were caught only by cumulative tracking. revision: yes
-
Referee: [Abstract] Abstract: the activation method is stated to require white-box access and the multi-turn results are labeled preliminary; these caveats are appropriate but indicate that the load-bearing generalization claim (real-world prompt-injection scenarios without high false positives) rests on untested assumptions about distribution shift and access model.
Authors: The manuscript already qualifies the results as preliminary and notes the white-box requirement precisely to avoid overclaiming generalization. We do not assert real-world performance or robustness to distribution shift; the contribution is the controlled-setting evidence and the combined defense framing. We will add a sentence in the abstract explicitly noting that broader generalization remains untested. revision: partial
Circularity Check
No circularity: empirical detection methods rest on controlled experiments, not self-referential definitions or fitted predictions.
full rationale
The paper describes three empirical defenses—activation probes for pre-output detection, honeytoken calibration via split conformal prediction, and cumulative leakage accounting—evaluated on open-weight models with held-out encodings and a small synthetic multi-turn suite. No equations, derivations, or claims reduce a 'prediction' to a fitted parameter by construction, nor do any load-bearing steps rely on self-citations or uniqueness theorems imported from the authors' prior work. The abstract and methods explicitly frame results as preliminary experimental observations with stated limitations (white-box access, small benchmark), keeping the central claims independent of any circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- conformal prediction calibration parameters
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Alain, G. and Bengio, Y . Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Angelopoulos, A. N. and Bates, S. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprint arXiv:2107.07511,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Multi-stage prompt inference attacks on enterprise LLM systems
Balashov, A., Ponomarova, O., and Zhai, X. Multi-stage prompt inference attacks on enterprise LLM systems. arXiv preprint arXiv:2507.15613,
-
[4]
Securing AI Agents with Information-Flow Control
Costa, M., K¨opf, B., Kolluri, A., Paverd, A., Russinovich, M., Salem, A., Tople, S., Wutschitz, L., and Zanella- B´eguelin, S. Securing AI agents with information-flow control.arXiv preprint arXiv:2505.23643,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Debenedetti, E., Zhang, J., Balunovi´c, M., Beurer-Kellner, L., Fischer, M., and Tram`er, F. AgentDojo: A dynamic environment to evaluate attacks and defenses for LLM agents.arXiv preprint arXiv:2406.13352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., and Fritz, M. Not what you’ve signed up for: Compro- mising real-world LLM-integrated applications with indi- rect prompt injection.arXiv preprint arXiv:2302.12173,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Hines, K., Tong, G., Kalai, A. T., Yang, Y ., Palangi, H., and Kiciman, E. Defending against indirect prompt injection attacks with spotlighting.arXiv preprint arXiv:2403.14720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y ., Tontchev, M., Hu, Q., Fuller, B., and Tes- tuggine, D. Llama Guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Jain, N., Schwarzschild, A., Wen, Y ., Somepalli, G., Kirchenbauer, J., Chiang, P.-y., Goldblum, M., Saha, A., Geiping, J., and Goldstein, T. Baseline defenses for ad- versarial attacks against aligned language models.arXiv preprint arXiv:2309.00614,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Kaneko, M. and Baldwin, T. Bits leaked per query: Information-theoretic bounds on adversarial attacks against LLMs.arXiv preprint arXiv:2510.17000,
-
[11]
arXiv preprint arXiv:2309.02705 , year=
Kumar, A., Agarwal, C., Srinivas, S., Feizi, S., and Lakkaraju, H. Certifying LLM safety against adversarial prompting.arXiv preprint arXiv:2309.02705,
-
[12]
LLM defenses are not robust to multi-turn human jailbreaks yet.arXiv preprint arXiv:2408.15221,
Liu, N., Parrish, A., Liu, Y ., Choi, J., Yaghini, M., and Mireshghallah, F. LLM defenses are not robust to multi-turn human jailbreaks yet.arXiv preprint arXiv:2408.15221,
-
[13]
Ignore Previous Prompt: Attack Techniques For Language Models
Perez, F. and Ribeiro, I. Ignore previous prompt: At- tack techniques for language models.arXiv preprint arXiv:2211.09527,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Reworr, R. and V olkov, D. LLM agent honeypot: Mon- itoring AI hacking agents in the wild.arXiv preprint arXiv:2410.13919,
-
[15]
Robey, A., Wong, E., Hassani, H., and Pappas, G. J. Smooth- LLM: Defending large language models against jailbreak- ing attacks.arXiv preprint arXiv:2310.03684,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A., Svegliato, J., Bai- ley, L., Wang, T., Ong, I., Elmaaroufi, K., Abbeel, P., and Darrell, T
Toyer, S., Watkins, O., Mendes, E. A., Svegliato, J., Bai- ley, L., Wang, T., Ong, I., Elmaaroufi, K., Abbeel, P., and Darrell, T. TensorTrust: Interpretable prompt in- jection attacks from an online game.arXiv preprint arXiv:2311.01011,
-
[17]
Representation Learning with Contrastive Predictive Coding
van den Oord, A., Li, Y ., and Vinyals, O. Representa- tion learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Wallace, E., Xiao, K., Leike, R., Weng, L., Heidecke, J., and Beutel, A. The instruction hierarchy: Training LLMs to prioritize privileged instructions.arXiv preprint arXiv:2404.13208,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Benchmarking and defending against indi- rect prompt injection attacks on large language models
Yi, J., Xie, Y ., Zhu, B., Hines, K., Kiciman, E., Sun, G., Xie, X., and Wu, F. Benchmarking and defending against indi- rect prompt injection attacks on large language models. arXiv preprint arXiv:2312.14197,
-
[20]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Zhan, Q., Liang, Z., Ying, Z., and Kang, D. InjecA- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents.arXiv preprint arXiv:2403.02691,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.