Brick-Composer: Using MLLMs for Assembly with Diverse Bricks
Pith reviewed 2026-06-28 05:57 UTC · model grok-4.3
The pith
MLLMs acquire brick assembly skills through three training signals, tripling selection accuracy and raising step success to 15%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Brick assembly is formulated as a sequential decision-making problem where each step requires brick selection from candidates and pose estimation for placement. Current state-of-the-art MLLMs struggle with both subtasks. Brick-Composer equips MLLMs with assembly capabilities by combining Human Design Sparks that supply affordance-rich construction demonstrations, World Feedback that grounds predictions in visual and physical outcomes, and Synthetic Experience that scales training beyond existing designs. The result is brick selection accuracy improved by over three times, substantially lower pose estimation errors, and strict step-level assembly success increased from less than 1% to around
What carries the argument
Brick-Composer learning framework that integrates Human Design Sparks for demonstrations, World Feedback for physical grounding, and Synthetic Experience for scaling to train MLLMs on sequential brick selection and pose estimation.
If this is right
- Brick selection accuracy improves by over three times compared with baseline MLLMs.
- Pose estimation errors are substantially reduced.
- Strict step-level assembly success rises from less than 1% to around 15%.
- A fine-tuned Qwen-3-8B model can correctly compose up to 42% of the steps for a complete object.
Where Pith is reading between the lines
- The same three-signal approach might transfer to assembly tasks with different building blocks such as furniture or modular robots.
- BC-Bench could serve as a reusable testbed for measuring progress in MLLM spatial reasoning over time.
- Closing the remaining gap to reliable full-object assembly would likely require tighter integration between the learned policy and real-world robot execution.
Load-bearing premise
The three proposed training signals can be combined and applied to MLLMs to produce the stated performance gains without requiring additional unstated assumptions about simulation fidelity or model fine-tuning details.
What would settle it
Retraining the same base MLLM with only two of the three signals and measuring whether step-level assembly success remains below 5% on BC-Bench would test whether the full combination is required for the reported gains.
Figures









read the original abstract
We dream of AI agents that can read arbitrary designs and construct real-world objects from reusable building blocks. As a first step toward this vision, we study whether multimodal large language models (MLLMs) possess the visual grounding and spatial reasoning capabilities required for brick assembly. We formulate brick assembly as a sequential decision-making problem, where each step involves two subtasks: brick selection, identifying the target brick from candidate components, and brick pose estimation, predicting where and how the selected brick should be placed. To support this study, we introduce BC-Bench (Brick Construction Benchmark), the first benchmark for evaluating MLLMs on assembly with diverse bricks. Experiments show that current state-of-the-art MLLMs remain far from reliable builders, struggling with fine-grained brick selection and failing at precise pose estimation. To bridge this gap, we propose Brick-Composer, a learning framework that equips MLLMs with assembly skills through three complementary signals: Human Design Sparks, which provide affordance-rich construction demonstrations; World Feedback, which grounds predicted actions in visual and physical consequences; and Synthetic Experience, which scales learning beyond existing object designs. Brick-Composer improves brick selection accuracy by over three times, substantially reduces pose estimation errors, and raises strict step-level assembly success from less than 1% to around 15%. After training, a Qwen-3-8B can correctly compose up to 42% of the steps for a complete object, suggesting that MLLMs can acquire assembly capabilities through targeted, physically grounded learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BC-Bench, the first benchmark for MLLM evaluation on sequential brick assembly (brick selection and pose estimation subtasks), and proposes Brick-Composer, a training framework that combines Human Design Sparks, World Feedback, and Synthetic Experience to fine-tune models such as Qwen-3-8B. It reports concrete gains: brick selection accuracy improved by over 3x, reduced pose estimation errors, strict step-level success raised from <1% to ~15%, and up to 42% of steps correctly composed for complete objects.
Significance. If the empirical results hold under real-world conditions, the work provides the first systematic demonstration that MLLMs can acquire grounded assembly skills via the three proposed signals, establishing a reproducible benchmark and training recipe that could extend to other sequential physical construction tasks.
major comments (2)
- [Abstract, §4] Abstract and §4 (World Feedback, Synthetic Experience): the central performance claims (3x selection accuracy, step success from <1% to ~15%) rest on simulator-generated signals, yet no section validates that the simulator reproduces real brick contact forces, friction coefficients, or stability under gravity at the precision required for pose estimation transfer; without this, the BC-Bench numbers may reflect simulator-specific overfitting rather than transferable skill.
- [§5] §5 (Experiments): the reported improvements lack details on data splits, statistical significance tests, number of runs, and whether post-hoc hyperparameter choices were made after seeing test results; these omissions make it impossible to assess whether the gains are robust or could be artifacts of the experimental protocol.
minor comments (2)
- [Abstract, §3] Notation for the two subtasks (selection vs. pose) is introduced in the abstract but not consistently referenced with equation numbers in the methods; adding explicit definitions would improve clarity.
- [Figures] Figure captions for BC-Bench examples should explicitly state the number of candidate bricks and the exact success criteria used for the 15% and 42% figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and note the planned revisions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (World Feedback, Synthetic Experience): the central performance claims (3x selection accuracy, step success from <1% to ~15%) rest on simulator-generated signals, yet no section validates that the simulator reproduces real brick contact forces, friction coefficients, or stability under gravity at the precision required for pose estimation transfer; without this, the BC-Bench numbers may reflect simulator-specific overfitting rather than transferable skill.
Authors: We agree that all experiments, including BC-Bench and the three training signals, are performed in simulation and that the manuscript provides no direct validation of simulator physics (contact forces, friction, gravity stability) against real bricks. The work positions itself as an initial study of MLLM assembly capabilities within a reproducible simulated environment rather than a claim of immediate real-world transfer. We will revise the abstract and §4 to state this scope explicitly and add a limitations paragraph discussing simulator assumptions and the sim-to-real gap. revision: partial
-
Referee: [§5] §5 (Experiments): the reported improvements lack details on data splits, statistical significance tests, number of runs, and whether post-hoc hyperparameter choices were made after seeing test results; these omissions make it impossible to assess whether the gains are robust or could be artifacts of the experimental protocol.
Authors: We acknowledge that the current manuscript omits these experimental details. The revised version will add a dedicated experimental protocol subsection specifying the train/validation/test splits, the number of independent runs, the statistical significance tests performed, and confirmation that hyperparameter selection preceded test-set evaluation. revision: yes
Circularity Check
No circularity: empirical results from training signals on benchmark
full rationale
The paper formulates brick assembly as a sequential decision problem and introduces BC-Bench plus the Brick-Composer framework with three training signals (Human Design Sparks, World Feedback, Synthetic Experience). All reported gains (3x selection accuracy, step success from <1% to ~15%) are presented as direct experimental outcomes after applying these signals to MLLMs such as Qwen-3-8B. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims rest on observable benchmark performance rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Brick-Composer training framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Spatialbot: Precise spatial understanding with vision language models,
SpatialBot: Precise spatial understand- ing with vision language models.arXiv preprint arXiv:2406.13642. Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. SpatialVLM: Endowing vision-language models with spatial reasoning capa- bilities. InProceedings of the IEEE/CVF Conference...
-
[2]
InAdvances in Neural Information Processing Systems
3D-LLM: Injecting the 3D world into large language models. InAdvances in Neural Information Processing Systems. Haochen Huang, Jiahuan Pei, Mohammad Aliannejadi, Xin Sun, Moonisa Ahsan, Chuang Yu, Zhaochun Ren, Pablo César, and Junxiao Wang. 2025. LEGO co-builder: Exploring fine-grained vision-language modeling for multimodal LEGO assembly assistants. arX...
-
[3]
Official Qwen blog post. Accessed: 2026-05-26. Ishika Singh, Ankit Goyal, Stan Birchfield, Dieter Fox, Animesh Garg, and Valts Blukis. 2025. Og-vla: 3d- aware vision language action model via orthographic image generation.arXiv preprint arXiv:2506.01196. Stefan Stevši´c, Sammy Christen, and Otmar Hilliges
-
[4]
Learning to assemble: Estimating 6d poses for robotic object-object manipulation.IEEE Robotics and Automation Letters, 5(2):1159–1166. Kexian Tang, Junyao Gao, Yanhong Zeng, Haodong Duan, Yanan Sun, Zhening Xing, Wenran Liu, Kaifeng Lyu, and Kai Chen. 2025. Lego-puzzles: How good are mllms at multi-step spatial reasoning? arXiv preprint arXiv:2503.19990. ...
-
[5]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Springer. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, and 56 others. 2025. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and effi- cie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
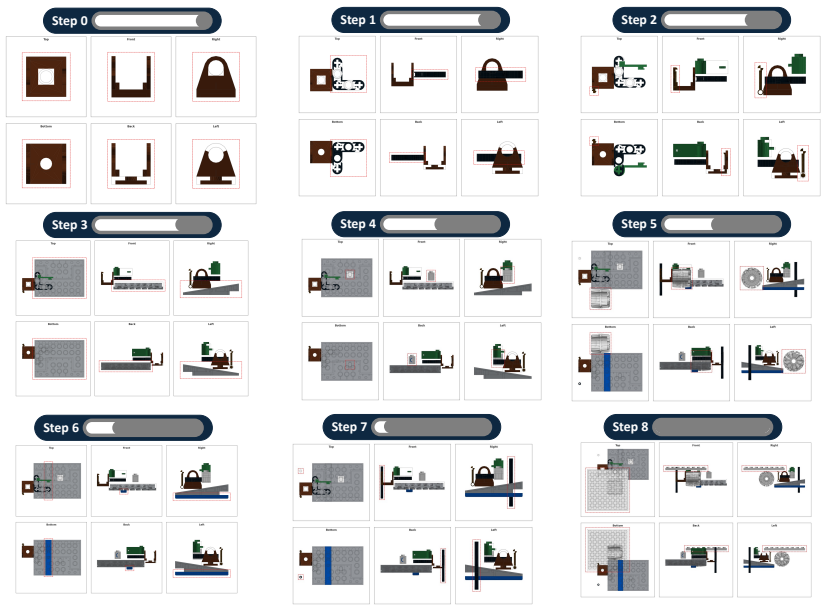
[6]
Original views: 6 orthogonal views (Top, Front, Right, Bottom, Back, Left) of the current LEGO assembly BEFORE the assembly step
-
[7]
Target views: the same 6 orthogonal views AFTER the brick is placed, with the newly added brick highlighted with a red dashed bounding box
-
[8]
conversations
Remaining brick catalog: a grid showing every brick that still needs to be placed (including the current step’s brick), with part filenames (e.g. 3023.dat) labeled above each tile. Y our task:Compare the Original and Target views to identify which brick was placed, then locate it in the catalog. Output format 2014 one line per brick: {part-filename}, row ...
2014
-
[9]
Original views: a composite of 6 orthogonal views (Top, Front, Right, Bottom, Back, Left) of the current LEGO assembly BEFORE the assembly step
-
[10]
The newly added brick is highlighted with a red dashed bounding box
Target views: the same 6 orthogonal views of the assembly AFTER the brick is placed. The newly added brick is highlighted with a red dashed bounding box
-
[11]
Part render(s): a rendered image of the brick (or bricks) to be placed, with the LDraw local coordinate frame annotated (red=+X, green=+Y , blue dot=+Z)
-
[12]
Brick 1:
Current-state axes render: a 7-view composite (6 orthogonal + 1 isometric) of the assembly BEFORE this step, with LDU coordinate tick labels on every view and an isometric 3D projection in the right column. Use this to read off exact LDU coordinates 13 Figure 5: Examples of our rendered part-demo data in BC-Bench, we visualize the part within its own coor...
2014
-
[13]
Original views: a composite of 6 orthogonal views (Back, Bottom, Left, Right, Up, Front) of the current LEGO assembly BEFORE the assembly step
-
[14]
The newly added brick is highlighted with a bounding box
Target views: the same 6 orthogonal views of the assembly AFTER the brick is placed. The newly added brick is highlighted with a bounding box
-
[15]
Part render(s): a rendered image of the brick (or bricks) to be placed, with the LDraw local coordinate frame annotated on the image
-
[16]
Previous assembly render (omitted for the very first step): a composite rendering of the entire assembly from the immediately preceding step, giving you spatial context about the accumulated model
-
[17]
Brick 1:
Erroneous prediction render (when available): a rendering in which the incorrectly placed brick is shown in red, produced from a previous model prediction. Accompanying text specifies the wrong predicted rotation matrix and scalar error magnitudes (Euclidean translation error and geodesic rotation error) only — no absolute translation values or per-axis o...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.