CASS-RTL: Correctness-Aware Subspace Steering for RTL Generation with LLMs
Pith reviewed 2026-06-27 23:04 UTC · model grok-4.3
The pith
CASS-RTL steers LLMs toward correct RTL by intervening in a low-dimensional subspace of attention heads that separate correct from incorrect outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
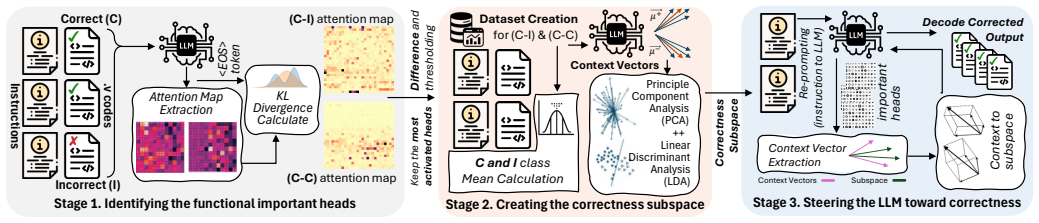
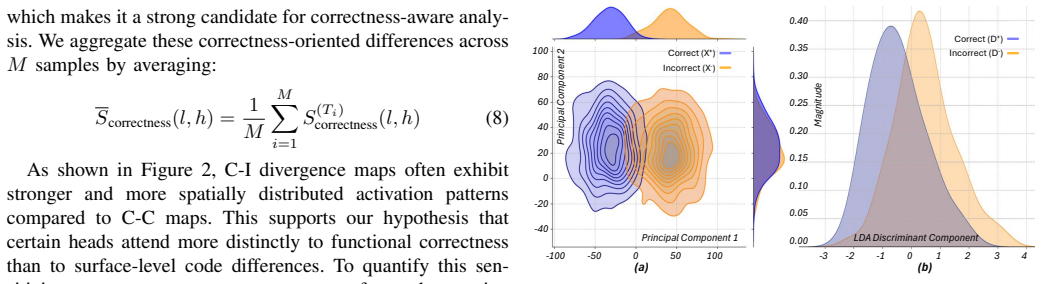
CASS-RTL identifies attention heads whose activation patterns consistently differentiate correct from incorrect RTL, constructs a low-dimensional subspace that captures the correctness-relevant signals, and applies a lightweight geometry-aware intervention at inference time to steer the model toward functionally accurate outputs; the approach is model-agnostic and needs no retraining or additional supervision.
What carries the argument
The correctness-aware subspace built from differentiating attention heads, which supplies the direction for the geometry-aware steering intervention.
If this is right
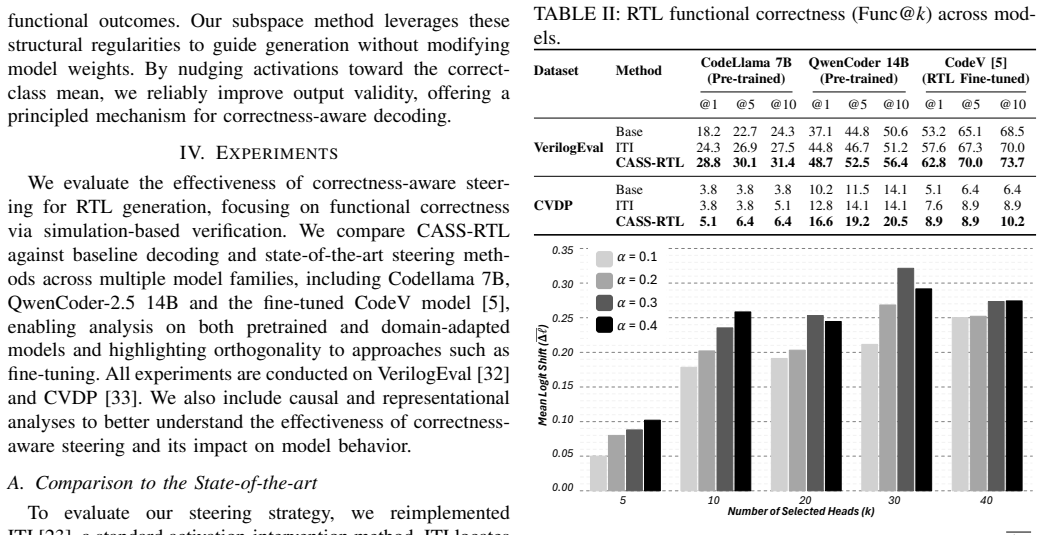
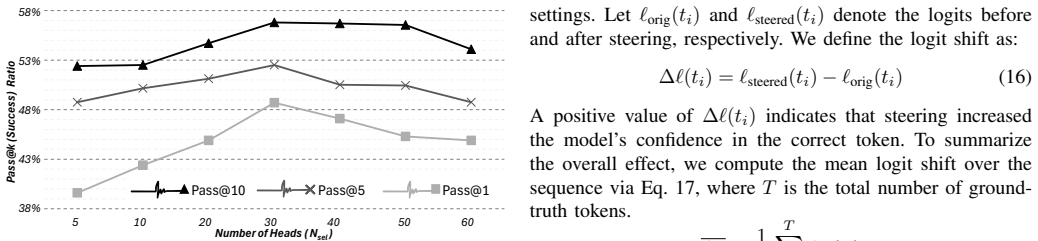
- Pass rates on RTL generation benchmarks rise 10-20 percent on VerilogEval and 5 percent on CVDP across multiple models.
- The steering integrates into existing LLMs at inference time with no retraining or extra labeled data.
- Functional accuracy improves while model efficiency and other capabilities remain intact.
- The same head-identification and subspace construction process can be repeated on new models or benchmarks.
Where Pith is reading between the lines
- Internal representations in LLMs appear to encode task-specific correctness signals that can be isolated geometrically without changing model weights.
- The same subspace construction might be tested on other domains that require strict functional correctness, such as formal property checking or embedded software generation.
- If the subspace remains stable across prompt distributions, reusable correctness vectors could be precomputed for families of hardware design tasks.
Load-bearing premise
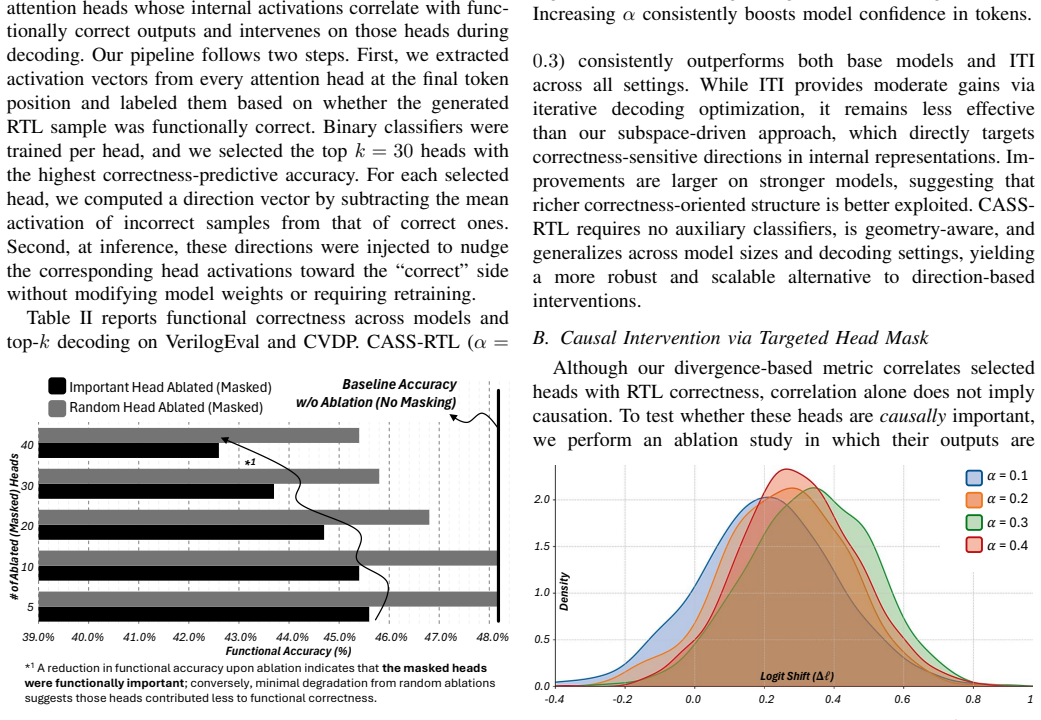
The attention heads whose patterns differentiate correct from incorrect RTL are causally responsible for correctness rather than merely correlated with it.
What would settle it
Measure whether accuracy gains disappear when the same intervention is applied to a control subspace drawn from attention heads that do not differentiate correct and incorrect RTL.
Figures
read the original abstract
Recent advances in large language models (LLMs) have enabled the automatic synthesis (generation) of register-transfer level (RTL) code from natural language instructions, offering a promising pathway to accelerate chip design. Unlike typical natural language (and software coding) tasks, LLM-based RTL code generation demands strict cycle accuracy with concurrency, where minor logical errors can render a circuit unusable or insecure. While prior work has explored hallucination mitigation via external verification, self-evaluation prompts, retrieval-augmented prompting, domain specific fine-tuning, agentic solutions, and reasoning, these approaches largely overlook the attention-oriented internal mechanisms of LLMs that may inherently correlate with RTL correctness. This work proposes CASS-RTL, a first-of-its-kind framework for discovering and leveraging LLMs' correctness-aware components to guide RTL generation toward functionally accurate outputs. We (i) identify attention heads whose activation patterns consistently differentiate correct from incorrect RTL; (ii) construct a low-dimensional subspace capturing correctness-relevant signals; and (iii) design a lightweight, geometry-aware intervention that steers the model at inference time. CASS-RTL is fully model-agnostic, requires no additional supervision or retraining, and readily integrates into existing models. Empirically, we evaluate CASS-RTL on multiple models and observe 10%-20% improvement in pass@1/5/10 accuracy on VerilogEval and 5% improvement on CVDP, demonstrating the effectiveness of our method in enhancing reliability without sacrificing model efficiency or requiring a large labeled dataset for fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CASS-RTL, a framework that identifies attention heads in LLMs whose activations differentiate correct from incorrect RTL outputs, constructs a low-dimensional subspace from those signals, and applies a lightweight geometry-aware intervention at inference time to steer generation. It claims this yields 10-20% gains in pass@1/5/10 on VerilogEval and 5% on CVDP, is model-agnostic, requires no retraining or inference-time supervision, and improves functional correctness in RTL synthesis.
Significance. If the reported gains can be shown to arise from causal correctness signals rather than correlation, the approach would offer a practical, training-free method for enhancing reliability in LLM-driven hardware design, where even small logical errors can invalidate circuits. The model-agnostic framing and integration with existing models are potential strengths if supported by the experiments.
major comments (3)
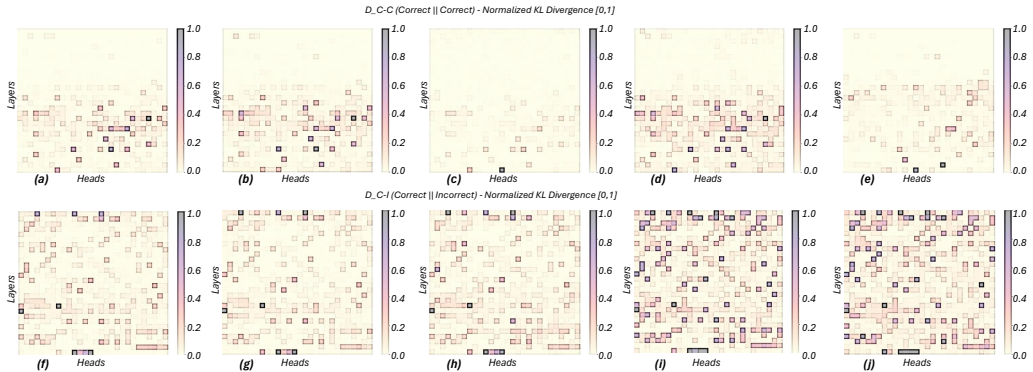
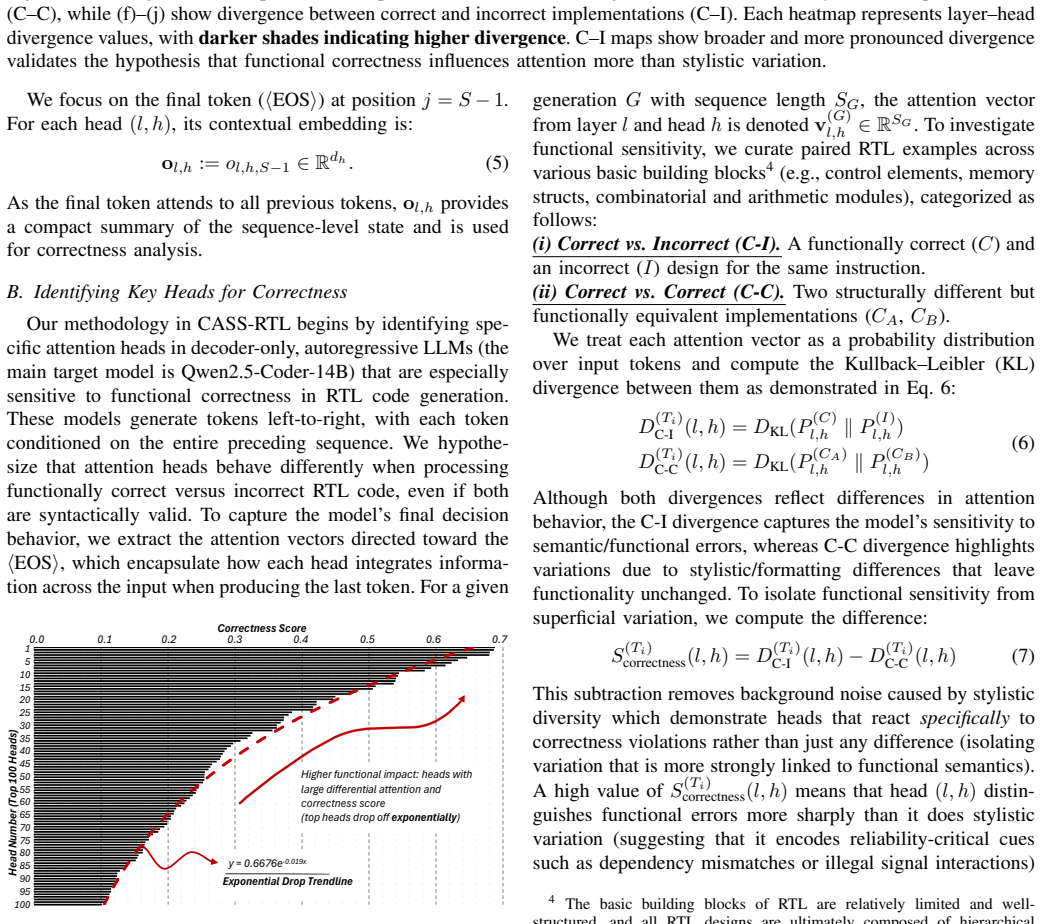
- [§3] §3 (head identification procedure): the claim that selected heads encode 'correctness-relevant signals' rests on activation-pattern differentiation between correct and incorrect RTL; however, the manuscript provides no causal tests (e.g., random-head or random-subspace baselines) to establish that intervening on these heads improves functional accuracy rather than merely correlating with output quality.
- [§5] §5 (experimental results): the 10-20% pass-rate improvements on VerilogEval and 5% on CVDP are reported without statistical significance tests, variance across multiple runs, or ablation against property-matched subspaces, leaving open whether the gains are robust or attributable to the proposed subspace.
- [§4] §4 (intervention formula): the geometry-aware steering is described as preserving model capabilities, yet no post-intervention checks for introduction of new error classes (timing violations, security issues, or concurrency bugs) are presented, which is load-bearing given the strict correctness requirements of RTL.
minor comments (2)
- [Abstract / §1] The abstract states the method is 'supervision-free at inference' while subspace construction requires labeled correct/incorrect pairs; this distinction should be clarified in the introduction.
- [§4] Notation for the subspace projection and intervention vector is introduced without an explicit equation reference, making the geometry-aware claim harder to follow.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and the opportunity to clarify and strengthen our work on CASS-RTL. Below we respond point-by-point to the major comments, indicating where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [§3] §3 (head identification procedure): the claim that selected heads encode 'correctness-relevant signals' rests on activation-pattern differentiation between correct and incorrect RTL; however, the manuscript provides no causal tests (e.g., random-head or random-subspace baselines) to establish that intervening on these heads improves functional accuracy rather than merely correlating with output quality.
Authors: We thank the referee for highlighting this important distinction between correlation and causation. The head selection in §3 is based on consistent differentiation in activation patterns between correct and incorrect generations, which we hypothesize captures correctness-relevant signals. To provide stronger evidence, we will add random-head selection and random-subspace baselines in the revised manuscript. These ablations will demonstrate that intervening on randomly chosen heads or subspaces does not produce comparable improvements in pass rates, supporting the specificity of our selected subspace. We believe this will address the causal concern while maintaining the training-free nature of the approach. revision: yes
-
Referee: [§5] §5 (experimental results): the 10-20% pass-rate improvements on VerilogEval and 5% on CVDP are reported without statistical significance tests, variance across multiple runs, or ablation against property-matched subspaces, leaving open whether the gains are robust or attributable to the proposed subspace.
Authors: We agree that reporting variance and statistical significance is essential for robustness. In the revision, we will include results averaged over multiple random seeds with standard deviations and perform t-tests or similar to assess significance of the improvements. Additionally, we will introduce an ablation study constructing subspaces from heads matched on properties such as average activation norm or layer position but without the correctness differentiation criterion. This will help isolate the contribution of the correctness-aware selection. These additions will be incorporated into §5. revision: yes
-
Referee: [§4] §4 (intervention formula): the geometry-aware steering is described as preserving model capabilities, yet no post-intervention checks for introduction of new error classes (timing violations, security issues, or concurrency bugs) are presented, which is load-bearing given the strict correctness requirements of RTL.
Authors: This is a critical consideration for RTL generation. Our current evaluation relies on the VerilogEval and CVDP benchmarks, which primarily assess functional correctness including aspects of concurrency and cycle accuracy. However, we did not conduct explicit post-steering analyses for timing violations, security vulnerabilities, or additional concurrency bugs beyond the benchmark pass rates. We will revise the manuscript to include a dedicated limitations subsection in §6 discussing these potential risks and the scope of our evaluation. While full verification would require specialized tools and is beyond the current scope, we can note that the steering is designed to be minimal and geometry-aware to avoid broad capability degradation. We partially address this by expanding the discussion but cannot add new empirical checks without further experiments. revision: partial
Circularity Check
No circularity: empirical identification from external labels, not self-referential
full rationale
The described pipeline identifies attention heads by comparing activation patterns on externally verified correct vs. incorrect RTL outputs, builds a subspace from those patterns, and applies an inference-time intervention. The reported accuracy gains are presented as measured outcomes on VerilogEval and CVDP benchmarks rather than quantities derived by construction from the identification step itself. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or method outline that would collapse the claimed improvement to a tautology. The central assumption (causal vs. correlational role of the subspace) is an empirical claim open to falsification, not a definitional reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rtl- coder: Fully open-source and efficient llm-assisted rtl code generation technique,
S. Liu, W. Fang, Y . Lu, J. Wang, Q. Zhang, H. Zhang, and Z. Xie, “Rtl- coder: Fully open-source and efficient llm-assisted rtl code generation technique,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024
2024
-
[2]
Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection,
F. Cui, C. Yin, K. Zhou, Y . Xiao, G. Sun, Q. Xu, Q. Guo, Y . Liang, X. Zhang, D. Songet al., “Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection,” inProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024, pp. 1–9
2024
-
[3]
Rtl++: Graph-enhanced llm for rtl code generation,
M. Akyash, K. Azar, and H. Kamali, “Rtl++: Graph-enhanced llm for rtl code generation,” in2025 IEEE International Conference on LLM-Aided Design (ICLAD). IEEE, 2025, pp. 44–50
2025
-
[4]
M. Liu, Y .-D. Tsai, W. Zhou, and H. Ren, “Craftrtl: High-quality synthetic data generation for verilog code models with correct-by- construction non-textual representations and targeted code repair,”arXiv preprint arXiv:2409.12993, 2024
-
[5]
Y . Zhao, D. Huang, C. Li, P. Jin, Z. Nan, T. Ma, L. Qi, Y . Pan, Z. Zhang, R. Zhanget al., “Codev: Empowering llms for verilog generation through multi-level summarization,”arXiv preprint arXiv:2407.10424, 2024
-
[6]
arXiv:2412.07822 [cs.AR] https://arxiv.org/abs/2412.07822 19
Y . Zhao, H. Zhang, H. Huang, Z. Yu, and J. Zhao, “Mage: A multi-agent engine for automated rtl code generation,”arXiv preprint arXiv:2412.07822, 2024
-
[7]
Scalertl: Scaling llms with reasoning data and test-time compute for accurate rtl code generation,
C. Deng, Y .-D. Tsai, G.-T. Liu, Z. Yu, and H. Ren, “Scalertl: Scaling llms with reasoning data and test-time compute for accurate rtl code generation,”arXiv preprint arXiv:2506.05566, 2025
-
[8]
Y . Zhu, D. Huang, H. Lyu, X. Zhang, C. Li, W. Shi, Y . Wu, J. Mu, J. Wang, Y . Zhaoet al., “Codev-r1: Reasoning-enhanced verilog gener- ation,”arXiv preprint arXiv:2505.24183, 2025
-
[9]
Simeval: Investigating the simi- larity obstacle in llm-based hardware code generation,
M. Akyash and H. Mardani Kamali, “Simeval: Investigating the simi- larity obstacle in llm-based hardware code generation,” inProceedings of the 30th Asia and South Pacific Design Automation Conference, ser. ASPDAC ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1002–1007
2025
-
[10]
Sage-hls: Syntax-aware ast-guided llm for high-level synthesis code generation,
M. Z. S. Khan, N. Mashnoor, M. Akyash, K. Azar, and H. Kamali, “Sage-hls: Syntax-aware ast-guided llm for high-level synthesis code generation,” in2025 IEEE 43rd International Conference on Computer Design (ICCD), 2025, pp. 574–581
2025
-
[11]
Llm-ift: Llm- powered information flow tracking for secure hardware,
N. Mashnoor, M. Akyash, H. Kamali, and K. Azar, “Llm-ift: Llm- powered information flow tracking for secure hardware,” in2025 IEEE 43rd VLSI Test Symposium (VTS). IEEE, 2025, pp. 1–5
2025
-
[12]
From Language to Logic: Bridging LLMs & Formal Representations for RTL Assertion Generation
N. Mashnoor, H. Kamali, and K. Azar, “From language to logic: Bridging llms & formal representations for rtl assertion generation,” arXiv preprint arXiv:2604.23100, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Decortl: A run-time decod- ing framework for rtl code generation with llms,
M. Akyash, K. Azar, and H. Kamali, “Decortl: A run-time decod- ing framework for rtl code generation with llms,”arXiv preprint arXiv:2507.02226, 2025
-
[14]
Hdlcore: A training-free framework for mitigating hallucinations in llm-generated hdl,
H. Ping, S. Li, P. Zhang, A. Cheng, S. Duan, N. Kanakaris, X. Xiao, W. Yang, S. Nazarian, A. Irimiaet al., “Hdlcore: A training-free framework for mitigating hallucinations in llm-generated hdl,”arXiv preprint arXiv:2503.16528, 2025
-
[15]
Haven: Hallucination-mitigated llm for verilog code generation aligned with hdl engineers,
Y . Yang, F. Teng, P. Liu, M. Qi, C. Lv, J. Li, X. Zhang, and Z. He, “Haven: Hallucination-mitigated llm for verilog code generation aligned with hdl engineers,” in2025 Design, Automation & Test in Europe Conference (DATE), 2025, pp. 1–7
2025
-
[16]
Self-hwdebug: Automation of llm self- instructing for hardware security verification,
M. Akyash and H. M. Kamali, “Self-hwdebug: Automation of llm self- instructing for hardware security verification,” in2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), 2024, pp. 391–396
2024
-
[17]
Safetune: Mitigating data poisoning in llm fine-tuning for rtl code generation,
M. Rezakhani, N. Mashnoor, K. Azar, and H. Kamali, “Safetune: Mitigating data poisoning in llm fine-tuning for rtl code generation,”
-
[18]
SafeTune: Mitigating Data Poisoning in LLM Fine-Tuning for RTL Code Generation
[Online]. Available: https://arxiv.org/abs/2604.27238
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
HaluEval: A large- scale hallucination evaluation benchmark for large language models,
J. Li, X. Cheng, X. Zhao, J.-Y . Nie, and J.-R. Wen, “HaluEval: A large- scale hallucination evaluation benchmark for large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023
2023
-
[20]
Language models that seek for knowledge: Modular search & genera- tion for dialogue and prompt completion,
K. Shuster, M. Komeili, L. Adolphs, S. Roller, A. Szlam, and J. Weston, “Language models that seek for knowledge: Modular search & genera- tion for dialogue and prompt completion,” inFindings of the Association for Computational Linguistics: EMNLP 2022, Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds. Association for Computational Linguistics, Dec
2022
-
[21]
Y . Wu, N. Hu, S. Bi, G. Qi, J. Ren, A. Xie, and W. Song, “Retrieve-rewrite-answer: A kg-to-text enhanced llms framework for knowledge graph question answering,” 2023. [Online]. Available: https://arxiv.org/abs/2309.11206
-
[22]
Halueval-wild: Evaluating hallucinations of language models in the wild,
Z. Zhu, Y . Yang, and Z. Sun, “Halueval-wild: Evaluating hallucinations of language models in the wild,”arXiv preprint arXiv:2403.04307, 2024
-
[23]
The internal state of an LLM knows when it’s lying,
A. Azaria and T. Mitchell, “The internal state of an LLM knows when it’s lying,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023
2023
-
[24]
Inference- time intervention: eliciting truthful answers from a language model,
K. Li, O. Patel, F. Vi ´egas, H. Pfister, and M. Wattenberg, “Inference- time intervention: eliciting truthful answers from a language model,” in Proceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
2023
-
[25]
TruthX: Alleviating hallucinations by editing large language models in truthful space,
S. Zhang, T. Yu, and Y . Feng, “TruthX: Alleviating hallucinations by editing large language models in truthful space,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Association for Computational Linguistics, Aug. 2024
2024
-
[26]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in gpt,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[27]
Self-alignment for factuality: Mitigating hallucinations in LLMs via self-evaluation,
X. Zhang, B. Peng, Y . Tian, J. Zhou, L. Jin, L. Song, H. Mi, and H. Meng, “Self-alignment for factuality: Mitigating hallucinations in LLMs via self-evaluation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for...
2024
-
[28]
Self-refine: Iter- ative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iter- ative refinement with self-feedback,”Advances in Neural Information Processing Systems, vol. 36, pp. 46 534–46 594, 2023
2023
-
[29]
Towards mitigating llm hallucination via self reflection,
Z. Ji, T. Yu, Y . Xu, N. Lee, E. Ishii, and P. Fung, “Towards mitigating llm hallucination via self reflection,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 1827–1843
2023
-
[30]
Discovering Latent Knowledge in Language Models Without Supervision
C. Burns, H. Ye, D. Klein, and J. Steinhardt, “Discovering latent knowledge in language models without supervision,”arXiv preprint arXiv:2212.03827, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
H. Huang, Z. Lin, Z. Wang, X. Chen, K. Ding, and J. Zhao, “Towards llm-powered verilog rtl assistant: Self-verification and self-correction,” arXiv preprint arXiv:2406.00115, 2024
-
[32]
Truth forest: toward multi-scale truthfulness in large language models through intervention without tuning,
Z. Chen, X. Sun, X. Jiao, F. Lian, Z. Kang, D. Wang, and C.-Z. Xu, “Truth forest: toward multi-scale truthfulness in large language models through intervention without tuning,” inAAAI, 2024
2024
-
[33]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1–8
2023
-
[34]
N. Pinckney, C. Deng, C.-T. Ho, Y .-D. Tsai, M. Liu, W. Zhou, B. Khailany, and H. Ren, “Comprehensive verilog design problems: A next-generation benchmark dataset for evaluating large language models and agents on rtl design and verification,” 2025. [Online]. Available: https://arxiv.org/abs/2506.14074
-
[35]
Meltrtl: Multi- expert llms with inference-time intervention for rtl code generation,
N. Mashnoor, M. Akyash, H. Kamali, and K. Azar, “Meltrtl: Multi- expert llms with inference-time intervention for rtl code generation,”
-
[36]
Available: https://arxiv.org/abs/2601.13015
[Online]. Available: https://arxiv.org/abs/2601.13015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.