UniCAD: A Unified Benchmark and Universal Model for Multi-Modal Multi-Task CAD
Pith reviewed 2026-06-28 06:53 UTC · model grok-4.3
The pith
A single end-to-end multi-modal LLM performs point-to-CAD reconstruction, text/image-to-CAD generation, and CAD question answering at state-of-the-art levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
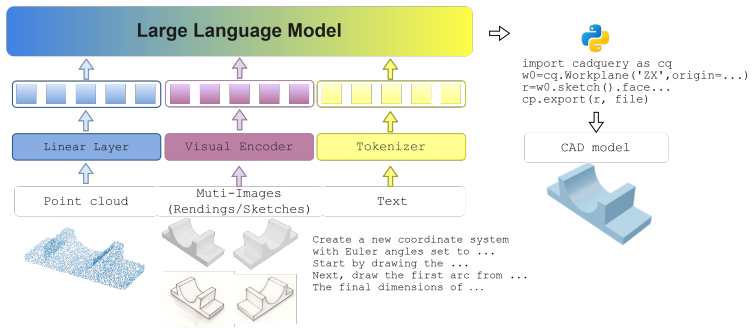
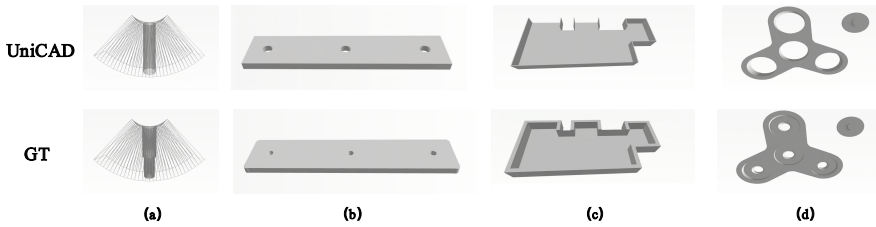
UniCAD-MLLM ingests text, images, sketches, and point clouds and performs point-to-CAD reconstruction, text/image-to-CAD generation, and CAD question answering in an end-to-end fashion inside one framework, reaching state-of-the-art accuracy on every task in the UniCAD and Fusion360 benchmarks.
What carries the argument
UniCAD-MLLM, the universal multi-modal large language model that ingests four modalities and executes the three heterogeneous CAD tasks inside a shared architecture.
If this is right
- One model can replace multiple separate CAD pipelines for reconstruction, generation, and QA.
- Multi-modal inputs such as point clouds and sketches can feed directly into generation and reconstruction inside the same network.
- CAD question answering becomes a native capability alongside geometry output rather than a separate module.
- Standardized evaluation on the released UniCAD benchmark replaces isolated per-task testing.
Where Pith is reading between the lines
- Joint training across tasks may improve robustness when input modalities change at test time.
- Releasing the dataset and pretrained weights allows other groups to test whether further scaling or modality additions improve results still more.
- The same architecture could be extended to assembly or editing tasks without redesigning the input or output interfaces.
Load-bearing premise
That one shared end-to-end multi-modal LLM can reach high performance on reconstruction, generation, and question answering without task-specific heads or losses.
What would settle it
An experiment in which a model equipped with task-specific heads or losses records substantially higher accuracy than UniCAD-MLLM across the same UniCAD tasks would falsify the unified-architecture claim.
Figures
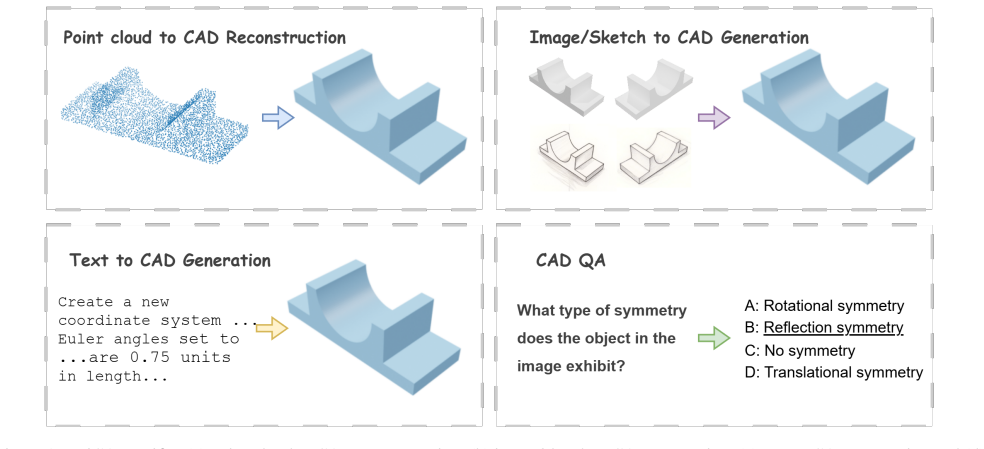

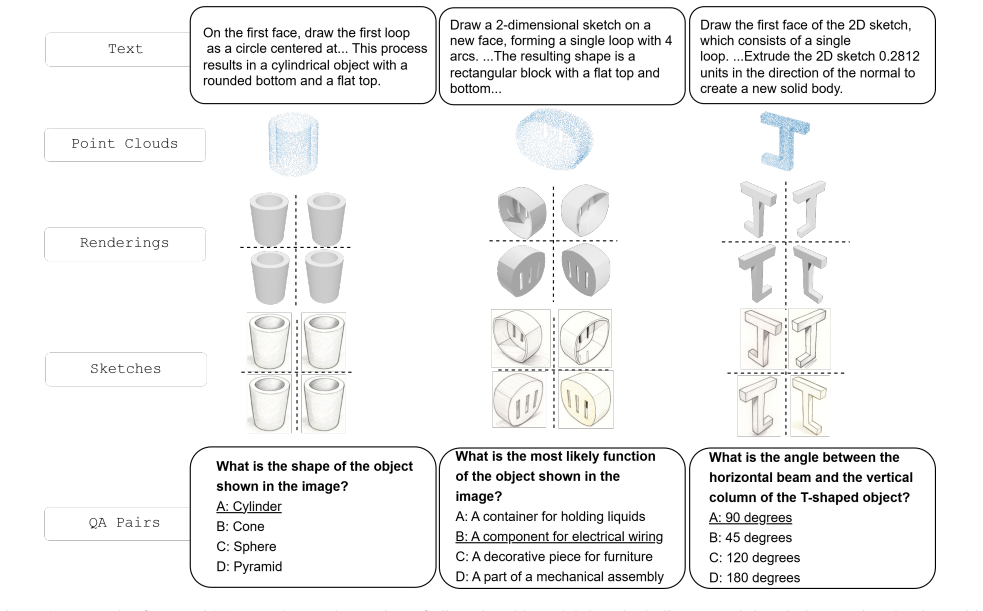

read the original abstract
Computer-Aided Design (CAD) underpins modern engineering and manufacturing by enabling the creation of precise, editable 3D models. However, CAD research typically studies tasks in isolation, and multi-modal, multi-task learning for CAD is hindered by the absence of a unified benchmark. To address this gap, we introduce UniCAD, a comprehensive benchmark for multi-modal CAD learning that covers point-to-CAD reconstruction, text/image-to-CAD generation, and CAD question answering across diverse input modalities. Alongside the benchmark, we present UniCAD-MLLM, a universal multi-modal large language model that ingests text, images, sketches, and point clouds and performs these heterogeneous tasks in an end-to-end fashion within a single framework. Extensive experiments on the UniCAD and Fusion360 benchmarks demonstrate that UniCAD-MLLM achieves state-of-the-art performance across all tasks, outperforming existing task-specific and multi-task baselines. We will release the dataset, code, and pretrained models to accelerate future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniCAD, a new benchmark covering point-to-CAD reconstruction, text/image-to-CAD generation, and CAD question answering across multiple input modalities. It also presents UniCAD-MLLM, described as a single multi-modal LLM that ingests text, images, sketches, and point clouds to perform all tasks end-to-end within one framework, and reports that this model achieves state-of-the-art results on both the new UniCAD benchmark and Fusion360, outperforming task-specific and multi-task baselines. The authors commit to releasing the dataset, code, and pretrained models.
Significance. A well-constructed unified benchmark for multi-modal CAD tasks would be a useful contribution to the field, as current work often studies tasks in isolation. If UniCAD-MLLM genuinely operates as a single shared architecture and training regime without task-specific heads or losses, the result would strengthen the case for unified models in CAD. The planned release of artifacts is a positive step toward reproducibility. However, the absence of any quantitative numbers, ablation studies, error bars, dataset statistics, architectural diagrams, or loss formulations in the abstract leaves the central performance and unification claims unverifiable from the provided material.
major comments (2)
- [Abstract / §3] Abstract and model description (likely §3): the claim that UniCAD-MLLM performs reconstruction, generation, and QA 'in an end-to-end fashion within a single framework' cannot be evaluated because no architectural diagram, tokenization scheme for geometry, output heads, or loss formulation is supplied. If separate components exist for parametric CAD output versus text answers or per-task loss weighting, the 'universal' and 'single framework' framing is undermined; this is load-bearing for the central claim.
- [Abstract] Abstract: the statement that UniCAD-MLLM 'achieves state-of-the-art performance across all tasks' is presented without any numerical results, tables, or error bars. This prevents assessment of whether the reported gains are meaningful or statistically reliable, which is required to support the SOTA claim over existing baselines.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of dataset scale (number of samples per task/modality) and the precise evaluation metrics used for each task.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight opportunities to strengthen the abstract's self-contained clarity while the full manuscript already provides the requested technical details. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and model description (likely §3): the claim that UniCAD-MLLM performs reconstruction, generation, and QA 'in an end-to-end fashion within a single framework' cannot be evaluated because no architectural diagram, tokenization scheme for geometry, output heads, or loss formulation is supplied. If separate components exist for parametric CAD output versus text answers or per-task loss weighting, the 'universal' and 'single framework' framing is undermined; this is load-bearing for the central claim.
Authors: Section 3 of the full manuscript supplies the architectural diagram (Figure 2), the unified tokenization scheme that maps text, images, sketches, and point clouds into a shared token space, the single output head for both parametric CAD sequences and text answers, and the joint loss formulation with task-specific weighting. No task-specific heads or separate components are used; all tasks share the same MLLM backbone and training regime. To make this verifiable directly from the abstract, we will add a concise clause describing the shared architecture. revision: partial
-
Referee: [Abstract] Abstract: the statement that UniCAD-MLLM 'achieves state-of-the-art performance across all tasks' is presented without any numerical results, tables, or error bars. This prevents assessment of whether the reported gains are meaningful or statistically reliable, which is required to support the SOTA claim over existing baselines.
Authors: The abstract is intentionally concise; the full paper contains Tables 1–4 with quantitative results, comparisons against task-specific and multi-task baselines on both UniCAD and Fusion360, and error-bar analyses from multiple runs. We will revise the abstract to include two or three key numerical results (e.g., average improvement margins) so that the SOTA claim can be assessed without reading the full text. revision: yes
Circularity Check
No circularity: empirical benchmark and model training paper
full rationale
The paper introduces the UniCAD benchmark and trains UniCAD-MLLM for multi-modal CAD tasks. No equations, derivations, or first-principles predictions exist; all claims rest on experimental results and comparisons to baselines. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear. The work is self-contained as standard empirical ML research with external benchmarks (UniCAD, Fusion360) for evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gencad: Image- conditioned computer-aided design generation with transformer-based contrastive representation and diffusion priors.Trans
Md Ferdous Alam and Faez Ahmed. Gencad: Image- conditioned computer-aided design generation with transformer-based contrastive representation and diffusion priors.Trans. Mach. Learn. Res., 2025. 3
2025
-
[3]
Generating cad code with vision-language models for 3d de- signs
Kamel Alrashedy, Pradyumna Tambwekar, Zulfiqar Haider Zaidi, Megan Langwasser, Wei Xu, and Matthew Gombolay. Generating cad code with vision-language models for 3d de- signs. InInt. Conf. Learn. Represent., pages 52236–52262,
-
[4]
Ge- ometric modeling of solid objects by using a face adjacency graph representation.ACM SIGGRAPH Computer Graphics, 19(3):131–139, 1985
Silvia Ansaldi, Leila De Floriani, and Bianca Falcidieno. Ge- ometric modeling of solid objects by using a face adjacency graph representation.ACM SIGGRAPH Computer Graphics, 19(3):131–139, 1985. 2
1985
-
[5]
Cadquery/cadquery: Cadquery 2.4.0,
CadQuery Authors. Cadquery/cadquery: Cadquery 2.4.0,
-
[6]
Akshay Badagabettu, Sai Sravan Yarlagadda, and Amir Barati Farimani. Query2cad: Generating cad models using natural language queries.arXiv preprint arXiv:2406.00144, 2024. 3, 4
-
[7]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Cad- crafter: Generating computer-aided design models from un- constrained images
Cheng Chen, Jiacheng Wei, Tianrun Chen, Chi Zhang, Xi- aofeng Yang, Shangzhan Zhang, Bingchen Yang, Chuan- Sheng Foo, Guosheng Lin, Qixing Huang, et al. Cad- crafter: Generating computer-aided design models from un- constrained images. InIEEE Conf. Comput. Vis. Pattern Recog., 2025. 3, 8
2025
-
[9]
Img2cad: Conditioned 3-d cad model generation from single image with structured visual geometry.IEEE Trans- actions on Industrial Informatics, 2025
Tianrun Chen, Chunan Yu, Yuanqi Hu, Jing Li, Tao Xu, Run- long Cao, Lanyun Zhu, Ying Zang, Yong Zhang, Zejian Li, et al. Img2cad: Conditioned 3-d cad model generation from single image with structured visual geometry.IEEE Trans- actions on Industrial Informatics, 2025. 4, 6, 8
2025
-
[10]
Cadops-net: Jointly learning cad operation types and steps from boundary-representations
Elona Dupont, Kseniya Cherenkova, Anis Kacem, Sk Aziz Ali, Ilya Arzhannikov, Gleb Gusev, and Djamila Aouada. Cadops-net: Jointly learning cad operation types and steps from boundary-representations. InInternational Conference on 3D Vision (3DV), pages 114–123. IEEE, 2022. 4
2022
-
[11]
Transcad: A hi- erarchical transformer for cad sequence inference from point clouds
Elona Dupont, Kseniya Cherenkova, Dimitrios Mallis, Gleb Gusev, Anis Kacem, and Djamila Aouada. Transcad: A hi- erarchical transformer for cad sequence inference from point clouds. InEur. Conf. Comput. Vis., pages 19–36. Springer,
-
[12]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InIEEE Conf. Comput. Vis. Pattern Recog., pages 605–613, 2017. 8
2017
-
[13]
Lrm: Large reconstruction model for single image to 3d
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d. InInt. Conf. Learn. Represent., 2024. 9
2024
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention
Mohammad Sadil Khan, Elona Dupont, Sk Aziz Ali, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention. InIEEE Conf. Comput. Vis. Pattern Recog., pages 4713–4722, 2024. 8, 9
2024
-
[16]
Text2cad: Generating sequential cad designs from beginner- to-expert level text prompts.Adv
Mohammad Sadil Khan, Sankalp Sinha, Talha Uddin, Di- dier Stricker, Sk Aziz Ali, and Muhammad Zeshan Afzal. Text2cad: Generating sequential cad designs from beginner- to-expert level text prompts.Adv. Neural Inform. Process. Syst., 37:7552–7579, 2024. 3, 4, 8
2024
-
[17]
Abc: A big cad model dataset for geometric deep learning
Sebastian Koch, Albert Matveev, Zhongshi Jiang, Francis Williams, Alexey Artemov, Evgeny Burnaev, Marc Alexa, Denis Zorin, and Daniele Panozzo. Abc: A big cad model dataset for geometric deep learning. InIEEE Conf. Comput. Vis. Pattern Recog., pages 9601–9611, 2019. 4
2019
-
[18]
Maksim Kolodiazhnyi, Denis Tarasov, Dmitrii Zhem- chuzhnikov, Alexander Nikulin, Ilya Zisman, Anna V orontsova, Anton Konushin, Vladislav Kurenkov, and Danila Rukhovich. cadrille: Multi-modal cad reconstruc- tion with online reinforcement learning.arXiv preprint arXiv:2505.22914, 2025. 3, 8, 9, 16
-
[19]
Reconstructing editable prismatic cad from rounded voxel models
Joseph George Lambourne, Karl Willis, Pradeep Kumar Ja- yaraman, Longfei Zhang, Aditya Sanghi, and Kamal Rahimi Malekshan. Reconstructing editable prismatic cad from rounded voxel models. InSIGGRAPH Asia 2022 Confer- ence Papers, pages 1–9, 2022. 8
2022
-
[20]
Sketch2cad: Sequential cad modeling by sketching in context.ACM Trans
Changjian Li, Hao Pan, Adrien Bousseau, and Niloy J Mi- tra. Sketch2cad: Sequential cad modeling by sketching in context.ACM Trans. Graph., 39(6):1–14, 2020. 3
2020
-
[21]
Free2cad: Parsing freehand drawings into cad commands
Changjian Li, Hao Pan, Adrien Bousseau, and Niloy J Mitra. Free2cad: Parsing freehand drawings into cad commands. ACM Trans. Graph., 41(4):1–16, 2022. 3, 4
2022
-
[22]
Supervised fitting of geometric prim- itives to 3d point clouds
Lingxiao Li, Minhyuk Sung, Anastasia Dubrovina, Li Yi, and Leonidas J Guibas. Supervised fitting of geometric prim- itives to 3d point clouds. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2652–2660, 2019. 2
2019
-
[23]
Seek-cad: A self-refined generative modeling 10 for 3d parametric cad using local inference via deepseek.Int
Xueyang Li, Jiahao Li, Yu Song, Yunzhong Lou, and Xiang- dong Zhou. Seek-cad: A self-refined generative modeling 10 for 3d parametric cad using local inference via deepseek.Int. Conf. Learn. Represent., 2026. 3
2026
-
[24]
Deepseek-vl: Towards real-world vision- language understanding, 2024
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, and Chong Ruan. Deepseek-vl: Towards real-world vision- language understanding, 2024. 3
2024
-
[25]
Multicad: Contrastive representation learning for multi-modal 3d computer-aided design models
Weijian Ma, Minyang Xu, Xueyang Li, and Xiangdong Zhou. Multicad: Contrastive representation learning for multi-modal 3d computer-aided design models. InProceed- ings of the 32nd ACM International Conference on Informa- tion and Knowledge Management, pages 1766–1776, 2023. 8, 9
2023
-
[26]
Draw step by step: Reconstructing cad construction sequences from point clouds via multimodal diffusion
Weijian Ma, Shuaiqi Chen, Yunzhong Lou, Xueyang Li, and Xiangdong Zhou. Draw step by step: Reconstructing cad construction sequences from point clouds via multimodal diffusion. InIEEE Conf. Comput. Vis. Pattern Recog., pages 27154–27163, 2024. 8, 9
2024
-
[27]
Cad- assistant: tool-augmented vllms as generic cad task solvers
Dimitrios Mallis, Ahmet Serda Karadeniz, Sebastian Cavada, Danila Rukhovich, Niki Foteinopoulou, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad- assistant: tool-augmented vllms as generic cad task solvers. InInt. Conf. Comput. Vis., pages 7284–7294, 2025. 3
2025
-
[28]
Polygen: An autoregressive generative model of 3d meshes
Charlie Nash, Yaroslav Ganin, SM Ali Eslami, and Peter Battaglia. Polygen: An autoregressive generative model of 3d meshes. InInt. Conf. Mach. Learn., pages 7220–7229. PMLR, 2020. 2
2020
-
[29]
Can large lan- guage models understand symbolic graphics programs? In Int
Zeju Qiu, Weiyang Liu, Haiwen Feng, Zhen Liu, Tim Xiao, Katherine Collins, Joshua B Tenenbaum, Adrian Weller, Michael J Black, and Bernhard Sch ¨olkopf. Can large lan- guage models understand symbolic graphics programs? In Int. Conf. Learn. Represent., pages 26265–26311, 2025. 3, 4
2025
-
[30]
Cad-recode: Reverse engineering cad code from point clouds
Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-recode: Reverse engineering cad code from point clouds. InInt. Conf. Comput. Vis., pages 9801–9811, 2025. 3, 4, 7, 8, 9
2025
-
[31]
Computer aided design and manufacturing
MMM Sarcar, K Mallikarjuna Rao, and K Lalit Narayan. Computer aided design and manufacturing. PHI Learning Pvt. Ltd., 2008. 1
2008
-
[32]
Ari Seff, Yaniv Ovadia, Wenda Zhou, and Ryan P Adams. Sketchgraphs: A large-scale dataset for modeling rela- tional geometry in computer-aided design.arXiv preprint arXiv:2007.08506, 2020. 3
-
[33]
Parsenet: A parametric surface fitting network for 3d point clouds
Gopal Sharma, Difan Liu, Subhransu Maji, Evangelos Kalogerakis, Siddhartha Chaudhuri, and Radom ´ır Mˇech. Parsenet: A parametric surface fitting network for 3d point clouds. InEur. Conf. Comput. Vis., pages 261–276. Springer,
-
[34]
Learning manifold patch-based representations of man-made shapes
Dmitriy Smirnov, Mikhail Bessmeltsev, and Justin Solomon. Learning manifold patch-based representations of man-made shapes. InInt. Conf. Learn. Represent., 2021. 2
2021
-
[35]
Large lan- guage models for computer-aided design (llm4cad) fine- tuned: Dataset and experiments.Journal of Mechanical De- sign, pages 1–19, 2025
Yuewan Sun, Xingang Li, and Zhenghui Sha. Large lan- guage models for computer-aided design (llm4cad) fine- tuned: Dataset and experiments.Journal of Mechanical De- sign, pages 1–19, 2025. 4
2025
-
[36]
Seed 1.6: Tech introduction
ByteDance Seed Team. Seed 1.6: Tech introduction. https : / / seed . bytedance . com / en / seed1 _ 6,
-
[37]
Accessed on September 28, 2025. 8
2025
-
[38]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Point2cyl: Reverse engineering 3d objects from point clouds to extrusion cylinders
Mikaela Angelina Uy, Yen-Yu Chang, Minhyuk Sung, Purvi Goel, Joseph G Lambourne, Tolga Birdal, and Leonidas J Guibas. Point2cyl: Reverse engineering 3d objects from point clouds to extrusion cylinders. InIEEE Conf. Comput. Vis. Pattern Recog., pages 11850–11860, 2022. 3, 8
2022
-
[40]
Attention is all you need.Adv
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Adv. Neural Inform. Process. Syst., 30, 2017. 2
2017
-
[41]
Neural face identi- fication in a 2d wireframe projection of a manifold object
Kehan Wang, Jia Zheng, and Zihan Zhou. Neural face identi- fication in a 2d wireframe projection of a manifold object. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1622–1631,
-
[42]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Cad-gpt: Synthesising cad construction sequence with spatial reasoning-enhanced mul- timodal llms
Siyu Wang, Cailian Chen, Xinyi Le, Qimin Xu, Lei Xu, Yanzhou Zhang, and Jie Yang. Cad-gpt: Synthesising cad construction sequence with spatial reasoning-enhanced mul- timodal llms. InAAAI Conf. Artif. Intell., pages 7880–7888,
-
[44]
Pie-net: Parametric inference of point cloud edges.Adv
Xiaogang Wang, Yuelang Xu, Kai Xu, Andrea Tagliasac- chi, Bin Zhou, Ali Mahdavi-Amiri, and Hao Zhang. Pie-net: Parametric inference of point cloud edges.Adv. Neural In- form. Process. Syst., 33:20167–20178, 2020. 2
2020
-
[45]
Fusion 360 gallery: A dataset and environ- ment for programmatic cad construction from human design sequences.ACM Trans
Karl DD Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G Lambourne, Armando Solar-Lezama, and Wo- jciech Matusik. Fusion 360 gallery: A dataset and environ- ment for programmatic cad construction from human design sequences.ACM Trans. Graph., 40(4):1–24, 2021. 3, 4, 9
2021
-
[46]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 6, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Deepcad: A deep generative network for computer-aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. Deepcad: A deep generative network for computer-aided design models. InInt. Conf. Comput. Vis., pages 6772–6782, 2021. 3, 4, 6, 8, 9
2021
-
[48]
3d shapenets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Lin- guang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1912–1920,
1912
-
[49]
Haoyang Xie and Feng Ju. Text-to-cadquery: A new paradigm for cad generation with scalable large model ca- pabilities.arXiv preprint arXiv:2505.06507, 2025. 3, 4, 5
-
[50]
Jingwei Xu, Zibo Zhao, Chenyu Wang, Wen Liu, Yi Ma, and Shenghua Gao. Cad-mllm: Unifying multimodality- conditioned cad generation with mllm.arXiv preprint arXiv:2411.04954, 2024. 3, 4 11
-
[51]
Skexgen: Autoregressive generation of cad construction se- quences with disentangled codebooks
Xiang Xu, Karl DD Willis, Joseph G Lambourne, Chin-Yi Cheng, Pradeep Kumar Jayaraman, and Yasutaka Furukawa. Skexgen: Autoregressive generation of cad construction se- quences with disentangled codebooks. InInt. Conf. Mach. Learn., pages 24698–24724. PMLR, 2022. 3
2022
-
[52]
Hierarchical neural coding for controllable cad model generation
Xiang Xu, Pradeep Kumar Jayaraman, Joseph G Lambourne, Karl DD Willis, and Yasutaka Furukawa. Hierarchical neural coding for controllable cad model generation. InInt. Conf. Mach. Learn., pages 38443–38461, 2023. 3, 8, 9
2023
-
[53]
Brepgen: A b-rep generative diffusion model with structured latent geometry.ACM Trans
Xiang Xu, Joseph Lambourne, Pradeep Jayaraman, Zhengqing Wang, Karl Willis, and Yasutaka Furukawa. Brepgen: A b-rep generative diffusion model with structured latent geometry.ACM Trans. Graph., 43(4):1–14, 2024. 2
2024
-
[54]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayi- heng Liu, Fei Huang, et al. Qwen2 technical report. corr, abs/2407.10671, 2024. doi: 10.48550.arXiv preprint ARXIV .2407.10671, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Img2cad: Re- verse engineering 3d cad models from images through vlm- assisted conditional factorization
Yang You, Mikaela Angelina Uy, Jiaqi Han, Rahul Thomas, Haotong Zhang, Yi Du, Hansheng Chen, Francis Engel- mann, Suya You, and Leonidas Guibas. Img2cad: Re- verse engineering 3d cad models from images through vlm- assisted conditional factorization. InProceedings of the SIG- GRAPH Asia 2025 Conference Papers, pages 1–12, 2025. 3, 4, 6
2025
-
[56]
Openecad: An efficient visual language model for editable 3d-cad design
Zhe Yuan, Jianqi Shi, and Yanhong Huang. Openecad: An efficient visual language model for editable 3d-cad design. Computers & Graphics, 124:104048, 2024. 4
2024
-
[57]
Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation
Zibo Zhao, Wen Liu, Xin Chen, Xianfang Zeng, Rui Wang, Pei Cheng, BIN FU, Tao Chen, Gang YU, and Shenghua Gao. Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation. InAdv. Neural Inform. Process. Syst., 2023. 7
2023
-
[58]
Cadparser: A learning approach of sequence modeling for b-rep cad
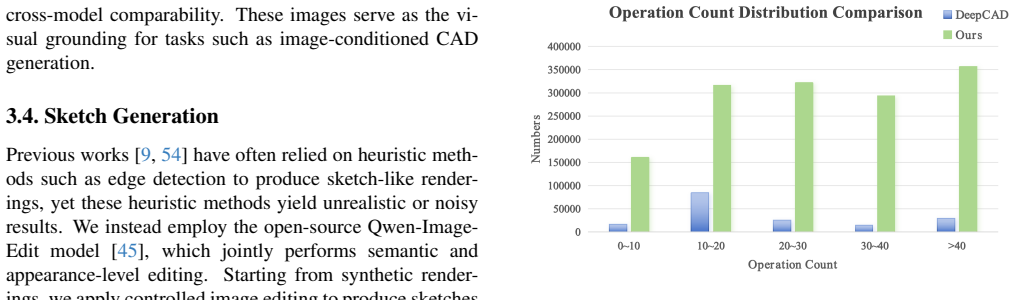
Shengdi Zhou, Tianyi Tang, and Bin Zhou. Cadparser: A learning approach of sequence modeling for b-rep cad. In Int. Jt. Conf. Artif. Intell., pages 1804–1812, 2023. 4 A. Details on UniCAD Dataset Construction A.1. Sketch Generation We input the multi-view rendered images of CAD models into the image editing model from Qwen-Image-Edit [45]. The following p...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.