RowNet: A Memory Transformer for Tabular Regression
Pith reviewed 2026-06-28 07:14 UTC · model grok-4.3
The pith
RowNet retrieves comparable properties from a memory bank using pairwise similarities and multiple attention heads to predict real estate prices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
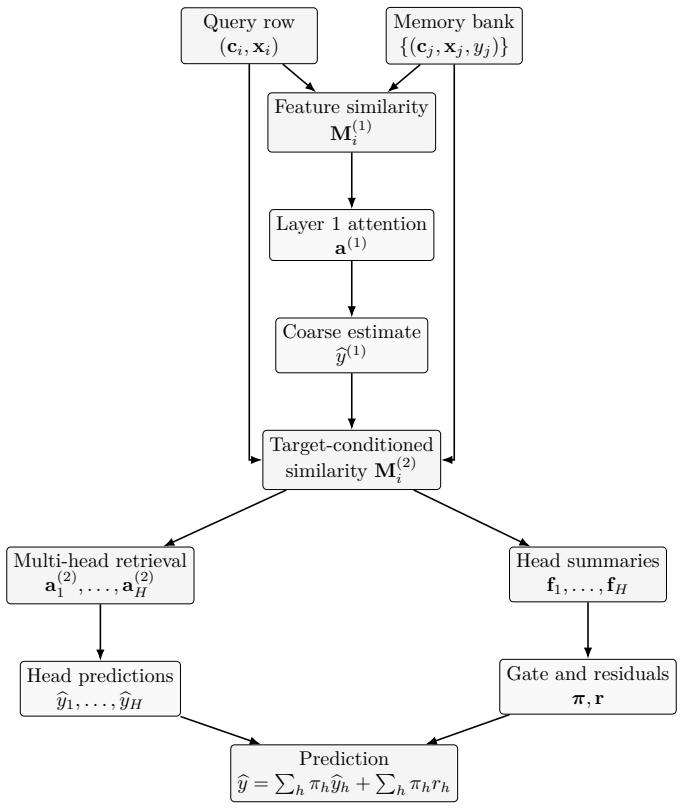
RowNet represents a query property through pairwise similarity features against a memory bank of labeled properties. A first retrieval layer estimates a coarse target from feature-only similarities. A second layer augments the memory comparison with target-consistency features and uses multiple learned attention heads to retrieve complementary comparable sets. A final mixture-of-experts module combines learned gating, residual correction, entropy regularization, and head-diversity regularization to produce the prediction.
What carries the argument
Pairwise similarity features against a memory bank of labeled properties, processed by two retrieval layers with multi-head attention and a final mixture-of-experts predictor.
If this is right
- The first retrieval layer produces a usable coarse target estimate using only feature similarities.
- Multiple attention heads can identify distinct complementary sets of comparable properties for the same query.
- Target-consistency features improve retrieval beyond pure feature matching.
- The mixture-of-experts module with entropy and diversity regularization combines head outputs without over-reliance on any single set.
Where Pith is reading between the lines
- The same memory-retrieval pattern could extend to other tabular regression domains where comparable historical rows carry predictive value.
- Explicit retrieval may reduce the depth of feature engineering needed when data exhibit natural grouping or locality structure.
- Dynamically updating the memory bank could allow the model to track shifting market conditions without retraining the entire network.
Load-bearing premise
That a memory bank of labeled properties exists and that pairwise similarity features plus learned attention heads can reliably surface complementary comparable sets whose targets are informative for the query property's price.
What would settle it
Evaluate RowNet against standard MLPs and gradient-boosted trees on a tabular regression dataset constructed so that no query shares feature or regional similarity with any memory-bank entry, then measure whether accuracy gains disappear.
Figures
read the original abstract
Real estate valuation is a structured regression problem in which prices are governed by heterogeneous feature types, sparse regional effects, nonlinear interactions, and the practical logic of comparable properties. Standard multilayer perceptrons treat each row as an isolated vector and must learn locality, scale sensitivity, and categorical matching from supervision alone. Gradient-boosted decision trees provide strong tabular baselines, but their feature-centric splitting mechanism does not explicitly model the retrieval of similar historical observations. This paper presents RowNet, a retrieval-based neural architecture for real estate price-per-square-meter prediction. RowNet represents a query property through pairwise similarity features against a memory bank of labeled properties. A first retrieval layer estimates a coarse target from feature-only similarities. A second layer augments the memory comparison with target-consistency features and uses multiple learned attention heads to retrieve complementary comparable sets. A final mixture-of-experts module combines learned gating, residual correction, entropy regularization, and head-diversity regularization to produce the prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RowNet, a retrieval-augmented neural architecture for tabular regression on real estate price-per-square-meter prediction. A query property is represented via pairwise similarity features against a memory bank of labeled properties; a first retrieval layer computes a coarse target from feature-only similarities; a second layer adds target-consistency features and employs multiple learned attention heads to retrieve complementary comparable sets; a final mixture-of-experts module applies learned gating, residual correction, entropy regularization, and head-diversity regularization to produce the final prediction.
Significance. If empirical results were to demonstrate that the explicit retrieval of comparable properties via pairwise features and target-augmented attention improves accuracy over standard MLPs and gradient-boosted trees, the work would offer a concrete mechanism for incorporating locality and historical comparables into neural tabular models. The design choices (feature-only vs. target-augmented retrieval, multi-head complementary sets, and regularized MoE) are clearly motivated by domain characteristics of heterogeneous tabular data.
major comments (1)
- [Abstract] Abstract (and entire manuscript): the description supplies the intended architecture and its components but supplies no experimental results, metrics, baselines, or validation details that would allow assessment of whether the design supports the stated claims. This absence is load-bearing for any contribution claim in a machine-learning paper.
Simulated Author's Rebuttal
We thank the referee for their summary and for identifying the central issue with the current manuscript. We address the single major comment below and commit to a substantive revision that supplies the missing empirical content.
read point-by-point responses
-
Referee: [Abstract] Abstract (and entire manuscript): the description supplies the intended architecture and its components but supplies no experimental results, metrics, baselines, or validation details that would allow assessment of whether the design supports the stated claims. This absence is load-bearing for any contribution claim in a machine-learning paper.
Authors: We agree that the submitted manuscript contains only an architectural description and omits all experimental results, metrics, baselines, and validation details. This omission prevents any assessment of the claims and is a material deficiency. In the revised version we will add a full experimental section reporting results on real-estate price-per-square-meter data, quantitative metrics (MAE, RMSE, etc.), comparisons against MLPs and gradient-boosted trees, ablation studies on the retrieval layers and MoE components, and explicit validation protocols. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces RowNet as a retrieval-augmented neural architecture for tabular regression, describing its components (pairwise similarity features, retrieval layers, attention heads, and MoE module) in architectural terms without any equations, fitted parameters presented as predictions, or self-citations that bear the central claim. No derivation chain reduces a result to its own inputs by construction; the model is defined directly via its design choices rather than through self-referential fitting or imported uniqueness theorems. The architecture's dependence on a memory bank is an empirical assumption, not a logical circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arik and Tomas Pfister
Sercan O. Arik and Tomas Pfister. TabNet: Attentive interpretable tabular learning.Proceedings of the AAAI Conference on Artificial Intelligence, 35(8):6679–6687, 2021
2021
-
[2]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794, 2016
2016
-
[3]
Nearest neighbor pattern classification.IEEE Transactions on Information Theory, 13(1):21–27, 1967
Thomas Cover and Peter Hart. Nearest neighbor pattern classification.IEEE Transactions on Information Theory, 13(1):21–27, 1967
1967
-
[4]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. InAdvances in Neural Information Processing Systems, volume 34, pages 18932–18943, 2021
2021
-
[5]
TabR: Tabular deep learning meets nearest neighbors.arXiv preprint arXiv:2307.14338, 2023
Yury Gorishniy, Ivan Rubachev, and Artem Babenko. TabR: Tabular deep learning meets nearest neighbors.arXiv preprint arXiv:2307.14338, 2023
-
[6]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[7]
LightGBM: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[8]
Kimi Team. Attention residuals.arXiv preprint arXiv:2603.15031, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
CatBoost: Unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. CatBoost: Unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems, volume 31, 2018. 16
2018
-
[10]
Bayan Bruss, and Tom Goldstein
Gowthami Somepalli, Micah Goldblum, Avi Schwarzschild, C. Bayan Bruss, and Tom Goldstein. SAINT: Improved neural networks for tabular data via row attention and contrastive pre-training. arXiv preprint arXiv:2106.01342, 2021
-
[11]
End-to-end memory networks
Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. InAdvances in Neural Information Processing Systems, volume 28, 2015
2015
-
[12]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[13]
JasonWeston, SumitChopra, andAntoineBordes. Memorynetworks.arXiv preprint arXiv:1410.3916, 2014. 17
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.