HapTile: A Haptic-Informed Vision-Tactile-Language-Action Dataset for Contact-Rich Imitation Learning
Pith reviewed 2026-06-28 06:10 UTC · model grok-4.3
The pith
HapTile dataset embeds fingertip tactile sensing and haptic feedback into visuotactile-language-action trajectories for contact-rich tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
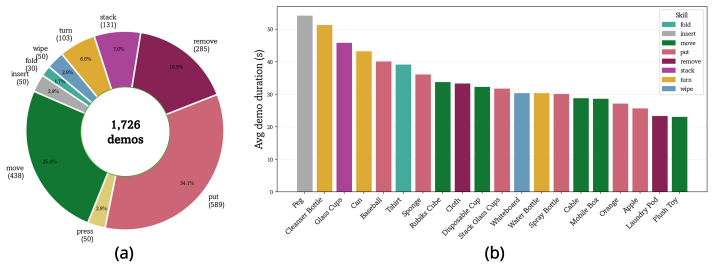
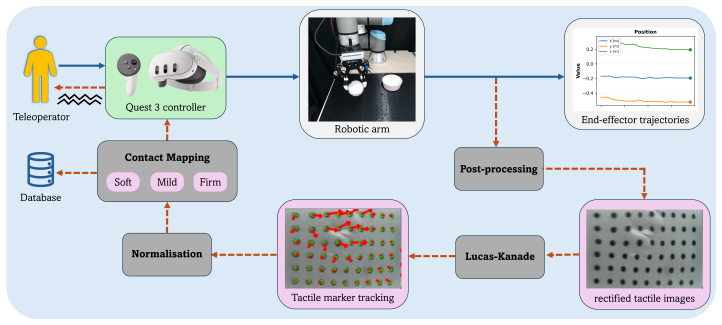
HapTile advances beyond vision-only trajectory datasets by embedding physical interaction sensing at two levels: fingertip tactile feedback at the robot end-effector, and haptic-informed demonstrations at the teleoperator side, with synchronized visuotactile observations and action trajectories for contact-rich skills paired with language instructions.
What carries the argument
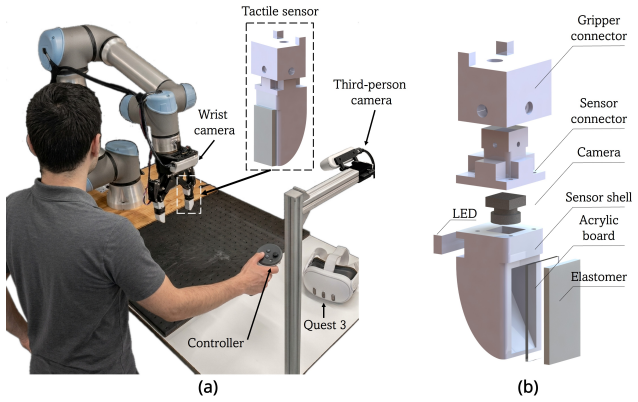
The data collection platform that integrates haptic feedback directly into the teleoperation controller while using custom fingertip tactile sensors on a standard robotic arm.
If this is right
- Policies trained on the dataset can condition actions on both visual and tactile signals during contact phases of manipulation.
- Language instructions can be paired with force-aware trajectories to produce goal-directed contact-rich behaviors.
- Benchmark results on baseline models provide a reference point for measuring gains from the added tactile and haptic channels.
- The platform design allows reproducible collection of synchronized multi-modal data on standard hardware.
Where Pith is reading between the lines
- The same two-level sensing approach could be tested on tasks with partial visual occlusion to quantify robustness gains.
- Future datasets might add force-torque readings at the wrist to further separate contact events from visual appearance.
- Transfer experiments could check whether policies learned in simulation with simulated tactile data match the real HapTile trajectories.
Load-bearing premise
Adding haptic feedback to the teleoperator and recording fingertip tactile data will produce higher-quality demonstrations and measurably better contact-rich policies than existing vision-only datasets.
What would settle it
A side-by-side trial in which policies trained on HapTile achieve no higher success rate than policies trained on an otherwise identical vision-only version of the same tasks.
Figures


read the original abstract
Despite the importance of tactile sensing for reliable manipulation, most existing Vision-Language-Action (VLA) datasets remain vision-only, and those that do incorporate tactile information typically lack the joint combination of task diversity, language conditioning, and action trajectories. Furthermore, existing teleoperation pipelines rarely provide haptic feedback to the operator, despite its established role in demonstration quality and manipulation stability. In this work, we present HapTile, a contact-grounded visuotactile manipulation dataset that advances beyond vision-only trajectory datasets by embedding physical interaction sensing at two levels: fingertip tactile feedback at the robot end-effector, and haptic-informed demonstrations at the teleoperator side. The data collection platform integrates haptic feedback directly into the teleoperation controller, enabling the operator to perceive contact interactions in real time. It is built around a standard and reproducible robotic system equipped with custom-designed fingertip tactile sensors. The dataset comprises everyday manipulation tasks spanning a broad range of contact-rich skills, including pick-and-place, folding, pressing, stacking, and other routine activities. Each task is paired with language instructions that condition the policy on the manipulation objective, together with synchronized visuotactile observations and action trajectories. In addition, we provide a benchmarking study on contact-rich policy learning using two baseline models to evaluate the effectiveness of the proposed contact-grounded dataset. The dataset and additional details are available on our website: haptile-dataset.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HapTile, a visuotactile VLA dataset for contact-rich manipulation collected via a teleoperation platform that supplies real-time haptic feedback to the operator and records synchronized fingertip tactile sensor data alongside RGB images, actions, and language instructions. Tasks span pick-and-place, folding, pressing, and stacking; the authors release the dataset and report benchmarking results on two baseline imitation-learning models to demonstrate its utility for contact-rich policy learning.
Significance. If the dual haptic components (operator feedback plus fingertip sensing) demonstrably improve demonstration quality and downstream policy performance, the dataset would fill a clear gap in existing vision-only VLA corpora and support more reliable contact-rich manipulation. The work credits a publicly released dataset on a standard, reproducible hardware platform together with language-conditioned trajectories; these assets are valuable even if the performance delta remains to be quantified.
major comments (1)
- [Benchmarking study (§5)] Benchmarking study (abstract and §5): the claim that the haptic-informed dataset yields higher-quality demonstrations and measurably better contact-rich policies than vision-only datasets is not supported by the reported experiments. The two baseline models are trained exclusively on the full HapTile data; no matched vision-only control (tactile channels masked), no ablation isolating the haptic feedback channel, and no head-to-head comparison against prior VLA datasets on identical tasks are presented. Consequently the performance numbers cannot be attributed to the tactile/haptic elements rather than task selection or data volume.
minor comments (2)
- [Abstract] The abstract states that “benchmarking with two baseline models was performed” yet supplies no quantitative metrics, error bars, or task-wise tables; these details should be added to the main text or a supplementary table so readers can assess effect sizes.
- [§3] Notation for the tactile sensor channels and the haptic feedback mapping is introduced without a dedicated diagram or equation; a small schematic in §3 would clarify the data synchronization pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the benchmarking experiments do not support claims of superior demonstration quality or policy performance attributable to the haptic components, as no ablations or vision-only controls are provided. We will revise the manuscript to clarify the scope of the benchmarking and remove overstated claims.
read point-by-point responses
-
Referee: [Benchmarking study (§5)] Benchmarking study (abstract and §5): the claim that the haptic-informed dataset yields higher-quality demonstrations and measurably better contact-rich policies than vision-only datasets is not supported by the reported experiments. The two baseline models are trained exclusively on the full HapTile data; no matched vision-only control (tactile channels masked), no ablation isolating the haptic feedback channel, and no head-to-head comparison against prior VLA datasets on identical tasks are presented. Consequently the performance numbers cannot be attributed to the tactile/haptic elements rather than task selection or data volume.
Authors: We agree that the reported experiments cannot attribute performance to the haptic-informed elements. The two baseline models were trained only on the full HapTile dataset, with no tactile-channel ablations, no vision-only matched controls, and no direct comparisons to prior VLA datasets on identical tasks. The benchmarking section was intended only to show that standard imitation-learning models can be trained on the dataset for contact-rich tasks and to report baseline success rates; it was not designed to isolate the contribution of haptic feedback or fingertip sensing. We will revise the abstract, §1, and §5 to remove any language implying that the results demonstrate higher-quality demonstrations or better policies due to haptics, and will instead present the numbers strictly as baseline performance on the new dataset. A limitations paragraph will be added noting the absence of such controls and the need for future comparative studies. No new data collection or experiments are proposed. revision: yes
Circularity Check
No significant circularity; empirical dataset paper with no derivations or self-referential predictions
full rationale
The paper describes construction of the HapTile dataset and a data collection platform incorporating haptic feedback and fingertip tactile sensing, followed by benchmarking on two baseline models. No equations, fitted parameters, predictions, or derivation chains are present. Central claims concern dataset properties and empirical utility assessed against external baselines rather than internal reductions. No self-citation load-bearing steps or ansatzes appear in the provided text. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. S. Johansson and J. R. Flanagan. Coding and use of tactile signals from the fingertips in object manipulation tasks.Nature Reviews Neuroscience, 10(5):345–359, 2009. doi:10.1038/nrn2621
-
[2]
Y . Sun, S. Zhang, Z. Chen, Z. Shen, F. Sun, C. Stefanini, D. Guo, S. Luo, J. Zhang, J. Shan, et al. Soft contact simulation and manipulation learning of deformable objects with vision-based tactile sensor.IEEE Transactions on Automation Science and Engineering, 2025
2025
-
[3]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In2019 International conference on robotics and automation (ICRA), pages 8943–8950. IEEE, 2019
2019
-
[4]
Q. Wang, Y . Du, and M. Y . Wang. Spectac: A visual-tactile dual-modality sensor using uv illumination. In2022 international conference on robotics and automation (ICRA), pages 10844–10850. IEEE, 2022
2022
-
[5]
S. Luo, N. F. Lepora, W. Yuan, K. Althoefer, G. Cheng, and R. Dahiya. Tactile robotics: An outlook.IEEE Transactions on Robotics, 2025
2025
-
[6]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[8]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language- action flow model for general robot control, 2026. URL https://arxiv.org...
2026
- [11]
-
[12]
Jones, O
J. Jones, O. Mees, C. Sferrazza, K. Stachowicz, P. Abbeel, and S. Levine. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5961–5968. IEEE, 2025
2025
-
[13]
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Cai, et al. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation.Ad- vances in Neural Information Processing Systems, 38:93409–93439, 2026
2026
-
[14]
J. Huang, S. Wang, F. Lin, Y . Hu, C. Wen, and Y . Gao. Tactile-vla: unlocking vision-language- action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160, 2025. 10
-
[15]
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li. 3d-vitac: Learning fine-grained manipulation with visuo-tactile sensing.arXiv preprint arXiv:2410.24091, 2024
- [16]
-
[17]
J. Bi, K. Y . Ma, C. Hao, M. S. Zheng, and H. Soh. Vla-touch: Enhancing vision-language-action model with dual-level tactile feedback.IEEE Robotics and Automation Letters, 2026
2026
-
[18]
Sliwowski, S
D. Sliwowski, S. Jadav, S. Stanovcici, J. Orbik, J. Heidersberger, and D. Lee. Demonstrating reassemble: A multimodal dataset for contact-rich robotic assembly and disassembly.11st Robotics: Science and Systems, RSS 2025, 2025
2025
- [19]
-
[20]
H.-G. Chi, J. Barreiros, J. Mercat, K. Ramani, and T. Kollar. Multi-modal representation learning with tactile data. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9660–9667. IEEE, 2024
2024
-
[21]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 653–660. IEEE, 2024
2024
- [22]
-
[23]
Calli, A
B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar. The ycb object and model set: Towards common benchmarks for manipulation research. In2015 international conference on advanced robotics (ICAR), pages 510–517. IEEE, 2015
2015
-
[24]
Bharadhwaj, J
H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V . Kumar. Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4788–4795. IEEE, 2024
2024
-
[25]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
-
[27]
Q. Liu, Y . Cui, Z. Sun, G. Li, J. Chen, and Q. Ye. Vtdexmanip: A dataset and benchmark for visual-tactile pretraining and dexterous manipulation with reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
T. Li, Y . Yan, C. Yu, J. An, Y . Wang, X. Zhu, and G. Chen. Vtg: a visual-tactile dataset for three-finger grasp.IEEE Robotics and Automation Letters, 9(11):10684–10691, 2024
2024
-
[29]
X. Zhu, B. Huang, and Y . Li. Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper.Advances in Neural Information Processing Systems, 38: 153783–153812, 2026
2026
-
[30]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024. 11
2024
-
[31]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . Myers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
-
[32]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. Inconference on Robot Learning, pages 991–1002. PMLR, 2022
2022
-
[34]
R. Gao, Z. Si, Y .-Y . Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, and J. Wu. Objectfolder 2.0: A multisensory object dataset for sim2real transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10598–10608, 2022
2022
-
[35]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
2017
-
[36]
T. Lin, Y . Zhang, Q. Li, H. Qi, B. Yi, S. Levine, and J. Malik. Learning visuotactile skills with two multifingered hands. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5637–5643. IEEE, 2025
2025
-
[37]
Bouguet et al
J.-Y . Bouguet et al. Pyramidal implementation of the affine lucas kanade feature tracker description of the algorithm.Intel corporation, 5(1-10):4, 2001
2001
-
[38]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[39]
R. Zhao, S. Xu, R. Jin, Y . Deng, Y . Tai, K. Jia, and G. Liu. Sim2real vla: Zero-shot generalization of synthesized skills to realistic manipulation. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[40]
G. Liu, Y . Deng, R. Zhao, H. Zhou, J. Chen, J. Chen, R. Xu, Y . Tai, and K. Jia. Dexscale: automating data scaling for sim2real generalizable robot control. InF orty-second international conference on machine learning, 2025
2025
-
[41]
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
B. Zhang, J. Li, J. Shen, Y . Cai, Y . Zhang, Y . Chen, J. Dai, J. Ji, and Y . Yang. Vla-arena: An open-source framework for benchmarking vision-language-action models.arXiv preprint arXiv:2512.22539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Elliott, Z
S. Elliott, Z. Xu, and M. Cakmak. Learning generalizable surface cleaning actions from demonstration. In2017 26th IEEE international symposium on robot and human interactive communication (RO-MAN), pages 993–999. IEEE, 2017
2017
-
[43]
Y . Zhu, J. Wong, A. Mandlekar, R. Martín-Martín, A. Joshi, K. Lin, A. Maddukuri, S. Nasiriany, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[44]
T. Lew, S. Singh, M. Prats, J. Bingham, J. Weisz, B. Holson, X. Zhang, V . Sindhwani, Y . Lu, F. Xia, et al. Robotic table wiping via reinforcement learning and whole-body trajectory optimization. In2023 IEEE international conference on robotics and automation (ICRA), pages 7184–7190. IEEE, 2023
2023
-
[45]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9. 12 A Appendix A.1 Data Formatting Raw demonstrations are converted into a unified LeRobot/OpenPI-style format. ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.