DLLG: Dynamic Logit-Level Gating of LLM Experts
Pith reviewed 2026-06-28 06:48 UTC · model grok-4.3
The pith
DLLG learns per-token fusion weights for LLM experts from response-level feedback alone
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
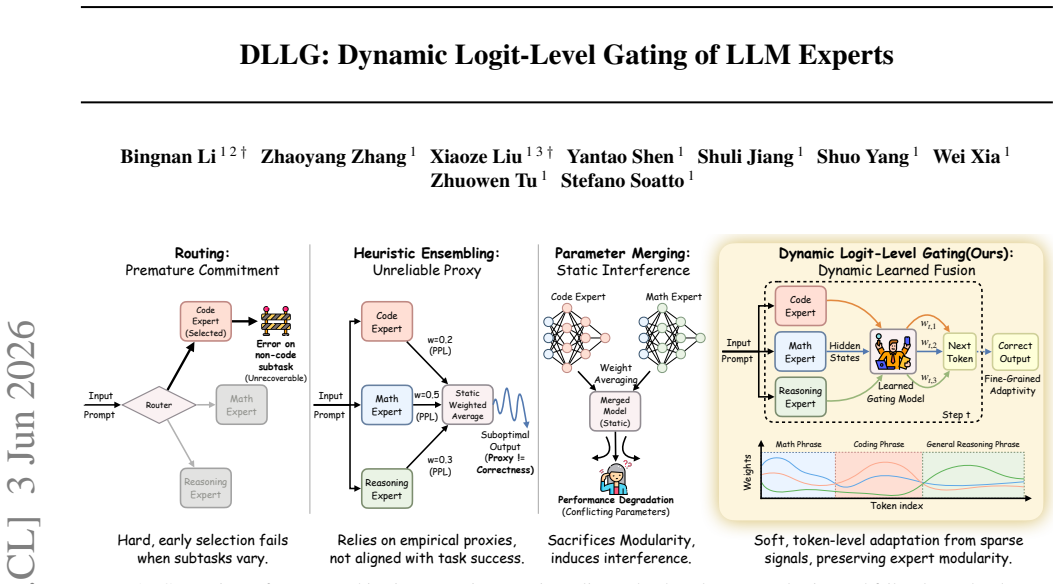
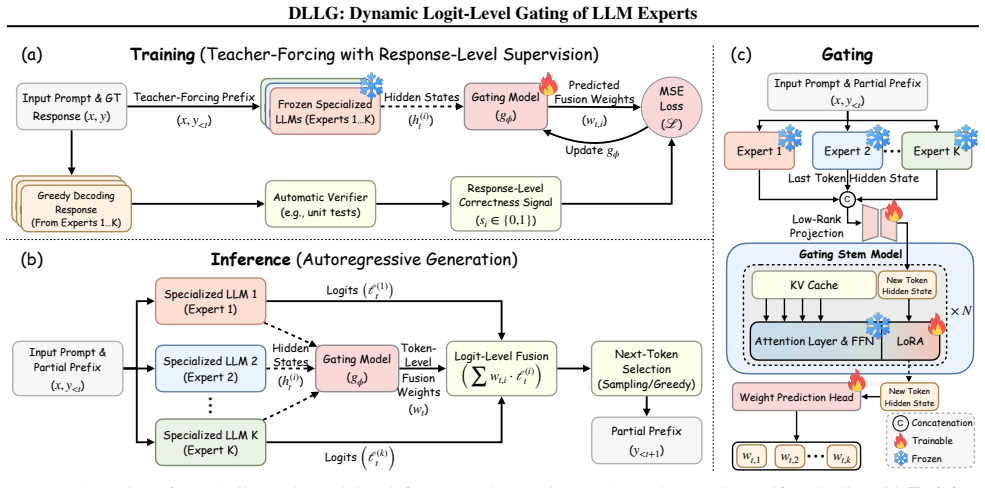
DLLG is a dynamic logit-level ensembling framework that learns token-level expert fusion from sparse response-level supervision. A lightweight gating module predicts step-wise fusion weights, linking trajectory-level correctness to generation without token-level labels or expert retraining. Across diverse reasoning and code benchmarks, DLLG consistently outperforms strong routing, heuristic ensembling, and parameter-merging baselines across model scales.
What carries the argument
The lightweight gating module that predicts step-wise fusion weights to combine expert logits dynamically at each generation step
If this is right
- DLLG outperforms routing, heuristic ensembling, and parameter-merging baselines on reasoning and code benchmarks
- The approach scales across different model sizes without retraining the underlying experts
- Learned logit-level fusion works from sparse response-level signals alone
Where Pith is reading between the lines
- The same gating idea could extend to mixing experts from different architectures or training regimes
- Response-level supervision might suffice for learning finer-grained control in other sequential decision tasks
- Combining this with routing could create hybrid systems that decide both which experts to activate and how to weight their outputs
Load-bearing premise
A lightweight gating module can learn effective step-wise fusion weights that link trajectory-level correctness to per-token generation without requiring token-level labels or expert retraining
What would settle it
Run DLLG on a new reasoning benchmark where the trained gating module produces no accuracy gain over the strongest single expert or any baseline; absence of outperformance would falsify the central claim
Figures


read the original abstract
Leveraging multiple specialized LLMs can combine complementary strengths, but existing approaches trade adaptability for stability: routing commits prematurely, heuristic ensembling depends on fragile proxies, and parameter merging introduces interference. We propose DLLG (Dynamic Logit-Level Gating), a dynamic logit-level ensembling framework that learns token-level expert fusion from sparse response-level supervision. A lightweight gating module predicts step-wise fusion weights, linking trajectory-level correctness to generation without token-level labels or expert retraining. Across diverse reasoning and code benchmarks, DLLG consistently outperforms strong routing, heuristic ensembling, and parameter-merging baselines across model scales, highlighting learned logit-level fusion as a robust and scalable paradigm for integrating specialized experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DLLG, a dynamic logit-level ensembling framework for combining specialized LLMs. A lightweight gating module is trained using only response-level correctness supervision to predict step-wise (per-token) fusion weights during generation, without requiring token-level labels or expert retraining. The central claim is that this approach consistently outperforms strong baselines in routing, heuristic ensembling, and parameter merging across reasoning and code benchmarks and multiple model scales.
Significance. If the dynamic mechanism is validated, the work could establish a scalable paradigm for expert integration that preserves adaptability while using efficient supervision. The avoidance of premature routing commitments and merging interference would be a meaningful advance, particularly if the gains are shown to stem from token-level adaptation rather than ensembling structure alone.
major comments (1)
- [Experimental results and analysis sections] The central claim requires that the gating module produces meaningfully varying step-wise fusion weights that adapt during generation and account for the reported gains. However, the manuscript provides no analysis of weight variance, entropy, or token-wise dynamics, nor ablations comparing the learned dynamic weights against their per-response averages (which would reduce to static ensembling). Without this, outperformance could arise from other aspects of the setup rather than the claimed dynamic logit-level mechanism.
minor comments (1)
- [Abstract] The abstract would benefit from including at least one quantitative performance delta or specific benchmark result rather than relying solely on the qualitative statement of consistent outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the evidence for the dynamic aspect of the gating mechanism. We agree this analysis is important to substantiate the central claims and will incorporate the suggested elements in the revision.
read point-by-point responses
-
Referee: [Experimental results and analysis sections] The central claim requires that the gating module produces meaningfully varying step-wise fusion weights that adapt during generation and account for the reported gains. However, the manuscript provides no analysis of weight variance, entropy, or token-wise dynamics, nor ablations comparing the learned dynamic weights against their per-response averages (which would reduce to static ensembling). Without this, outperformance could arise from other aspects of the setup rather than the claimed dynamic logit-level mechanism.
Authors: We acknowledge the validity of this observation. The current manuscript emphasizes end-to-end performance gains but does not include direct diagnostics of the gating module's behavior. To address this, the revised version will add: (1) quantitative analysis of weight variance and entropy across tokens and responses, (2) examples of token-wise weight trajectories during generation, and (3) an ablation replacing per-token weights with their per-response averages (reducing to static ensembling) and reporting the resulting performance drop on the benchmarks. These additions will isolate the contribution of token-level dynamics. We view this as a necessary strengthening of the experimental section. revision: yes
Circularity Check
No significant circularity; gating module trained independently on response-level signals
full rationale
The abstract and available description present DLLG as training a lightweight gating module on sparse response-level correctness to produce step-wise fusion weights. No equations, self-citations, or derivations are shown that reduce the claimed token-level predictions or performance gains to quantities defined by the inputs themselves. The central mechanism is an empirical training procedure rather than a self-definitional or fitted-input construction. This is the most common honest finding for papers whose claims rest on experimental results rather than closed-form derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[3]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Code-R1: Reproducing R1 for Code with Reliable Rewards , author=
-
[5]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[8]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions , author=. arXiv preprint arXiv:2406.15877 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Breaking the ceiling of the llm community by treating token generation as a classification for ensembling , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[10]
arXiv preprint arXiv:2410.03777 , year=
Determine-then-ensemble: Necessity of top-k union for large language model ensembling , author=. arXiv preprint arXiv:2410.03777 , year=
-
[11]
arXiv preprint arXiv:2404.11531 , year=
Pack of llms: Model fusion at test-time via perplexity optimization , author=. arXiv preprint arXiv:2404.11531 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Ensemble learning for heterogeneous large language models with deep parallel collaboration , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2404.09492 , year=
Bridging the gap between different vocabularies for llm ensemble , author=. arXiv preprint arXiv:2404.09492 , year=
-
[14]
arXiv preprint arXiv:2502.21265 , year=
Token-level Ensembling of Models with Different Vocabularies , author=. arXiv preprint arXiv:2502.21265 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Routerdc: Query-based router by dual contrastive learning for assembling large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2410.02223 , year=
EmbedLLM: Learning compact representations of large language models , author=. arXiv preprint arXiv:2410.02223 , year=
-
[17]
arXiv preprint arXiv:2505.19797 , year=
The Avengers: A Simple Recipe for Uniting Smaller Language Models to Challenge Proprietary Giants , author=. arXiv preprint arXiv:2505.19797 , year=
-
[18]
arXiv preprint arXiv:2404.14618 , year=
Hybrid llm: Cost-efficient and quality-aware query routing , author=. arXiv preprint arXiv:2404.14618 , year=
-
[19]
arXiv preprint arXiv:2407.10834 , year=
Metallm: A high-performant and cost-efficient dynamic framework for wrapping llms , author=. arXiv preprint arXiv:2407.10834 , year=
-
[20]
Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
Fly-swat or cannon? cost-effective language model choice via meta-modeling , author=. Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
-
[21]
arXiv preprint arXiv:2505.19435 , year=
Route to Reason: Adaptive Routing for LLM and Reasoning Strategy Selection , author=. arXiv preprint arXiv:2505.19435 , year=
-
[22]
arXiv preprint arXiv:2412.04167 , year=
Bench-CoE: a Framework for Collaboration of Experts from Benchmark , author=. arXiv preprint arXiv:2412.04167 , year=
-
[23]
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Harnessing multiple large language models: A survey on llm ensemble , author=. arXiv preprint arXiv:2502.18036 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
RouteLLM: Learning to Route LLMs with Preference Data
Routellm: Learning to route llms with preference data , author=. arXiv preprint arXiv:2406.18665 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
International conference on machine learning , pages=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[26]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities , author=. arXiv preprint arXiv:2408.07666 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Advances in Neural Information Processing Systems , volume=
Ties-merging: Resolving interference when merging models , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Forty-first International Conference on Machine Learning , year=
Language models are super mario: Absorbing abilities from homologous models as a free lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[30]
arXiv preprint arXiv:2406.11617 , year=
Della-merging: Reducing interference in model merging through magnitude-based sampling , author=. arXiv preprint arXiv:2406.11617 , year=
-
[31]
Proceedings of the 12th annual conference on Computer graphics and interactive techniques , pages=
Animating rotation with quaternion curves , author=. Proceedings of the 12th annual conference on Computer graphics and interactive techniques , pages=
-
[32]
Mathematische Zeitschrift , volume=
How to conjugate C 1-close group actions , author=. Mathematische Zeitschrift , volume=. 1973 , publisher=
1973
-
[33]
arXiv preprint arXiv:2309.15698 , year=
Deep model fusion: A survey , author=. arXiv preprint arXiv:2309.15698 , year=
-
[34]
arXiv preprint arXiv:2412.13328 , year=
Expansion span: Combining fading memory and retrieval in hybrid state space models , author=. arXiv preprint arXiv:2412.13328 , year=
-
[35]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[36]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[41]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[42]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. arXiv preprint arXiv:2401.06066 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2303.01610 , year=
Sparse moe as the new dropout: Scaling dense and self-slimmable transformers , author=. arXiv preprint arXiv:2303.01610 , year=
-
[45]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
IEEE Transactions on Knowledge and Data Engineering , year=
A survey on mixture of experts in large language models , author=. IEEE Transactions on Knowledge and Data Engineering , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.