MimeLens: Position-Agnostic Content-Type Detection for Binary Fragments
Pith reviewed 2026-06-28 09:11 UTC · model grok-4.3
The pith
MimeLens classifies file types from arbitrary binary fragments by pretraining BERT-style encoders on random-offset windows instead of file heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
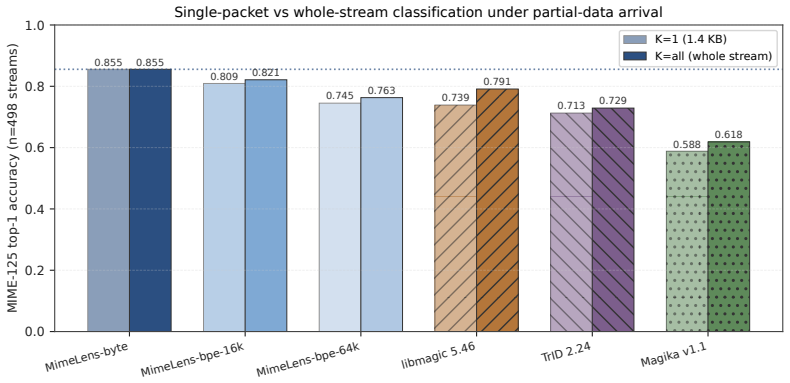
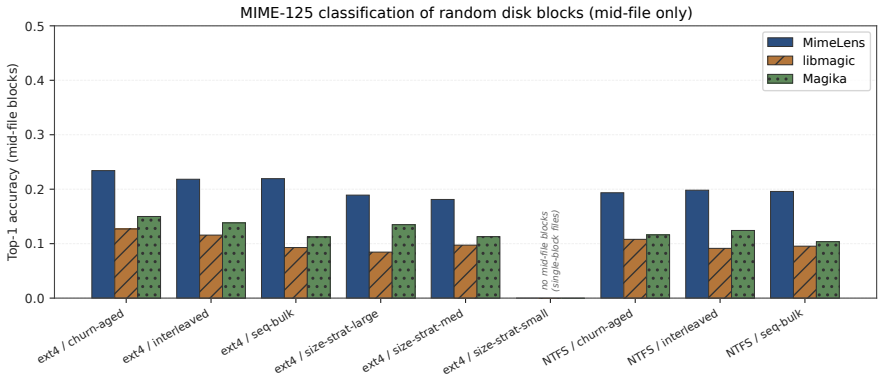
MimeLens consists of small BERT-style encoders pretrained on binary content drawn from windows sampled at a uniformly random offset inside each file, with no privileged head-of-file position. A byte chunk of any length from anywhere inside a file is mapped directly to one of libmagic's 125 MIME labels. On the clean heads of complete files the model exceeds Magika v1.1 top-1 accuracy by 10.7 points on libmagic-labeled data; the same model continues to classify single mid-stream UDP packets and achieves more than twice the accuracy of both libmagic and Magika on random mid-file disk blocks.
What carries the argument
Random-offset window sampling during pretraining of BERT-style encoders on raw binary bytes, removing any dependence on file-head position or fixed chunk size.
If this is right
- Classifies single mid-stream UDP packet payloads where Magika cannot run.
- More than doubles accuracy of libmagic and Magika on random mid-file disk blocks.
- Works on header-less carved fragments and chunked uploads without reconstruction.
- Standard- and short-context variants allow trade-offs between accuracy and speed.
- All trained checkpoints released for direct use or further fine-tuning.
Where Pith is reading between the lines
- The same random-offset pretraining could be applied to other binary tasks such as partial malware signature matching without full-file access.
- GPU or batched inference removes the reported CPU latency gap, enabling deployment in high-throughput network or storage pipelines.
- Extending the label set beyond libmagic's 125 classes would require only retraining the final classifier head while keeping the position-agnostic encoder.
Load-bearing premise
Libmagic labels are treated as reliable ground truth for both training and evaluation, and random-offset sampling is assumed to capture all distinguishing features without introducing biases absent from real fragments.
What would settle it
A test set of fragments drawn from files whose libmagic labels were independently verified by multiple tools shows MimeLens top-1 accuracy falling below Magika on the same clean-head data.
Figures
read the original abstract
File-type classification underlies many workflows like malware triage, forensic carving, packet inspection, and storage indexing. Learned systems such as Google's Magika assume whole-file access at a known offset, so they break on the inputs many of these tasks actually produce, like a single packet payload, a header-less carved fragment, a random disk block, or a chunked upload. We introduce MimeLens, a family of small BERT-style encoders pretrained on binary content from windows sampled at a uniformly random offset within each file, with no privileged head-of-file position, in standard- and short-context variants. A byte chunk goes in from anywhere in a file, no header needed and no fixed size; out comes one of libmagic's 125 MIME labels. On the clean head of complete files, MimeLens beats Magika v1.1 by +10.7 pp top-1 on libmagic-labeled data, and it keeps classifying where Magika cannot: from a single mid-stream UDP packet, and more than twice as accurately as libmagic and Magika on random mid-file disk blocks. The cost is latency: MimeLens runs roughly one to two orders of magnitude slower per sample on CPU than Magika, though it matches on consumer GPUs or in batch. All trained checkpoints are released on Hugging Face (mjbommar/mimelens-001-*).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MimeLens, a family of small BERT-style encoders pretrained on binary content from windows sampled at uniformly random offsets within files (no privileged head position). It outputs one of 125 libmagic MIME labels and claims +10.7 pp top-1 accuracy over Magika v1.1 on clean file heads, plus the ability to classify single mid-stream UDP packets and random mid-file disk blocks at more than twice the accuracy of libmagic and Magika.
Significance. If the fragment-performance claims hold under independent validation, the work would advance practical position-agnostic file-type detection for forensics, packet inspection, and carving. Releasing all trained checkpoints on Hugging Face is a clear strength for reproducibility.
major comments (2)
- [Results / Evaluation] Evaluation of mid-file and packet accuracy: reported gains on random mid-file disk blocks and single UDP packets are measured solely as agreement with the parent file's libmagic label. Because the model is trained on the same libmagic labels and no independent ground-truth or per-class analysis of head-only vs. distributed magic is supplied, the >2x claim on fragments rests on an untested assumption that type-discriminating features are uniformly present outside headers.
- [Abstract / Methods] Missing experimental details: the abstract states precise deltas (+10.7 pp top-1, >2x on blocks) yet supplies no dataset sizes, train/test split ratios, number of files per MIME class, or statistical significance tests. These quantities are load-bearing for assessing whether the reported improvements are reliable.
minor comments (1)
- [Abstract] Latency statement ('roughly one to two orders of magnitude slower per sample on CPU') would benefit from concrete wall-clock numbers or batch-size conditions to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on MimeLens. We address each major point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Results / Evaluation] Evaluation of mid-file and packet accuracy: reported gains on random mid-file disk blocks and single UDP packets are measured solely as agreement with the parent file's libmagic label. Because the model is trained on the same libmagic labels and no independent ground-truth or per-class analysis of head-only vs. distributed magic is supplied, the >2x claim on fragments rests on an untested assumption that type-discriminating features are uniformly present outside headers.
Authors: We agree that fragment labels are inherited from the parent file and that no independent per-fragment ground truth exists. This is an inherent limitation when evaluating on unlabeled carved blocks or packets. Because training uses uniformly random offsets, the model is explicitly incentivized to discover type signals outside headers; the observed gains on fragments therefore reflect the success of that training regime relative to header-dependent baselines. We will add an explicit limitations paragraph stating the proxy-label assumption and include per-class head-versus-random-offset accuracy tables to show where distributed features suffice. revision: partial
-
Referee: [Abstract / Methods] Missing experimental details: the abstract states precise deltas (+10.7 pp top-1, >2x on blocks) yet supplies no dataset sizes, train/test split ratios, number of files per MIME class, or statistical significance tests. These quantities are load-bearing for assessing whether the reported improvements are reliable.
Authors: The referee is correct that the abstract and high-level methods description omit these quantities. We will revise the manuscript to include a concise dataset table (total files, files per MIME class or at least summary statistics, exact train/test split ratios) and report bootstrap confidence intervals or appropriate significance tests for the accuracy deltas. revision: yes
Circularity Check
No significant circularity; external libmagic labels used as independent benchmark
full rationale
The paper trains on and evaluates against labels produced by the external libmagic tool on held-out files and fragments. All reported metrics (head-of-file accuracy, UDP packet, mid-file blocks) are measured as agreement with these external labels or as comparisons to Magika and libmagic itself. No derivation step reduces a claimed prediction to a quantity defined by the model's own fitted parameters, no self-citation chain is load-bearing, and no ansatz or uniqueness result is imported from prior author work. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- context-length variants
axioms (1)
- domain assumption libmagic MIME labels constitute accurate and unbiased ground truth for supervised training and evaluation
Reference graph
Works this paper leans on
-
[1]
Nicole L. Beebe, Laurence A. Maddox, Lishu Liu, and Minghe Sun. Sceadan: Using concate- nated n-gram vectors for improved file and data type classification.IEEE Transactions on Information Forensics and Security, 8(9), 2013. Available athttps://doi.org/10.1109/TIFS. 2013.2274728
-
[2]
Clark, Dan Garrette, Iulia Turc, and John Wieting
Jonathan H. Clark, Dan Garrette, Iulia Turc, and John Wieting. CANINE: Pre-training an efficient tokenization-free encoder for language representation.Transactions of the Association for Computational Linguistics, 10, 2022. Available athttps://arxiv.org/abs/2103.06874
-
[3]
Apache tika
Apache Software Foundation. Apache tika. Available athttps://tika.apache.org/. 11
-
[4]
Magika: AI-Powered Content-Type Detection
Yanick Fratantonio, Luca Invernizzi, Loua Farah, Kurt Thomas, Marina Zhang, Ange Albertini, Francois Galilee, Giancarlo Metitieri, Julien Cretin, Alex Petit-Bianco, David Tao, and Elie Bursztein. Magika: AI-Powered Content-Type Detection. InProceedings of the 47th IEEE/ACM International Conference on Software Engineering (ICSE), 2025. arXiv:2409.13768. Av...
-
[5]
Michael J. Bommarito II. Binary-30K: A heterogeneous dataset for deep learning in bi- nary analysis and malware detection, 2025. Multi-platform dataset of29 ,793unique bi- nary executables (ELF, PE, Mach-O, APK; ∼33 GB; ∼27% malware) stratified across Linux, Windows, macOS, and Android. https://arxiv.org/abs/2511.22095; dataset at https://huggingface.co/d...
-
[6]
Michael J. Bommarito II. Binary BPE: A family of cross-platform tokenizers for binary analysis, 2025. https://arxiv.org/abs/2511.17573; tokenizers at https://huggingface. co/mjbommar/binary-tokenizer-001-64kand sibling repos
-
[7]
Bommarito II
Michael J. Bommarito II. glaurung: A binary-analysis toolkit, 2025. Open-source binary- analysis tooling (loaders, disassembly, and feature extraction). Available athttps://github. com/mjbommar/glaurung
2025
-
[8]
Byte latent transformer: Patches scale better than tokens
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, and Srinivasan Iyer. Byte latent transformer: Patches scale better than tokens. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL),
-
[9]
Available athttps://arxiv.org/abs/2412.09871
arXiv:2412.09871. Available athttps://arxiv.org/abs/2412.09871
-
[10]
TrID – file identifier
Marco Pontello. TrID – file identifier. Curated signature database; available athttps://mark0. net/soft-trid-e.html
-
[11]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568, 2024. Original arXiv 2104.09864 (2021). Available athttps://arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. ByT5: Towards a token-free future with pre-trained byte-to-byte models.Transactions of the Association for Computational Linguistics, 10, 2022. Available at https://arxiv.org/abs/2105.13626
-
[13]
Christos Zoulas and contributors. file/libmagic. Available athttps://www.darwinsys.com/ file/. 12 A Model family and within-cube results The three deployed cells are seed-1 of themediumlayer of a3× 4 × {2, 3} factorial cube: three model sizes (tiny3.15M backbone /4layers;small14 .16M /8;medium37 .76M /12, head dim 64, hidden512) crossed with four input pi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.