Rollout-Level Advantage-Prioritized Experience Replay for GRPO
Pith reviewed 2026-06-28 07:41 UTC · model grok-4.3
The pith
A rollout-level replay buffer that prioritizes high-advantage rollouts and evicts stale ones improves GRPO sample efficiency for reasoning LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
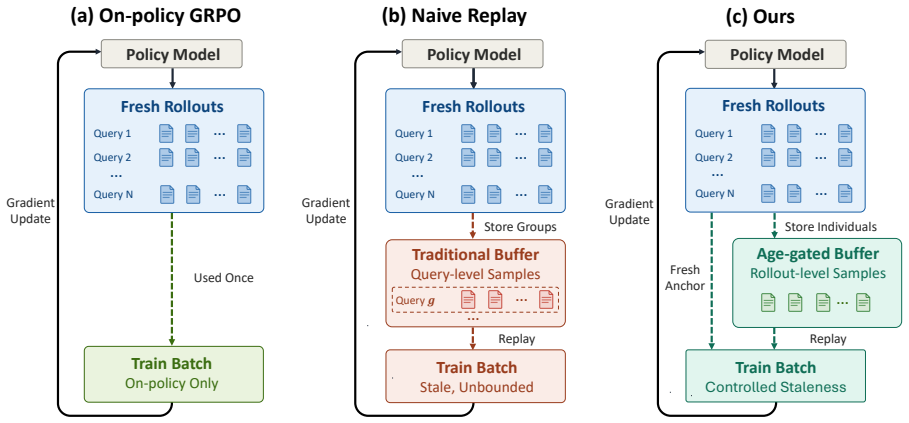
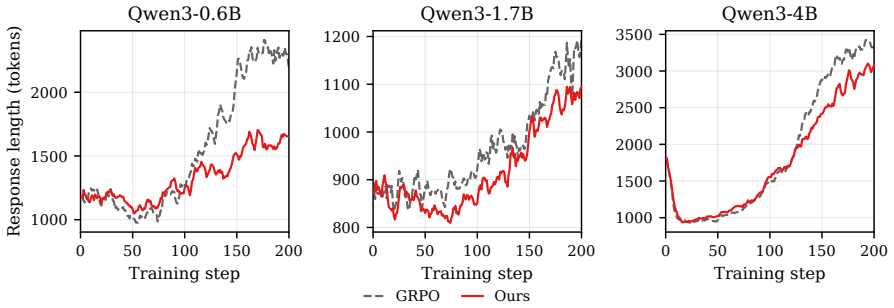
The method stores and samples individual rollouts in a buffer bounded by age eviction at tau_max steps, prioritizes by per-rollout advantage magnitude, and uses fresh-anchored composition to mix current and replay data. This leads to better performance than standard GRPO and naive replay on five math benchmarks across three Qwen3 scales, with the largest improvement of 4.35 percentage points on the average at 4B model size.
What carries the argument
Rollout-level replay buffer with advantage-magnitude prioritization and age-based eviction, plus fresh-anchored batch composition.
If this is right
- Models achieve higher accuracy on math benchmarks with the same number of rollouts.
- Gains increase as model scale grows from smaller to 4B parameters.
- Token efficiency improves alongside accuracy under the AES metric.
- The approach mitigates sample inefficiency in GRPO by recycling useful rollouts.
Where Pith is reading between the lines
- Similar replay designs could apply to other policy optimization methods facing rapid policy changes.
- Advantage prioritization might be combined with other signals like uncertainty for better selection.
- Testing on non-math tasks would reveal if the gains are specific to verifiable reward settings.
Load-bearing premise
Per-rollout advantage magnitude serves as a reliable signal for prioritization, and age eviction sufficiently controls staleness without causing bias or instability.
What would settle it
Training runs where high-advantage rollouts are replayed but result in lower final performance or increased variance compared to no-replay GRPO would falsify the benefit.
Figures
read the original abstract
Reinforcement learning from verifiable rewards with GRPO is a standard approach for post-training reasoning LLMs. It remains sample inefficient. Each rollout is used for a single gradient update and then discarded. Naive replay is not well suited in this setting because LLM policies drift quickly per gradient step. Stored rollouts therefore become stale and can destabilize training. We propose a rollout-level replay buffer for GRPO that stores and samples individual rollouts rather than whole groups. The buffer bounds staleness through age eviction. Any rollout older than tau_max training steps is removed. The buffer also preserves on-policy data via fresh-anchored composition. Each batch keeps its fresh on-policy rollouts and then concatenates replay rollouts drawn separately from the buffer. We prioritize replay by per-rollout advantage magnitude and recycle individual rollouts whose advantages are large. Across three Qwen3-Base scales on five math benchmarks, our method outperforms GRPO and naive replay baselines. Gains are positive at every scale and grow with model size. The largest gain is +4.35 pp on the five-benchmark average at 4B. Under an AES metric that jointly measures accuracy and token efficiency, the efficiency margin over GRPO is again largest at 4B, at +0.579.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a rollout-level replay buffer for GRPO that stores individual rollouts (rather than groups), prioritizes sampling by per-rollout advantage magnitude, evicts rollouts older than tau_max steps to bound staleness, and maintains on-policy data via fresh-anchored batch composition (fresh rollouts plus replayed ones). Across three Qwen3-Base scales on five math benchmarks, the method reports consistent outperformance versus GRPO and naive replay baselines, with gains positive at every scale, increasing with model size, reaching +4.35 pp on the five-benchmark average at 4B, and a corresponding +0.579 improvement on an AES efficiency metric.
Significance. If the empirical gains hold under rigorous controls, the work provides a targeted mechanism to recycle high-advantage rollouts in GRPO while addressing policy drift, potentially improving sample efficiency for reasoning LLM post-training. The scale-dependent improvement is a notable observation. The contribution is primarily empirical; its interpretability would be strengthened by direct validation of the core assumption that stored advantages remain predictive.
major comments (2)
- [Method (buffer design)] Buffer design (method section describing prioritization and fresh-anchored batches): the central claim that advantage magnitude reliably signals which rollouts to replay rests on the untested assumption that advantage computed at storage time correlates with utility under the current policy. No measurement is provided of how quickly advantage rankings decorrelate across GRPO updates, nor whether advantages are recomputed for buffered items; this directly affects whether the reported gains can be attributed to the prioritization mechanism rather than other factors.
- [Experiments] Experimental results (section reporting benchmark gains and AES): the abstract and results claim consistent positive gains (e.g., +4.35 pp at 4B) but provide no details on number of random seeds, variance, statistical significance tests, or exact hyperparameter matching for the GRPO and naive-replay baselines. This information is load-bearing for assessing whether the outperformance is robust.
minor comments (2)
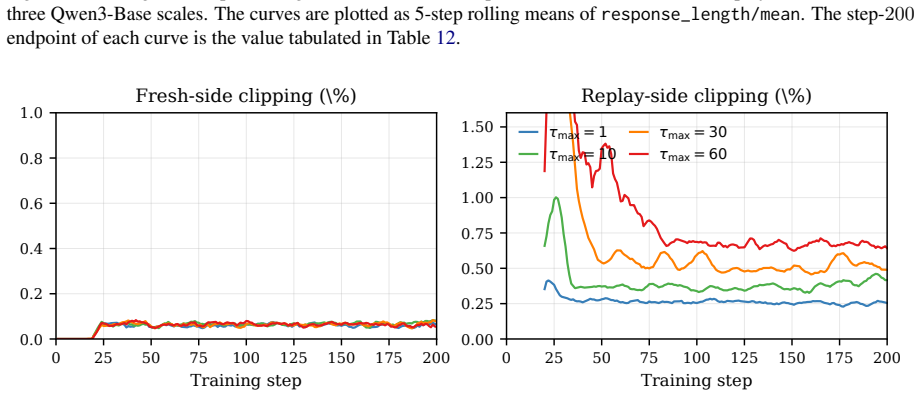
- [Method] tau_max is identified as a free parameter in the buffer design; a sensitivity study or default value justification would improve reproducibility.
- [Method] Notation for the AES metric and the exact composition of fresh-anchored batches could be clarified with a small pseudocode or equation block.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Method (buffer design)] Buffer design (method section describing prioritization and fresh-anchored batches): the central claim that advantage magnitude reliably signals which rollouts to replay rests on the untested assumption that advantage computed at storage time correlates with utility under the current policy. No measurement is provided of how quickly advantage rankings decorrelate across GRPO updates, nor whether advantages are recomputed for buffered items; this directly affects whether the reported gains can be attributed to the prioritization mechanism rather than other factors.
Authors: We agree the assumption is central and untested in the current version. Advantages are computed once upon storage and not recomputed, to limit overhead. In revision we will add an appendix analysis measuring Spearman rank correlation of per-rollout advantages over successive GRPO updates on a held-out subset of training data, directly addressing decorrelation speed and supporting attribution of gains to prioritization. revision: yes
-
Referee: [Experiments] Experimental results (section reporting benchmark gains and AES): the abstract and results claim consistent positive gains (e.g., +4.35 pp at 4B) but provide no details on number of random seeds, variance, statistical significance tests, or exact hyperparameter matching for the GRPO and naive-replay baselines. This information is load-bearing for assessing whether the outperformance is robust.
Authors: We agree these details are required. All reported numbers are means over three independent random seeds; we will revise tables and text to include standard deviations. Hyperparameters for GRPO and naive-replay baselines were matched exactly to the main setting (see Appendix A). We will add a short paragraph noting that gains remain positive and consistent across all seeds. revision: yes
Circularity Check
No circularity; purely empirical method and benchmark results
full rationale
The paper proposes a rollout-level replay buffer for GRPO, using per-rollout advantage for prioritization and age-based eviction. All load-bearing claims are empirical performance numbers on math benchmarks across model scales. No equations, derivations, or first-principles predictions are presented that could reduce to fitted inputs or self-definitions. No self-citations are invoked as load-bearing uniqueness theorems. The central results (gains over GRPO baselines) are measured outcomes, not constructed by the method's own definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- tau_max
Reference graph
Works this paper leans on
-
[1]
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. 2017. https://proceedings.neurips.cc/paper/2017/hash/453fadbd8a1a3af50a9df4df899537b5-Abstract.html Hindsight experience replay . In Advances in Neural Information Processing Systems ( NeurIPS )
2017
-
[2]
Charles Arnal, Vivien Cabannes, Taco Cohen, Julia Kempe, and R \'e mi Munos. 2026. https://arxiv.org/abs/2604.08706 Efficient RL training for LLMs with experience replay . arXiv preprint arXiv:2604.08706
Pith/arXiv arXiv 2026
-
[3]
Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, Jeongyeon Nam, and Donghyun Kwak. 2026. https://doi.org/10.18653/v1/2026.eacl-long.30 Online difficulty filtering for reasoning oriented reinforcement learning . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers) , ...
-
[4]
Andrei Baroian and Rutger Berger. 2026. https://arxiv.org/abs/2603.21177 Prompt replay: Speeding up GRPO with on-policy reuse of high-signal prompts . arXiv preprint arXiv:2603.21177
arXiv 2026
-
[5]
Brian R. Bartoldson, Siddarth Venkatraman, James Diffenderfer, Moksh Jain, Tal Ben-Nun, Seanie Lee, Minsu Kim, Johan Obando-Ceron, Yoshua Bengio, and Bhavya Kailkhura. 2025. https://arxiv.org/abs/2503.18929 Trajectory balance with asynchrony: Decoupling exploration and learning for fast, scalable LLM post-training . In Advances in Neural Information Proce...
arXiv 2025
-
[6]
Bellemare, Will Dabney, and R \'e mi Munos
Marc G. Bellemare, Will Dabney, and R \'e mi Munos. 2017. https://proceedings.mlr.press/v70/bellemare17a.html A distributional perspective on reinforcement learning . In Proceedings of the 34th International Conference on Machine Learning ( ICML ) , volume 70 of Proceedings of Machine Learning Research, pages 449--458. PMLR
2017
-
[7]
Albin Cassirer, Gabriel Barth-Maron, Eugene Brevdo, Sabela Ramos, Toby Boyd, Thibault Sottiaux, and Manuel Kroiss. 2021. https://arxiv.org/abs/2102.04736 Reverb : A framework for experience replay . arXiv preprint arXiv:2102.04736
arXiv 2021
-
[8]
Xinyue Chen, Che Wang, Zijian Zhou, and Keith W. Ross. 2021. https://openreview.net/forum?id=AY8zfZm0tDd Randomized ensembled double Q -learning: Learning fast without a model . In International Conference on Learning Representations ( ICLR )
2021
-
[9]
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. 2023. https://openreview.net/forum?id=m7p5O7zblY RAFT : Reward r A nked F ine- T uning for generative foundation model alignment . Transactions on Machine Learning Research
2023
-
[10]
Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, Jue Chen, Binhua Li, Zhi Jin, Fei Huang, Yongbin Li, and Ge Li. 2025. https://arxiv.org/abs/2508.00222 RL-PLUS : Countering capability boundary collapse of LLMs in reinforcement learning with hybrid-policy optimization . arXiv preprint arXiv:2508.00222
Pith/arXiv arXiv 2025
-
[11]
Bellemare, and Aaron Courville
Pierluca D'Oro, Max Schwarzer, Evgenii Nikishin, Pierre-Luc Bacon, Marc G. Bellemare, and Aaron Courville. 2023. https://openreview.net/forum?id=OpC-9aBBVJe Sample-efficient reinforcement learning by breaking the replay ratio barrier . In International Conference on Learning Representations ( ICLR )
2023
-
[12]
Mehdi Fatemi. 2026. https://arxiv.org/abs/2601.02648 Prioritized replay for RL post-training . arXiv preprint arXiv:2601.02648
arXiv 2026
-
[13]
William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, and Will Dabney. 2020. https://proceedings.mlr.press/v119/fedus20a.html Revisiting fundamentals of experience replay . In Proceedings of the 37th International Conference on Machine Learning ( ICML ) , volume 119 of Proceedings of Machine Learning Research, ...
2020
-
[14]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. 2025. https://arxiv.org/abs/2505.24298 AReaL : A large-scale asynchronous reinforcement learning system for language reasoning . arXiv preprint arXiv:2505.24298
Pith/arXiv arXiv 2025
-
[15]
Scott Fujimoto, David Meger, and Doina Precup. 2020. https://proceedings.neurips.cc/paper/2020/hash/a3bf6e4db673b6449c2f7d13ee6ec9c0-Abstract.html An equivalence between loss functions and non-uniform sampling in experience replay . In Advances in Neural Information Processing Systems 33 ( NeurIPS ) , Online. Curran Associates, Inc
2020
-
[16]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, and 1 others. 2024. https://doi.org/10.5281/zenodo.12608602 A framework for few-shot language model evaluation . GitHub repository
-
[17]
Zhaolin Gao, Joongwon Kim, Wen Sun, Thorsten Joachims, Sid Wang, Richard Yuanzhe Pang, and Liang Tan. 2025. https://arxiv.org/abs/2510.01135 Prompt curriculum learning for efficient LLM post-training . arXiv preprint arXiv:2510.01135
arXiv 2025
-
[18]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/s41586-025-09422-z DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement lear...
-
[19]
Zhenyu Han, Ansheng You, Haibo Wang, Kui Luo, Guang Yang, Wenqi Shi, Menglong Chen, Sicheng Zhang, Zeshun Lan, Chunshi Deng, Huazhong Ji, Wenjie Liu, Yu Huang, Yixiang Zhang, Chenyi Pan, Jing Wang, Xin Huang, Chunsheng Li, and Jianping Wu. 2025. https://arxiv.org/abs/2507.01663 AsyncFlow : An asynchronous streaming RL framework for efficient LLM post-trai...
arXiv 2025
-
[20]
Harvard--MIT Mathematics Tournament . 2025. https://www.hmmt.org HMMT february 2025 . Harvard--MIT Mathematics Tournament, February 2025
2025
-
[21]
Harvard--MIT Mathematics Tournament . 2026. https://www.hmmt.org HMMT february 2026 . Harvard--MIT Mathematics Tournament, February 2026
2026
-
[22]
Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. 2018. https://doi.org/10.1609/aaai.v32i1.11796 Rainbow: Combining improvements in deep reinforcement learning . In Proceedings of the AAAI Conference on Artificial Intelligence , volume 32, pages 3215--3222. A...
-
[23]
Zhang-Wei Hong, Tao Chen, Yen-Chen Lin, Joni Pajarinen, and Pulkit Agrawal. 2022. https://openreview.net/forum?id=OXRZeMmOI7a Topological experience replay . In International Conference on Learning Representations ( ICLR )
2022
-
[24]
Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado van Hasselt, and David Silver. 2018. https://arxiv.org/abs/1803.00933 Distributed prioritized experience replay . In International Conference on Learning Representations ( ICLR )
Pith/arXiv arXiv 2018
-
[25]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Weikai Fang, Xianyu, Yu Cao, Haotian Xu, and Yiming Liu. 2024. https://arxiv.org/abs/2405.11143 OpenRLHF : An easy-to-use, scalable and high-performance RLHF framework . arXiv preprint arXiv:2405.11143
Pith/arXiv arXiv 2024
-
[26]
Hugging Face . 2025. https://github.com/huggingface/Math-Verify Math-verify: Mathematical answer verification . GitHub repository
2025
-
[27]
David Isele and Akansel Cosgun. 2018. https://doi.org/10.1609/aaai.v32i1.11595 Selective experience replay for lifelong learning . In Proceedings of the AAAI Conference on Artificial Intelligence , volume 32. AAAI Press
-
[28]
Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. 2025. https://arxiv.org/abs/2509.19803 VCRL : Variance-based curriculum reinforcement learning for large language models . arXiv preprint arXiv:2509.19803
arXiv 2025
-
[29]
Steven Kapturowski, Georg Ostrovski, John Quan, R \'e mi Munos, and Will Dabney. 2019. https://openreview.net/forum?id=r1lyTjAqYX Recurrent experience replay in distributed reinforcement learning . In International Conference on Learning Representations ( ICLR )
2019
-
[30]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles ( SOSP )
-
[31]
Le, Myeongho Jeon, Kim Vu, Viet Dac Lai, and Eunho Yang
Thanh-Long V. Le, Myeongho Jeon, Kim Vu, Viet Dac Lai, and Eunho Yang. 2026. https://openreview.net/forum?id=kiXFIESZKv No prompt left behind: Exploiting zero-variance prompts in LLM reinforcement learning via entropy-guided advantage shaping . In The Fourteenth International Conference on Learning Representations ( ICLR )
2026
-
[32]
Nicolas Le Roux, Marc G. Bellemare, Jonathan Lebensold, Arnaud Bergeron, Joshua Greaves, Alex Fr \'e chette, Carolyne Pelletier, Eric Thibodeau-Laufer, S \'a ndor Toth, and Sam Work. 2025. https://arxiv.org/abs/2503.14286 Tapered off-policy REINFORCE : Stable and efficient reinforcement learning for large language models . In Advances in Neural Informatio...
arXiv 2025
-
[33]
Long Li, Zhijian Zhou, Tianyi Wang, Weidi Xu, Zuming Huang, Wei Chu, Zhe Wang, Shirui Pan, Chao Qu, and Yuan Qi. 2026. https://arxiv.org/abs/2603.16157 DyJR : Preserving diversity in reinforcement learning with verifiable rewards via dynamic Jensen-Shannon replay . arXiv preprint arXiv:2603.16157
arXiv 2026
-
[34]
Siheng Li, Zhanhui Zhou, Wai Lam, Chao Yang, and Chaochao Lu. 2025. https://arxiv.org/abs/2506.09340 RePO : Replay-enhanced policy optimization . arXiv preprint arXiv:2506.09340
arXiv 2025
-
[35]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. https://openreview.net/forum?id=v8L0pN6EOi Let's verify step by step . In The Twelfth International Conference on Learning Representations ( ICLR )
2024
-
[36]
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2016. https://arxiv.org/abs/1509.02971 Continuous control with deep reinforcement learning . In International Conference on Learning Representations ( ICLR )
Pith/arXiv arXiv 2016
-
[37]
Long-Ji Lin. 1992. https://doi.org/10.1007/BF00992699 Self-improving reactive agents based on reinforcement learning, planning and teaching . Machine Learning, 8(3--4):293--321
-
[38]
Zhihang Lin, Mingbao Lin, Yuan Xie, and Rongrong Ji. 2025. https://openreview.net/forum?id=SVHerutWxp CPPO : Accelerating the training of group relative policy optimization-based reasoning models . In Advances in Neural Information Processing Systems ( NeurIPS )
2025
-
[39]
Yitao Liu, Chenglei Si, Karthik R. Narasimhan, and Shunyu Yao. 2025 a . https://doi.org/10.18653/v1/2025.acl-long.694 Contextual experience replay for self-improvement of language agents . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14179--14198, Vienna, Austria. Association for...
-
[40]
Zichuan Liu, Jinyu Wang, Lei Song, and Jiang Bian. 2025 b . https://arxiv.org/abs/2508.06412 Sample-efficient LLM optimization with reset replay . arXiv preprint arXiv:2508.06412
Pith/arXiv arXiv 2025
-
[41]
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. 2025 a . https://arxiv.org/abs/2501.12570 O1-Pruner : Length-harmonizing fine-tuning for O1 -like reasoning pruning . arXiv preprint arXiv:2501.12570
arXiv 2025
-
[42]
Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. 2025 b . DeepScaleR : Surpassing O1-Preview with a 1.5 B model by scaling RL . Notion Blog. https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scali...
2025
-
[43]
Weiyu Ma, Yongcheng Zeng, Yan Song, Xinyu Cui, Jian Zhao, Xuhui Liu, and Mohamed Elhoseiny. 2026. https://arxiv.org/abs/2604.16918 Freshness-aware prioritized experience replay for LLM / VLM reinforcement learning . arXiv preprint arXiv:2604.16918
Pith/arXiv arXiv 2026
-
[44]
Hanyi Mao, Quanjia Xiao, Lei Pang, and Haixiao Liu. 2025. https://arxiv.org/abs/2509.09177 Clip your sequences fairly: Enforcing length fairness for sequence-level RL . arXiv preprint arXiv:2509.09177
arXiv 2025
-
[45]
Mathematical Association of America . 2025. https://artofproblemsolving.com/wiki/index.php/2025_AIME_I AIME 2025 problems . American Invitational Mathematics Examination, February 2025
2025
-
[46]
Mathematical Association of America . 2026. https://artofproblemsolving.com/wiki/index.php/2026_AIME_I AIME 2026 problems . American Invitational Mathematics Examination, February 2026
2026
-
[47]
MiniMax . 2025. https://arxiv.org/abs/2506.13585 MiniMax-M1 : Scaling test-time compute efficiently with lightning attention . arXiv preprint arXiv:2506.13585
Pith/arXiv arXiv 2025
-
[48]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. https://doi.org/10.1038/nature14236 Human-...
-
[49]
Evgenii Nikishin, Max Schwarzer, Pierluca D'Oro, Pierre-Luc Bacon, and Aaron Courville. 2022. https://proceedings.mlr.press/v162/nikishin22a.html The primacy bias in deep reinforcement learning . In Proceedings of the 39th International Conference on Machine Learning ( ICML ) , volume 162 of Proceedings of Machine Learning Research, pages 16828--16847. PMLR
2022
-
[50]
Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. 2025. https://openreview.net/forum?id=FhTAG591Ve Asynchronous RLHF : Faster and more efficient off-policy RL for language models . In The Thirteenth International Conference on Learning Representations ( ICLR )
2025
-
[51]
Guido Novati and Petros Koumoutsakos. 2019. https://proceedings.mlr.press/v97/novati19a.html Remember and forget for experience replay . In Proceedings of the 36th International Conference on Machine Learning ( ICML ) , volume 97 of Proceedings of Machine Learning Research, pages 4851--4860. PMLR
2019
-
[52]
Susskind, and Etai Littwin
Noam Razin, Hattie Zhou, Omid Saremi, Vimal Thilak, Arwen Bradley, Preetum Nakkiran, Joshua M. Susskind, and Etai Littwin. 2024. https://openreview.net/forum?id=IcVNBR7qZi Vanishing gradients in reinforcement finetuning of language models . In The Twelfth International Conference on Learning Representations ( ICLR )
2024
-
[53]
Lillicrap, and Greg Wayne
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P. Lillicrap, and Greg Wayne. 2019. https://proceedings.neurips.cc/paper/2019/hash/fa7cdfad1a5aaf8370ebeda47a1ff1c3-Abstract.html Experience replay for continual learning . In Advances in Neural Information Processing Systems 32 ( NeurIPS ) , Vancouver, Canada. Curran Associates, Inc
2019
-
[54]
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. 2016. https://arxiv.org/abs/1511.05952 Prioritized experience replay . In International Conference on Learning Representations ( ICLR )
Pith/arXiv arXiv 2016
-
[55]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 DeepSeekMath : Pushing the limits of mathematical reasoning in open language models . arXiv preprint arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[56]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2024. https://arxiv.org/abs/2409.19256 HybridFlow : A flexible and efficient RLHF framework . arXiv preprint arXiv:2409.19256
Pith/arXiv arXiv 2024
-
[57]
Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, and Jieyu Zhao. 2025. https://arxiv.org/abs/2504.05520 Efficient reinforcement finetuning via adaptive curriculum learning . arXiv preprint arXiv:2504.05520
Pith/arXiv arXiv 2025
-
[58]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, and 22 others. 2024. https://openreview.net/forum?id=lNAyUngGFK Beyond human data: Sc...
2024
-
[59]
Samarth Sinha, Jiaming Song, Animesh Garg, and Stefano Ermon. 2022. https://proceedings.mlr.press/v168/sinha22a.html Experience replay with likelihood-free importance weights . In Proceedings of the 4th Annual Learning for Dynamics and Control Conference ( L4DC ) , volume 168 of Proceedings of Machine Learning Research, pages 110--123. PMLR
2022
-
[60]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. 2025. https://openreview.net/forum?id=uwUkETPIJN Improving data efficiency for LLM reinforcement fine-tuning through difficulty-targeted online data selection and rollout replay . In Advances in Neural Information Processing Systems ( NeurIPS )
2025
-
[61]
Hado van Hasselt, Yotam Doron, Florian Strub, Matteo Hessel, Nicolas Sonnerat, and Joseph Modayil. 2018. https://arxiv.org/abs/1812.02648 Deep reinforcement learning and the deadly triad . arXiv preprint arXiv:1812.02648
Pith/arXiv arXiv 2018
-
[62]
Xu Wan, Yansheng Wang, Wenqi Huang, and Mingyang Sun. 2026. https://arxiv.org/abs/2602.20722 Buffer matters: Unleashing the power of off-policy reinforcement learning in large language model reasoning . arXiv preprint arXiv:2602.20722. Introduces ``Batch Adaptation Policy Optimization (BAPO)''; the BAPO acronym here is distinct from the BAPO (Balanced Pol...
arXiv 2026
-
[63]
Chen Wang, Lai Wei, Yanzhi Zhang, Chenyang Shao, Zedong Dan, Weiran Huang, Yuzhi Zhang, and Yue Wang. 2025 a . https://arxiv.org/abs/2506.22200 EFRame : Deeper reasoning via exploration-filter-replay reinforcement learning framework . arXiv preprint arXiv:2506.22200
arXiv 2025
-
[64]
Zhenting Wang, Guofeng Cui, Yu-Jhe Li, Kun Wan, and Wentian Zhao. 2025 b . https://arxiv.org/abs/2504.09710 DUMP : Automated distribution-level curriculum learning for RL -based LLM post-training . arXiv preprint arXiv:2504.09710
arXiv 2025
-
[65]
Bo Wu, Sid Wang, Yunhao Tang, Jia Ding, Eryk Helenowski, Liang Tan, Tengyu Xu, Tushar Gowda, Zhengxing Chen, Chen Zhu, Xiaocheng Tang, Yundi Qian, Beibei Zhu, and Rui Hou. 2025. https://arxiv.org/abs/2505.24034 LlamaRL : A distributed asynchronous reinforcement learning framework for efficient large-scale LLM training . arXiv preprint arXiv:2505.24034
arXiv 2025
-
[66]
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jixuan Huang, Zhihao Zhang, Honglin Guo, Xun Deng, Zhikai Lei, Miao Zheng, Guoteng Wang, Shuo Zhang, Peng Sun, Rui Zheng, Hang Yan, Tao Gui, and 2 others. 2025. https://arxiv.org/abs/2510.18927 BAPO : Stabilizing off-policy reinforcement learning for LLMs via balanced policy ...
arXiv 2025
-
[67]
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, and Hanze Dong. 2025 a . https://arxiv.org/abs/2504.11343 A minimalist approach to LLM reasoning: from rejection sampling to reinforce . arXiv preprint arXiv:2504.11343
arXiv 2025
-
[68]
Wei Xiong, Chenlu Ye, Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, Jiang Bian, Nan Jiang, and Tong Zhang. 2025 b . https://arxiv.org/abs/2510.04996 Reinforce-Ada : An adaptive sampling framework under non-linear RL objectives . arXiv preprint arXiv:2510.04996
arXiv 2025
-
[69]
Yixuan Even Xu, Yash Savani, Fei Fang, and J. Zico Kolter. 2025. https://arxiv.org/abs/2504.13818 Not all rollouts are useful: Down-sampling rollouts in LLM reinforcement learning . arXiv preprint arXiv:2504.13818
Pith/arXiv arXiv 2025
-
[70]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. 2025. https://openreview.net/forum?id=vO8LLoNWWk LUFFY : Learning to reason under off-policy guidance . In Advances in Neural Information Processing Systems ( NeurIPS )
2025
-
[71]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[72]
Jiarui Yao, Yifan Hao, Hanning Zhang, Hanze Dong, Wei Xiong, Nan Jiang, and Tong Zhang. 2025. https://arxiv.org/abs/2505.02391 Optimizing chain-of-thought reasoners via gradient variance minimization in rejection sampling and RL . arXiv preprint arXiv:2505.02391
arXiv 2025
-
[73]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, and 17 others. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/hash/a4277440d50f1f15d2cb4c14f7e0c0d2-Abstract-Confe...
2025
-
[74]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/hash/537d5aa768c2d534016a4d06f87bc8fb-Abstract-Conference.html Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? In Advances in Neural Information Processing Systems ...
2025
-
[75]
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F. Wong, and Yu Cheng. 2026. https://arxiv.org/abs/2510.02245 ExGRPO : Learning to reason from experience . In Proceedings of the International Conference on Learning Representations ( ICLR )
arXiv 2026
-
[76]
Hongzhi Zhang, Jia Fu, Jingyuan Zhang, Kai Fu, Qi Wang, Fuzheng Zhang, and Guorui Zhou. 2025 a . https://arxiv.org/abs/2507.07451 RLEP : Reinforcement learning with experience replay for LLM reasoning . arXiv preprint arXiv:2507.07451
arXiv 2025
-
[77]
Ruiqi Zhang, Daman Arora, Song Mei, and Andrea Zanette. 2025 b . https://arxiv.org/abs/2506.09016 SPEED-RL : Faster training of reasoning models via online curriculum learning . arXiv preprint arXiv:2506.09016
arXiv 2025
-
[78]
Shangtong Zhang and Richard S. Sutton. 2017. https://arxiv.org/abs/1712.01275 A deeper look at experience replay . arXiv preprint arXiv:1712.01275
Pith/arXiv arXiv 2017
-
[79]
Yuheng Zhang, Wenlin Yao, Changlong Yu, Yao Liu, Qingyu Yin, Bing Yin, Hyokun Yun, and Lihong Li. 2025 c . https://arxiv.org/abs/2509.25808 AR3PO : Improving sampling efficiency in RLVR through adaptive rollout and response reuse . arXiv preprint arXiv:2509.25808
arXiv 2025
-
[80]
Rui Zhao and Volker Tresp. 2018. https://proceedings.mlr.press/v87/zhao18a.html Energy-based hindsight experience prioritization . In Proceedings of the 2nd Conference on Robot Learning ( CoRL ) , volume 87 of Proceedings of Machine Learning Research, pages 113--122. PMLR
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.