VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
Pith reviewed 2026-06-28 06:58 UTC · model grok-4.3
The pith
A new dataset of 315K video reasoning examples improves models on knowledge-intensive tasks while staying competitive on general benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Post-training models on VideoKR produces better results on knowledge-intensive video reasoning than prior post-training methods while remaining competitive on general video reasoning, which the authors attribute to the design of the examples and their rationales.
What carries the argument
The human-in-the-loop, skill-oriented example generation pipeline that creates progressively deeper reasoning examples and reliable CoT rationales from expert-domain videos.
If this is right
- Post-training on VideoKR raises accuracy on knowledge-intensive video reasoning tasks relative to earlier datasets.
- The same models stay competitive on standard general video reasoning benchmarks.
- Ablation studies separate the contribution of the new data from other training factors.
- Data design choices, including skill progression and rationale quality, drive measurable gains in video reasoning.
Where Pith is reading between the lines
- The same pipeline could be adapted to generate training data for other complex multimodal tasks where shortcuts are common.
- Scaling the number of videos while preserving the human-in-the-loop checks might further widen the gap on knowledge-heavy benchmarks.
- Benchmarks like VideoKR-Eval could become standard tests for whether video models truly integrate visual and knowledge sources.
Load-bearing premise
The pipeline ensures that the chain-of-thought rationales demand genuine video understanding and external knowledge instead of allowing models to exploit textual patterns or shortcuts.
What would settle it
Models post-trained on VideoKR would show no advantage on VideoKR-Eval if the videos were replaced by static text descriptions of their content.
Figures







read the original abstract
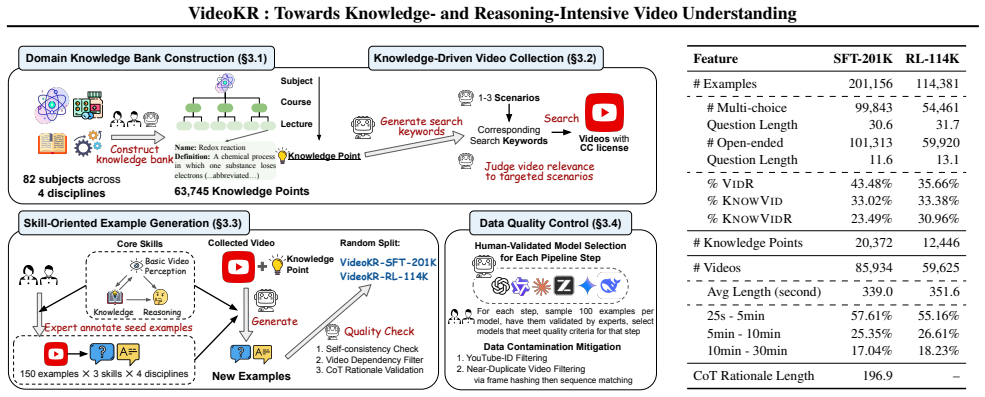
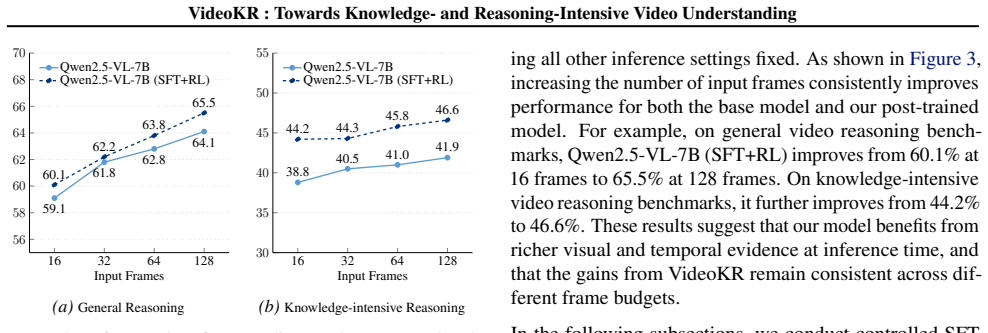
We introduce VideoKR, the first large-scale training corpus specifically designed to strengthen knowledge- and reasoning-intensive video understanding. It comprises 315K video reasoning examples over 145K newly collected, CC-licensed, expert-domain videos. We develop a human-in-the-loop, skill-oriented example generation pipeline that targets progressively deeper video reasoning capabilities while ensuring the difficulty, diversity, and reliability of both the examples and their CoT rationales. We also curate VideoKR-Eval, a new expert-annotated benchmark where questions require genuine video understanding and knowledge-intensive reasoning rather than textual shortcuts. Our experiments show that, under a standard SFT$\rightarrow$GRPO pipeline, models post-trained on VideoKR outperform prior post-training approaches on knowledge-intensive video reasoning while remaining competitive on general video reasoning, highlighting data design as a key driver of progress in video reasoning. We further conduct comprehensive ablations to isolate the contributions of VideoKR, providing actionable insights for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoKR, a 315K-example training corpus over 145K newly collected videos, generated via a human-in-the-loop skill-oriented pipeline that produces CoT rationales, together with the expert-annotated VideoKR-Eval benchmark. Under a fixed SFT→GRPO post-training regime, models trained on VideoKR are reported to outperform prior post-training methods on knowledge-intensive video reasoning while remaining competitive on general video reasoning; comprehensive ablations are said to isolate the contributions of the data design.
Significance. If the central claims are substantiated, the work supplies a large-scale, expert-curated resource and a new benchmark that could serve as a foundation for future video-reasoning research. The emphasis on data curation as a driver of progress, together with the reported ablations, would provide concrete guidance for dataset construction in the field.
major comments (2)
- [VideoKR-Eval and experiments] VideoKR-Eval description and experiments: the attribution of gains to 'genuine video understanding and knowledge-intensive reasoning rather than textual shortcuts' is load-bearing for the headline claim. No text-only baseline accuracies, caption-only results, or quantitative verification that questions cannot be solved from text/priors alone are reported, leaving the assumption that the human-in-the-loop pipeline and expert annotation enforce video necessity unsupported by evidence.
- [Experiments] Experiments and ablations: while the abstract states that models 'outperform prior post-training approaches' and that 'comprehensive ablations' were conducted, the provided text supplies neither numerical metrics, specific baseline names and scores, nor details on what was ablated (e.g., data scale, rationale quality, skill categories). This absence prevents assessment of effect sizes and robustness of the central result.
minor comments (1)
- [Abstract] Abstract: the phrase 'comprehensive ablations' is used without enumerating the factors varied; a short parenthetical list would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important gaps in evidence and reporting that we will address through revisions. We respond point-by-point below.
read point-by-point responses
-
Referee: [VideoKR-Eval and experiments] VideoKR-Eval description and experiments: the attribution of gains to 'genuine video understanding and knowledge-intensive reasoning rather than textual shortcuts' is load-bearing for the headline claim. No text-only baseline accuracies, caption-only results, or quantitative verification that questions cannot be solved from text/priors alone are reported, leaving the assumption that the human-in-the-loop pipeline and expert annotation enforce video necessity unsupported by evidence.
Authors: We agree this verification is necessary to support the central claim. In the revised manuscript we will add text-only baseline results (models evaluated on question text alone) and caption-only results on VideoKR-Eval, together with quantitative comparisons showing substantial performance drops when video content is removed. These additions will directly demonstrate that the benchmark questions require video input rather than textual shortcuts or priors. revision: yes
-
Referee: [Experiments] Experiments and ablations: while the abstract states that models 'outperform prior post-training approaches' and that 'comprehensive ablations' were conducted, the provided text supplies neither numerical metrics, specific baseline names and scores, nor details on what was ablated (e.g., data scale, rationale quality, skill categories). This absence prevents assessment of effect sizes and robustness of the central result.
Authors: We acknowledge that the main text should contain explicit numerical results, baseline names, scores, and ablation details for transparency. The revised version will expand the experiments section to include these: specific scores against named prior methods, effect sizes, and breakdowns of ablations on data scale, rationale quality, and skill categories. This will allow direct assessment of the reported gains. revision: yes
Circularity Check
No significant circularity; empirical results from new data and standard training
full rationale
The paper introduces a new corpus (315K examples) and benchmark via a described human-in-the-loop pipeline, then reports empirical performance of models post-trained with standard SFT→GRPO on that data versus priors. No equations, fitted parameters, or self-citations reduce the claimed gains to inputs by construction. The VideoKR-Eval design and ablations are methodological choices whose validity is externally testable via model accuracy; they do not tautologically define the outcome. This matches the default expectation for data-centric papers with independent evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators in the loop produce accurate and video-dependent chain-of-thought rationales
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y ., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y ., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Eagle 2.5: Boosting long-context post-training for frontier vision-language models, 2025a
Chen, G., Li, Z., Wang, S., Jiang, J., Liu, Y ., Lu, L., Huang, D.-A., Byeon, W., Le, M., Rintamaki, T., Poon, T., Ehrlich, M., Rintamaki, T., Poon, T., Lu, T., Wang, L., Catanzaro, B., Kautz, J., Tao, A., Yu, Z., and Liu, G. Eagle 2.5: Boosting long-context post-training for frontier vision-language models, 2025a. URL https: //arxiv.org/abs/2504.15271. C...
- [3]
-
[4]
Video-R1: Reinforcing Video Reasoning in MLLMs
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y ., Peng, T., Wu, J., Zhang, X., Wang, B., and Yue, X. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025a. Feng, K., Zhang, M., Li, H., Fan, K., Chen, S., Jiang, Y ., Zheng, D., Sun, P., Zhang, Y ., Sun, H., et al. Onethinker: All-in-one reasoning model for image and video.arXi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
URL https: //arxiv.org/abs/2405.21075. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
URLhttps://arxiv.org/abs/2501.13826. Li, B., Zhang, P., Zhang, K., Pu, F., Du, X., Dong, Y ., Liu, H., Zhang, Y ., Zhang, G., Li, C., and Liu, Z. Lmms- eval: Accelerating the development of large multimodal models, March 2024a. URL https://github.com/ EvolvingLMMs-Lab/lmms-eval. Li, K., Wang, Y ., He, Y ., Li, Y ., Wang, Y ., Liu, Y ., Wang, Z., Xu, J., C...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
doi: 10.1109/TIP.2025.3649356. Liu, S., Zhuge, M., Zhao, C., Chen, J., Wu, L., Liu, Z., Zhu, C., Cai, Z., Zhou, C., Liu, H., Chang, E., Suri, S., Xu, H., Qian, Q., Wen, W., Varadarajan, B., Liu, Z., Xu, H., Bordes, F., Krishnamoorthi, R., Ghanem, B., Chandra, V ., and Xiong, Y . Videoauto-r1: Video auto reasoning via thinking once, answering twice. 2026a....
-
[8]
Ouyang, K., Liu, Y ., Wu, H., Liu, Y ., Zhou, H., Zhou, J., Meng, F., and Sun, X
URLhttps://arxiv.org/abs/2411.04923. Ouyang, K., Liu, Y ., Wu, H., Liu, Y ., Zhou, H., Zhou, J., Meng, F., and Sun, X. Spacer: Reinforcing mllms in video spatial reasoning,
-
[9]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
URL https://arxiv. org/abs/2504.01805. Plizzari, C., Tonioni, A., Xian, Y ., Kulshrestha, A., and Tombari, F. Omnia de egotempo: Benchmarking tem- poral understanding of multi-modal llms in egocentric videos
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ren, W., Ma, W., Yang, H., Wei, C., Zhang, G., and Chen, W
URL https://arxiv.org/abs/ 2503.13646. Ren, W., Ma, W., Yang, H., Wei, C., Zhang, G., and Chen, W. Vamba: Understanding hour-long videos with hybrid mamba-transformers.arXiv preprint arXiv:2503.11579,
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexi- ble and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Song, E., Chai, W., Xu, W., Xie, J., Liu, Y ., and Wang, G. Video-mmlu: A massive multi-discipline lecture under- standing benchmark.arXiv preprint arXiv:2504.14693,
-
[14]
Video spatial reasoning with object-centric 3d rollout
Tang, H., Cao, M., Liu, R., Liang, X., Li, L., Li, G., and Liang, X. Video spatial reasoning with object-centric 3d rollout. 2025a. URL https://arxiv.org/abs/ 2511.13190. Tang, Y . Y ., Shimada, D., Hua, H., Huang, C., Bi, J., Feris, R., and Xu, C. Video-r4: Reinforcing text-rich video reasoning with visual rumination. 2025b. URL https: //arxiv.org/abs/25...
-
[15]
Wang, Q., Yu, Y ., Yuan, Y ., Mao, R., and Zhou, T. Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning.arXiv preprint arXiv:2505.12434, 2025a. Wang, S., Jin, J., Wang, X., Song, L., Fu, R., Wang, H., Ge, Z., Lu, Y ., and Cheng, X. Video-thinker: Sparking” thinking with videos” via reinforcement learning.arXiv preprint a...
-
[16]
URL https://openreview. net/forum?id=3G1ZDXOI4f. Wu, R., Ma, X., Ci, H., Fan, Y ., Wang, Y ., Zhao, H., Li, Q., and Wang, Y . Longvitu: Instruction tuning for long-form video understanding.arXiv preprint arXiv:2501.05037,
-
[17]
arXiv preprint arXiv:2510.11606 , year=
URLhttps://arxiv.org/ abs/2510.11606. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, J., Yang, S., Gupta, A. W., Han, R., Fei-Fei, L., and Xie, S. Thinking in space: How multimodal large language models see, remember, and recall spac...
-
[18]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
URL https://arxiv. org/abs/2403.13372. Zhou, J., Shu, Y ., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y ., Zhang, B., Huang, T., and Liu, Z. Mlvu: Benchmarking multi-task long video understanding
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
MLVU: Benchmarking Multi-task Long Video Understanding
URL https://arxiv.org/ abs/2406.04264. Zohar, O., Wang, X., Bitton, Y ., Szpektor, I., and Yeung- Levy, S. Video-star: Self-training enables video instruc- tion tuning with any supervision,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URL https: //arxiv.org/abs/2407.06189. Zohar, O., Wang, X., Dubois, Y ., Mehta, N., Xiao, T., Hansen-Estruch, P., Yu, L., Wang, X., Juefei-Xu, F., Zhang, N., et al. Apollo: An exploration of video under- standing in large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 18891–18901,
-
[21]
Step 1: Define Problem
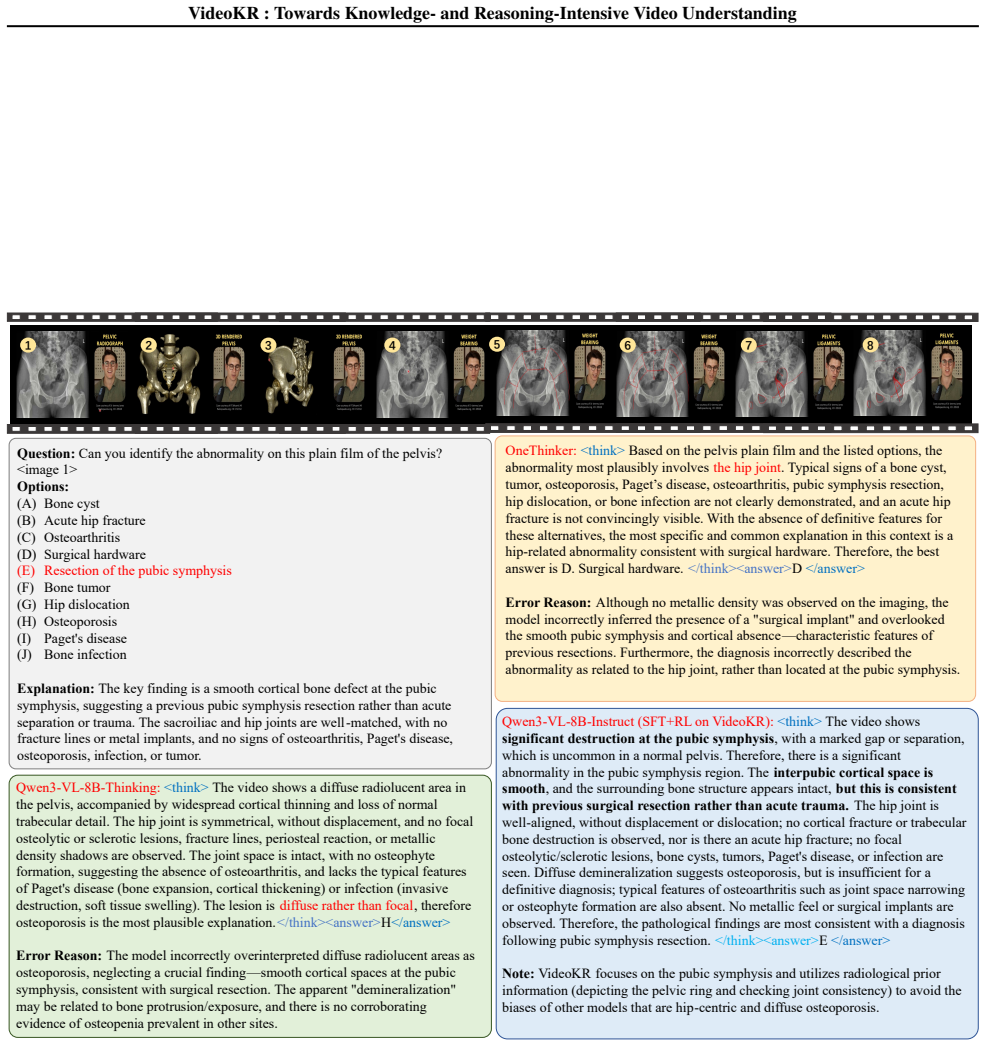
× 100 ≈ 17.2872%, round to two decimal places to get 17.29%, which corresponds to option B. A. 16.89% B. 17.29% C. 17.50% D. 18.00% Figure 6.A VideoKR-SFT-201K example from the engineering domain. The reasoning process is presented in a concise and abbreviated form to improve readability. Q: In the illustration with a warehouse, how many helmeted figures ...
2020
-
[22]
Deeds" as stated at around 00:18.(...abbreviated...)The title specifically uses
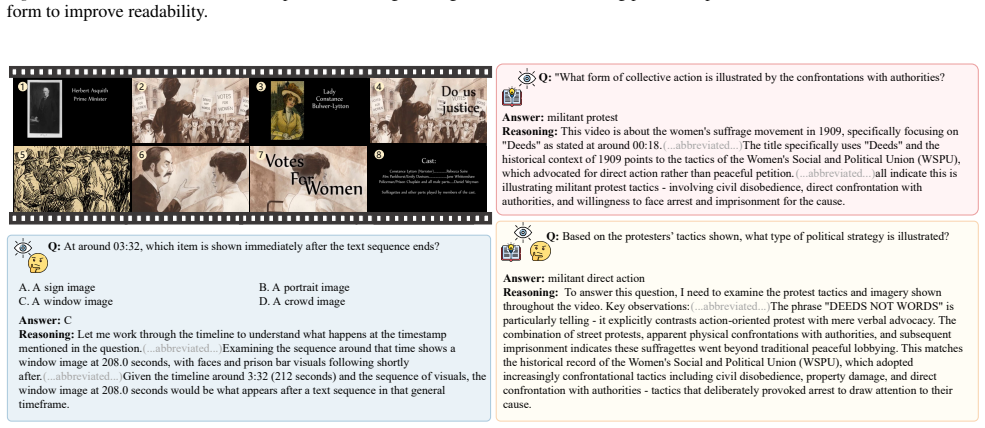
1 2 3 4 5 6 7 8 Figure 7.A VideoKR-SFT-201K example from the engineering domain. The reasoning process is presented in a concise and abbreviated form to improve readability. Q: At around 03:32, which item is shown immediately after the text sequence ends? Answer:C Reasoning:Let me work through the timeline to understand what happens at the timestamp menti...
1909
-
[23]
aha moment
as our reinforcement learning algorithm. Following the standard RLVR-style reward formulation, the total reward is defined as R= 0.1·R f + 0.9·R a, where Rf and Ra denote theformatandaccuracyrewards, respectively. Specifically, Rf is set to 1.0 if the model output strictly satisfies the required format: <think>...</think><answer>...</answer>. For the accu...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.