Temporal Preference Concepts and their Functions in a Large Language Model
Pith reviewed 2026-06-30 22:15 UTC · model grok-4.3
The pith
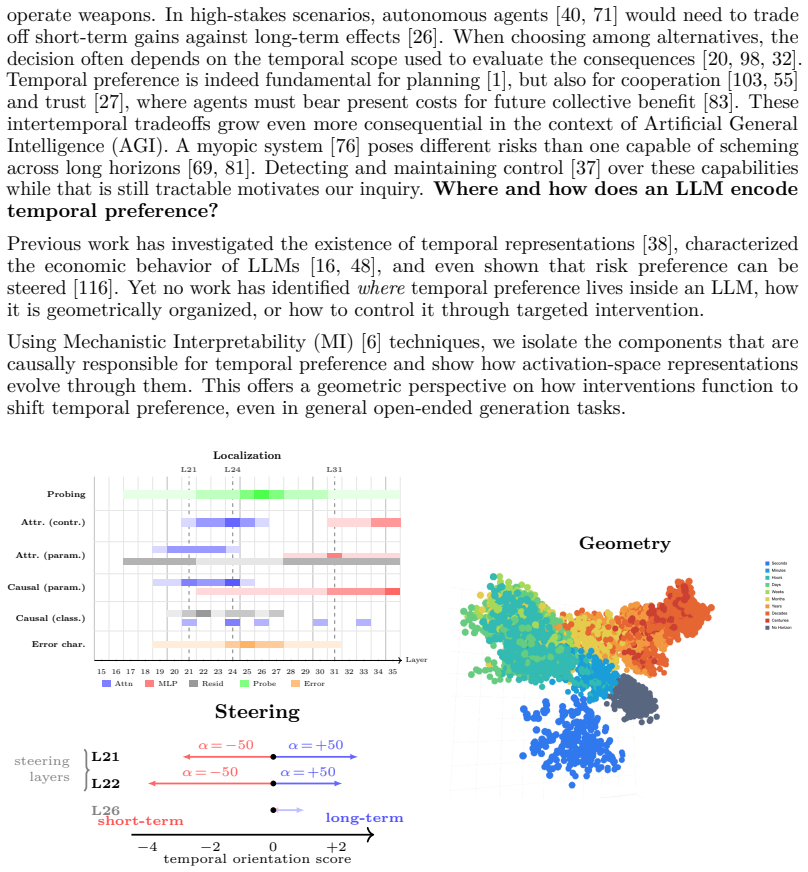
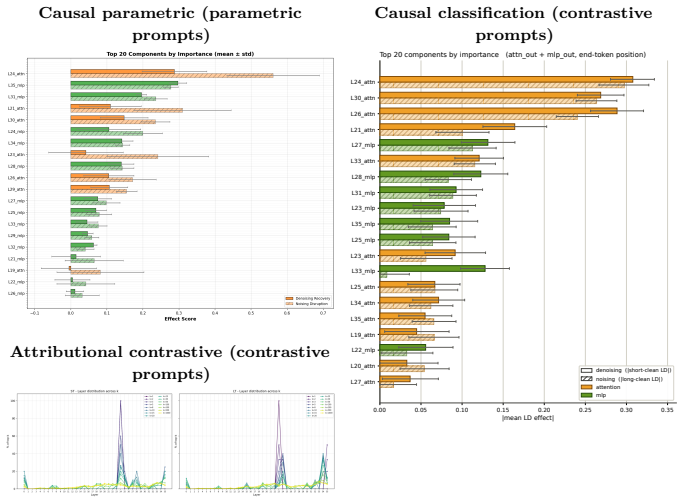
Temporal preference in an LLM localizes to a causal subgraph in mid-to-upper layers via attribution and patching
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
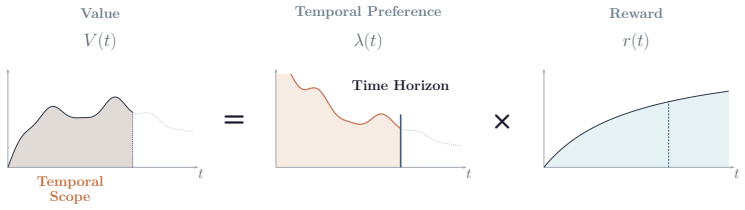
By combining gradient-based attribution and activation patching we causally localize an underlying subgraph for temporal preference in Qwen3-4B-Instruct-2507 at mid-to-upper layers; the geometry of time horizon is encoded in the residual stream at those layers. Behavioral measurements show that the unintervened model discounts the future several times less steeply than humans yet remains unstable across contexts. Steering vectors produce suggestive shifts in the observed preference.
What carries the argument
The causal subgraph for temporal preference, localized in mid-to-upper layers of the residual stream by converging gradient attribution and activation patching.
If this is right
- Unintervened LLMs discount future outcomes several times less steeply than humans, yet this preference varies markedly with context.
- Steering vectors applied at the localized layers can shift the model's temporal preference.
- Mechanistic localization supplies a route to explicit rather than implicit control over how the model weighs near-term versus long-term consequences.
Where Pith is reading between the lines
- If the same localization technique succeeds on other models, temporal preference circuits could be mapped systematically across architectures.
- The observed context instability implies that temporal preference may be better treated as a context-dependent activation pattern than as a fixed model property.
- The identified subgraph could be tested for involvement in other long-horizon reasoning tasks such as multi-step planning or resource allocation.
Load-bearing premise
Converging evidence from gradient attribution and activation patching identifies the true causal subgraph for temporal preference rather than features that are merely correlated with the behavior.
What would settle it
Patching or ablating the identified mid-to-upper-layer nodes produces no measurable change in the model's temporal discounting behavior on held-out contexts.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly being deployed to make decisions that require trading off near-term gains against long-term consequences, yet little is known about how they internally represent or resolve these tradeoffs. In this work, we causally localize an underlying subgraph for temporal preference in a distilled LLM (Qwen3-4B-Instruct-2507), identifying mid-to-upper-layer nodes through converging evidence from gradient-based attribution and activation patching. We find that the geometry of time horizon is encoded in the residual stream at the expected localized layers. A behavioral analysis reveals that unintervened LLMs discount the future several times less steeply than humans, yet this preference is unstable across contexts, motivating explicit control rather than implicit reliance on training. Finally, we find suggestive evidence that steering vectors can shift temporal preference. Our work demonstrates how mechanistic interpretability can bring us closer to reliable control over how LLMs plan and reason
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to causally localize a subgraph responsible for temporal preference (near- vs. long-term tradeoffs) inside the distilled model Qwen3-4B-Instruct-2507. Localization is performed by converging gradient-based attribution and activation patching, which identify mid-to-upper-layer nodes; the geometry of time horizons is reported to be encoded in the residual stream at those layers. Behavioral experiments show that the model discounts the future several times less steeply than humans, with unstable preferences across contexts, and provide suggestive evidence that steering vectors can shift the preference.
Significance. If the causal localization and steering results hold under rigorous controls, the work would supply a concrete mechanistic handle on an important class of planning behavior in LLMs. The explicit contrast with human discounting rates and the instability finding are useful for motivating interpretability-driven control rather than reliance on training alone.
major comments (2)
- [Abstract / §3] Abstract and §3 (results): the central claim that gradient attribution plus activation patching converge on a causal subgraph is load-bearing, yet no quantitative metrics (effect sizes, p-values, ablation baselines, or false-positive rates) are supplied in the visible text. Without these, it is impossible to distinguish true causal nodes from correlated features.
- [§4] §4 (behavioral analysis): the statement that 'unintervened LLMs discount the future several times less steeply than humans' is presented without the exact discounting model, fitting procedure, or context-variation statistics. This undermines the motivation for explicit control.
minor comments (2)
- [Abstract] Model name 'Qwen3-4B-Instruct-2507' should be verified against the official release; the date suffix is atypical.
- [Abstract / §2] Notation for 'residual stream' and 'time horizon geometry' is used without an explicit definition or reference to prior work on residual-stream geometry.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below with clarifications and commitments to strengthen the quantitative presentation of our results.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (results): the central claim that gradient attribution plus activation patching converge on a causal subgraph is load-bearing, yet no quantitative metrics (effect sizes, p-values, ablation baselines, or false-positive rates) are supplied in the visible text. Without these, it is impossible to distinguish true causal nodes from correlated features.
Authors: We acknowledge that explicit statistical metrics such as p-values, effect sizes, and false-positive rates from ablation baselines are not reported in the main text. The localization rests on the observed overlap between independent gradient attribution and activation patching results identifying the same mid-to-upper layer nodes. In revision we will add quantitative support including ablation performance deltas relative to random and layer-matched baselines, intersection statistics, and any applicable significance tests to §3. revision: yes
-
Referee: [§4] §4 (behavioral analysis): the statement that 'unintervened LLMs discount the future several times less steeply than humans' is presented without the exact discounting model, fitting procedure, or context-variation statistics. This undermines the motivation for explicit control.
Authors: The behavioral results use a standard hyperbolic discounting model V = A / (1 + kD) fitted by maximum likelihood on binary choice data collected from temporal tradeoff prompts. The fitting procedure, estimated k values (several times lower than human benchmarks), and context-variation statistics (standard deviations across prompt templates) appear in Appendix B and Table 3. We will move a concise description of the model equation and fitting details into the main text of §4. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical mechanistic interpretability study that reports results from gradient-based attribution, activation patching, and behavioral experiments on Qwen3-4B-Instruct-2507. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All claims rest on experimental observations rather than reducing to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wealth accumulation and the propensity to plan.The Quarterly Journal of Economics, 118(3):1007–1047, 2003
John Ameriks, Andrew Caplin, and John Leahy. Wealth accumulation and the propensity to plan.The Quarterly Journal of Economics, 118(3):1007–1047, 2003
2003
-
[2]
Statement from dario amodei on our discussions with the department of war, 2026
Dario Amodei. Statement from dario amodei on our discussions with the department of war, 2026. URL https://www.anthropic.com/news/ statement-department-of-war
2026
-
[3]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 136037–136083. Curran Associates,...
2024
-
[4]
Arrow, Theodore Harris, and Jacob Marschak
Kenneth J. Arrow, Theodore Harris, and Jacob Marschak. Optimal inventory policy. Econometrica, 19(3):250–272, 1951. doi: 10.2307/1906813
-
[5]
Representation engineering for large-language models: Survey and research challenges, 2025
Lukasz Bartoszcze, Sarthak Munshi, Bryan Sukidi, Jennifer Yen, Zejia Yang, David Williams-King, Linh Le, Kosi Asuzu, and Carsten Maple. Representation engineering for large-language models: Survey and research challenges, 2025. URLhttps://arxiv. org/abs/2502.17601. 9
arXiv 2025
-
[6]
Mechanistic interpretability for ai safety – a review, 2024
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety – a review, 2024. URLhttps://arxiv.org/abs/2404.14082
Pith/arXiv arXiv 2024
-
[7]
Emergent misalignment: Narrow finetuning can produce broadly misaligned llms, 2025
Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms, 2025. URLhttps://arxiv.org/abs/2502.17424
arXiv 2025
-
[8]
Michael E. Bratman. Intention and means-end reasoning.The Philosophical Review, 90(2):252–265, 1981
1981
-
[9]
Understanding (un)reliability of steering vectors in language models,
Joschka Braun, Carsten Eickhoff, David Krueger, Seyed Ali Bahrainian, and Dmitrii Krasheninnikov. Understanding (un)reliability of steering vectors in language models,
-
[10]
URLhttps://arxiv.org/abs/2505.22637
-
[11]
Jon-Paul Cacioli. Categorical perception in large language model hidden states: Structural warping at digit-count boundaries, 2026. URLhttps://arxiv.org/abs/ 2603.28258
Pith/arXiv arXiv 2026
-
[12]
Jon-Paul Cacioli. Weber’s law in transformer magnitude representations: Efficient coding, representational geometry, and psychophysical laws in language models, 2026. URLhttps://arxiv.org/abs/2603.20642
arXiv 2026
-
[13]
Large language models for planning: A comprehensive and systematic survey, 2025
Pengfei Cao, Tianyi Men, Wencan Liu, Jingwen Zhang, Xuzhao Li, Xixun Lin, Dianbo Sui, Yanan Cao, Kang Liu, and Jun Zhao. Large language models for planning: A comprehensive and systematic survey, 2025. URL https://arxiv.org/abs/2505. 19683
2025
-
[14]
A financial brain scan of the LLM.arXiv preprint arXiv:2508.21285, 2025
Hui Chen, Antoine Didisheim, Mohammad Pourmohammadi, Luciano Somoza, and Hanqing Tian. A financial brain scan of the LLM.arXiv preprint arXiv:2508.21285, 2025
arXiv 2025
-
[15]
Yize Cheng, Arshia Soltani Moakhar, Chenrui Fan, Parsa Hosseini, Kazem Faghih, Zahra Sodagar, Wenxiao Wang, and Soheil Feizi. Your LLM agents are temporally blind: The misalignment between tool use decisions and human time perception.arXiv preprint arXiv:2510.23853, 2025. URLhttps://arxiv.org/abs/2510.23853
Pith/arXiv arXiv 2025
-
[16]
Cohen, Keith Marzilli Ericson, David Laibson, and John Myles White
Jonathan D. Cohen, Keith Marzilli Ericson, David Laibson, and John Myles White. Measuring time preferences.Journal of Economic Literature, 58(2):299–347, 2020. doi: 10.1257/jel.20191074
-
[17]
Cook, Sophia Kazinnik, Zach Modig, and Nathan M
Thomas R. Cook, Sophia Kazinnik, Zach Modig, and Nathan M. Palmer. What do LLMs want? Finance and Economics Discussion Series 2026-006, Board of Governors of the Federal Reserve System, January 2026. URLhttps://www.federalreserve. gov/econres/feds/what-do-llms-want.htm
2026
-
[18]
Functional analysis.The Journal of Philosophy, 72(20):741–765, 1975
Robert Cummins. Functional analysis.The Journal of Philosophy, 72(20):741–765, 1975
1975
-
[19]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
Pith/arXiv arXiv 2023
-
[20]
Temporal predictors of outcome in reasoning language models.arXiv preprint arXiv:2511.14773, 2025
Joey David. Temporal predictors of outcome in reasoning language models.arXiv preprint arXiv:2511.14773, 2025. URLhttps://arxiv.org/abs/2511.14773
arXiv 2025
-
[21]
Interpreting time horizon effects in inter-temporal choice.CESifo Working Paper, 2012
Thomas J Dohmen, Armin Falk, David Huffman, and Uwe Sunde. Interpreting time horizon effects in inter-temporal choice.CESifo Working Paper, 2012
2012
-
[22]
Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410, 2024
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410, 2024
2024
-
[23]
Ronald J. Ebert and DeWayne Piehl. Time horizon: A concept for management. California Management Review, 15(4):35–41, 1973. doi: 10.2307/41164456. 10
-
[24]
Takeaways from our recent work on SAE probing
Josh Engels, Subhash Kantamneni, Senthooran Rajamanoharan, and Neel Nanda. Takeaways from our recent work on SAE probing. AI Alignment Forum, March 2025. URLhttps://www.alignmentforum.org/posts/osNKnwiJWHxDYvQTD/ takeaways-from-our-recent-work-on-sae-probing. Accessed: 2025
2025
-
[25]
Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark
Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2405.14860
arXiv 2025
-
[26]
Test of time: A benchmark for evaluating llms on temporal reasoning, 2024
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. Test of time: A benchmark for evaluating llms on temporal reasoning, 2024. URLhttps://arxiv. org/abs/2406.09170
arXiv 2024
-
[27]
Bellemare, and Hugo Larochelle
William Fedus, Carles Gelada, Yoshua Bengio, Marc G. Bellemare, and Hugo Larochelle. Hyperbolic discounting and learning over multiple horizons, 2019. URLhttps:// arxiv.org/abs/1902.06865
Pith/arXiv arXiv 2019
-
[28]
A field study on cooperativeness and impatience in the tragedy of the commons.Journal of Public Economics, 95(9–10):1144–1155, 2011
Ernst Fehr and Andreas Leibbrandt. A field study on cooperativeness and impatience in the tragedy of the commons.Journal of Public Economics, 95(9–10):1144–1155, 2011
2011
-
[29]
Johnson, Amy R
Bernd Figner, Daria Knoch, Eric J. Johnson, Amy R. Krosch, Sarah H. Lisanby, Ernst Fehr, and Elke U. Weber. Lateral prefrontal cortex and self-control in intertemporal choice.Nature Neuroscience, 13(5):538–539, 2010
2010
-
[30]
Time discounting and time preference: A critical review.Journal of Economic Literature, 40(2):351–401,
Shane Frederick, George Loewenstein, and Ted O’Donoghue. Time discounting and time preference: A critical review.Journal of Economic Literature, 40(2):351–401,
-
[31]
doi: 10.1257/002205102320161311
-
[32]
MIT Press, Cambridge, MA, 2000
Peter Gärdenfors.Conceptual Spaces: The Geometry of Thought. MIT Press, Cambridge, MA, 2000
2000
-
[33]
Can llms perceive time? an empirical investigation, 2026
Aniketh Garikaparthi. Can llms perceive time? an empirical investigation, 2026. URL https://arxiv.org/abs/2604.00010
arXiv 2026
-
[34]
Valuing the future: Changing time horizons and policy preferences.Political Behavior, 47(2):553–572, 2025
Alexander F Gazmararian. Valuing the future: Changing time horizons and policy preferences.Political Behavior, 47(2):553–572, 2025
2025
-
[35]
Causal abstraction: A theoretical foundation for mechanistic interpretability, 2025
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, and Thomas Icard. Causal abstraction: A theoretical foundation for mechanistic interpretability, 2025. URLhttps://arxiv.org/abs/2301.04709
arXiv 2025
-
[36]
Pentagon threatens to make Anthropic a pariah if it refuses to drop AI guardrails, 2026
Hadas Gold and Haley Britzky. Pentagon threatens to make Anthropic a pariah if it refuses to drop AI guardrails, 2026. URLhttps://www.cnn.com/2026/02/24/tech/ hegseth-anthropic-ai-military-amodei. Kaanita Iyer contributing
2026
-
[37]
Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969, 2023
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969, 2023
Pith/arXiv arXiv 2023
-
[38]
A discounting framework for choice with delayed and probabilistic rewards.Psychological Bulletin, 130(5):769–792, 2004
Leonard Green and Joel Myerson. A discounting framework for choice with delayed and probabilistic rewards.Psychological Bulletin, 130(5):769–792, 2004
2004
-
[39]
Ai control: Improving safety despite intentional subversion, 2024
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger. Ai control: Improving safety despite intentional subversion, 2024. URLhttps://arxiv.org/abs/ 2312.06942
arXiv 2024
-
[40]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/forum?id=jE8xbmvFin
2024
-
[41]
Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah, and Joshua Batson. When models manipulate manifolds: The geometry of a counting task.arXiv preprint arXiv:2601.04480, 2026. 11
arXiv 2026
-
[42]
politically unacceptable, morally repugnant and should be banned
António Guterres. Lethal autonomous weapon system “politically unacceptable, morally repugnant and should be banned”, 2025. URLhttps://press.un.org/en/2025/ sgsm22643.doc.htm
2025
-
[43]
Temporal alignment of llms through cycle encoding for long-range time representations, 2025
Xue Han, Qian Hu, Yitong Wang, Wenchun Gao, Lianlian Zhang, Qing Wang, Lijun Mei, Chao Deng, and Junlan Feng. Temporal alignment of llms through cycle encoding for long-range time representations, 2025. URLhttps://arxiv.org/abs/2503.04150
arXiv 2025
-
[44]
How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model
Michael Hanna, Ollie Liu, and Alexandre Variengien. How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[45]
Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms, 2024
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms, 2024. URLhttps: //arxiv.org/abs/2403.17806
arXiv 2024
-
[46]
How to use and interpret activation patching,
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching,
-
[47]
URLhttps://arxiv.org/abs/2404.15255
-
[48]
Monotonic representation of numeric attributes in language models
Benjamin Heinzerling and Kentaro Inui. Monotonic representation of numeric attributes in language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 175–195, 2024. doi: 10.18653/v1/2024.acl-short.18. URL https://aclanthology.org/2024.acl-short. 18/
-
[49]
Time awareness in large language models: Benchmarking fact recall across time, 2024
David Herel, Vojtech Bartek, Jiri Jirak, and Tomas Mikolov. Time awareness in large language models: Benchmarking fact recall across time, 2024. URL https: //arxiv.org/abs/2409.13338
arXiv 2024
-
[50]
Around the world in 24 hours: Probing llm knowledge of time and place, 2025
Carolin Holtermann, Paul Röttger, and Anne Lauscher. Around the world in 24 hours: Probing llm knowledge of time and place, 2025. URLhttps://arxiv.org/abs/2506. 03984
2025
-
[51]
Horton, Apostolos Filippas, and Benjamin S
John J. Horton, Apostolos Filippas, and Benjamin S. Manning. Large language models as simulated economic agents: What can we learn from homo silicus?, 2026. URL https://arxiv.org/abs/2301.07543
arXiv 2026
-
[52]
Pentagon vs
Cloud Security Alliance AI Safety Initiative. Pentagon vs. Anthropic: Autonomous weapons AI guardrails and the governance crisis for enterprise AI vendors, 2026. URL https://labs.cloudsecurityalliance.org/research/ csa-research-note-dod-ai-guardrail-mandates-vendor-governanc/
2026
-
[53]
Retroactive date
International Risk Management Institute. Retroactive date. IRMI Insurance Glossary, n.d. URL https://www.irmi.com/term/insurance-definitions/ retroactive-date. Accessed April 13, 2026
2026
-
[54]
Kable and Paul W
Joseph W. Kable and Paul W. Glimcher. The neural correlates of subjective value during intertemporal choice.Nature Neuroscience, 10(12):1625–1633, 2007
2007
-
[55]
Pre-trained language models learn remarkably accurate representations of numbers
Marek Kadlčík, Michal Štefánik, Timothee Mickus, Michal Spiegel, and Josef Kuchař. Pre-trained language models learn remarkably accurate representations of numbers. arXiv preprint arXiv:2506.08966, 2025. URLhttps://arxiv.org/abs/2506.08966
arXiv 2025
-
[56]
Language models use trigonometry to do addition, 2025
Subhash Kantamneni and Max Tegmark. Language models use trigonometry to do addition, 2025. URLhttps://arxiv.org/abs/2502.00873
arXiv 2025
-
[57]
Korchinski, Andres Nava, Matthieu Wyart, and Yasaman Bahri
Dhruva Karkada, Daniel J. Korchinski, Andres Nava, Matthieu Wyart, and Yasaman Bahri. Symmetry in language statistics shapes the geometry of model representations,
-
[58]
URLhttps://arxiv.org/abs/2602.15029
-
[59]
The effects of time preferences on cooperation: Experimental evidence from infinitely repeated games.American Economic Journal: Microeconomics, 15(1): 618–637, 2023
Jeongbin Kim. The effects of time preferences on cooperation: Experimental evidence from infinitely repeated games.American Economic Journal: Microeconomics, 15(1): 618–637, 2023. 12
2023
-
[60]
Linear representations of political perspective emerge in large language models, 2025
Junsol Kim, James Evans, and Aaron Schein. Linear representations of political perspective emerge in large language models, 2025. URLhttps://arxiv.org/abs/ 2503.02080
arXiv 2025
-
[61]
Kris N. Kirby, Nancy M. Petry, and Warren K. Bickel. Heroin addicts have higher discount rates for delayed rewards than non-drug-using controls.Journal of Experimental Psychology: General, 128(1):78–87, 1999. doi: 10.1037/0096-3445.128. 1.78
-
[62]
Korsgaard
Christine M. Korsgaard. The normativity of instrumental reason. In Garrett Cullity and Berys Gaut, editors,Ethics and Practical Reason, pages 215–254. Oxford University Press, Oxford, 1997
1997
-
[63]
Linear representations in language models can change dramatically over a conversation, 2026
Andrew Kyle Lampinen, Yuxuan Li, Eghbal Hosseini, Sangnie Bhardwaj, and Murray Shanahan. Linear representations in language models can change dramatically over a conversation, 2026. URLhttps://arxiv.org/abs/2601.20834
arXiv 2026
-
[64]
Geometric signatures of compositionality across a language model’s lifetime, 2025
Jin Hwa Lee, Thomas Jiralerspong, Lei Yu, Yoshua Bengio, and Emily Cheng. Geometric signatures of compositionality across a language model’s lifetime, 2025. URLhttps://arxiv.org/abs/2410.01444
arXiv 2025
-
[65]
Cambridge University Press, 2021
Tom Leinster.Entropy and Diversity: The Axiomatic Approach. Cambridge University Press, 2021. ISBN 9781108832700. doi: 10.1017/9781108963558
-
[66]
Yan Leng. Can LLMs mimic human-like mental accounting and behavioral biases? In Proceedings of the 25th ACM Conference on Economics and Computation (EC ’24). ACM, 2024. doi: 10.1145/3670865.3673632
-
[67]
Folk economics in the machine: LLMs and the emergence of mental accounting.SSRN preprint 4705130, 2024
Yan Leng. Folk economics in the machine: LLMs and the emergence of mental accounting.SSRN preprint 4705130, 2024
2024
-
[68]
Steering vector fields for context-aware inference-time control in large language models, 2026
Jiaqian Li, Yanshu Li, and Kuan-Hao Huang. Steering vector fields for context-aware inference-time control in large language models, 2026. URLhttps://arxiv.org/abs/ 2602.01654
arXiv 2026
-
[69]
The other mind: How language models exhibit human temporal cognition, 2025
Lingyu Li, Yang Yao, Yixu Wang, Chubo Li, Yan Teng, and Yingchun Wang. The other mind: How language models exhibit human temporal cognition, 2025. URL https://arxiv.org/abs/2507.15851
arXiv 2025
-
[70]
Time-r1: Towards comprehensive temporal reasoning in llms, 2025
Zijia Liu, Peixuan Han, Haofei Yu, Haoru Li, and Jiaxuan You. Time-r1: Towards comprehensive temporal reasoning in llms, 2025. URLhttps://arxiv.org/abs/2505. 13508
2025
-
[71]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InConference on Language Modeling (COLM), 2024. URLhttps://arxiv.org/abs/2310.06824
Pith/arXiv arXiv 2024
-
[72]
Ali Mazyaki, Mohammad Naghizadeh, Samaneh Ranjkhah Zonouzaghi, and Hossein Setareh. Temporal preferences in language models for long-horizon assistance.arXiv preprint arXiv:2509.09704, 2025
arXiv 2025
-
[73]
Frontier models are capable of in-context scheming, 2025
Alexander Meinke, Bronson Schoen, Jérémy Scheurer, Mikita Balesni, Rusheb Shah, and Marius Hobbhahn. Frontier models are capable of in-context scheming, 2025. URL https://arxiv.org/abs/2412.04984
Pith/arXiv arXiv 2025
-
[74]
Ian M. Mitchell, Alexandre M. Bayen, and Claire J. Tomlin. A time-dependent Hamilton–Jacobi formulation of reachable sets for continuous dynamic games.IEEE Transactions on Automatic Control, 50(7):947–957, 2005. doi: 10.1109/TAC.2005. 851439
-
[75]
Fully autonomous AI agents should not be developed.arXiv preprint arXiv:2502.02649, 2025
Margaret Mitchell, Avijit Ghosh, Alexandra Sasha Luccioni, and Giada Pistilli. Fully autonomous AI agents should not be developed.arXiv preprint arXiv:2502.02649, 2025. 13
arXiv 2025
-
[77]
URLhttps://arxiv.org/abs/2505.18235
-
[78]
Decoupling time and risk: Risk-sensitive reinforcement learning with general discounting, 2026
Mehrdad Moghimi, Anthony Coache, and Hyejin Ku. Decoupling time and risk: Risk-sensitive reinforcement learning with general discounting, 2026. URLhttps: //arxiv.org/abs/2602.04131
arXiv 2026
-
[79]
Mib: A mechanistic interpretability benchmark, 2025
Aaron Mueller, Atticus Geiger, Sarah Wiegreffe, Dana Arad, Iván Arcuschin, Adam Belfki, Yik Siu Chan, Jaden Fiotto-Kaufman, Tal Haklay, Michael Hanna, Jing Huang, Rohan Gupta, Yaniv Nikankin, Hadas Orgad, Nikhil Prakash, Anja Reusch, Aruna Sankaranarayanan, Shun Shao, Alessandro Stolfo, Martin Tutek, Amir Zur, David Bau, and Yonatan Belinkov. Mib: A mecha...
arXiv 2025
-
[80]
Jatin Nainani, Sankaran Vaidyanathan, Connor Watts, Andre N. Assis, and Alice Rigg. Detecting and characterizing planning in language models, 2025. URLhttps: //arxiv.org/abs/2508.18098
arXiv 2025
-
[81]
The alignment problem from a deep learning perspective, 2025
Richard Ngo, Lawrence Chan, and Sören Mindermann. The alignment problem from a deep learning perspective, 2025. URLhttps://arxiv.org/abs/2209.00626
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.