When Surface Form Changes Moderation Decisions: A Paired Study of Code-Mixed Workflow Instability
Pith reviewed 2026-06-28 00:36 UTC · model grok-4.3
The pith
Code-mixed inputs flip moderation decisions at a 0.265 rate under English-tuned thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
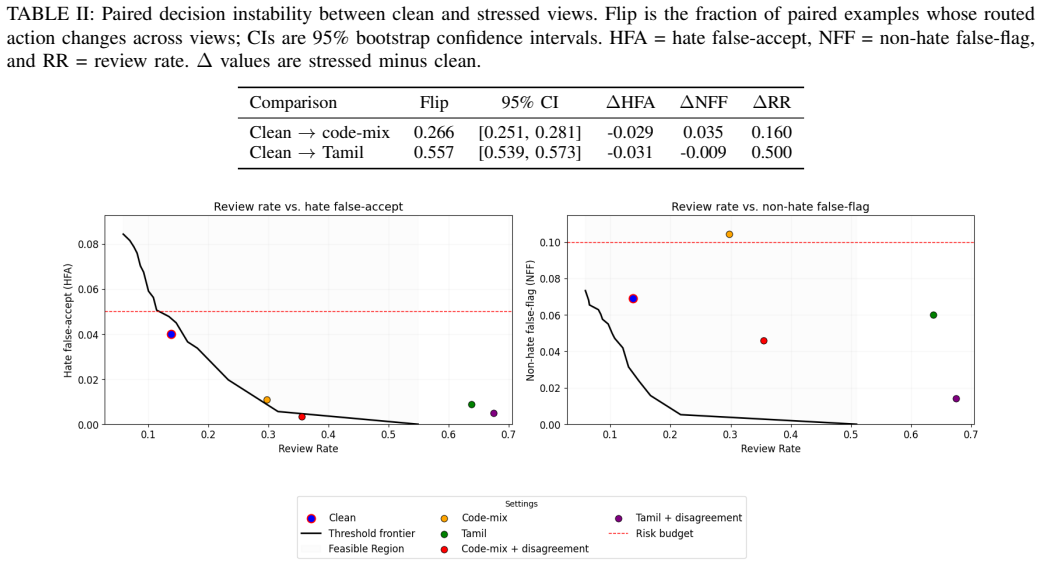
Under thresholds tuned on clean English development data, code-mixed inputs produce substantial action instability, with a paired clean- to-code-mix decision flip rate of 0.265. The main workflow effects are increased review burden and increased false-flagging of non-hateful content: review rate rises from 0.138 to 0.297 and non-hate false-flag rate rises from 0.069 to 0.104. Tamil-only inputs show stronger degradation overall, suggesting a broader language-coverage limitation rather than the same code-mixed instability pattern. A simple disagreement-based deferral rule reduces automatic errors on stressed inputs, but only by increasing review load. These results show that workflow-level eva
What carries the argument
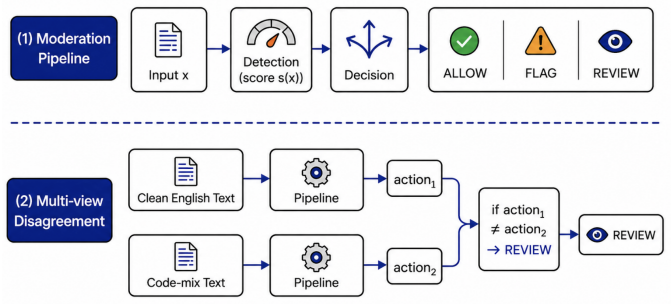
The paired evaluation setting that holds underlying content fixed while varying surface form between clean English and Tamil-English code-mix.
If this is right
- Review rate rises from 0.138 to 0.297 on code-mixed inputs.
- Non-hate false-flag rate rises from 0.069 to 0.104 on code-mixed inputs.
- Tamil-only inputs exhibit stronger overall degradation than code-mixed inputs.
- A disagreement-based deferral rule cuts automatic errors on stressed inputs but raises review load.
- Workflow-level metrics expose failures invisible to standard classification accuracy.
Where Pith is reading between the lines
- Systems may require separate threshold sets for each surface form to keep action distributions stable.
- Code-mixing could serve as an input perturbation that systematically shifts moderation outcomes without changing semantic intent.
- Extending the paired design to other language pairs would test whether the instability pattern generalizes beyond Tamil-English.
- The observed increase in review burden implies higher operational cost for platforms serving multilingual users.
Load-bearing premise
The paired clean English and code-mixed versions are assumed to represent identical underlying content and intent, with no additional variables introduced by the translation or mixing process that independently affect model decisions.
What would settle it
Re-running the full paired experiment after retuning thresholds on a code-mixed development set and checking whether the decision-flip rate falls below 0.1.
Figures

read the original abstract
Hate moderation is often evaluated as classification on clean English inputs, but deployed systems must route content to actions such as ALLOW, FLAG, or REVIEW. We study how this workflow changes under code-mixed inputs using a paired evaluation setting where the same underlying content is expressed as clean English and Tamil-English code-mix. Under thresholds tuned on clean English development data, code-mixed inputs produce substantial action instability, with a paired clean- to-code-mix decision flip rate of 0.265. The main workflow effects are increased review burden and increased false-flagging of non-hateful content: review rate rises from 0.138 to 0.297 and non-hate false-flag rate rises from 0.069 to 0.104. Tamil-only inputs show stronger degradation overall, suggesting a broader language-coverage limitation rather than the same code-mixed instability pattern. A simple disagreement-based deferral rule reduces automatic errors on stressed inputs, but only by increasing review load. These results show that workflow-level evaluation reveals moderation failures that standard classification summaries can miss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a paired empirical study of hate moderation workflows, comparing decisions on clean English inputs versus Tamil-English code-mixed versions of the same underlying content. Under thresholds tuned on clean English development data, it reports a clean-to-code-mix decision flip rate of 0.265, with review rates rising from 0.138 to 0.297 and non-hate false-flag rates rising from 0.069 to 0.104. Tamil-only inputs exhibit stronger overall degradation. A disagreement-based deferral rule is shown to reduce automatic errors on stressed inputs at the cost of higher review load. The central argument is that workflow-level evaluation reveals moderation failures missed by standard classification summaries.
Significance. If the paired equivalence holds and the measurements prove reliable, the work would usefully demonstrate that surface-form variation can induce substantial workflow instability (review burden and false flagging) even when classification accuracy appears acceptable on clean English. The distinction between code-mix effects and full-language degradation is a constructive observation. The deferral experiment provides a concrete, if partial, mitigation. These points would matter for practitioners deploying moderation in multilingual settings.
major comments (2)
- [Abstract] Abstract and evaluation description: the abstract states specific numeric outcomes (flip rate 0.265, review-rate increase 0.138→0.297, non-hate false-flag rise 0.069→0.104) but supplies no information on dataset size, model architecture, statistical tests, or how pairs were constructed, leaving the central claim without visible supporting derivation or controls.
- [Paired evaluation setting] Paired evaluation setting: the claim that code-mixed inputs produce the observed instability requires the paired clean-English and Tamil-English versions to differ only in surface form while preserving identical content and intent. No validation of this equivalence (human ratings, semantic similarity, or lexical-shift controls) is reported; without it the attribution to code-mixing rather than generation artifacts remains untested and load-bearing for the 0.265 flip-rate result.
minor comments (1)
- The manuscript would benefit from explicit reporting of sample sizes, confidence intervals, and any inter-annotator agreement for the underlying labels.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the abstract states specific numeric outcomes (flip rate 0.265, review-rate increase 0.138→0.297, non-hate false-flag rise 0.069→0.104) but supplies no information on dataset size, model architecture, statistical tests, or how pairs were constructed, leaving the central claim without visible supporting derivation or controls.
Authors: We agree that the abstract would be more informative with additional methodological context. In the revised version we will expand the abstract to report the dataset size, briefly describe the model architecture and threshold-tuning procedure, note the statistical tests performed, and indicate how the paired inputs were generated. Full details remain in the methods section, but the abstract will become more self-contained. revision: yes
-
Referee: [Paired evaluation setting] Paired evaluation setting: the claim that code-mixed inputs produce the observed instability requires the paired clean-English and Tamil-English versions to differ only in surface form while preserving identical content and intent. No validation of this equivalence (human ratings, semantic similarity, or lexical-shift controls) is reported; without it the attribution to code-mixing rather than generation artifacts remains untested and load-bearing for the 0.265 flip-rate result.
Authors: We acknowledge that explicit validation of content equivalence is necessary to attribute instability specifically to surface-form change. The pairs were produced via a controlled back-translation pipeline intended to preserve semantics while introducing Tamil-English code-mixing. We did not include human equivalence ratings or similarity metrics in the original submission. We will add a dedicated subsection on pair construction together with human-rated equivalence scores on a random sample of pairs and lexical-shift statistics to address this concern. revision: yes
Circularity Check
No circularity: purely empirical paired measurement with no derivations or self-referential fits
full rationale
The paper performs a direct empirical comparison of moderation workflow outcomes on paired clean-English vs. code-mixed inputs using fixed thresholds tuned on English dev data. All reported quantities (0.265 flip rate, review-rate shift from 0.138 to 0.297, false-flag shift from 0.069 to 0.104) are observed counts from the paired evaluation; none are derived from equations, fitted parameters renamed as predictions, or self-citation chains. The central assumption that pairs preserve identical content is an untested modeling choice but does not create definitional circularity or reduce any result to its own inputs by construction. No load-bearing uniqueness theorems, ansatzes, or renamings appear. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automated hate speech detection and the problem of offensive language,
T. Davidson, D. Warmsley, M. Macy, and I. Weber, “Automated hate speech detection and the problem of offensive language,” in Proceedings of the 11th International AAAI Conference on Web and Social Media (ICWSM 2017), 2017, pp. 512–515. [Online]. Available: https://github.com/t-davidson/hate-speech-and-offensive-language
2017
-
[2]
Large scale crowdsourcing and characterization of twitter abusive behavior,
A.-M. Founta, C. Djouvas, D. Chatzakou, I. Leontiadis, J. Blackburn, G. Stringhini, A. Vakali, M. Sirivianos, and N. Kourtellis, “Large scale crowdsourcing and characterization of twitter abusive behavior,” inProceedings of the 12th International AAAI Conference on Web and Social Media (ICWSM 2018), 2018, pp. 491–500. [Online]. Available: https://dblp.org...
2018
-
[3]
Wokegpt: Improving counterspeech generation against online hate speech by intel- ligently augmenting datasets using a novel metric,
S. M. Halim, S. Irtiza, Y . Hu, L. Khan, and B. Thuraisingham, “Wokegpt: Improving counterspeech generation against online hate speech by intel- ligently augmenting datasets using a novel metric,” in2023 International Joint Conference on Neural Networks (IJCNN). IEEE, 2023, pp. 1–10
2023
-
[4]
Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries,
Y . Jin, M. Chandra, G. Verma, Y . Hu, M. De Choudhury, and S. Kumar, “Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries,” inProceedings of the ACM Web Con- ference 2024. Association for Computing Machinery, 2024, pp. 2627– 2638
2024
-
[5]
CodeMixBench: Evaluating code-mixing capabilities of LLMs across 18 languages,
Y . Yang and Y . Chai, “CodeMixBench: Evaluating code-mixing capabilities of LLMs across 18 languages,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 2139–2169. [Online]. Av...
2025
-
[6]
G. I. Winata, D. Anugraha, P. A. Irawan, A. Das, H. Yoo, P. Dashore, S. Kulkarni, R. Zhang, H. Sakajo, F. Hudiet al., “Can large language models understand, reason about, and generate code-switched text?” arXiv preprint arXiv:2601.07153, 2026
-
[7]
Z. Safdari Fesaghandis and S. K. Maity, “Multilingual hate speech detection and counterspeech generation: A comprehensive survey and practical guide,”arXiv preprint arXiv:2603.19279, 2026. [Online]. Available: https://arxiv.org/abs/2603.19279
-
[8]
A survey on multi-lingual offensive language detection,
K. Mnassri, R. Farahbakhsh, R. Chalehchaleh, P. Rajapaksha, A. R. Jafari, G. Li, and N. Crespi, “A survey on multi-lingual offensive language detection,”PeerJ Computer Science, vol. 10, p. e1934, 2024. [Online]. Available: https://pmc.ncbi.nlm.nih.gov/articles/ PMC11042037/
2024
-
[9]
Word-level detection of code-mixed hate speech with multilingual domain transfer,
K. Niederreiter and D. Gromann, “Word-level detection of code-mixed hate speech with multilingual domain transfer,” inFindings of the Association for Computational Linguistics: ACL 2025. Vienna, Austria: Association for Computational Linguistics, 2025, pp. 21 093–21 104. [Online]. Available: https://aclanthology.org/2025.findings-acl.1086/
2025
-
[10]
A. Chopra, D. K. Sharma, A. Jha, and U. Ghosh, “A framework for online hate speech detection on code-mixed hindi-english text and hindi text in devanagari,”ACM Transactions on Asian and Low- Resource Language Information Processing, 2023. [Online]. Available: https://dl.acm.org/doi/10.1145/3568673
-
[11]
Model robustness with text classification: Semantic-preserving adversarial attacks,
R. Singh, T. Joshi, V . N. Nair, and A. Sudjianto, “Model robustness with text classification: Semantic-preserving adversarial attacks,”arXiv preprint arXiv:2008.05536, 2020. [Online]. Available: https://arxiv.org/abs/2008.05536
-
[12]
Semantic- preserving adversarial example attack against bert,
C. Gao, K. Gu, S. V osoughi, and S. Mehnaz, “Semantic- preserving adversarial example attack against bert,” inProceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024). Mexico City, Mexico: Association for Computational Linguistics, 2024, pp. 202–207. [Online]. Available: https://aclanthology.org/2024.trustnlp-1.17/
2024
-
[13]
The art of abstention: Selective prediction and error regularization for natural language processing,
J. Xin, R. Tang, Y . Yu, and J. Lin, “The art of abstention: Selective prediction and error regularization for natural language processing,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computatio...
2021
-
[14]
Exploring predictive uncer- tainty and calibration in nlp: A study on the impact of method & data scarcity,
D. Ulmer, J. Frellsen, and C. Hardmeier, “Exploring predictive uncer- tainty and calibration in nlp: A study on the impact of method & data scarcity,” inFindings of the Association for Computational Linguistics: EMNLP 2022, 2022
2022
-
[15]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProceedings of the 34th International Conference on Machine Learning, 2017
2017
-
[16]
Beyond temperature scaling: Obtaining well-calibrated multiclass prob- abilities with dirichlet calibration,
M. Kull, M. Perello-Nieto, M. K ¨angsepp, H. Song, and P. Flach, “Beyond temperature scaling: Obtaining well-calibrated multiclass prob- abilities with dirichlet calibration,” inAdvances in Neural Information Processing Systems, 2019
2019
-
[17]
Multidimensional uncertainty-aware evidential neural networks,
Y . Hu, Y . Ou, X. Zhao, J.-H. Cho, and F. Chen, “Multidimensional uncertainty-aware evidential neural networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 9, 2021, pp. 7815–7822
2021
-
[18]
Uncertainty-aware reliable text classification,
Y . Hu and L. Khan, “Uncertainty-aware reliable text classification,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 628–636
2021
-
[19]
Classification with abstention but without disparities,
N. Schreuder and E. Chzhen, “Classification with abstention but without disparities,”arXiv preprint arXiv:2102.12258, 2021
-
[20]
HateBench: Benchmarking hate speech detectors on LLM-generated content and hate campaigns,
X. Shen, Y . Wu, Y . Qu, M. Backes, S. Zannettou, and Y . Zhang, “HateBench: Benchmarking hate speech detectors on LLM-generated content and hate campaigns,” inUSENIX Security Symposium (USENIX Security). USENIX, 2025. [Online]. Available: https: //www.usenix.org/conference/usenixsecurity25/presentation/shen
2025
-
[21]
Lessons learned from the chameleon testbed,
K. Keahey, J. Anderson, Z. Zhen, P. Riteau, P. Ruth, D. Stanzione, M. Cevik, J. Colleran, H. S. Gunawi, C. Hammock, J. Mambretti, A. Barnes, F. Halbach, A. Rocha, and J. Stubbs, “Lessons learned from the chameleon testbed,” inProceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC ’20). USENIX Association, July 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.