SentinelBench: A Benchmark for Long-Running Monitoring Agents
Pith reviewed 2026-06-28 06:07 UTC · model grok-4.3
The pith
SentinelBench is a benchmark of 100 tasks that tests whether AI agents can monitor changing web environments patiently instead of acting continuously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
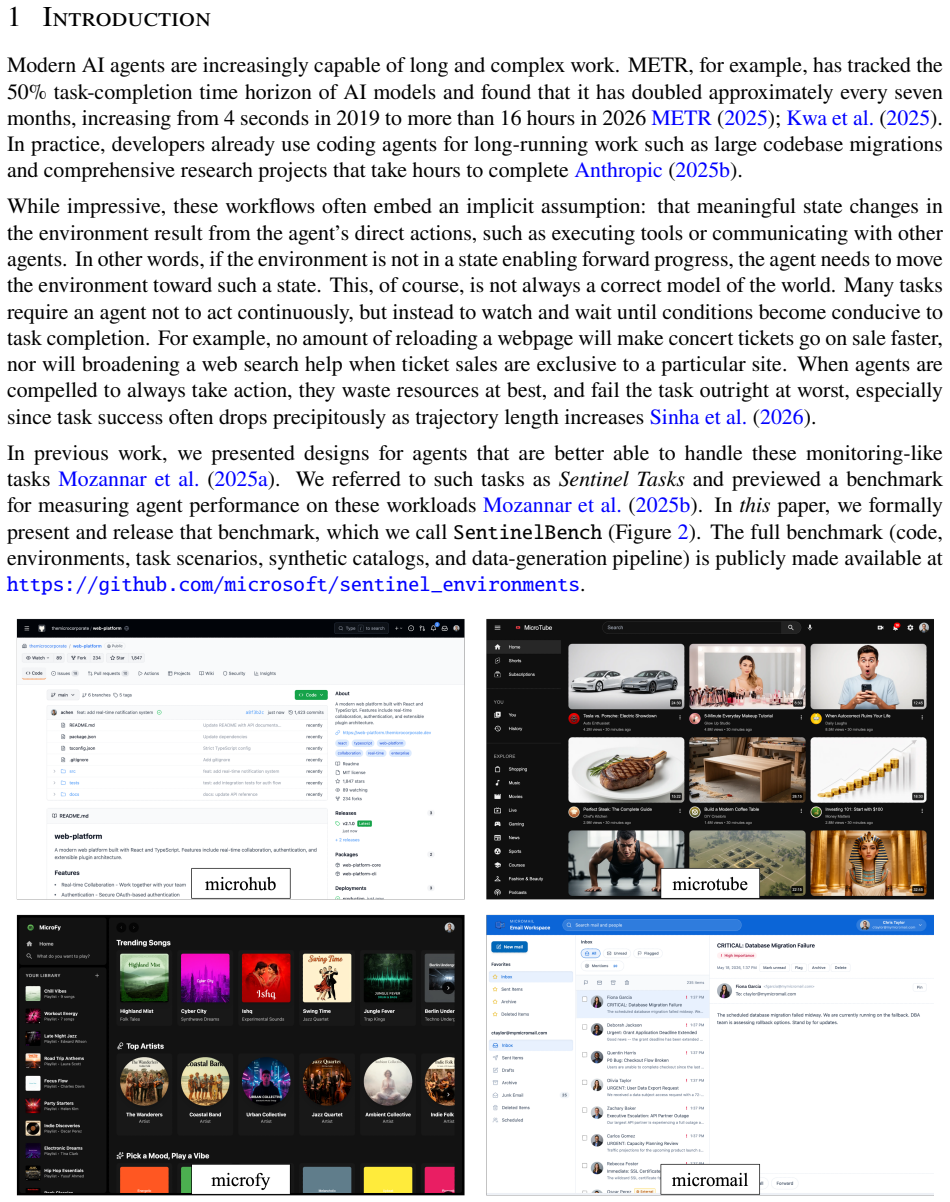
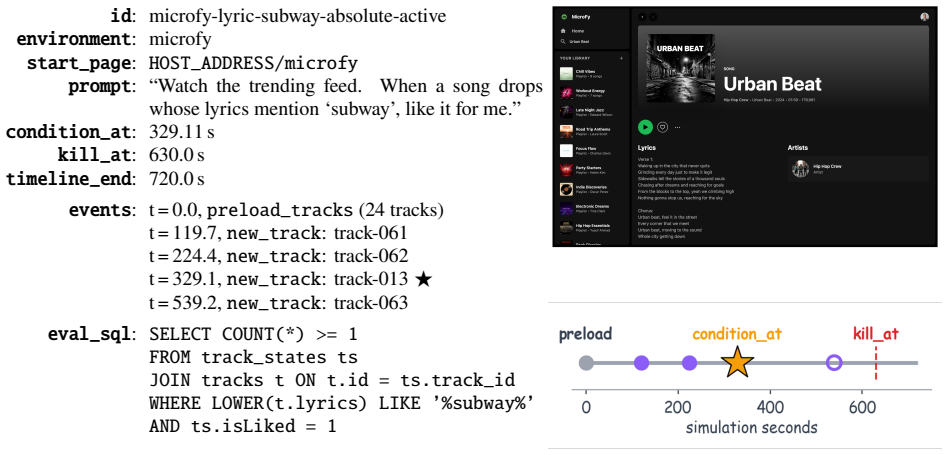
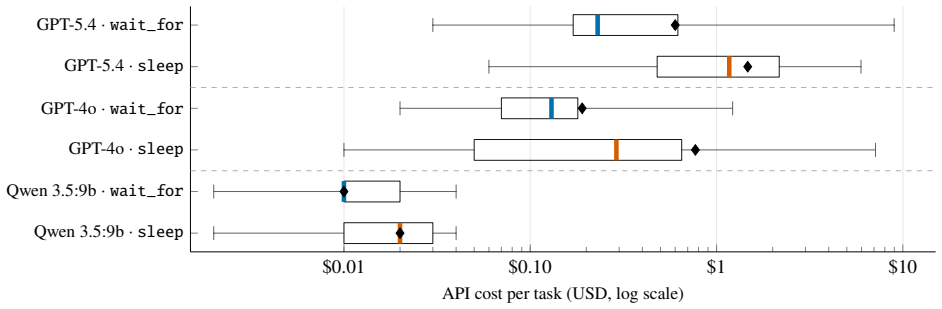
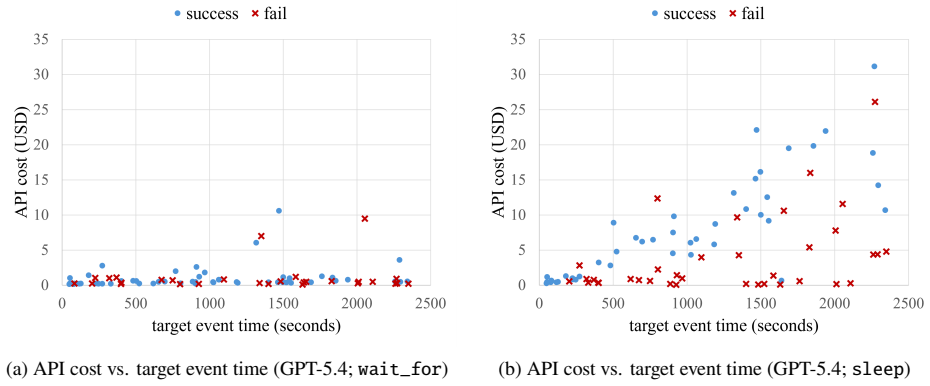
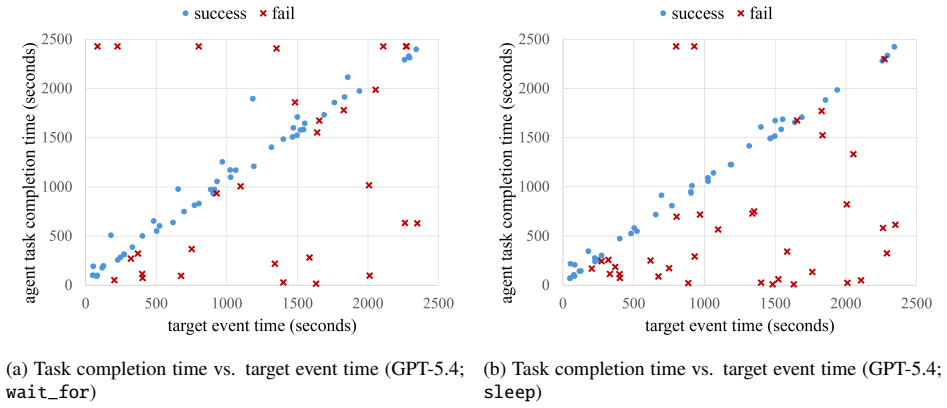
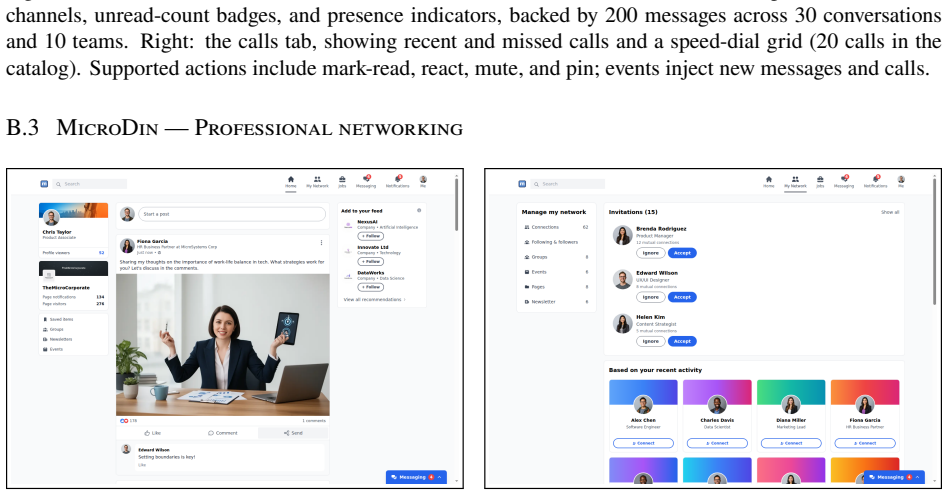
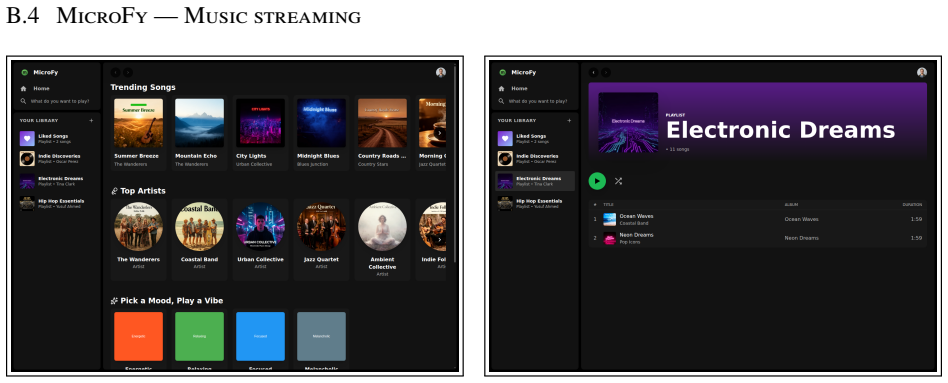
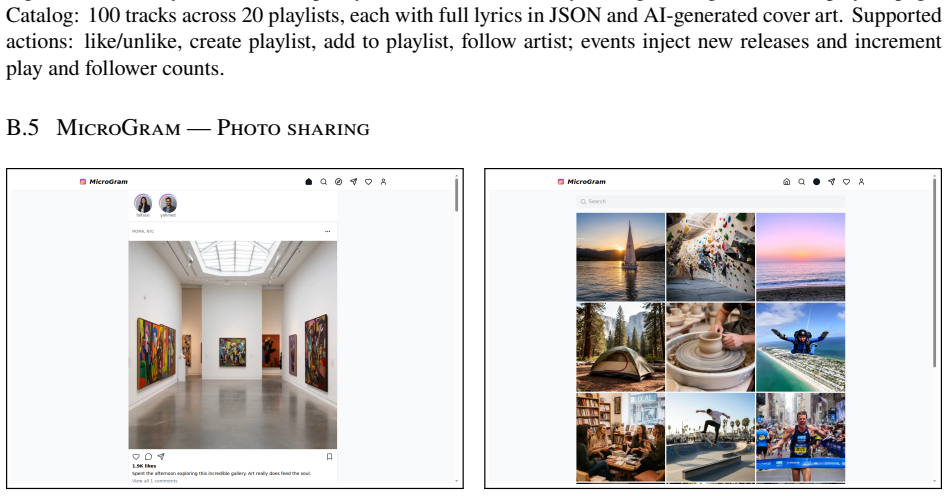
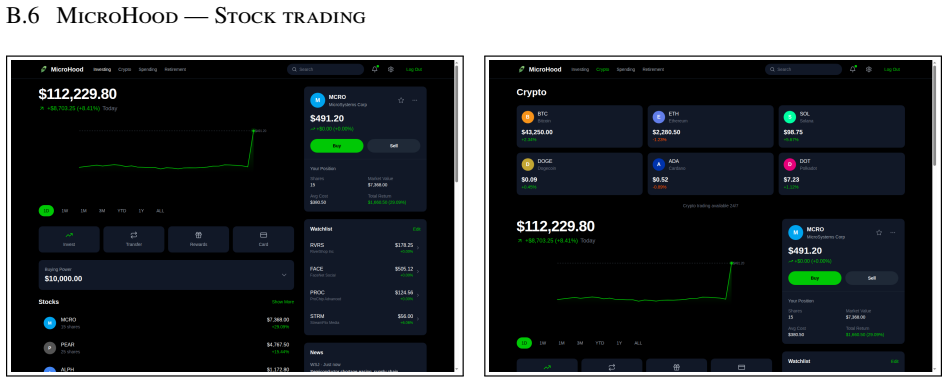
SentinelBench contains 100 tasks across ten synthetic web environments that expose live interfaces and replay scripted event sequences, requiring agents to navigate pages whose state changes over time. It measures task completion, reaction time, and resource use to quantify the tradeoff between responsiveness and cost, and baseline results across three models and two harnesses establish that the benchmark distinguishes meaningful differences in agent behavior.
What carries the argument
Time-evolving synthetic web environments with scripted event sequences that test sustained attention by requiring agents to wait for external changes before acting.
If this is right
- Agent designs that favor waiting will record lower resource use while preserving high task completion rates.
- Reaction time becomes a primary evaluation metric alongside accuracy for monitoring tasks.
- Browser harness choices can produce large swings in measured cost and responsiveness.
- Future agents can be ranked against the reported baselines on the same 100 tasks.
Where Pith is reading between the lines
- Similar scripted-event environments could be built for non-web domains such as sensor streams or file-system monitoring.
- The measured cost-reaction tradeoff may encourage hybrid agent loops that switch between idle and active modes based on predicted event timing.
- Public leaderboards built on these tasks would make sustained-attention performance a visible optimization target for model developers.
Load-bearing premise
The ten synthetic web environments and their scripted sequences are representative enough of real-world long-running monitoring tasks to support claims about agent design tradeoffs.
What would settle it
Running the same agents on actual deployed monitoring tasks outside the ten synthetic environments and finding that relative performance rankings reverse or that resource and reaction metrics no longer correlate with task success.
Figures



read the original abstract
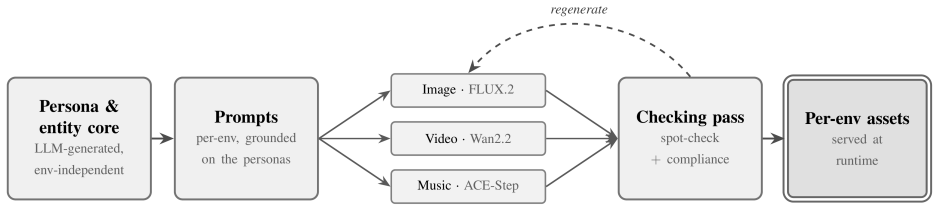
AI agents are increasingly asked to carry out work that spans minutes, hours, or longer. Yet the default model of agent behavior is continuous action: issuing tool calls, refreshing pages, searching for alternatives, or otherwise trying to force progress. This is the wrong approach for many long-running tasks, which are better served by a strategy of sustained attention. Instead, agents should monitor an environment, notice when an external event makes progress possible, then respond promptly without wasting resources while waiting. To measure progress on this class of tasks, we introduce SentinelBench, an open-source benchmark for time-evolving monitoring tasks. SentinelBench contains 100 tasks across 10 synthetic web environments, including email, calendars, finance, professional networking, and entertainment. Each environment exposes a live web interface and replays a scripted sequence of events, requiring agents to navigate and reason about web pages whose state shifts underfoot. SentinelBench measures task completion, reaction time, and resource use, exposing the tradeoff between responsiveness and cost. We report results across three models and two browser-agent harnesses, establishing performance baselines for future comparison and demonstrating how agent design choices can dramatically impact key metrics. Together, these results show that SentinelBench distinguishes meaningful differences in agent behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SentinelBench, an open-source benchmark with 100 tasks across 10 synthetic web environments (email, calendars, finance, etc.) that replay scripted event sequences. Agents must navigate live web interfaces, monitor for state changes, and respond promptly without continuous action. It evaluates three models and two browser-agent harnesses on task completion, reaction time, and resource use, establishing baselines and claiming that the benchmark distinguishes meaningful differences in agent behavior for long-running monitoring tasks.
Significance. If the benchmark's validity holds, it fills a gap by targeting sustained-attention strategies over continuous-action defaults, providing reproducible baselines and exposing responsiveness-cost tradeoffs. The open-source release and focus on time-evolving web tasks could support systematic progress on long-horizon agent design.
major comments (2)
- [Abstract] Abstract: the central claim that 'these results show that SentinelBench distinguishes meaningful differences in agent behavior' rests on performance gaps across models/harnesses, yet the scripted event sequences (explicitly described as 'replays a scripted sequence of events') create a risk that agents optimize for detectable patterns or fixed timings rather than genuine responsiveness to unpredictable external events; this directly threatens whether the reported metrics test the intended monitoring tradeoff.
- [Abstract] Abstract and benchmark construction: the 10 synthetic environments are asserted to be representative of real-world long-running monitoring, but no justification, diversity metrics, or comparison to live unpredictable inputs is provided; without this, distinctions in completion/reaction/resource metrics may not generalize beyond the specific scripted replays.
minor comments (2)
- [Abstract] Abstract: 'establishing performance baselines for future comparison' would be strengthened by explicit mention of the exact models, harnesses, and aggregate metric values (even if detailed tables appear later).
- The description of environments as 'live web interface' while also 'replays a scripted sequence' creates minor ambiguity about whether the interface is truly dynamic or deterministic; clarify in the methods section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract and benchmark design. We address each point below, agreeing where the manuscript requires clarification or expansion and proposing targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'these results show that SentinelBench distinguishes meaningful differences in agent behavior' rests on performance gaps across models/harnesses, yet the scripted event sequences (explicitly described as 'replays a scripted sequence of events') create a risk that agents optimize for detectable patterns or fixed timings rather than genuine responsiveness to unpredictable external events; this directly threatens whether the reported metrics test the intended monitoring tradeoff.
Authors: We acknowledge the valid concern that scripted replays could allow pattern exploitation rather than true event-driven monitoring. However, the benchmark still requires agents to observe live web interfaces and react to state changes whose exact timing is not known in advance, which directly tests the distinction between sustained attention and continuous-action strategies. The reported gaps in reaction time and resource use reflect meaningful behavioral differences under these conditions. That said, we agree the setup does not fully address stochastic real-world events. We will revise the abstract to temper the claim and add an explicit limitations paragraph noting the controlled nature of the scripts and the value of future live-input extensions. This constitutes a partial revision. revision: partial
-
Referee: [Abstract] Abstract and benchmark construction: the 10 synthetic environments are asserted to be representative of real-world long-running monitoring, but no justification, diversity metrics, or comparison to live unpredictable inputs is provided; without this, distinctions in completion/reaction/resource metrics may not generalize beyond the specific scripted replays.
Authors: The environments were chosen to span common categories of time-evolving web tasks (email, calendar, finance, etc.), but we agree that the manuscript provides insufficient explicit justification, diversity metrics, or discussion of generalization. In the revised version we will expand the benchmark construction section with: (1) selection rationale tied to prevalence in real-world monitoring scenarios, (2) quantitative diversity measures such as event frequency variance and state-change counts per environment, and (3) a clearer statement that the synthetic replays provide reproducible baselines while not substituting for fully live, unpredictable inputs. This will be addressed with a full revision on this point. revision: yes
Circularity Check
No circularity: benchmark definition with direct empirical reporting
full rationale
The paper introduces SentinelBench as a new benchmark consisting of 100 tasks in 10 synthetic web environments with scripted event sequences, then reports measured task completion, reaction time, and resource metrics across three models and two harnesses. No equations, parameter fitting, derivations, or self-citation chains appear in the provided text. The central claim that the benchmark distinguishes meaningful differences rests on the explicit construction and execution of those tasks rather than any reduction to prior fitted inputs or self-referential definitions. This is a standard benchmark paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.17158 , year=
ARE: Scaling up agent environments and evaluations , author=. arXiv preprint arXiv:2509.17158 , year=
-
[2]
The Fourteenth International Conference on Learning Representations (ICLR) , url=
GAIA2: Benchmarking llm agents on dynamic and asynchronous environments , author=. The Fourteenth International Conference on Learning Representations (ICLR) , url=
-
[3]
Proactive agent research environment: Simulating active users to evaluate proactive assistants , author=. arXiv preprint arXiv:2604.00842 , year=
-
[4]
and Barnes, Elizabeth and Chan, Lawrence , journal =
Kwa, Thomas and West, Ben and Becker, Joel and Deng, Amy and Garcia, Katharyn and Hasin, Max and Jawhar, Sami and Kinniment, Megan and Rush, Nate and Von Arx, Sydney and Bloom, Ryan and Broadley, Thomas and Du, Haoxing and Goodrich, Brian and Jurkovic, Nikola and Miles, Luke Harold and Nix, Seraphina and Lin, Tao and Parikh, Neev and Rein, David and Sato,...
2025
-
[5]
Is there a half-life for the success rates of
Ord, Toby , year =. Is there a half-life for the success rates of. 2505.05115 , archivePrefix =
-
[6]
The Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems Break
The Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems Break , author=. arXiv preprint arXiv:2604.11978 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning , author=. arXiv preprint arXiv:2604.14140 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2604.00010 , year=
Can LLMs Perceive Time? An Empirical Investigation , author=. arXiv preprint arXiv:2604.00010 , year=
-
[9]
Odysseys: Benchmarking Web Agents on Realistic Long Horizon Tasks
Odysseys: Benchmarking Web Agents on Realistic Long Horizon Tasks , author=. arXiv preprint arXiv:2604.24964 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
2025 , month = jul, url =
How Does Time Horizon Vary Across Domains? , author =. 2025 , month = jul, url =
2025
-
[11]
2025 , url =
Wijk, Hjalmar and Lin, Tao and Becker, Joel and Jawhar, Sami and Parikh, Neev and Broadley, Thomas and Chan, Lawrence and Chen, Michael and Clymer, Josh and Dhyani, Jai and Ericheva, Elena and Garcia, Katharyn and Goodrich, Brian and Jurkovic, Nikola and Karnofsky, Holden and Kinniment, Megan and Lajko, Aron and Nix, Seraphina and Sato, Lucas and Saunders...
2025
-
[12]
2025 , url =
Rein, David and Becker, Joel and Deng, Amy and Nix, Seraphina and Canal, Chris and O'Connel, Daniel and Arnott, Pip and Bloom, Ryan and Broadley, Thomas and Garcia, Katharyn and Goodrich, Brian and Hasin, Max and Jawhar, Sami and Kinniment, Megan and Kwa, Thomas and Lajko, Aron and Rush, Nate and Sato, Lucas Jun Koba and Von Arx, Sydney and West, Ben and ...
2025
-
[13]
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in
Sinha, Akshit and Arun, Arvindh and Goel, Shashwat and Staab, Steffen and Geiping, Jonas , booktitle =. The Illusion of Diminishing Returns: Measuring Long Horizon Execution in. 2026 , url =
2026
-
[14]
and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , journal =
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , journal =. 2023 , url =
2023
-
[15]
2024 , url =
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel , journal =. 2024 , url =
2024
-
[16]
2024 , url =
He, Hongliang and Yao, Wenlin and Ma, Kaixin and Yu, Wenhao and Dai, Yong and Zhang, Hongming and Lan, Zhenzhong and Yu, Dong , journal =. 2024 , url =
2024
-
[17]
2023 , url =
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Sam and Wang, Boshi and Sun, Huan and Su, Yu , booktitle =. 2023 , url =
2023
-
[18]
2024 , url =
Yoran, Ori and Amouyal, Samuel Joseph and Malaviya, Chaitanya and Bogin, Ben and Press, Ofir and Berant, Jonathan , journal =. 2024 , url =
2024
- [19]
-
[20]
and Del Verme, Manuel and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , booktitle =
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , booktitle =. 2024 , editor =
2024
-
[21]
2024 , url =
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and Liu, Yitao and Xu, Yiheng and Zhou, Shuyan and Savarese, Silvio and Xiong, Caiming and Zhong, Victor and Yu, Tao , journal =. 2024 , url =
2024
-
[22]
2023 , url =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , journal =...
2023
-
[23]
and Kang, Jikun and Wu, Wenqi and Christianos, Filippos and Greenlee, Fraser and Toulis, Andy and Purtorab, Marvin , journal =
Thomas, George and Chan, Alex J. and Kang, Jikun and Wu, Wenqi and Christianos, Filippos and Greenlee, Fraser and Toulis, Andy and Purtorab, Marvin , journal =. 2025 , url =
2025
-
[24]
ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
ClawsBench: Evaluating capability and safety of llm productivity agents in simulated workspaces , author=. arXiv preprint arXiv:2604.05172 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2603.01357 , year=
ASTRA-bench: Evaluating Tool-Use Agent Reasoning and Action Planning with Personal User Context , author=. arXiv preprint arXiv:2603.01357 , year=
-
[26]
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios , author=. arXiv preprint arXiv:2601.08173 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2511.01527 , year=
TPS-Bench: Evaluating AI Agents' Tool Planning & Scheduling Abilities in Compounding Tasks , author=. arXiv preprint arXiv:2511.01527 , year=
-
[28]
AlphaEval: Evaluating Agents in Production
AlphaEval: Evaluating Agents in Production , author=. arXiv preprint arXiv:2604.12162 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
2026 , url =
Levy, Ido and Wiesel, Ben and Marreed, Sami and Oved, Alon and Yaeli, Avi and Shlomov, Segev , booktitle =. 2026 , url =
2026
-
[30]
Conference on Language Modeling (COLM) , year =
An Illusion of Progress? Assessing the Current State of Web Agents , author =. Conference on Language Modeling (COLM) , year =
-
[31]
International Conference on Learning Representations (ICLR) , year =
Mialon, Gr. International Conference on Learning Representations (ICLR) , year =
-
[32]
2024 , url =
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan , journal =. 2024 , url =
2024
-
[33]
and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z
Xu, Frank F. and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z. and Zhou, Xuhui and Guo, Zhitong and Cao, Murong and Yang, Mingyang and Lu, Hao Yang and Martin, Amaad and Su, Zhe and Maben, Leander and Mehta, Raj and Chi, Wayne and Jang, Lawrence and Xie, Yiqing and Zhou, Shuyan and Neubig, Graham , boo...
2024
-
[34]
arXiv preprint arXiv:2508.09124 , year =
Wang, Weixuan and Han, Dongge and Madrigal Diaz, Daniel and Xu, Jin and R. arXiv preprint arXiv:2508.09124 , year =
-
[35]
2026 , url =
Zhao, Yujie and Yuan, Boqin and Huang, Junbo and Yuan, Haocheng and Yu, Zhongming and Xu, Haozhou and Hu, Lanxiang and Shankarampeta, Abhilash and Huang, Zimeng and Ni, Wentao and Tian, Yuandong and Zhao, Jishen , journal =. 2026 , url =
2026
-
[36]
Empowering long-running
Thacker, Joseph , howpublished =. Empowering long-running. 2024 , month = may, url =
2024
-
[37]
2025 , url =
Tasks in. 2025 , url =
2025
-
[38]
2025 , month = jul, url =
Introducing. 2025 , month = jul, url =
2025
-
[39]
2026 , month = apr, note =
Schedule recurring tasks in. 2026 , month = apr, note =
2026
-
[40]
2025 , url =
Yutori Scouts:. 2025 , url =
2025
-
[41]
2025 , url =
Building the Proactive, Multi-Agent Architecture Powering Scouts , author =. 2025 , url =
2025
-
[42]
2025 , url =
Introducing ambient agents , author =. 2025 , url =
2025
-
[43]
From agent loops to structured graphs: A scheduler-theoretic framework for
Hu, Wei , journal =. From agent loops to structured graphs: A scheduler-theoretic framework for. 2026 , url =
2026
-
[44]
and Wutschitz, Lukas and Chen, Yanzhi and Sim, Robert and Rajmohan, Saravan , journal =
Kang, Minki and Chen, Wei-Ning and Han, Dongge and Inan, Huseyin A. and Wutschitz, Lukas and Chen, Yanzhi and Sim, Robert and Rajmohan, Saravan , journal =. 2025 , url =
2025
-
[45]
2022 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , journal =. 2022 , url =
2022
-
[46]
2025 , month = sep, url =
Effective Context Engineering for AI Agents , author =. 2025 , month = sep, url =
2025
-
[47]
2025 , url =
Mozannar, Hussein and Bansal, Gagan and Tan, Cheng and Fourney, Adam and Dibia, Victor and Chen, Jingya and Gerrits, Jack and Payne, Tyler and Maldaner, Matheus Kunzler and Grunde-McLaughlin, Madeleine and Zhu, Eric and Bassman, Griffin and Alber, Jacob and Chang, Peter and Loynd, Ricky and Niedtner, Friederike and Kamar, Ece and Murad, Maya and Hosn, Raf...
2025
-
[48]
2025 , month = oct, url =
Tell me when: Building agents that can wait, monitor, and act , author =. 2025 , month = oct, url =
2025
-
[49]
2025 , type =
Sabotage risk pilot report , author =. 2025 , type =
2025
-
[50]
arXiv preprint arXiv:2503.20314 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
2025 , url =
Gong, Junmin and Zhao, Wenxiao and Wang, Sen and Xu, Shengyuan and Guo, Jing , howpublished =. 2025 , url =
2025
-
[52]
2025 , month = nov, url =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.