Dual Advantage Fields
Pith reviewed 2026-06-28 10:40 UTC · model grok-4.3
The pith
Dual Advantage Fields extracts local action advantages from bilinear dual value models by aligning predicted feature displacements with the goal gradient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
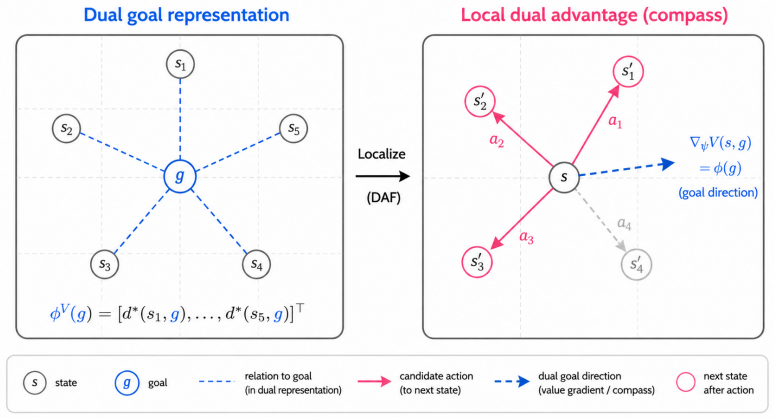
Under the bilinear dual parameterization the goal embedding is exactly the gradient of the value field with respect to the state representation. DAF therefore learns an action-effect model that predicts the discounted feature displacement induced by an action and defines the advantage of that action as the inner product between the predicted displacement and the goal embedding. In the realizable case this inner-product score is identical to the goal-conditioned Bellman advantage and therefore supplies the standard local policy-improvement guarantee.
What carries the argument
The action-effect model that predicts discounted feature displacement; its inner product with the goal embedding (gradient of the value field) supplies the advantage score.
If this is right
- The extracted policy satisfies the standard local improvement guarantee of goal-conditioned Bellman advantages.
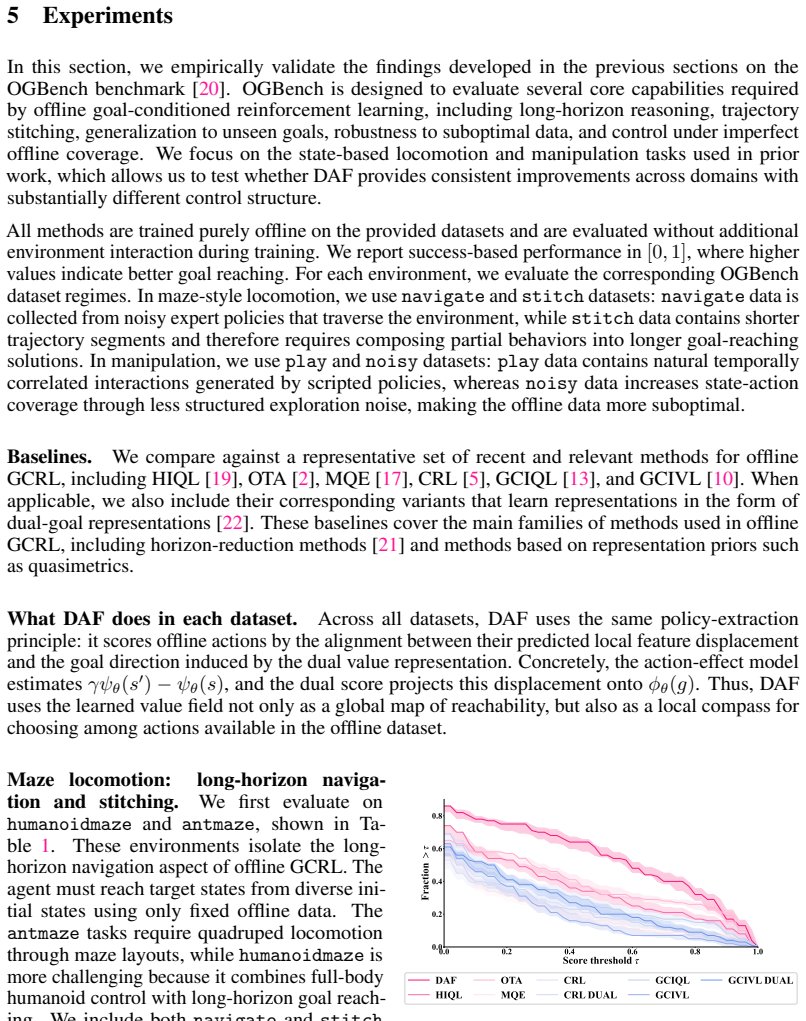
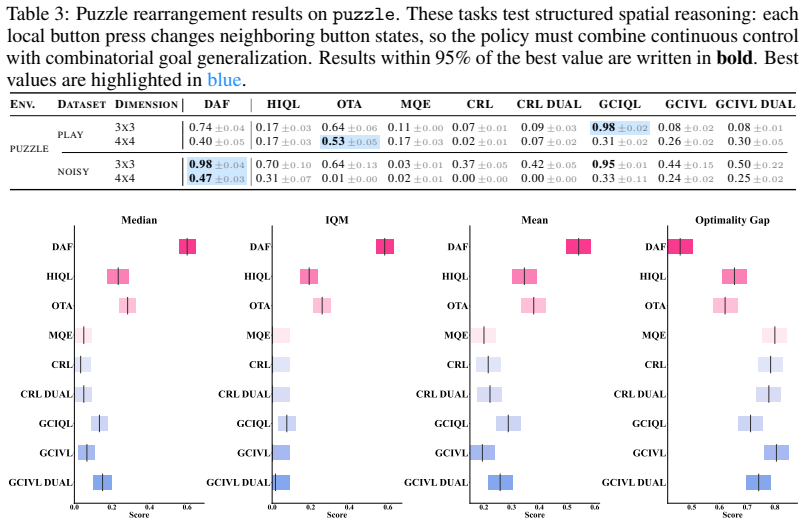
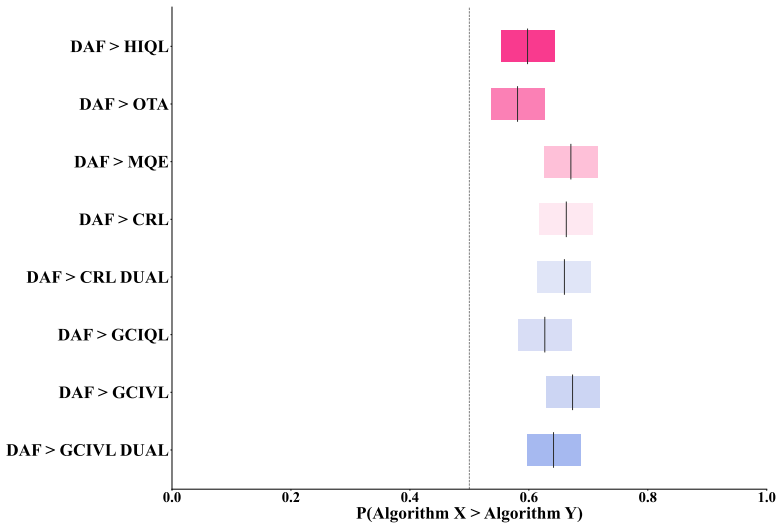
- DAF improves aggregate RLiable metrics on locomotion, manipulation, and puzzle tasks from OGBench.
- The method remains effective in settings where the locally optimal action differs from direct movement toward the final goal.
- Global reachability information stored in the dual value field can be converted into locally correct action rankings without additional value-function fitting.
Where Pith is reading between the lines
- The same displacement-alignment construction could be applied to extract policies from any dual representation whose embedding acts as a directional gradient.
- Testing whether the advantage equality continues to hold approximately when the bilinear assumption is mildly violated would clarify the method's robustness.
- The action-effect model itself might serve as a learned dynamics model for planning in other goal-conditioned settings.
- Connecting the feature-displacement prediction to contrastive or representation-learning objectives could reduce the sample cost of training the action-effect model.
Load-bearing premise
The value model must be bilinearly parameterized so that the goal embedding equals the gradient of the value field with respect to the state representation.
What would settle it
A counter-example in which the bilinear dual value model is realizable yet the proposed alignment score differs from the goal-conditioned Bellman advantage, or an experiment in which DAF fails to improve local policy performance on the reported OGBench tasks.
Figures


read the original abstract
Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dual Advantage Fields (DAF), a policy-extraction method for offline goal-conditioned RL. It converts a bilinear dual value model into a local advantage signal by learning an action-effect model that predicts the discounted feature displacement of an action and scoring actions via alignment between this displacement and the goal embedding (defined as the gradient of the value field w.r.t. the state representation). Under the realizable case with this bilinear parameterization and an exact action-effect model, the alignment score equals the goal-conditioned Bellman advantage and yields a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs well when locally correct actions differ from direct movement toward the goal.
Significance. If the realizability assumption holds, the work supplies a clean theoretical link between global reachability in dual goal representations and local action selection, with explicit credit due for conditioning the central claim on the realizable case and for recovering the inner-product form of the advantage via alignment. The empirical gains across diverse task types indicate practical utility beyond direct goal-directed movement. The approach could be significant for offline goal-conditioned RL settings where separate long-horizon and local-comparison mechanisms are needed.
major comments (2)
- [Abstract] Abstract: the equivalence of the alignment score to the goal-conditioned Bellman advantage is stated only under the realizable-case assumption with bilinear dual parameterization (goal embedding equals gradient of value field); the manuscript provides no verification procedure or diagnostic for this assumption in the learned models.
- [Empirical evaluation] Empirical evaluation (OGBench results): aggregate RLiable improvements are reported without error bars, statistical tests, or ablations that isolate the realizability condition or the action-effect model fit.
minor comments (2)
- The distinction between free parameters of the action-effect model and the value model could be made more explicit in the method description to avoid notation overlap.
- Figure captions for OGBench results should include the precise definition of the RLiable metric used.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. We address the two major comments point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the equivalence of the alignment score to the goal-conditioned Bellman advantage is stated only under the realizable-case assumption with bilinear dual parameterization (goal embedding equals gradient of value field); the manuscript provides no verification procedure or diagnostic for this assumption in the learned models.
Authors: The manuscript already conditions the claimed equivalence on the realizable case under bilinear dual parameterization, both in the abstract and in the theoretical development (Section 3). We agree, however, that the absence of any discussion of verification procedures for the assumption is a presentational gap. In the revised version we will add a short subsection discussing practical diagnostics, such as measuring the alignment between the learned goal embedding and the empirical gradient of the value field on held-out transitions, and noting the limitations of such checks. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation (OGBench results): aggregate RLiable improvements are reported without error bars, statistical tests, or ablations that isolate the realizability condition or the action-effect model fit.
Authors: We acknowledge that the reported aggregate RLiable metrics lack error bars, statistical tests, and targeted ablations. The original experiments followed the OGBench evaluation protocol, which emphasizes aggregate metrics across task suites. For the revision we will recompute the results with multiple random seeds to produce error bars, add paired statistical tests against baselines, and include an ablation that removes or perturbs the learned action-effect model while keeping the dual value model fixed, thereby isolating its contribution under the same training regime. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation states that under the realizable case with bilinear dual parameterization, the alignment score between predicted feature displacement and goal embedding equals the goal-conditioned Bellman advantage. This equality follows directly from the Bellman equation applied to the exact (realizable) action-effect model and the gradient interpretation of the goal embedding; it is not obtained by fitting parameters to the target quantity or by renaming. No self-citations are invoked as load-bearing premises, no uniqueness theorems are imported from prior author work, and the action-effect model is learned separately from the theoretical guarantee. The central claim therefore remains independent of any particular fit and is self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- action-effect model parameters
axioms (2)
- domain assumption Bilinear dual parameterization of the value model
- domain assumption Realizable case for the action-effect and value models
Reference graph
Works this paper leans on
-
[1]
Courville, and Marc G
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron C. Courville, and Marc G. Bellemare. Deep reinforcement learning at the edge of the statistical precipice. InAdvances in 9 Neural Information Processing Systems (NeurIPS), 2021
2021
-
[2]
Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning, 2025
Hongjoon Ahn, Heewoong Choi, Jisu Han, and Taesup Moon. Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning, 2025. URL https: //arxiv.org/abs/2505.12737
-
[3]
Hindsight experience replay.Advances in neural information processing systems, 30, 2017
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017
2017
-
[4]
Peter Dayan and Satinder P. Singh. Improving policies without measuring merits. In Gerald Tesauro, David Touretzky, and Todd Leen, editors,Advances in Neural Information Processing Systems, volume 8. MIT Press, 1995. URL https://proceedings.neurips.cc/paper/ 1995/hash/208e43f0e45c4c78cafadb83d2888cb6-Abstract.html
1995
-
[5]
Contrastive learning as goal- conditioned reinforcement learning
Benjamin Eysenbach, Ruslan Salakhutdinov, and Sergey Levine. Contrastive learning as goal- conditioned reinforcement learning. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[6]
Reinforcement learning from passive data via latent intentions
Dibya Ghosh, Chethan Anand Bhateja, and Sergey Levine. Reinforcement learning from passive data via latent intentions. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 11321–11339. PMLR, 2023
2023
-
[7]
Goal reaching with eikonal-constrained hier- archical quasimetric reinforcement learning
Vittorio Giammarino and Ahmed H Qureshi. Goal reaching with eikonal-constrained hier- archical quasimetric reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=5WhsCB0Vty
2026
-
[8]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Zhang-Wei Hong, Ge Yang, and Pulkit Agrawal. Bilinear value networks. InInternational Conference on Learning Representations, 2022. arXiv:2204.13695
-
[10]
Conservative offline goal-conditioned implicit v-learning
Kaiqiang Ke, Qian Lin, Zongkai Liu, Shenghong He, and Chao Yu. Conservative offline goal-conditioned implicit v-learning. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=5ryn8tYWHL
2025
-
[11]
Hierarchical quasimetric reinforcement learning
Kaiqiang Ke, Zhonghai Ruan, Shengwen Tan, and Weixia Wu. Hierarchical quasimetric reinforcement learning. InProceedings of the 2025 International Conference on Machine Learning and Neural Networks, pages 34–41, 2025
2025
-
[12]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[13]
Offline reinforcement learning with implicit Q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q-learning. InInternational Conference on Learning Representations, 2022
2022
-
[14]
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299, 2022
-
[15]
Offline goal-conditioned reinforcement learning via f-advantage regression.Advances in neural information processing systems, 35:310–323, 2022
Jason Yecheng Ma, Jason Yan, Dinesh Jayaraman, and Osbert Bastani. Offline goal-conditioned reinforcement learning via f-advantage regression.Advances in neural information processing systems, 35:310–323, 2022
2022
-
[16]
Understanding the impact of the max operation in value-based deep reinforcement learning
Gabriel Matheron, Nicolas Perrin, and Olivier Sigaud. Understanding the impact of the max operation in value-based deep reinforcement learning. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[17]
Vivek Myers, Chongyi Zheng, Anca Dragan, Sergey Levine, and Benjamin Eysenbach. Learning temporal distances: Contrastive successor features can provide a metric structure for decision- making.arXiv preprint arXiv:2406.17098, 2024. 10
-
[18]
Vivek Myers, Bill Chunyuan Zheng, Benjamin Eysenbach, and Sergey Levine. Offline goal-conditioned reinforcement learning with quasimetric representations.arXiv preprint arXiv:2509.20478, 2025
-
[19]
HIQL: Offline goal- conditioned RL with latent states as actions
Seohong Park, Dibya Ghosh, Benjamin Eysenbach, and Sergey Levine. HIQL: Offline goal- conditioned RL with latent states as actions. InAdvances in Neural Information Processing Systems, 2023. arXiv:2307.11949
-
[20]
OGBench: Benchmark- ing offline goal-conditioned RL
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. OGBench: Benchmark- ing offline goal-conditioned RL. InInternational Conference on Learning Representations,
-
[21]
Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
-
[22]
Dual goal representations.arXiv preprint arXiv:2510.06714, 2025
Seohong Park, Deepinder Mann, and Sergey Levine. Dual goal representations.arXiv preprint arXiv:2510.06714, 2025
-
[23]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning, 2019. URL https://arxiv.org/ abs/1910.00177
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
AFU: Actor-free critic updates in off-policy RL for continuous control,
Nicolas Perrin-Gilbert. AFU: Actor-free critic updates in off-policy RL for continuous control,
- [25]
-
[26]
Optimal goal-reaching reinforcement learning via quasimetric learning
Tongzhou Wang, Antonio Torralba, Phillip Isola, and Amy Zhang. Optimal goal-reaching reinforcement learning via quasimetric learning. InInternational Conference on Machine Learning, pages 36411–36430. PMLR, 2023
2023
-
[27]
distance
Ziyu Wang, Alexander Novikov, Konrad Zolna, Josh S Merel, Jost Tobias Springenberg, Scott E Reed, Bobak Shahriari, Noah Siegel, Caglar Gulcehre, Nicolas Heess, et al. Critic regularized regression.Advances in Neural Information Processing Systems, 33:7768–7778, 2020. 11 Table 4: Network configuration for DAF on OGBench. Configuration Value Gradient steps1...
2020
-
[28]
essential
Two actions are available: right (a= +1 , s→s+ 1 ) and left (a=−1 , s→s−1 ). The episode terminates upon reaching g; the reward is 0 at the goal and −1 otherwise. Hence the optimal policy always moves right fors < T, and the optimal (negative) value function is V ⋆(s, g) =s−T, s≤T. Fixed state embedding.The environment provides a feature map ψ:Z→R d with ...
-
[29]
14 in the main paper): aDAF(s) = arg max a∈{−1,+1} u(s, a)⊤ϕ(g)
DAF local advantage.Score each action by the inner product of its predicted feature displacement and the goal embedding (Eq. 14 in the main paper): aDAF(s) = arg max a∈{−1,+1} u(s, a)⊤ϕ(g). (The sparse reward, identical for both actions, is omitted from the comparison.)
-
[30]
margin <0
Hierarchical HIQL.The hierarchical policy first selects a subgoal at distance k≥2 (to the right, ssub =s+k) by comparing values of the candidate subgoals: ssub = arg max x∈{s+k,s−k} bV(x, g)− bV(s, g) . Subsequently a low -level controller attempts to reach that subgoal, using the subgoal’s own embeddingϕ(s sub)and the same flat value-difference rule: aℓ(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.