When New Generators Arrive: Lifelong Machine-Generated Text Attribution via Ridge Feature Transfer
Pith reviewed 2026-06-28 01:36 UTC · model grok-4.3
The pith
RidgeFT adds new generators to machine-generated text attribution via replay-free ridge updates on a frozen encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
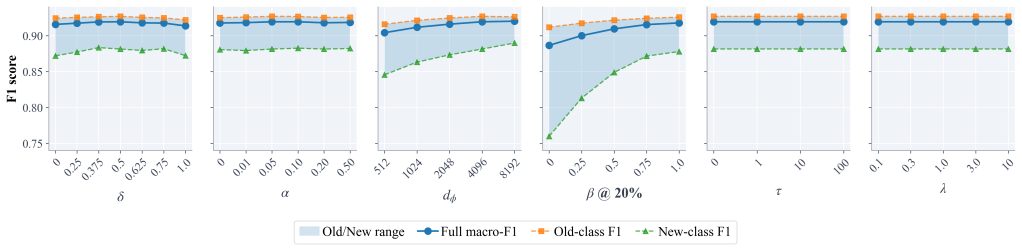
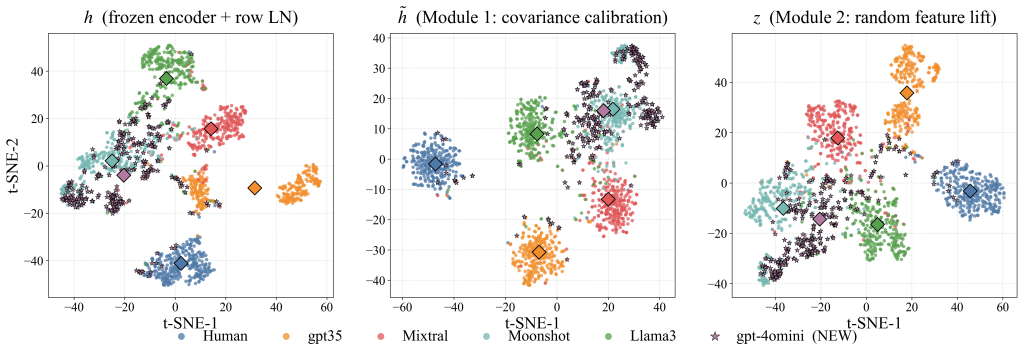
RidgeFT trains a task-aware encoder on the initial generator set, stores compact class-wise sufficient statistics when each generator class is first observed, freezes the encoder, suppresses generator-irrelevant variation through covariance calibration, improves representation capacity with fixed random features, and updates new classes through closed-form ridge regression based on class-level sufficient statistics.
What carries the argument
Closed-form ridge regression updates on class-wise sufficient statistics from a frozen task-aware encoder, preceded by covariance calibration and fixed random feature expansion.
If this is right
- New generator classes can be incorporated without storing or replaying any previous text examples.
- Both old-class retention and new-class adaptation improve simultaneously compared with prior lifelong methods.
- The same analytic procedure works across different text domains, encoder backbones, and incremental learning protocols.
- Only compact class-level statistics need to be stored after the initial training phase.
Where Pith is reading between the lines
- The same sufficient-statistic plus ridge update pattern could be tested on other incremental text classification tasks such as topic or author attribution.
- Memory cost scales with the number of classes rather than the number of examples, which may become advantageous as the number of generators grows.
- If the initial encoder captures sufficiently general features, the method could be applied to generators that appear long after the initial training period.
- Direct comparison of wall-clock update time versus full retraining would quantify the efficiency gain in a production setting.
Load-bearing premise
An encoder trained only on the initial generator set remains sufficiently discriminative when frozen so that class-wise sufficient statistics plus ridge updates can handle new generators without major loss of power or need for replay.
What would settle it
An evaluation in which new generators are added sequentially and RidgeFT shows either a large drop in old-class accuracy or lower overall macro-F1 than a full retraining baseline on the same data.
Figures


read the original abstract
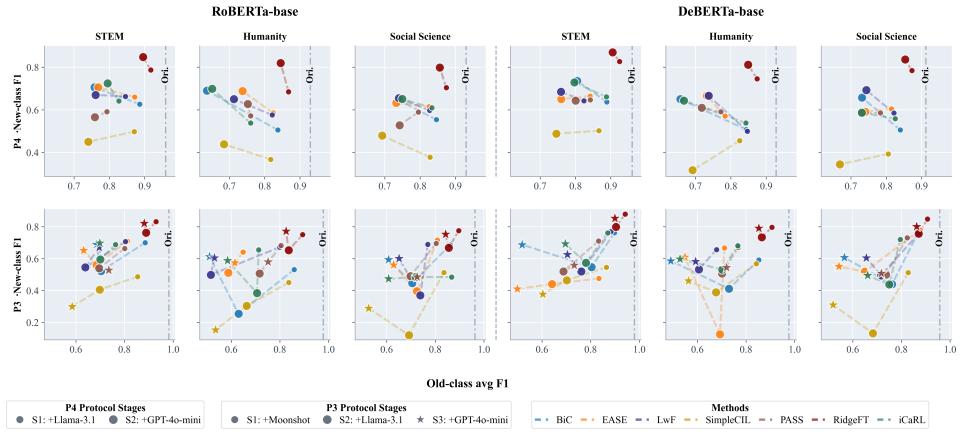
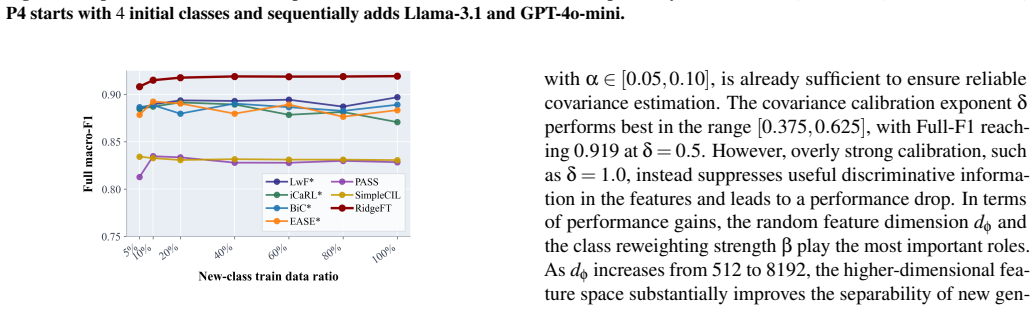
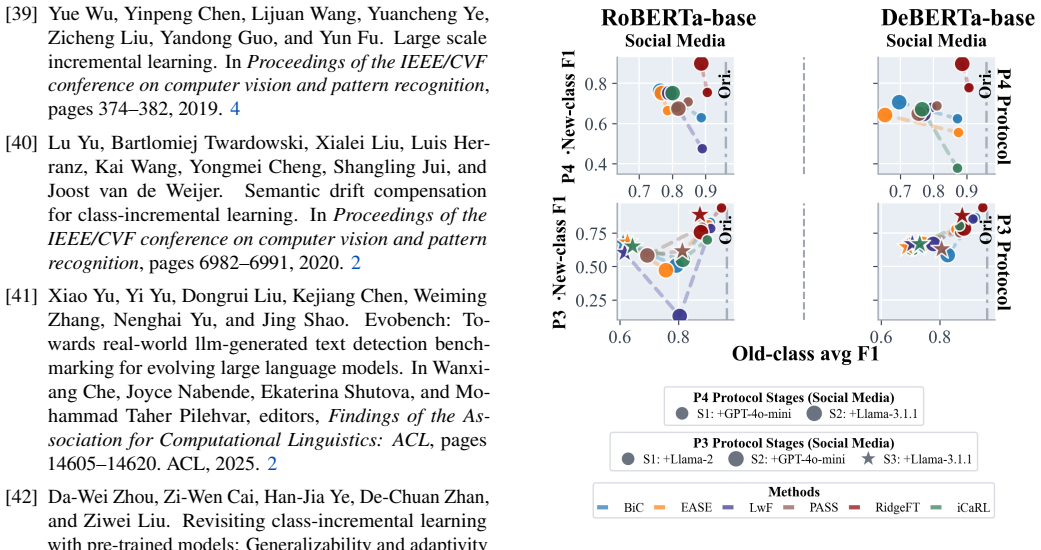
Machine-generated text (MGT) attribution aims to identify the specific generator responsible for a given text, thereby providing fine-grained evidence for model accountability and misuse investigation. As new large language models continue to emerge, attribution models must continuously incorporate new generators while preserving their ability to recognize previously seen ones. Prior works have shown that this lifelong MGT attribution setting is challenging, and existing methods often struggle to achieve a stable balance between adapting to new classes and retaining old ones. To address this issue, we propose RidgeFT, a lightweight analytic update framework that does not rely on exemplar replay. RidgeFT trains a task-aware encoder on the initial generator set, stores compact class-wise sufficient statistics when each generator class is first observed, and then freezes the encoder for replay-free closed-form updates. It then suppresses generator-irrelevant variation through covariance calibration, improves representation capacity with fixed random features, and updates new classes through closed-form ridge regression based on class-level sufficient statistics. Across multi-topic evaluations with varying initial generator setups, RidgeFT consistently outperforms baselines. It achieves the best macro-F1 across domains, backbones, and incremental protocols, while also improving both old-class retention and new-class adaptation. These results suggest that feature-stable analytic updates provide a simple yet effective approach to lifelong MGT attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RidgeFT, a replay-free framework for lifelong machine-generated text attribution. An encoder is trained on the initial generator set and frozen. Class-wise sufficient statistics (means and covariances) are stored upon first observation of each generator. For new generators, closed-form ridge regression updates are performed after covariance calibration and augmentation with fixed random features. The paper reports that this approach consistently achieves the highest macro-F1 scores across domains, backbones, and incremental protocols while balancing retention of old classes and adaptation to new ones.
Significance. If the reported results are robust, the work offers a computationally efficient alternative to replay-based or fine-tuning methods for continual attribution, which is relevant as new LLMs proliferate. The analytic nature of the updates and avoidance of exemplar storage are notable strengths, providing a parameter-efficient way to handle incremental classes without catastrophic forgetting.
major comments (2)
- [Method] The core assumption that the feature space learned from the initial generator set remains discriminative for subsequently introduced generators is not validated. The ridge update is derived under the premise of linear separability in this fixed space, but no experiment or analysis demonstrates that stylistic or topical shifts from new LLMs lie within the span of the initial encoder's representation. This assumption is load-bearing for the central claim of effective closed-form adaptation.
- [Experiments] Table reporting macro-F1 results across incremental protocols: while outperformance is claimed, there is no ablation isolating the contribution of covariance calibration versus random features, nor any diagnostic measuring how much new-generator variance falls outside the initial encoder span. This weakens the ability to attribute gains specifically to the analytic update mechanism.
minor comments (2)
- [Abstract] The abstract asserts quantitative superiority (best macro-F1, improved retention and adaptation) without supplying any numerical values, dataset sizes, or protocol details, reducing its standalone informativeness.
- [Method] Notation for the class-wise sufficient statistics and the exact closed-form ridge solution could be presented with numbered equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of validating the core feature-space assumption and providing targeted ablations. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method] The core assumption that the feature space learned from the initial generator set remains discriminative for subsequently introduced generators is not validated. The ridge update is derived under the premise of linear separability in this fixed space, but no experiment or analysis demonstrates that stylistic or topical shifts from new LLMs lie within the span of the initial encoder's representation. This assumption is load-bearing for the central claim of effective closed-form adaptation.
Authors: We agree that the manuscript does not contain a direct diagnostic validating that new-generator features remain within the discriminative span of the initial encoder. While the reported results across domains, backbones, and protocols show that the closed-form updates yield strong macro-F1 and retention-adaptation balance, this does not substitute for an explicit test (e.g., variance explained by the initial principal components or alignment of new class statistics). In revision we will add such an analysis to quantify how much new-generator variation projects onto the frozen feature space. revision: yes
-
Referee: [Experiments] Table reporting macro-F1 results across incremental protocols: while outperformance is claimed, there is no ablation isolating the contribution of covariance calibration versus random features, nor any diagnostic measuring how much new-generator variance falls outside the initial encoder span. This weakens the ability to attribute gains specifically to the analytic update mechanism.
Authors: We concur that the current experiments do not isolate the individual contributions of covariance calibration and random-feature augmentation, nor do they include the out-of-span variance diagnostic. To address this, the revised manuscript will add controlled ablations that remove or vary each component while keeping the ridge update fixed, together with the diagnostic requested in the method comment. These additions will allow clearer attribution of performance to the analytic mechanism. revision: yes
Circularity Check
No circularity; method is an empirical proposal using standard analytic updates
full rationale
The paper proposes RidgeFT as a practical method: train encoder on initial generators, freeze it, store class-wise sufficient statistics (means/covariances), then apply closed-form ridge regression for new classes after covariance calibration and random features. No derivation chain, first-principles claim, or prediction is shown to reduce by construction to fitted inputs or self-citations. Performance claims rest on multi-domain empirical evaluations rather than any self-referential definition or load-bearing prior result from the same authors. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lucas Caccia, Rahaf Aljundi, Nader Asadi, Tinne Tuytelaars, Joelle Pineau, and Eugene Belilovsky. New insights on reducing abrupt representation change in online continual learning.arXiv preprint arXiv:2104.05025, 2021. 2
-
[2]
Openturingbench: An open-model-based benchmark and framework for machine-generated text detection and attribution
Lucio La Cava and Andrea Tagarelli. Openturingbench: An open-model-based benchmark and framework for machine-generated text detection and attribution. In Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 26655–26671. Association for Computational Linguistics, 2025. 1
2025
-
[3]
Divscore: Zero-shot detection of llm-generated text in specialized domains
Zhihui Chen, Kai He, Yucheng Huang, Yunxiao Zhu, and Mengling Feng. Divscore: Zero-shot detection of llm-generated text in specialized domains. In Chris- tos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Conference on Empiri- cal Methods in Natural Language Processing (EMNLP), pages 19231–19253. ACL, 2025. 2
2025
-
[4]
Hongchao Fang, Yixin Liu, Jiangshu Du, Can Qin, Ran Xu, Feng Liu, Lichao Sun, Dongwon Lee, Lifu Huang, and Wenpeng Yin. Could ai trace and explain the ori- gins of ai-generated images and text?arXiv preprint arXiv:2504.04279, 2025. 2
-
[5]
Catastrophic forgetting in connection- ist networks.Trends in cognitive sciences, 3(4):128–135,
Robert M French. Catastrophic forgetting in connection- ist networks.Trends in cognitive sciences, 3(4):128–135,
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Learning to rewrite: Generalized llm- generated text detection
Wei Hao, Ran Li, Weiliang Zhao, Junfeng Yang, and Chengzhi Mao. Learning to rewrite: Generalized llm- generated text detection. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Annual Meeting of the Association for Computational Linguistics (ACL), pages 6421–6434. ACL, 2025. 2
2025
-
[8]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. Deber- tav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing.arXiv preprint arXiv:2111.09543, 2021. 4
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Mgtbench: Benchmarking machine- generated text detection
Xinlei He, Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. Mgtbench: Benchmarking machine- generated text detection. In Bo Luo, Xiaojing Liao, Jun Xu, Engin Kirda, and David Lie, editors,ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 2251–2265. ACM, 2024. 1, 2
2024
-
[10]
Authorship attribution in the era of llms: Problems, methodologies, and challenges.ACM SIGKDD Explorations Newsletter, 26(2):21–43, 2025
Baixiang Huang, Canyu Chen, and Kai Shu. Authorship attribution in the era of llms: Problems, methodologies, and challenges.ACM SIGKDD Explorations Newsletter, 26(2):21–43, 2025. 2
2025
-
[11]
Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal
Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal. In Annual Meeting of the Association for Computational Linguistics (ACL), pages 1416–1428, 2024. 2
2024
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt- 4o system card.arXiv preprint arXiv:2410.21276, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
M-rangedetector: Enhancing gen- eralization in machine-generated text detection through multi-range attention masks
Kaijie Jiao, Quan Wang, Licheng Zhang, Zikang Guo, and Zhendong Mao. M-rangedetector: Enhancing gen- eralization in machine-generated text detection through multi-range attention masks. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Com- putational Linguistics: ACL, pages 8971–8983. ACL,
-
[15]
Tharindu Kumarage, Garima Agrawal, Paras Sheth, Raha Moraffah, Aman Chadha, Joshua Garland, and Huan Liu. A survey of ai-generated text forensic sys- tems: Detection, attribution, and characterization.arXiv preprint arXiv:2403.01152, 2024. 1
-
[16]
Authorship Attribution in Multilingual Machine-Generated Texts
Lucio La Cava, Dominik Macko, Róbert Móro, Ivan Srba, and Andrea Tagarelli. Authorship attribution in multilingual machine-generated texts.arXiv preprint arXiv:2508.01656, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Prde- tect: Perturbation-robust llm-generated text detection based on syntax tree
Xiang Li, Zhiyi Yin, Hexiang Tan, Shaoling Jing, Du Su, Yi Cheng, Huawei Shen, and Fei Sun. Prde- tect: Perturbation-robust llm-generated text detection based on syntax tree. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL, pages 8290–8301. ACL, 2025. 2
2025
-
[18]
Iron sharpens iron: Defending 8 against attacks in machine-generated text detection with adversarial training
Yuanfan Li, Zhaohan Zhang, Chengzhengxu Li, Chao Shen, and Xiaoming Liu. Iron sharpens iron: Defending 8 against attacks in machine-generated text detection with adversarial training. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, ed- itors,Annual Meeting of the Association for Computa- tional Linguistics (ACL), pages 3091...
2025
-
[19]
Learning without forget- ting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forget- ting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017. 4
2017
-
[20]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019. 4
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[21]
On the gen- eralization and adaptation ability of machine-generated text detectors in academic writing
Yule Liu, Zhiyuan Zhong, Yifan Liao, Zhen Sun, Jingyi Zheng, Jiaheng Wei, Qingyuan Gong, Fenghua Tong, Yang Chen, Yang Zhang, and Xinlei He. On the gen- eralization and adaptation ability of machine-generated text detectors in academic writing. InACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pages 5674–5685. ACM, 2025. 1, 2, 4, 11
2025
-
[22]
Multisocial: Multilingual benchmark of machine- generated text detection of social-media texts
Dominik Macko, Jakub Kopal, Róbert Móro, and Ivan Srba. Multisocial: Multilingual benchmark of machine- generated text detection of social-media texts. In Wanx- iang Che, Joyce Nabende, Ekaterina Shutova, and Mo- hammad Taher Pilehvar, editors,Annual Meeting of the Association for Computational Linguistics (ACL), pages 727–752. ACL, 2025. 2
2025
-
[23]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and moti- vation, volume 24, pages 109–165. Elsevier, 1989. 2
1989
-
[24]
Moonshot AI
Moonshot AI. Moonshot AI. https://www.moonshot. ai/, 2026. Accessed: 2026-05-15. 4
2026
-
[25]
Leveraging explainable ai for llm text attribution: Differentiating human-written and multiple llm-generated text.Information, 16(9):767, 2025
Ayat A Najjar, Huthaifa I Ashqar, Omar Darwish, and Eman Hammad. Leveraging explainable ai for llm text attribution: Differentiating human-written and multiple llm-generated text.Information, 16(9):767, 2025. 2
2025
-
[26]
Openclaw docs
OpenClaw. Openclaw docs. https://docs.openclaw. ai/, 2026. Accessed: 2026-05-14. 1
2026
-
[27]
Artificial intelligence (ai) tools for academic research.Library Hi Tech News, 41(8):18–20,
Adetoun A Oyelude. Artificial intelligence (ai) tools for academic research.Library Hi Tech News, 41(8):18–20,
-
[28]
Stress-testing machine generated text detection: Shifting language models writing style to fool detectors
Andrea Pedrotti, Michele Papucci, Cristiano Ciaccio, Alessio Miaschi, Giovanni Puccetti, Felice Dell’Orletta, and Andrea Esuli. Stress-testing machine generated text detection: Shifting language models writing style to fool detectors. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Find- ings of the Association for ...
2025
-
[29]
Random features for large-scale kernel machines.Advances in neural infor- mation processing systems, 20, 2007
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in neural infor- mation processing systems, 20, 2007. 3
2007
-
[30]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017. 4
2001
-
[31]
Almost ai, almost human: The challenge of detecting ai-polished writing
Shoumik Saha and Soheil Feizi. Almost ai, almost human: The challenge of detecting ai-polished writing. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL, pages 25414–25431. ACL, 2025. 2
2025
-
[32]
Areg Mikael Sarvazyan, José Ángel González, Marc Franco-Salvador, Francisco Rangel, Berta Chulvi, and Paolo Rosso. Overview of autextification at iberlef 2023: Detection and attribution of machine-generated text in multiple domains.arXiv preprint arXiv:2309.11285,
-
[33]
Haco-det: A study to- wards fine-grained machine-generated text detection un- der human-ai coauthoring
Zhixiong Su, Yichen Wang, Herun Wan, Zhaohan Zhang, and Minnan Luo. Haco-det: A study to- wards fine-grained machine-generated text detection un- der human-ai coauthoring. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Annual Meeting of the Association for Computational Linguistics (ACL), pages 22015–22036. ACL, 2025. 2
2025
-
[34]
Are we in the ai-generated text world already? quantify- ing and monitoring AIGT on social media
Zhen Sun, Zongmin Zhang, Xinyue Shen, Ziyi Zhang, Yule Liu, Michael Backes, Yang Zhang, and Xinlei He. Are we in the ai-generated text world already? quantify- ing and monitoring AIGT on social media. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar, editors,Annual Meeting of the As- sociation for Computational Linguistics ...
2025
-
[35]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Bap- tiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Continual learning: Applications and the road forward.arXiv preprint arXiv:2311.11908,
Eli Verwimp, Rahaf Aljundi, Shai Ben-David, Matthias Bethge, Andrea Cossu, Alexander Gepperth, Tyler L Hayes, Eyke Hüllermeier, Christopher Kanan, Dhiree- sha Kudithipudi, et al. Continual learning: Applications and the road forward.arXiv preprint arXiv:2311.11908,
-
[38]
Chao, and Derek Fai Wong
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia S. Chao, and Derek Fai Wong. A survey on llm- generated text detection: Necessity, methods, and future directions.Comput. Linguistics, 51(1):275–338, 2025. 1, 2 9
2025
-
[39]
Large scale incremental learning
Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large scale incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 374–382, 2019. 4
2019
-
[40]
Semantic drift compensation for class-incremental learning
Lu Yu, Bartlomiej Twardowski, Xialei Liu, Luis Her- ranz, Kai Wang, Yongmei Cheng, Shangling Jui, and Joost van de Weijer. Semantic drift compensation for class-incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6982–6991, 2020. 2
2020
-
[41]
Evobench: To- wards real-world llm-generated text detection bench- marking for evolving large language models
Xiao Yu, Yi Yu, Dongrui Liu, Kejiang Chen, Weiming Zhang, Nenghai Yu, and Jing Shao. Evobench: To- wards real-world llm-generated text detection bench- marking for evolving large language models. In Wanxi- ang Che, Joyce Nabende, Ekaterina Shutova, and Mo- hammad Taher Pilehvar, editors,Findings of the As- sociation for Computational Linguistics: ACL, pag...
2025
-
[42]
Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 133(3):1012–1032, 2025
Da-Wei Zhou, Zi-Wen Cai, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 133(3):1012–1032, 2025. 4
2025
-
[43]
Expandable subspace ensemble for pre- trained model-based class-incremental learning
Da-Wei Zhou, Hai-Long Sun, Han-Jia Ye, and De- Chuan Zhan. Expandable subspace ensemble for pre- trained model-based class-incremental learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23554–23564,
-
[44]
Fei Zhu, Xu-Yao Zhang, Chuang Wang, Fei Yin, and Cheng-Lin Liu. Prototype augmentation and self- supervision for incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5871–5880, 2021. 4 A Sufficiency Analysis of Frozen Representa- tions SinceRidgeFTfreezes the task-tuned encoder during the increme...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.