Smart Transportation Without Neurons -- Fair Metro Network Expansion with Tabular Reinforcement Learning
Pith reviewed 2026-06-28 10:59 UTC · model grok-4.3
The pith
Tabular reinforcement learning matches deep RL performance on metro network expansion while using 18 times fewer episodes and emitting 12 times less carbon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reformulating the Metro Network Expansion Problem as a Non-Markovian Rewards Decision Process, tabular RL achieves similar performance to Deep RL on instances from Xi'an and Amsterdam, with an average 18-fold reduction in total training episodes and 12-fold reduction in carbon emissions, while also incorporating social equity into the reward functions.
What carries the argument
Reformulation of MNEP as a Non-Markovian Rewards Decision Process (NMRDP) to enable tabular RL instead of deep RL.
If this is right
- Tabular RL matches Deep RL performance on real MNEP instances.
- Training requires 18 times fewer episodes on average.
- Carbon emissions from training drop by a factor of 12.
- Social equity criteria can be directly included in the reward.
- The method is more interpretable and modular than deep RL approaches.
Where Pith is reading between the lines
- Tabular RL may apply to other combinatorial optimization problems of similar size in transportation and logistics.
- Practitioners could adopt this for quicker prototyping and lower environmental impact in planning tools.
- The interpretability could help in regulatory approval for AI-driven infrastructure decisions.
- Hybrid approaches might use tabular RL on subproblems within larger networks.
Load-bearing premise
Metro network expansion problems in practice stay small enough for the state-action space to fit in tabular RL without needing deep function approximation.
What would settle it
Running the method on a significantly larger metro network where the state space grows too big, causing tabular RL to underperform or require more episodes than deep RL would falsify the efficiency claim.
Figures
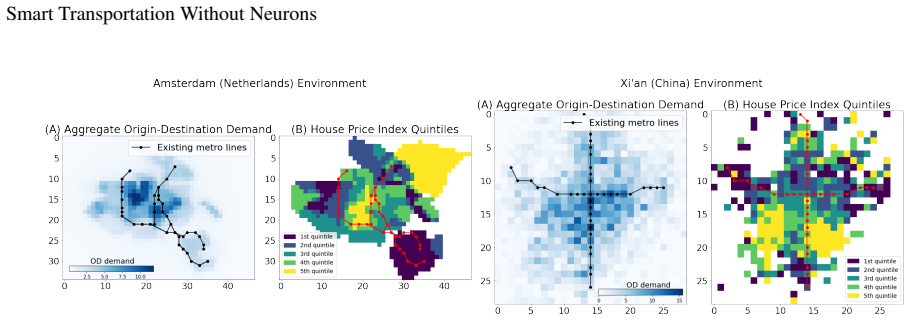
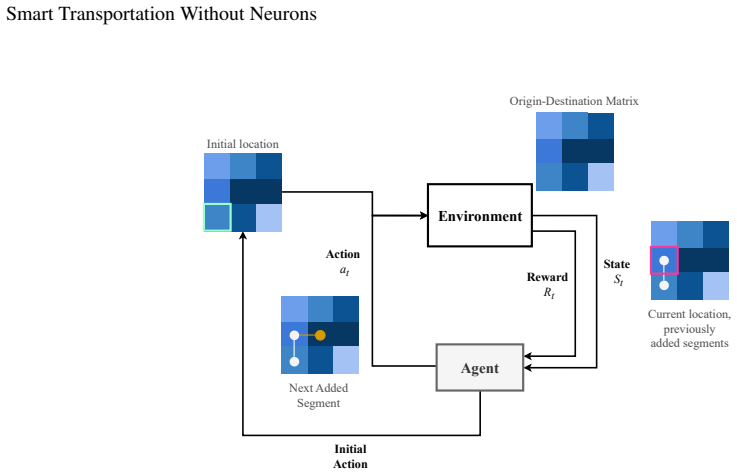
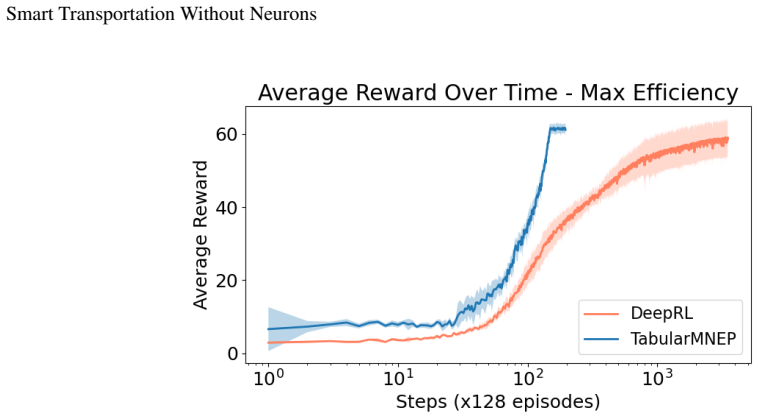
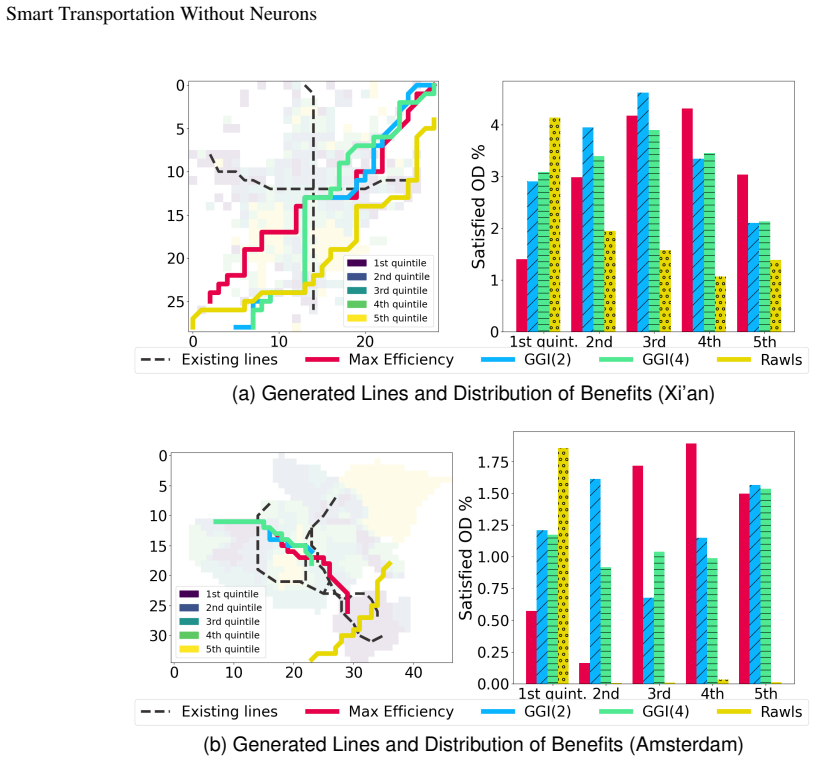

read the original abstract
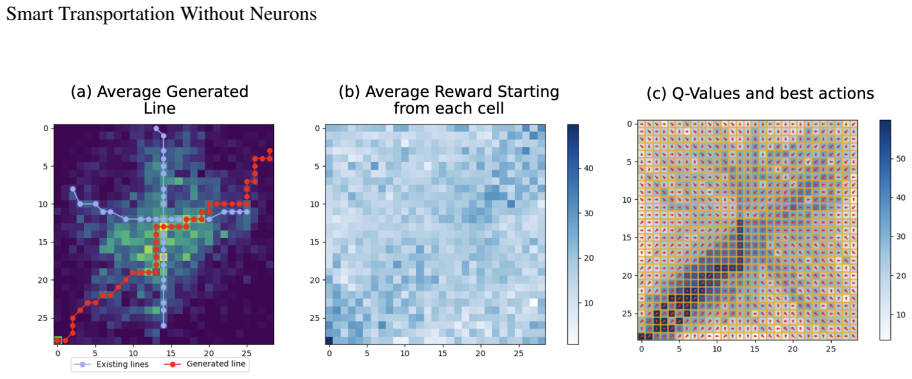
We tackle the Metro Network Expansion Problem (MNEP), a subset of the Transport Network Design Problem (TNDP), which focuses on expanding metro systems to satisfy travel demand. Traditional methods rely on exact and heuristic approaches that require expert-defined constraints to reduce the search space. Recently, deep reinforcement learning (Deep RL) has emerged due to its effectiveness in complex sequential decision-making processes-it remains, however, computationally expensive, environmentally costly, and requires additional engineering to interpret. We show that MNEP problems are small enough to not require Deep RL methods. Reformulating the MNEP as a Non-Markovian Rewards Decision Process (NMRDP), we use tabular RL to achieve similar performance with significantly fewer training episodes, additionally offering greater interpretability. Additionally, we incorporate social equity criteria into the reward functions, focusing on efficiency and fairness, highlighting the versatility of our method. Evaluated in real-world settings-Xi'an and Amsterdam-our method reduces total episodes by a factor of 18 and total carbon emissions by a factor of 12 on average, while remaining competitive with Deep RL. This approach offers a replicable, modular, interpretable, and resource-efficient solution with potential applications to other combinatorial optimization problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the Metro Network Expansion Problem (MNEP) can be reformulated as a Non-Markovian Rewards Decision Process (NMRDP) so that standard tabular reinforcement learning suffices, achieving performance competitive with deep RL on real instances from Xi'an and Amsterdam while reducing training episodes by a factor of 18 and carbon emissions by a factor of 12 on average; the approach additionally incorporates social equity criteria into the reward.
Significance. If the tractability and performance claims hold after proper quantification, the work would establish that tabular RL remains viable for a practically relevant class of transportation network design problems, delivering measurable gains in sample efficiency, environmental cost, and interpretability over deep RL while supporting multi-objective rewards that include fairness.
major comments (2)
- [Abstract] Abstract: the central claim that 'MNEP problems are small enough to not require Deep RL methods' after NMRDP reformulation is load-bearing for the contribution, yet the manuscript reports neither |S| nor |A| for the Xi'an and Amsterdam networks, nor the growth rate of the state space induced by the non-Markovian reward encoding, nor any scaling experiment. Without these quantities the reported 18× episode reduction cannot be evaluated as a general property rather than an instance-specific observation.
- [Abstract] Abstract / Evaluation section: the statements of 'similar performance' and the specific reduction factors (18× episodes, 12× carbon) are given without error bars, baseline implementation details, number of random seeds, or statistical tests comparing tabular RL against the deep RL reference. This leaves the competitiveness claim without the quantitative support required to substantiate the factor-of-18 and factor-of-12 improvements.
minor comments (1)
- [Method] The manuscript should supply pseudocode or a precise description of how the NMRDP is encoded into a standard MDP for tabular Q-learning (history augmentation, reward shaping) to permit exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which correctly identify gaps in the quantitative support for our claims. We will revise the manuscript to address these issues by adding the requested details on state and action spaces, error bars, baseline information, and statistical analysis. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'MNEP problems are small enough to not require Deep RL methods' after NMRDP reformulation is load-bearing for the contribution, yet the manuscript reports neither |S| nor |A| for the Xi'an and Amsterdam networks, nor the growth rate of the state space induced by the non-Markovian reward encoding, nor any scaling experiment. Without these quantities the reported 18× episode reduction cannot be evaluated as a general property rather than an instance-specific observation.
Authors: We agree that the manuscript does not report |S| or |A| for the evaluated networks and lacks an explicit analysis of state-space growth or scaling experiments. In the revised version we will add the state and action space sizes for both Xi'an and Amsterdam instances. We will also include a description of how the non-Markovian reward encoding affects state-space size. Because the study was limited to two real-world instances, we will revise the text to present the 18× episode reduction as an empirical observation on these practical cases rather than a general property, and we will not claim generality without additional scaling experiments. revision: partial
-
Referee: [Abstract] Abstract / Evaluation section: the statements of 'similar performance' and the specific reduction factors (18× episodes, 12× carbon) are given without error bars, baseline implementation details, number of random seeds, or statistical tests comparing tabular RL against the deep RL reference. This leaves the competitiveness claim without the quantitative support required to substantiate the factor-of-18 and factor-of-12 improvements.
Authors: We agree that the competitiveness and reduction-factor claims require additional statistical support. The revised manuscript will report means and standard deviations (error bars) over multiple random seeds, provide fuller implementation details for the deep RL baseline, state the number of seeds used, and include appropriate statistical tests comparing tabular RL against the deep RL reference. revision: yes
Circularity Check
No circularity; standard tabular RL applied to NMRDP reformulation with empirical results
full rationale
The paper's central method consists of reformulating MNEP as an NMRDP and applying off-the-shelf tabular RL, with performance measured via direct experiments on Xi'an and Amsterdam instances. No equations reduce reported gains (episode reduction, carbon savings) to quantities fitted from the same runs, no self-citation chains support load-bearing uniqueness claims, and no ansatz or renaming is smuggled in. The tractability premise is an explicit modeling assumption rather than a derived result that collapses to its inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Equity weighting coefficient in reward
axioms (1)
- domain assumption Metro Network Expansion Problem instances can be faithfully represented as a Non-Markovian Rewards Decision Process.
Reference graph
Works this paper leans on
-
[1]
Routledge, July 2016
Karel Martens.Transport Justice: Designing fair transportation systems. Routledge, July 2016. Google-Books-ID: m0yTDAAAQBAJ
2016
-
[2]
Public Transit Buses: A Green Choice Gets Greener
Marcy Lowe, Bengu Aytekin, and Gary Gereffi. Public Transit Buses: A Green Choice Gets Greener. October 2009
2009
-
[3]
Optimization and scale economies in urban bus transportation.The American Economic Review, 62(4):591–604, 1972
Herbert Mohring. Optimization and scale economies in urban bus transportation.The American Economic Review, 62(4):591–604, 1972. 11 Smart Transportation Without Neurons
1972
-
[4]
Reza Zanjirani Farahani, Elnaz Miandoabchi, W. Y . Szeto, and Hannaneh Rashidi. A review of urban transportation network design problems.European Journal of Operational Research, 229(2):281–302, September 2013
2013
-
[5]
City Metro Network Expansion with Reinforcement Learning
Yu Wei, Minjia Mao, Xi Zhao, Jianhua Zou, and Ping An. City Metro Network Expansion with Reinforcement Learning. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2646–2656, Virtual Event CA USA, August 2020. ACM
2020
-
[6]
Designing Metro Network Expansion: Deterministic and Robust Optimization Models.Networks and Spatial Economics, 23(1):317–347, March 2023
Lebing Wang, Jian Gang Jin, Gleb Sibul, and Yi Wei. Designing Metro Network Expansion: Deterministic and Robust Optimization Models.Networks and Spatial Economics, 23(1):317–347, March 2023
2023
-
[7]
Metrognn: Metro network expansion with reinforcement learning
Hongyuan Su, Yu Zheng, Jingtao Ding, Depeng Jin, and Yong Li. Metrognn: Metro network expansion with reinforcement learning. InCompanion Proceedings of the ACM on Web Conference 2024, pages 650–653, 2024
2024
-
[8]
Gilbert Laporte and Marta M. B. Pascoal. Path based algorithms for metro network design.Computers & Operations Research, 62:78–94, October 2015
2015
-
[9]
Mahmoud Owais and Mostafa K. Osman. Complete hierarchical multi-objective genetic algorithm for transit network design problem.Expert Systems with Applications, 114:143–154, December 2018
2018
-
[10]
optimising Public Bus Transit Networks Using Deep Reinforcement Learning
Ahmed Darwish, Momen Khalil, and Karim Badawi. optimising Public Bus Transit Networks Using Deep Reinforcement Learning. In2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), pages 1–7, Rhodes, Greece, September 2020. IEEE
2020
-
[11]
Naveen Raman, Sanket Shah, and John Dickerson. Data-Driven Methods for Balancing Fairness and Efficiency in Ride-Pooling.arXiv:2110.03524 [cs], October 2021. arXiv: 2110.03524
-
[12]
Sami Jullien, Mozhdeh Ariannezhad, Paul Groth, and Maarten de Rijke. A simulation environment and reinforce- ment learning method for waste reduction.arXiv preprint arXiv:2205.15455, 2022
-
[13]
Reinforcement learning for combinatorial optimization: A survey.Computers & Operations Research, 134:105400, October 2021
Nina Mazyavkina, Sergey Sviridov, Sergei Ivanov, and Evgeny Burnaev. Reinforcement learning for combinatorial optimization: A survey.Computers & Operations Research, 134:105400, October 2021
2021
-
[14]
Grigory Neustroev, Sytze P. E. Andringa, Remco A. Verzijlbergh, and Mathijs M. De Weerdt. Deep Reinforcement Learning for Active Wake Control. InProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’22, pages 944–953, Richland, SC, May 2022. International Foundation for Autonomous Agents and Multiagent Systems
2022
-
[15]
Performance of Deep Reinforcement Learning for High Frequency Market Making on Actual Tick Data
Ziyi Xu, Xue Cheng, and Yangbo He. Performance of Deep Reinforcement Learning for High Frequency Market Making on Actual Tick Data. InProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’22, pages 1765–1767, Richland, SC, May 2022. International Foundation for Autonomous Agents and Multiagent Systems
2022
-
[16]
Wolff Anthony, Benjamin Kanding, and Raghavendra Selvan
Lasse F. Wolff Anthony, Benjamin Kanding, and Raghavendra Selvan. Carbontracker: Tracking and predicting the carbon footprint of training deep learning models, 2020
2020
-
[17]
Energy and policy considerations for modern deep learning research.Proceedings of the AAAI Conference on Artificial Intelligence, 34(09):13693–13696, Apr
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for modern deep learning research.Proceedings of the AAAI Conference on Artificial Intelligence, 34(09):13693–13696, Apr. 2020
2020
-
[18]
Carbon emissions and large neural network training, 2021
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training, 2021
2021
-
[19]
Quarl: Quantization for fast and environmentally sustainable reinforcement learning, 2022
Srivatsan Krishnan, Maximilian Lam, Sharad Chitlangia, Zishen Wan, Gabriel Barth-Maron, Aleksandra Faust, and Vijay Janapa Reddi. Quarl: Quantization for fast and environmentally sustainable reinforcement learning, 2022
2022
-
[20]
Connectivity of metro station location with urban space–a study of hanoi metro line n° 2.3
Vu Thi Thuy Giang, Than Dinh Vinh, Nguyen Thanh Huyen, Dang Thi Nga, Nguyen Manh Hung, et al. Connectivity of metro station location with urban space–a study of hanoi metro line n° 2.3. InE3S Web of Conferences, volume 403, page 07008. EDP Sciences, 2023
2023
-
[21]
Playing atari with six neurons, 2019
Giuseppe Cuccu, Julian Togelius, and Philippe Cudre-Mauroux. Playing atari with six neurons, 2019
2019
-
[22]
A path-based greedy algorithm for multi-objective transit routes design with elastic demand.Public Transport, 8:261–293, 2016
Amirali Zarrinmehr, Mahmoud Saffarzadeh, Seyedehsan Seyedabrishami, and Yu Marco Nie. A path-based greedy algorithm for multi-objective transit routes design with elastic demand.Public Transport, 8:261–293, 2016
2016
-
[23]
Corridor-based metro network design with travel flow capture.Computers & Operations Research, 89:58–67, January 2018
Gabriel Gutiérrez-Jarpa, Gilbert Laporte, and Vladimir Marianov. Corridor-based metro network design with travel flow capture.Computers & Operations Research, 89:58–67, January 2018
2018
-
[24]
Machemehl
Wei Fan and Randy B. Machemehl. Using a Simulated Annealing Algorithm to Solve the Transit Route Network Design Problem.Journal of Transportation Engineering, 132(2):122–132, February 2006. Publisher: American Society of Civil Engineers
2006
-
[25]
Approximate multi-objective optimization for integrated bus route design and service frequency setting.Transportation Research Part B: Methodological, 155:1–25, January 2022
Zeke Ahern, Alexander Paz, and Paul Corry. Approximate multi-objective optimization for integrated bus route design and service frequency setting.Transportation Research Part B: Methodological, 155:1–25, January 2022. 12 Smart Transportation Without Neurons
2022
-
[26]
A parallel ant colony algorithm for bus network optimization
Zhongzhen Yang, Bin Yu, and Chuntian Cheng. A parallel ant colony algorithm for bus network optimization. Computer-Aided Civil and Infrastructure Engineering, 22(1):44–55, 2007
2007
-
[27]
W. Y . Szeto and Y . Jiang. Transit route and frequency design: Bi-level modeling and hybrid artificial bee colony algorithm approach.Transportation Research Part B: Methodological, 67:235–263, 2014
2014
-
[28]
Solving transit network design problem using many- objective evolutionary approach.IEEE Transactions on Intelligent Transportation Systems, 20(10):3952–3963, 2018
Muhammad Ali Nayeem, Md Monirul Islam, and Xin Yao. Solving transit network design problem using many- objective evolutionary approach.IEEE Transactions on Intelligent Transportation Systems, 20(10):3952–3963, 2018
2018
-
[29]
Deep reinforcement learning for transportation network combinatorial optimization: A survey.Knowledge-Based Systems, 233:107526, December 2021
Qi Wang and Chunlei Tang. Deep reinforcement learning for transportation network combinatorial optimization: A survey.Knowledge-Based Systems, 233:107526, December 2021
2021
-
[30]
Machine learning for combinatorial optimization: A methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, April 2021
Yoshua Bengio, Andrea Lodi, and Antoine Prouvost. Machine learning for combinatorial optimization: A methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, April 2021
2021
-
[31]
Graph reinforcement learning for combinatorial optimization: A survey and unifying perspective,
Victor-Alexandru Darvariu, Stephen Hailes, and Mirco Musolesi. Graph reinforcement learning for combinatorial optimization: A survey and unifying perspective.arXiv preprint arXiv:2404.06492, 2024
-
[32]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V . Le, Mohammad Norouzi, and Samy Bengio. Neural Combinatorial Optimization with Reinforcement Learning.arXiv:1611.09940 [cs, stat], January 2017. arXiv: 1611.09940
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Learning Heuristics for the TSP by Policy Gradient
Michel Deudon, Pierre Cournut, Alexandre Lacoste, Yossiri Adulyasak, and Louis-Martin Rousseau. Learning Heuristics for the TSP by Policy Gradient. In Willem-Jan van Hoeve, editor,Integration of Constraint Program- ming, Artificial Intelligence, and Operations Research, Lecture Notes in Computer Science, pages 170–181, Cham,
-
[34]
Reinforcement learning for solving the vehicle routing problem
MohammadReza Nazari, Afshin Oroojlooy, Lawrence Snyder, and Martin Takac. Reinforcement learning for solving the vehicle routing problem. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[35]
Attention, learn to solve routing problems! InInternational Conference on Learning Representations, 2018
Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! InInternational Conference on Learning Representations, 2018
2018
-
[36]
Metrozero: Deep reinforcement learning and monte carlo tree search for optimized metro network expansion.IEEE Transactions on Intelligent Transportation Systems, 2024
Khaled Alkilane and Der-Horng Lee. Metrozero: Deep reinforcement learning and monte carlo tree search for optimized metro network expansion.IEEE Transactions on Intelligent Transportation Systems, 2024
2024
-
[37]
Planning spatial networks with monte carlo tree search.Proceedings of the Royal Society A, 479(2269):20220383, 2023
Victor-Alexandru Darvariu, Stephen Hailes, and Mirco Musolesi. Planning spatial networks with monte carlo tree search.Proceedings of the Royal Society A, 479(2269):20220383, 2023
2023
-
[38]
City metro network expansion based on multi-objective reinforcement learning.Transportation Research Part C: Emerging Technologies, 169:104880, 2024
Liqing Zhang, Leong Hou U, Shaoquan Ni, Dingjun Chen, Zhenning Li, Wenxian Wang, and Weizhi Xian. City metro network expansion based on multi-objective reinforcement learning.Transportation Research Part C: Emerging Technologies, 169:104880, 2024
2024
-
[39]
Fairness in Transport Network Design - A Multi-Objective Reinforcement Learning Approach.Adaptive and Learning Agents Workshop, 2023
Dimitris Michailidis, Willem Röpke, Sennay Ghebreab, Diederik M Roijers, and Fernando P Santos. Fairness in Transport Network Design - A Multi-Objective Reinforcement Learning Approach.Adaptive and Learning Agents Workshop, 2023
2023
-
[40]
Hamid Behbahani, Sobhan Nazari, Masood Jafari Kang, and Todd Litman. A conceptual framework to formulate transportation network design problem considering social equity criteria.Transportation Research Part A: Policy and Practice, 125:171–183, July 2019
2019
-
[41]
Discussing Equity and Social Exclusion in Accessibility Evaluations
Bert van Wee. Discussing Equity and Social Exclusion in Accessibility Evaluations. page 18, 2011
2011
-
[42]
Rafael H. M. Pereira, David Banister, Tim Schwanen, and Nate Wessel. Distributional effects of transport policies on inequalities in access to opportunities in Rio de Janeiro.Journal of Transport and Land Use, 12(1):741–764,
-
[43]
Publisher: Journal of Transport and Land Use
-
[44]
van der Veen, Jan Anne Annema, Karel Martens, Bart van Arem, and Gonçalo Homem de Almeida Correia
Anne S. van der Veen, Jan Anne Annema, Karel Martens, Bart van Arem, and Gonçalo Homem de Almeida Correia. Operationalizing an indicator of sufficient accessibility – a case study for the city of Rotterdam.Case Studies on Transport Policy, 8(4):1360–1370, 2020
2020
-
[45]
Uneven mobilities, uneven opportunities: Social distribution of public transport accessibility to jobs and education in Montevideo.Journal of Transport Geography, 67:119–125, 2018
Diego Hernandez. Uneven mobilities, uneven opportunities: Social distribution of public transport accessibility to jobs and education in Montevideo.Journal of Transport Geography, 67:119–125, 2018
2018
-
[46]
Nurul Habib
Steven Farber, Keith Bartholomew, Xiao Li, Antonio Páez, and Khandker M. Nurul Habib. Assessing social equity in distance based transit fares using a model of travel behavior.Transportation Research Part A: Policy and Practice, 67:291–303, September 2014
2014
-
[47]
The cost of equity: Assessing transit accessibility and social disparity using total travel cost.Transportation Research Part A: Policy and Practice, 91:302–316, September 2016
Ahmed El-Geneidy, David Levinson, Ehab Diab, Genevieve Boisjoly, David Verbich, and Charis Loong. The cost of equity: Assessing transit accessibility and social disparity using total travel cost.Transportation Research Part A: Policy and Practice, 91:302–316, September 2016. 13 Smart Transportation Without Neurons
2016
-
[48]
Evaluating the spatial equity of bus rapid transit-based accessibility patterns in a developing country: The case of Cali, Colombia.Transport Policy, 20:36–46, March 2012
Elizabeth Cahill Delmelle and Irene Casas. Evaluating the spatial equity of bus rapid transit-based accessibility patterns in a developing country: The case of Cali, Colombia.Transport Policy, 20:36–46, March 2012
2012
-
[49]
Dimitra Pyrialakou, Konstantina Gkritza, and Jon D
V . Dimitra Pyrialakou, Konstantina Gkritza, and Jon D. Fricker. Accessibility, mobility, and realized travel behavior: Assessing transport disadvantage from a policy perspective.Journal of Transport Geography, 51:252– 269, February 2016
2016
-
[50]
Assessing the spatial accessibility and spatial equity of public libraries’ physical locations.Library & Information Science Research, 43(2):101089, April 2021
Wenting Cheng, Jiahui Wu, William Moen, and Lingzi Hong. Assessing the spatial accessibility and spatial equity of public libraries’ physical locations.Library & Information Science Research, 43(2):101089, April 2021
2021
-
[51]
Govardana Sachithanandam Ramachandran, Ivan Brugere, Lav R. Varshney, and Caiming Xiong. GAEA: Graph Augmentation for Equitable Access via Reinforcement Learning.arXiv:2012.03900 [cs], April 2021. arXiv: 2012.03900
-
[52]
David Tedjopurnomo, Zhifeng Bao, Farhana Choudhury, Hui Luo, and A. K. Qin. Equitable Public Bus Network Optimization for Social Good: A Case Study of Singapore. In2022 ACM Conference on Fairness, Accountability, and Transparency, pages 278–288, Seoul Republic of Korea, June 2022. ACM
2022
-
[53]
Transit network design and scheduling: A global review.Transportation Research Part A: Policy and Practice, 42(10):1251–1273, 2008
Valérie Guihaire and Jin-Kao Hao. Transit network design and scheduling: A global review.Transportation Research Part A: Policy and Practice, 42(10):1251–1273, 2008
2008
-
[54]
Umer Siddique, Paul Weng, and Matthieu Zimmer. Learning Fair Policies in Multiobjective (Deep) Reinforcement Learning with Average and Discounted Rewards.arXiv:2008.07773 [cs], August 2020. arXiv: 2008.07773
-
[55]
Reinforcement Learning with Non-Markovian Rewards.Proceedings of the AAAI Conference on Artificial Intelligence, 34(04):3980–3987, April 2020
Maor Gaon and Ronen Brafman. Reinforcement Learning with Non-Markovian Rewards.Proceedings of the AAAI Conference on Artificial Intelligence, 34(04):3980–3987, April 2020
2020
-
[56]
Markus Schläpfer, Lei Dong, Kevin O’Keeffe, Paolo Santi, Michael Szell, Hadrien Salat, Samuel Anklesaria, Mohammad Vazifeh, Carlo Ratti, and Geoffrey B. West. The universal visitation law of human mobility.Nature, 593(7860):522–527, May 2021. Number: 7860 Publisher: Nature Publishing Group
2021
-
[57]
Quantifying the carbon emissions of machine learning, 2019
Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. Quantifying the carbon emissions of machine learning, 2019
2019
-
[58]
Mesa, Francisco A
Gilbert Laporte, Juan A. Mesa, Francisco A. Ortega, and Ignacio Sevillano. Maximizing Trip Coverage in the Location of a Single Rapid Transit Alignment.Annals of Operations Research, 136(1):49–63, April 2005
2005
-
[59]
Learning to boost resilience of complex networks via neural edge rewiring.Transactions on Machine Learning Research, 2023
Shanchao Yang, MA KAILI, Baoxiang Wang, Tianshu Yu, and Hongyuan Zha. Learning to boost resilience of complex networks via neural edge rewiring.Transactions on Machine Learning Research, 2023. 14 Smart Transportation Without Neurons Appendix A Feasibility Rules The feasibility rules applied in this paper closely resemble those in previous studies [5, 38]....
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.