InstantRetouch: Efficient and High-Fidelity Instruction-Guided Image Retouching with Bilateral Space
Pith reviewed 2026-06-28 06:48 UTC · model grok-4.3
The pith
A bilateral grid of affine transforms enables efficient, high-fidelity instruction-guided image retouching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
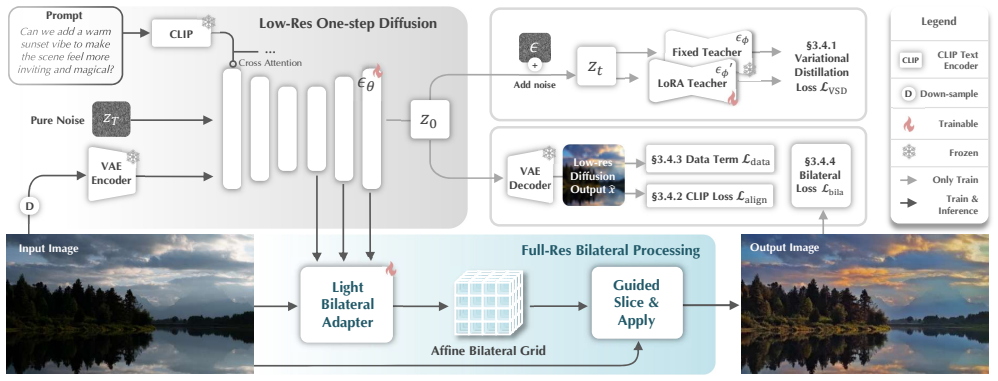
By predicting a low-resolution bilateral grid of affine transforms that are sliced with a learned guidance map and applied to the full image, combined with distilling diffusion priors via Variational Score Distillation and a prompt alignment loss, the method achieves instruction-guided retouching that is both efficient and faithful to the input.
What carries the argument
low-resolution bilateral grid of affine transforms sliced using a learned guidance map
If this is right
- Retouching becomes faster by avoiding iterative sampling steps of diffusion models.
- Content drift is reduced because edits are applied directly via affine transforms on the original pixels.
- High fidelity is preserved since the grid operates without altering geometry or texture.
- Instruction following improves through the added prompt alignment loss in distillation.
Where Pith is reading between the lines
- The compact grid representation could support real-time retouching on resource-limited devices.
- Similar distillation into bilateral space might apply to other pixel-precise editing tasks such as local tone mapping.
- Combining the grid with additional spatial controls could allow more complex instruction-based edits without increasing compute.
Load-bearing premise
Distilling a multi-step diffusion model into the bilateral-grid framework via Variational Score Distillation plus prompt alignment loss transfers strong generative priors while preserving pixel-level fidelity and preventing content drift.
What would settle it
Run the method on images with fine details and check if the output exactly matches the input except for the specified color or tone changes, or measure latency and drift against diffusion baselines on the new benchmark.
Figures


read the original abstract
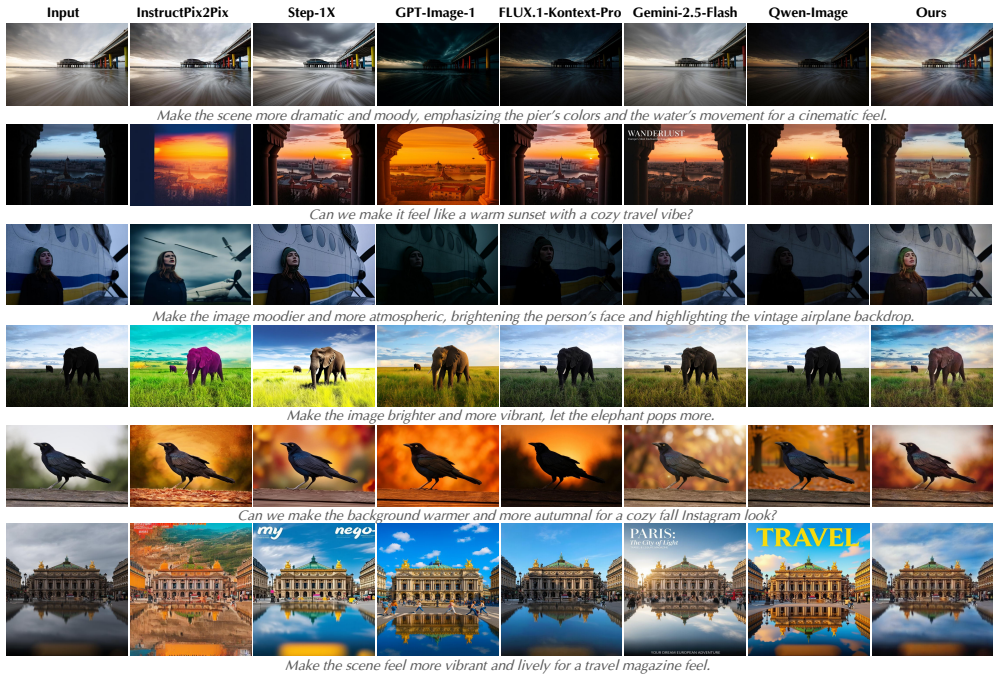
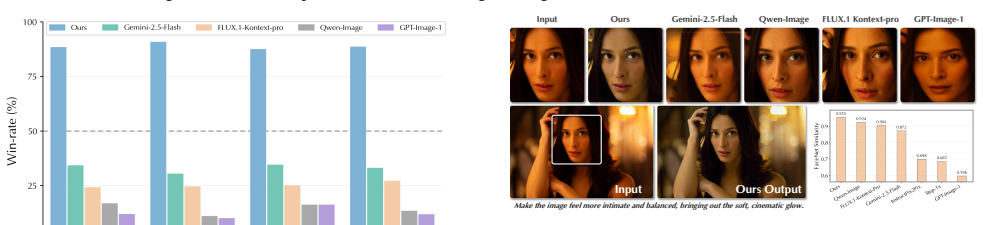
Language-guided photo retouching aims to adjust color and tone while preserving geometry and texture. Recently, diffusion-based retouching shows a superior visual quality, but often struggles with both fidelity issues due to its generative nature and efficiency because of its iterative sampling process. In this work, we propose an efficient and fidelity-preserving retouching method using bilateral space manipulation, which is both compact and content-decoupled. Specifically, instead of directly editing pixels or image latents, our model predicts a low-resolution bilateral grid of affine transforms, which are sliced using a learned guidance map and then applied to the full-resolution image. This approach yields both high fidelity and improved efficiency. To retain strong priors of a pretrained generative model, we distill a multi-step diffusion model into our bilateral grid framework using Variational Score Distillation, complemented by a prompt alignment loss to guide instruction-following behavior. Additionally, we introduce a new benchmark and evaluate our method across multiple dimensions: fidelity, instruction following, and efficiency. Compared to the latest retouch methods, like Gemini-2.5-Flash (Nano-Banana), our method can avoid content drift, significantly improve latency, and generate visually pleasing edits, while maintaining a high level of fidelity. Project page: https://openimaginglab.github.io/InstantRetouch/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InstantRetouch, a method for language-guided photo retouching that predicts a low-resolution bilateral grid of affine transforms (sliced via a learned guidance map) rather than editing pixels or latents directly. It distills a multi-step diffusion model into this bilateral-grid framework via Variational Score Distillation supplemented by a prompt alignment loss, introduces a new benchmark, and claims superior results versus recent methods including Gemini-2.5-Flash on fidelity, instruction following, latency, and avoidance of content drift while preserving geometry and texture.
Significance. If the empirical claims are substantiated, the bilateral-space formulation could supply a practical efficiency-fidelity trade-off for instruction-driven retouching by decoupling content via the grid structure while transferring generative priors through distillation; this would be relevant for real-time editing pipelines.
major comments (3)
- [Abstract] Abstract: the headline claims of avoiding content drift, significantly improved latency, and maintained high fidelity versus Gemini-2.5-Flash are stated without any quantitative metrics, error bars, ablation tables, or benchmark details; this absence prevents verification that the reported gains are not reducible to the choice of distillation loss or backbone.
- [Method (distillation paragraph)] The central technical assumption (that VSD plus prompt alignment loss into low-resolution bilateral affine transforms will reproduce diffusion priors while enforcing strict pixel-level fidelity and blocking content drift) lacks a supporting analysis or bound; the bilateral construction is described as content-decoupled but no derivation shows that upsampled affine slices remain below perceptual drift thresholds once the optimization-based VSD gradients are applied.
- [Experiments] The new benchmark is introduced and used to evaluate fidelity, instruction following, and efficiency, yet no description of its construction, size, diversity, or comparison to existing datasets is supplied, making it impossible to judge whether the cross-method superiority claims are load-bearing or circular.
minor comments (2)
- [Abstract/Method] The abstract and method description would benefit from an explicit equation or diagram showing how the sliced affine transforms are upsampled and applied to the full-resolution input.
- [Method] Notation for the bilateral grid, guidance map, and affine parameters should be introduced consistently with a single table or figure to avoid ambiguity when reading the distillation objective.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and note revisions where the manuscript will be updated to improve clarity and substantiation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of avoiding content drift, significantly improved latency, and maintained high fidelity versus Gemini-2.5-Flash are stated without any quantitative metrics, error bars, ablation tables, or benchmark details; this absence prevents verification that the reported gains are not reducible to the choice of distillation loss or backbone.
Authors: We agree the abstract would be strengthened by quantitative anchors. In revision we will insert concise metrics (e.g., latency reduction factor and fidelity scores versus Gemini-2.5-Flash) drawn from the experiments section, together with a reference to the benchmark. Full ablation tables comparing distillation losses and backbones already appear in the supplementary material and demonstrate that performance gains arise from the bilateral-grid formulation rather than loss choice alone. revision: yes
-
Referee: [Method (distillation paragraph)] The central technical assumption (that VSD plus prompt alignment loss into low-resolution bilateral affine transforms will reproduce diffusion priors while enforcing strict pixel-level fidelity and blocking content drift) lacks a supporting analysis or bound; the bilateral construction is described as content-decoupled but no derivation shows that upsampled affine slices remain below perceptual drift thresholds once the optimization-based VSD gradients are applied.
Authors: The bilateral grid is content-decoupled by construction: each low-resolution affine transform is applied only within spatially localized bilateral cells defined by the learned guidance map, thereby preserving geometry and texture. Empirical evidence across the benchmark shows substantially lower content drift than direct latent editing. While a formal perceptual-drift bound is not derived, we will add a paragraph in the method section explaining the locality properties of the slicing operation and include additional qualitative examples that illustrate fidelity preservation under VSD optimization. revision: partial
-
Referee: [Experiments] The new benchmark is introduced and used to evaluate fidelity, instruction following, and efficiency, yet no description of its construction, size, diversity, or comparison to existing datasets is supplied, making it impossible to judge whether the cross-method superiority claims are load-bearing or circular.
Authors: We will expand the experiments section with a dedicated subsection describing benchmark construction, including image count, instruction diversity, scene variety, and explicit comparisons to prior retouching datasets. This addition will clarify that the reported superiority is evaluated on a standardized, independently constructed test set rather than a circular one. revision: yes
- A formal mathematical derivation or bound showing that upsampled affine slices remain below perceptual drift thresholds under optimization-based VSD gradients.
Circularity Check
No circularity: architecture and distillation are independent of target metrics
full rationale
The paper defines a bilateral-grid affine-transform predictor, trains it by distilling a separate pretrained diffusion model via VSD plus an auxiliary prompt-alignment loss, and evaluates on a newly introduced benchmark. No equation, loss term, or cited result is shown to be defined in terms of the final fidelity or drift metrics; the training objective does not contain the evaluation quantities as inputs, and no self-citation chain is invoked to justify uniqueness or force the architecture. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023. 2, 3, 6
2023
-
[3]
Learning to follow object-centric image editing instructions faithfully
Tuhin Chakrabarty, Kanishk Singh, Arkadiy Saakyan, and Smaranda Muresan. Learning to follow object-centric image editing instructions faithfully. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 9630– 9646, Singapore, 2023. Association for Computational Lin- guistics. 2
2023
-
[4]
Real-time edge-aware image processing with the bilateral grid.ACM Transactions on Graphics (TOG), 26(3):103–es, 2007
Jiawen Chen, Sylvain Paris, and Fr ´edo Durand. Real-time edge-aware image processing with the bilateral grid.ACM Transactions on Graphics (TOG), 26(3):103–es, 2007. 2, 3
2007
-
[5]
Bilateral guided upsampling.ACM Transactions on Graphics (TOG), 35(6):1–8, 2016
Jiawen Chen, Andrew Adams, Neal Wadhwa, and Samuel W Hasinoff. Bilateral guided upsampling.ACM Transactions on Graphics (TOG), 35(6):1–8, 2016. 2
2016
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020. 6
2020
-
[9]
Diffretouch: Using diffusion to retouch on the shoulder of experts
Zheng-Peng Duan, Jiawei Zhang, Zheng Lin, Xin Jin, Xun- Dong Wang, Dongqing Zou, Chun-Le Guo, and Chongyi Li. Diffretouch: Using diffusion to retouch on the shoulder of experts. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2825–2833, 2025. 2
2025
-
[10]
In: ICLR (2024),https: //arxiv.org/abs/2309.17102
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guiding instruction-based im- age editing via multimodal large language models.arXiv preprint arXiv:2309.17102, 2023. 2
-
[11]
Instructdiffusion: A generalist modeling inter- face for vision tasks
Zigang Geng, Binxin Yang, Tiankai Hang, Chen Li, Shuyang Gu, Ting Zhang, Jianmin Bao, Zheng Zhang, Houqiang Li, Han Hu, et al. Instructdiffusion: A generalist modeling inter- face for vision tasks. InProceedings of the IEEE/CVF Con- ference on computer vision and pattern recognition, pages 12709–12720, 2024. 2
2024
-
[12]
Deep bilateral learning for real- time image enhancement.ACM Transactions on Graphics (TOG), 36(4):1–12, 2017
Micha ¨el Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, and Fr´edo Durand. Deep bilateral learning for real- time image enhancement.ACM Transactions on Graphics (TOG), 36(4):1–12, 2017. 2
2017
-
[13]
Focus on your instruction: Fine-grained and multi-instruction image editing by atten- tion modulation
Qin Guo and Tianwei Lin. Focus on your instruction: Fine-grained and multi-instruction image editing by atten- tion modulation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 6986–6996, 2024. 2
2024
-
[14]
Exposure: A white-box photo post-processing framework.ACM Transactions on Graphics (TOG), 37(2): 1–17, 2018
Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework.ACM Transactions on Graphics (TOG), 37(2): 1–17, 2018. 3
2018
-
[15]
Image editing as programs with diffusion models.arXiv preprint arXiv:2506.04158, 2025
Yujia Hu, Songhua Liu, Zhenxiong Tan, Xingyi Yang, and Xinchao Wang. Image editing as programs with diffusion models.arXiv preprint arXiv:2506.04158, 2025. 2
-
[16]
Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8362– 8371, 2024. 2
2024
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 3
2019
-
[19]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 3
2021
-
[20]
Unpaired image enhancement featuring reinforcement-learning-controlled image editing software
Satoshi Kosugi and Toshihiko Yamasaki. Unpaired image enhancement featuring reinforcement-learning-controlled image editing software. InProceedings of the AAAI con- ference on artificial intelligence, pages 11296–11303, 2020. 3
2020
-
[21]
Flowedit: Inversion- free text-based editing using pre-trained flow models
Vladimir Kulikov, Matan Kleiner, Inbar Huberman- Spiegelglas, and Tomer Michaeli. Flowedit: Inversion- free text-based editing using pre-trained flow models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19721–19730, 2025. 2
2025
-
[22]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Sijia Li, Chen Chen, and Haonan Lu. Moecon- troller: Instruction-based arbitrary image manipula- tion with mixture-of-expert controllers.arXiv preprint arXiv:2309.04372, 2023. 2
-
[24]
Shufan Li, Harkanwar Singh, and Aditya Grover. Instruc- tany2pix: Flexible visual editing via multimodal instruction following.arXiv preprint arXiv:2312.06738, 2023. 2
-
[25]
Ppr10k: A large-scale portrait photo retouch- ing dataset with human-region mask and group-level consis- tency
Jie Liang, Hui Zeng, Miaomiao Cui, Xuansong Xie, and Lei Zhang. Ppr10k: A large-scale portrait photo retouch- ing dataset with human-region mask and group-level consis- tency. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 653–661, 2021. 7
2021
-
[26]
Yunlong Lin, Zixu Lin, Kunjie Lin, Jinbin Bai, Panwang Pan, Chenxin Li, Haoyu Chen, Zhongdao Wang, Xinghao Ding, Wenbo Li, et al. Jarvisart: Liberating human artistic creativ- ity via an intelligent photo retouching agent.arXiv preprint arXiv:2506.17612, 2025. 2
-
[27]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[28]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chun- rui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Chaojie Mao, Jingfeng Zhang, Yulin Pan, Zeyinzi Jiang, Zhen Han, Yu Liu, and Jingren Zhou. Ace++: Instruction- based image creation and editing via context-aware content filling.arXiv preprint arXiv:2501.02487, 2025. 2
-
[31]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Rsfnet: A white-box image retouch- ing approach using region-specific color filters
Wenqi Ouyang, Yi Dong, Xiaoyang Kang, Peiran Ren, Xin Xu, and Xuansong Xie. Rsfnet: A white-box image retouch- ing approach using region-specific color filters. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 12160–12169, 2023. 2, 3, 6
2023
-
[33]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 2
2021
-
[34]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3
2022
-
[36]
Complex wavelet structural sim- ilarity: A new image similarity index.IEEE transactions on image processing, 18(11):2385–2401, 2009
Mehul P Sampat, Zhou Wang, Shalini Gupta, Alan Conrad Bovik, and Mia K Markey. Complex wavelet structural sim- ilarity: A new image similarity index.IEEE transactions on image processing, 18(11):2385–2401, 2009. 6
2009
-
[37]
Facenet: A unified embedding for face recognition and clus- tering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clus- tering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015. 7
2015
-
[38]
Laion- aesthetics.LAION
Christoph Schuhmann and Romain Beaumont. Laion- aesthetics.LAION. AI, 2022. 3
2022
-
[39]
Emu edit: Precise image editing via recognition and gen- eration tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and gen- eration tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871– 8879, 2024. 2
2024
-
[40]
Neu- ral photo-finishing.ACM Transactions on Graphics, 41(6): 3555526, 2022
Ethan Tseng, Yuxuan Zhang, Lars Jebe, Xuaner Zhang, Zhi- hao Xia, Yifei Fan, Felix Heide, and Jiawen Chen. Neu- ral photo-finishing.ACM Transactions on Graphics, 41(6): 3555526, 2022. 3
2022
-
[41]
Seededit 3.0: Fast and high-quality generative image editing
Peng Wang, Yichun Shi, Xiaochen Lian, Zhonghua Zhai, Xin Xia, Xuefeng Xiao, Weilin Huang, and Jianchao Yang. Seededit 3.0: Fast and high-quality generative image editing. arXiv preprint arXiv:2506.05083, 2025. 3
-
[42]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 6
2004
-
[43]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in neural information processing systems, 36: 8406–8441, 2023
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in neural information processing systems, 36: 8406–8441, 2023. 2
2023
-
[44]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 1, 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Goal conditioned reinforcement learning for photo fin- ishing tuning
Jiarui Wu, Yujin Wang, Lingen Li, Fan Zhang, and Tianfan Xue. Goal conditioned reinforcement learning for photo fin- ishing tuning. InAdvances in Neural Information Processing Systems, pages 46294–46318. Curran Associates, Inc., 2024. 3
2024
-
[46]
One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024. 4, 5
2024
-
[47]
Gradient magnitude similarity deviation: A highly efficient perceptual image quality index.IEEE transactions on image processing, 23(2):684–695, 2013
Wufeng Xue, Lei Zhang, Xuanqin Mou, and Alan C Bovik. Gradient magnitude similarity deviation: A highly efficient perceptual image quality index.IEEE transactions on image processing, 23(2):684–695, 2013. 6
2013
-
[48]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6613–6623, 2024. 2, 4, 5
2024
-
[49]
Hui Zeng, Jianrui Cai, Lida Li, Zisheng Cao, and Lei Zhang. Learning image-adaptive 3d lookup tables for high perfor- mance photo enhancement in real-time.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(4):2058– 2073, 2020. 2, 3, 6
2058
-
[50]
Hong Zhang, Zhongjie Duan, Xingjun Wang, Yuze Zhao, Weiyi Lu, Zhipeng Di, Yixuan Xu, Yingda Chen, and Yu Zhang. Nexus-gen: A unified model for image understanding, generation, and editing.arXiv preprint arXiv:2504.21356, 2025. 3
-
[51]
Magicbrush: A manually annotated dataset for instruction- guided image editing.Advances in Neural Information Pro- cessing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction- guided image editing.Advances in Neural Information Pro- cessing Systems, 36:31428–31449, 2023. 2, 6
2023
-
[52]
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. In-context edit: Enabling instructional image editing with in- context generation in large scale diffusion transformer.arXiv preprint arXiv:2504.20690, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Pro- cessing Systems, 37:3058–3093, 2024
Haozhe Zhao, Xiaojian Shawn Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Pro- cessing Systems, 37:3058–3093, 2024. 2
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.