Temporal Order Matters for Agentic Memory: Segment Trees for Long-Horizon Agents
Pith reviewed 2026-06-28 06:11 UTC · model grok-4.3
The pith
A segment tree that inserts conversation turns in chronological order improves answer quality on long-horizon agent benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
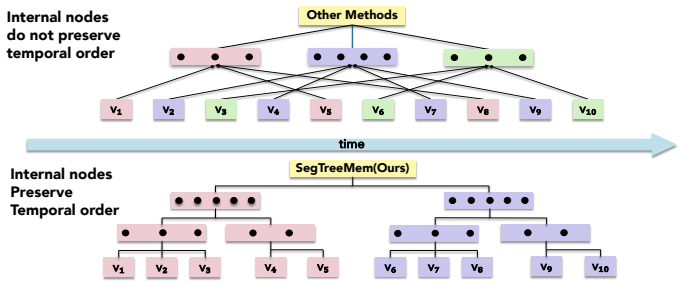
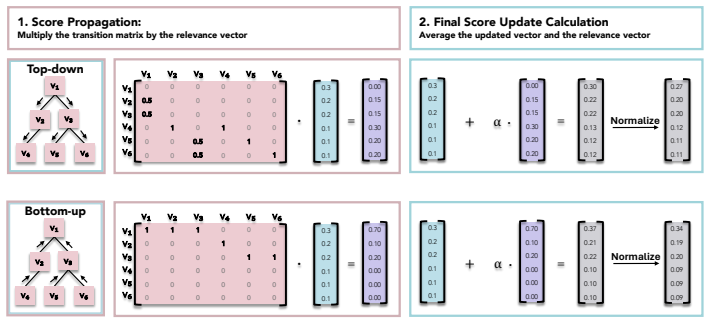
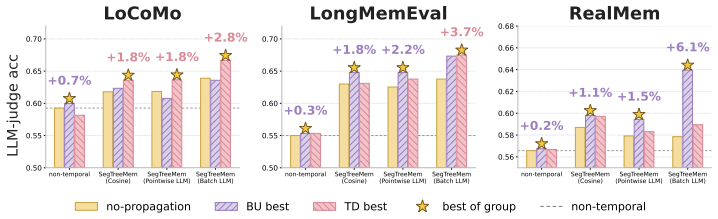
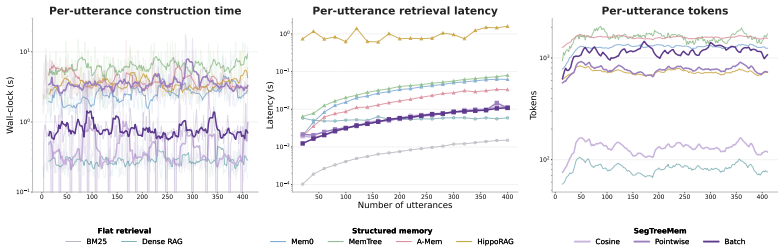
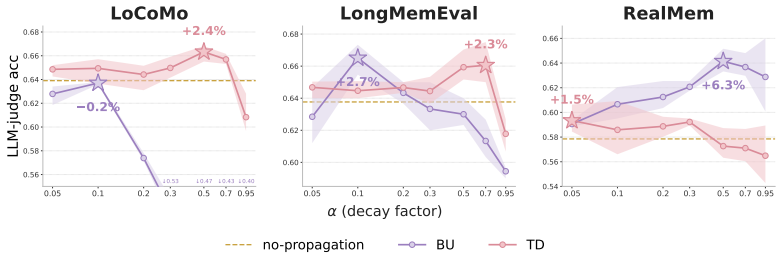
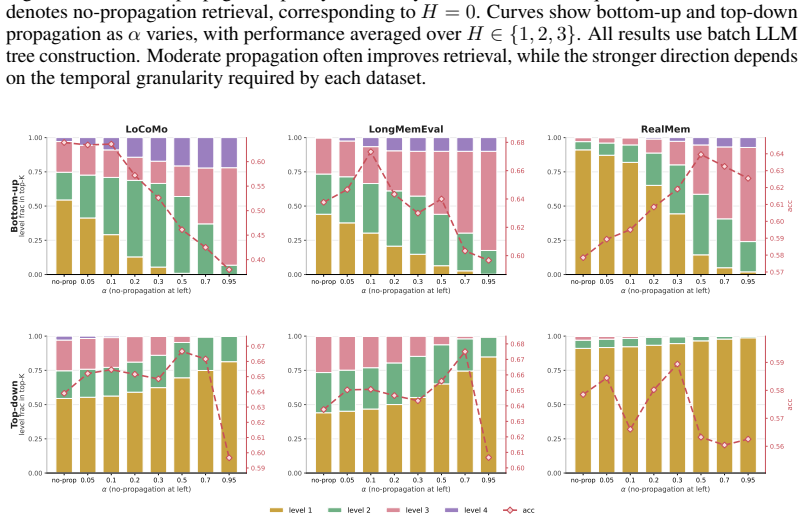
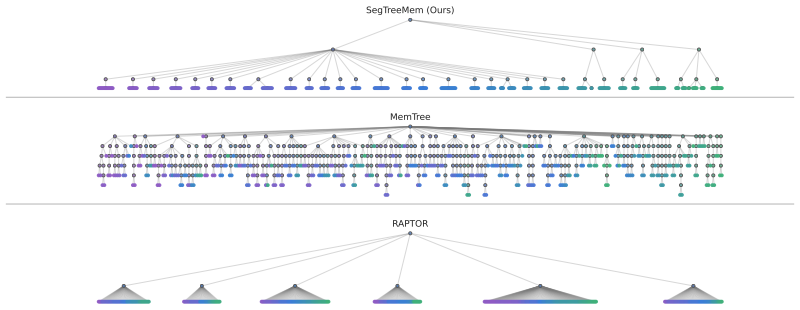
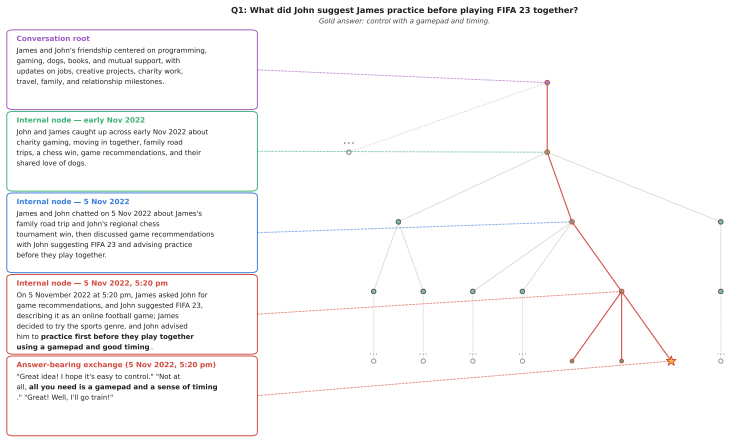
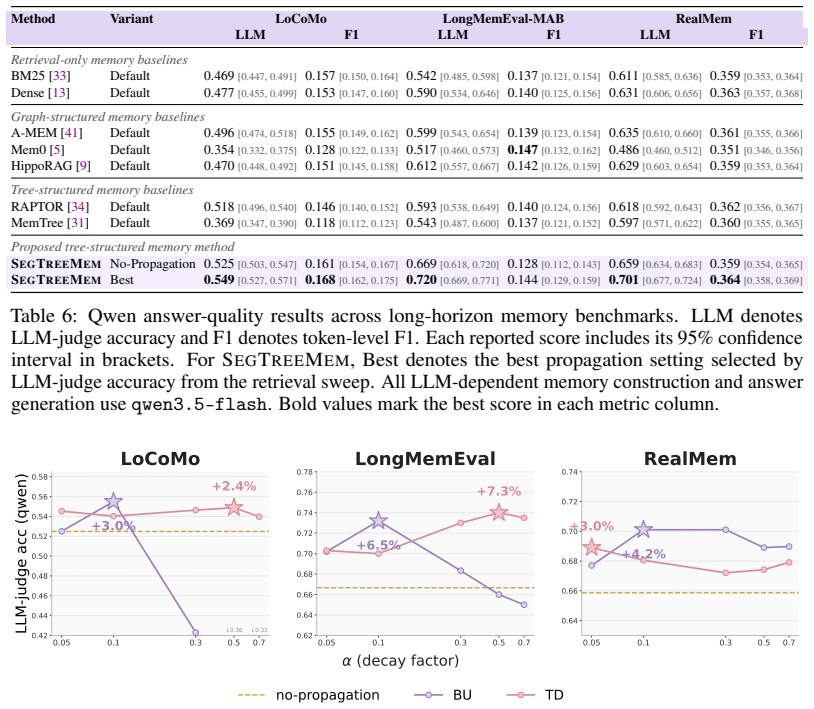
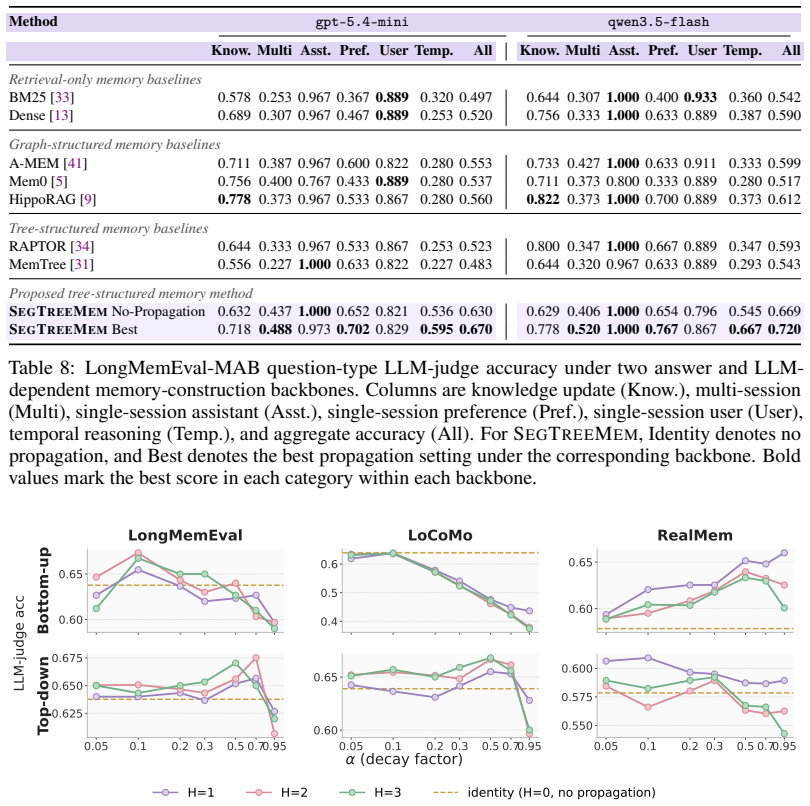
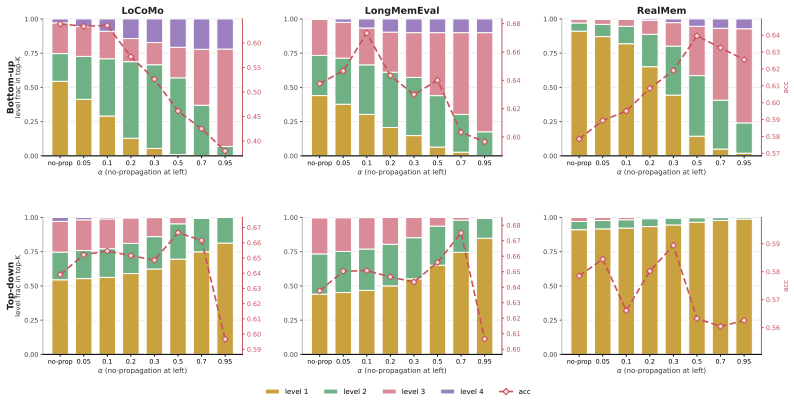
SegTreeMem represents conversation history as a temporally ordered Segment Tree over utterances, incrementally inserts new utterances through an online rightmost-frontier update rule while forming hierarchical memory segments, and propagates relevance scores through the tree to combine local semantic matching with hierarchical temporal context; across three long-horizon memory benchmarks and two LLM backbones this yields higher answer quality than flat retrieval, graph-structured memory, and tree-structured memory baselines, and a temporal-order permutation analysis shows that the performance gain depends on preserving temporal order during memory construction.
What carries the argument
Segment tree with online rightmost-frontier update rule that preserves chronological order while forming hierarchical segments, plus relevance-score propagation for retrieval.
If this is right
- Long-horizon agents can maintain coherent recall of evolving events without explicit time-stamping at query time.
- Memory systems that ignore insertion order will underperform even when they use hierarchical or graph structures.
- Online incremental construction is sufficient to produce usable temporal hierarchy without full offline reordering.
- Retrieval that combines local match scores with ancestor context captures both topical and sequential relevance.
Where Pith is reading between the lines
- The same insertion rule could be tested on non-conversational event streams such as sensor logs or code commit histories.
- If temporal order is the dominant factor, simpler linear buffers with time-aware scoring might close much of the gap.
- The approach suggests that agent memory benchmarks should include explicit order-permutation controls as a standard diagnostic.
Load-bearing premise
That the measured gains come from temporal-order preservation rather than from other differences in how the segment tree inserts items or scores them.
What would settle it
Running the same benchmarks after building the segment tree with the rightmost-frontier rule disabled or after randomly shuffling utterance order at insertion time and finding no drop in answer quality.
Figures



read the original abstract
Long-horizon conversational agents need to interact with users through evolving events, tasks, and goals. Such histories are naturally temporal, yet many existing memory systems organize information primarily by topical similarity and may ignore the order in which events occur. We introduce Segment Tree Memory, or SegTreeMem, a memory architecture that represents conversation history as a temporally ordered Segment Tree over utterances. SegTreeMem incrementally inserts new utterances through an online rightmost-frontier update rule, preserving chronological order while forming hierarchical memory segments. For retrieval, SegTreeMem propagates relevance scores through the tree to combine local semantic matching with hierarchical temporal context. Across three long-horizon memory benchmarks and two LLM backbones, SegTreeMem improves answer quality over flat retrieval, graph-structured memory, and tree-structured memory baselines. Additional temporal-order permutation analysis shows that the performance gain depends on preserving temporal order during memory construction, supporting the claim that temporal order is a key structure for agentic memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SegTreeMem, a memory architecture that represents conversation history as a temporally ordered segment tree over utterances. New utterances are inserted incrementally via an online rightmost-frontier update rule that preserves chronological order while forming hierarchical segments; relevance scores are propagated through the tree at retrieval time to combine local semantic matching with hierarchical temporal context. Empirical results across three long-horizon benchmarks and two LLM backbones show improved answer quality relative to flat retrieval, graph-structured memory, and other tree-structured baselines. A temporal-order permutation analysis is presented to support the claim that performance gains depend on preserving temporal order during memory construction.
Significance. If the central empirical claims and the attribution to temporal order hold after addressing the noted methodological gap, the work would strengthen the case that chronological structure is a load-bearing inductive bias for agentic memory systems, distinct from topical similarity alone. The choice of a standard segment-tree data structure with an explicit online insertion rule is a clear methodological strength that could facilitate reproducibility.
major comments (1)
- [Permutation analysis] Permutation analysis (described in the abstract and presumably §4 or §5): randomly reordering utterances necessarily alters the rightmost-frontier insertion sequence and therefore the resulting hierarchical segment boundaries and tree topology. No control experiment is described that holds segment structure fixed while only permuting order (or vice versa), so the observed performance drop cannot be attributed solely to loss of chronological order rather than to disruption of the tree topology or scoring propagation rules. This directly affects the load-bearing claim that 'the performance gain depends on preserving temporal order.'
minor comments (2)
- The abstract states empirical improvements but supplies no numerical values, error bars, or statistical tests; the full results section should include these details with explicit baseline comparisons.
- Clarify the exact relevance-score propagation rule (e.g., how scores are combined across levels) with a worked example or pseudocode, as the current description leaves the interaction between local matching and hierarchical context underspecified.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We respond to the major comment on the permutation analysis and will revise the manuscript accordingly to address the methodological concern.
read point-by-point responses
-
Referee: [Permutation analysis] Permutation analysis (described in the abstract and presumably §4 or §5): randomly reordering utterances necessarily alters the rightmost-frontier insertion sequence and therefore the resulting hierarchical segment boundaries and tree topology. No control experiment is described that holds segment structure fixed while only permuting order (or vice versa), so the observed performance drop cannot be attributed solely to loss of chronological order rather than to disruption of the tree topology or scoring propagation rules. This directly affects the load-bearing claim that 'the performance gain depends on preserving temporal order.'
Authors: We thank the referee for highlighting this important point. The permutation analysis was intended to demonstrate the importance of chronological order in the construction process, which inherently determines the tree topology via the online insertion rule. However, we acknowledge that this does not fully disentangle the contribution of order from the resulting structure. To address this, we will include an additional control experiment in the revised manuscript where the segment tree topology is fixed based on the original temporal order, but the leaf utterances are permuted in content. This will allow us to assess the impact of order independently of topology changes. We believe this will strengthen the evidence for our central claim. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks
full rationale
The paper introduces SegTreeMem via an online insertion rule and reports answer-quality gains on three external long-horizon benchmarks plus a temporal-order permutation test. No equations, fitted parameters, self-citations, or ansatzes are described that reduce any claimed result to an input by construction. The reported improvements and the dependence on temporal order are presented as measured outcomes on independent benchmarks rather than quantities defined in terms of the method itself; the derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3.5-Flash model documentation
Alibaba Cloud. Qwen3.5-Flash model documentation. https://www.alibabacloud.com/ help/en/model-studio/getting-started/models, 2026. Alibaba Cloud Model Studio documentation forqwen3.5-flash; snapshotqwen3.5-flash-2026-02-23
2026
-
[2]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
2024
-
[3]
Haonan Bian, Zhiyuan Yao, Sen Hu, Zishan Xu, Shaolei Zhang, Yifu Guo, Ziliang Yang, Xueran Han, Huacan Wang, and Ronghao Chen. Realmem: Benchmarking llms in real-world memory-driven interaction.arXiv preprint arXiv:2601.06966, 2026
-
[4]
Howard Chen, Ramakanth Pasunuru, Jason Weston, and Asli Celikyilmaz. Walking down the memory maze: Beyond context limit through interactive reading.arXiv preprint arXiv:2310.05029, 2023
-
[5]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. Includes Mem0 and graph-enhanced Mem0g variants
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Springer, 3 edition, 2008
Mark de Berg, Otfried Cheong, Marc van Kreveld, and Mark Overmars.Computational Geometry: Algorithms and Applications. Springer, 3 edition, 2008
2008
-
[7]
McKeown, Eric Fosler-Lussier, and Hongyan Jing
Michel Galley, Kathleen R. McKeown, Eric Fosler-Lussier, and Hongyan Jing. Discourse segmentation of multi-party conversation. InProceedings of the 41st Annual Meeting of the Association for Computational Linguistics, pages 562–569, Sapporo, Japan, July 2003. Association for Computational Linguistics. doi: 10.3115/1075096.1075167. URL https: //aclantholog...
-
[8]
Nilesh Gupta, Wei-Cheng Chang, Ngot Bui, Cho-Jui Hsieh, and Inderjit S. Dhillon. LLM-guided hierarchical retrieval.arXiv preprint arXiv:2510.13217, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
J.; Shu, Y.; Gu, Y.; Yasunaga, M.; and Su, Y
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models.arXiv preprint arXiv:2405.14831, 2024
-
[10]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Scaling personalized web search
Glen Jeh and Jennifer Widom. Scaling personalized web search. InProceedings of the 12th International Conference on World Wide Web, pages 271–279. ACM, 2003
2003
-
[12]
Shafiq Joty, Giuseppe Carenini, and Raymond T. Ng. Topic segmentation and labeling in asynchronous conversations.Journal of Artificial Intelligence Research, 47:521–573, 2013. doi: 10.1613/jair.3940. URLhttps://doi.org/10.1613/jair.3940
-
[13]
InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online, November 2020. Association for Computational Lin- guistics. ...
-
[14]
Junyoung Kim, Anton Korikov, Jiazhou Liang, Justin Cui, Yifan Simon Liu, Qianfeng Wen, Mark Zhao, and Scott Sanner. Bayesian active learning with gaussian processes guided by llm relevance scoring for dense passage retrieval.arXiv preprint arXiv:2604.17906, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Evaluating Scene-based In-Situ Item Labeling for Immersive Conversational Recommendation
Jiazhou Liang, Yifan Simon Liu, David Guo, Minqi Sun, Yilun Jiang, and Scott Sanner. Evaluating scene-based in-situ item labeling for immersive conversational recommendation. arXiv preprint arXiv:2604.09698, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Goal-Oriented Reasoning for RAG-based Memory in Conversational Agentic LLM Systems
Jiazhou Liang, Armin Toroghi, Yifan Simon Liu, Faeze Moradi Kalarde, Liam Gallagher, and Scott Sanner. Goal-oriented reasoning for rag-based memory in conversational agentic llm systems.arXiv preprint arXiv:2605.12213, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 2511–2522, 2023
2023
-
[19]
A compar- ative study of static and contextual embeddings for analyzing semantic changes in medieval latin charters
Yifan Liu, Gelila Tilahun, Xinxiang Gao, Qianfeng Wen, and Michael Gervers. A compar- ative study of static and contextual embeddings for analyzing semantic changes in medieval latin charters. InProceedings of the First Workshop on Language Models for Low-Resource Languages, pages 182–192, 2025
2025
-
[20]
Yifan Liu, Qianfeng Wen, Jiazhou Liang, Mark Zhao, Justin Cui, Anton Korikov, Armin Toroghi, Junyoung Kim, and Scott Sanner. Multimodal item scoring for natural language recommendation via gaussian process regression with llm relevance judgments.arXiv preprint arXiv:2510.22023, 2025
-
[21]
Ma-dpr: Manifold- aware distance metrics for dense passage retrieval
Yifan Liu, Qianfeng Wen, Mark Zhao, Jiazhou Liang, and Scott Sanner. Ma-dpr: Manifold- aware distance metrics for dense passage retrieval. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31073–31091, 2025
2025
-
[22]
Yifan Simon Liu, Ruifan Wu, Liam Gallagher, Jiazhou Liang, Armin Toroghi, and Scott Sanner. Semantic xpath: Structured agentic memory access for conversational ai.arXiv preprint arXiv:2603.01160, 2026
-
[23]
2504.08266,arXiv:2504.08266,doi:10.48550/ARXIV.2504.08266
Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model.CoRR, abs/2305.02156, 2023. doi: 10.48550/arXiv. 2305.02156
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[24]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents.arXiv preprint arXiv:2402.17753, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
GPT-4o mini model documentation
OpenAI. GPT-4o mini model documentation. https://platform.openai.com/docs/ models/gpt-4o-mini, 2024. Official OpenAI API documentation for gpt-4o-mini; snap- shotgpt-4o-mini-2024-07-18
2024
-
[26]
New embedding models and api updates
OpenAI. New embedding models and api updates. https://openai. com/index/new-embedding-models-and-api-updates/ , 2024. Introduces text-embedding-3-small
2024
-
[27]
Gpt-5.4 mini model documentation
OpenAI. Gpt-5.4 mini model documentation. https://developers.openai.com/ api/docs/models/gpt-5.4-mini, 2026. Official OpenAI API documentation for gpt-5.4-mini
2026
-
[28]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
The pagerank citation ranking: Bringing order to the web
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The pagerank citation ranking: Bringing order to the web. Technical report, Stanford InfoLab, 1999
1999
-
[30]
Bernstein
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, 2023. 12
2023
-
[31]
Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao. From isolated conversations to hierarchi- cal schemas: Dynamic tree memory representation for llms.arXiv preprint arXiv:2410.14052, 2024
-
[32]
The probabilistic relevance framework: Bm25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009. doi: 10.1561/ 1500000019
2009
-
[33]
Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford
Stephen E. Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford. Okapi at trec-3. InText Retrieval Conference, 1994
1994
-
[34]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. RAPTOR: Recursive abstractive processing for tree-organized retrieval.arXiv preprint arXiv:2401.18059, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. Is ChatGPT good at search? investigating large language models as re-ranking agents. InProceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 14918–14937, Singapore, December 2023. As- sociation for Computati...
-
[36]
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
Yixuan Tang and Yi Yang. Multihop-rag: Benchmarking retrieval-augmented generation for multi-hop queries.arXiv preprint arXiv:2401.15391, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Fast random walk with restart and its applications
Hanghang Tong, Christos Faloutsos, and Jia-Yu Pan. Fast random walk with restart and its applications. InProceedings of the Sixth IEEE International Conference on Data Mining, pages 613–622, 2006
2006
-
[38]
Qianfeng Wen, Yifan Liu, Joshua Zhang, George Saad, Anton Korikov, Yury Sambale, and Scott Sanner. Elaborative subtopic query reformulation for broad and indirect queries in travel destination recommendation.arXiv preprint arXiv:2410.01598, 2024
-
[39]
Qianfeng Wen, Yifan Liu, Justin Cui, Joshua Zhang, Anton Korikov, George-Kirollos Saad, and Scott Sanner. A simple but effective elaborative query reformulation approach for natural language recommendation.arXiv preprint arXiv:2510.02656, 2025
-
[40]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Rank-without- GPT: Building GPT-independent listwise rerankers on open-source large language models
Xinyu Zhang, Sebastian Hofstätter, Patrick Lewis, Raphael Tang, and Jimmy Lin. Rank-without- GPT: Building GPT-independent listwise rerankers on open-source large language models. CoRR, abs/2312.02969, 2023. doi: 10.48550/arXiv.2312.02969
-
[43]
John advised him to practice first . . . using a gamepad and good tim- ing
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory.Proceedings of the AAAI Conference on Artificial Intelligence, 38(17), 2024. 13 A Algorithmic Details This subsection provides pseudocode for the two SEGTREEMEMoperations. Node annotations are denoted byA(v), node intervals byI(...
-
[44]
The question category (1=single-hop, 2=temporal, 3=open-ended, 4=multi-hop, 5=adversarial)
-
[45]
The gold answer (or adversarial answer for category 5)
-
[46]
For category 5, the candidate provides the adversarial (wrong) answer as if it were true
The candidate answer to evaluate Scoring criteria: Score 0: The candidate answer is incorrect or contradicts the gold answer. For category 5, the candidate provides the adversarial (wrong) answer as if it were true. Score 1: The candidate answer is vague or generic, not using specific information from the conversation. For category 5, the candidate is unc...
-
[47]
The user’s current query
-
[48]
The user-related memory, representing the latest valid user state
-
[49]
A reference answer based on the relevant memory
-
[50]
facts, constraints, preferences, and confirmed states
The candidate answer to be evaluated Please follow these rules during evaluation: - Focus only on whether "facts, constraints, preferences, and confirmed states" are correctly used - Do NOT evaluate language style, tone, politeness, empathy, or fluency - Do NOT give a high score just because the answer "sounds reasonable" - The reference answer is only to...
-
[51]
Answer: [Yes] Justification: We use LLMs as core components of both our method and evaluation
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.