MemoryCard: Topic-Aware Multi-Modal Clue Compression for Long-Video Question Answering
Pith reviewed 2026-06-28 01:50 UTC · model grok-4.3
The pith
MemoryCard segments long videos into topic-coherent units and packs each into a retrievable Memory Card to raise QA accuracy by up to 21.8 percent relative.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
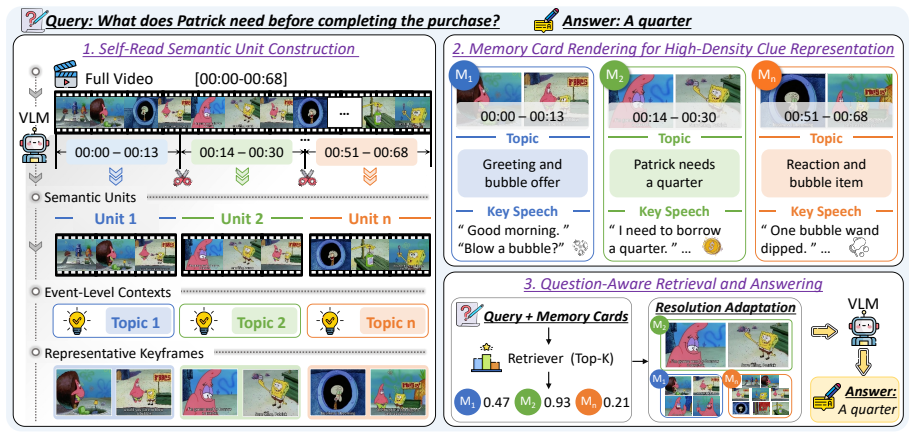
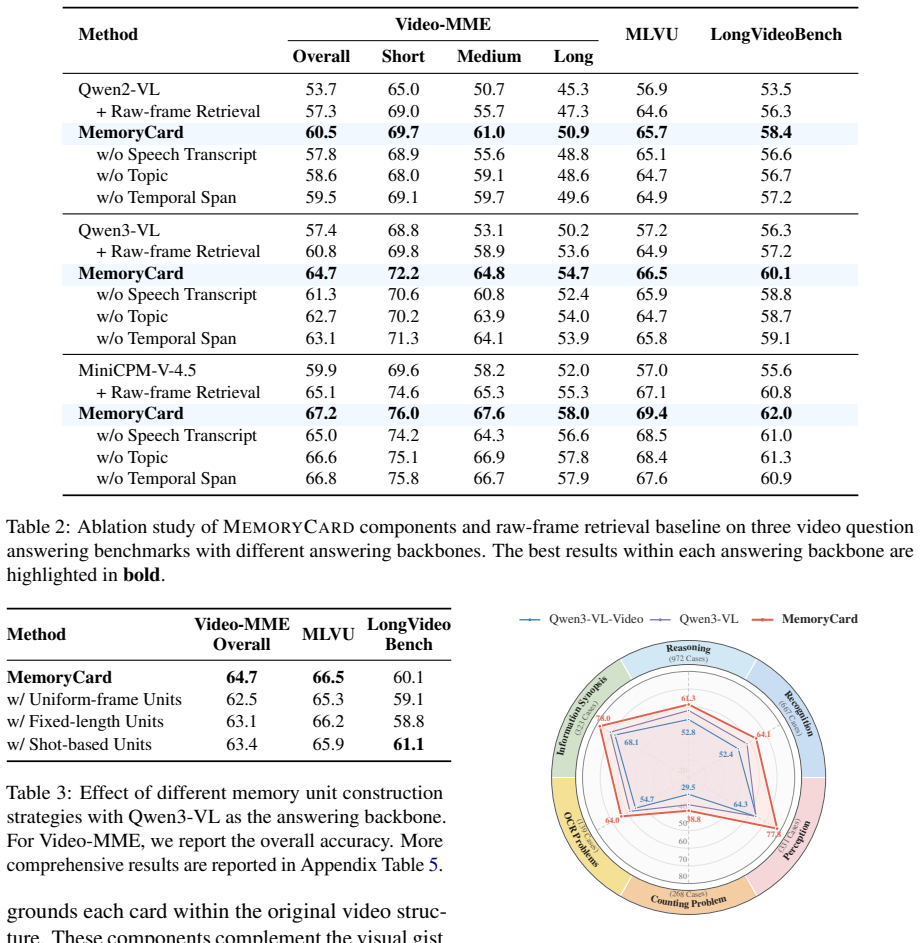
The paper presents MemoryCard as a video-memory augmentation that performs self-reading over videos and aligned utterances to segment them into semantically coherent units, each tied to a distinct topic or event. For each unit it produces an event-level video gist and selects representative visual moments, then renders both into unified Memory Cards. These cards serve as the basic evidence units for retrieval and question answering, yielding consistent gains in long-video QA performance while staying within comparable visual-token budgets and reaching a maximum relative accuracy improvement of 21.8 percent.
What carries the argument
Memory Cards: unified, topic-aware compressions that combine an event-level video gist with representative visual moments for each self-read segment.
If this is right
- VLMs receive coherent event-level semantics instead of fragmented frames as evidence units.
- Accuracy rises without any increase in the visual-token budget allocated to the model.
- The same Memory Card format supports both retrieval and final answer generation in one pipeline.
- Gains hold across multiple long-video QA benchmarks under fixed token constraints.
Where Pith is reading between the lines
- The same segmentation-plus-gist approach could be applied to audio-only or text-only long sequences by swapping the visual component for transcript chunks.
- If topic boundaries are noisy, downstream retrieval precision would drop first, offering a direct diagnostic for the self-reading module.
- Memory Cards could be cached across multiple questions about the same video, turning one-time segmentation into reusable memory for repeated queries.
Load-bearing premise
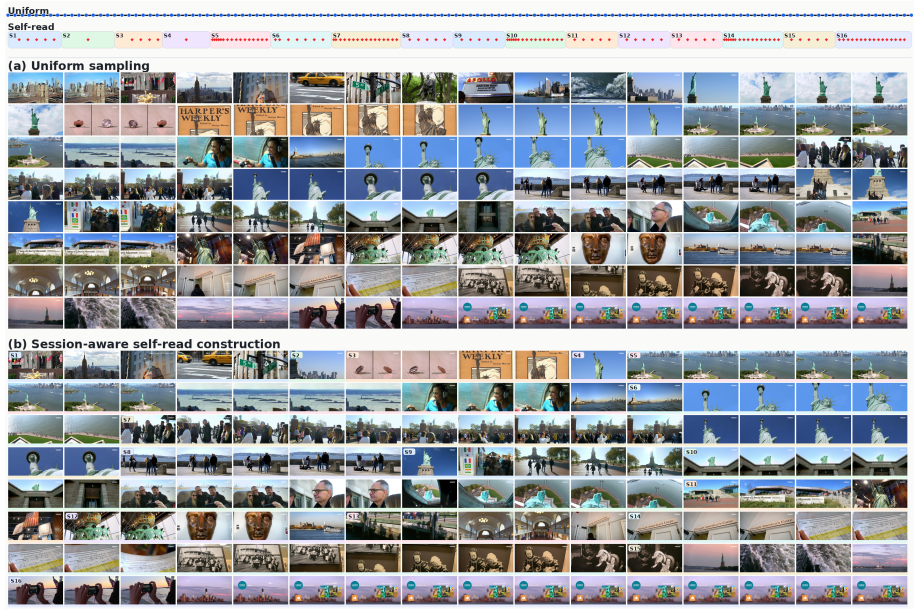
The self-reading process over videos and aligned utterances reliably segments the video into semantically coherent units that each correspond to a distinct topic or event.
What would settle it
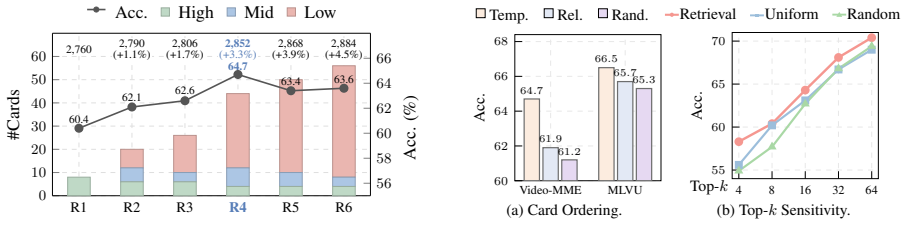
A controlled test in which the topic-segmentation step is removed and replaced by uniform frame sampling, yet accuracy remains equal or higher, would falsify the central claim.
Figures

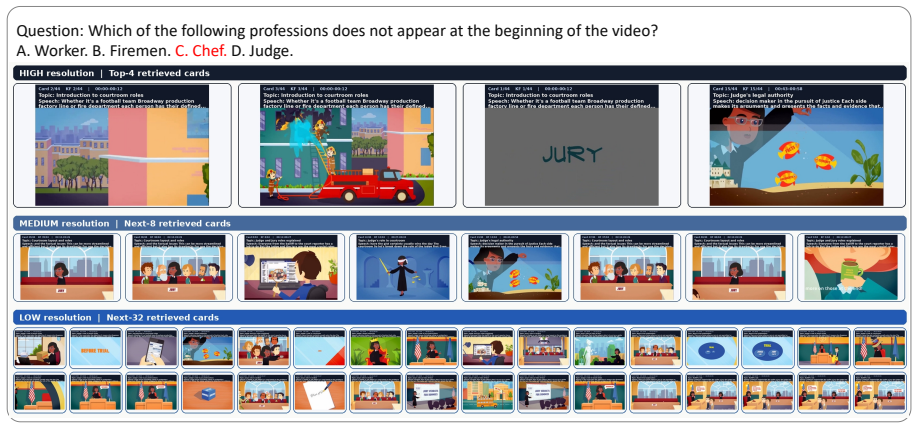

read the original abstract
Long-video question answering remains challenging for Vision-Language Models (VLMs), as answer-relevant evidence is often sparse, transient, and temporally dispersed across lengthy video contexts. Existing frame-centric approaches improve efficiency through uniform sampling, query-aware frame selection, visual-token compression, and adaptive resolution strategies. However, they still rely on isolated and fragmented frames as the fundamental evidence units, limiting VLMs' ability to effectively capture coherent event-level semantics. To address this limitation, we propose MemoryCard, a video-memory-based augmentation framework that organizes long videos into self-contained Memory Cards. Specifically, MemoryCard first performs a self-reading process over videos and aligned utterances to segment the video into semantically coherent units, each corresponding to a distinct topic or event. For each unit, it generates an event-level video gist and selects representative visual moments, which are then rendered into unified Memory Cards for retrieval and question answering. Experimental results demonstrate that MemoryCard consistently improves long-video QA performance under comparable visual-token budgets, achieving up to a 21.8% relative improvement in accuracy. All code is available at https://github.com/NEUIR/MemoryCard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemoryCard, a video-memory augmentation framework for long-video QA. It performs self-reading over videos and aligned utterances to segment into semantically coherent topic/event units, then generates event-level gists, selects representative moments, and renders them into unified Memory Cards for retrieval and answering. It reports consistent improvements over frame-centric baselines under comparable visual-token budgets, with up to 21.8% relative accuracy gain, and releases code.
Significance. If the segmentation premise holds and gains are attributable to event-level semantics rather than other factors, the work could advance long-video QA by shifting from fragmented frames to coherent units. The open-source code release supports reproducibility and is a clear strength.
major comments (2)
- [Abstract, paragraph 3] Abstract, paragraph 3: The central performance claim (up to 21.8% relative gain) rests on the self-reading process producing units each matching a distinct topic or event. No quantitative validation (coherence metrics, human agreement scores, or ablation removing the segmentation) is provided to confirm this holds on the evaluation videos; without it, gains cannot be confidently attributed to topic-aware compression rather than gist rendering or retrieval.
- [Experiments] Experiments (assumed §4-5): The reported accuracy improvements lack details on exact baselines, statistical significance testing, dataset splits, or controls for segmentation quality. This makes it difficult to verify whether the gains hold under fixed token budgets after accounting for the unvalidated segmentation step.
minor comments (1)
- [Abstract] The abstract mentions 'comparable visual-token budgets' but does not define how token counts are measured or normalized across methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validating the segmentation premise and expanding experimental details. We address each major comment below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract, paragraph 3] Abstract, paragraph 3: The central performance claim (up to 21.8% relative gain) rests on the self-reading process producing units each matching a distinct topic or event. No quantitative validation (coherence metrics, human agreement scores, or ablation removing the segmentation) is provided to confirm this holds on the evaluation videos; without it, gains cannot be confidently attributed to topic-aware compression rather than gist rendering or retrieval.
Authors: We agree that the absence of quantitative validation for the segmentation step limits confident attribution of gains specifically to topic-aware units. The manuscript provides qualitative examples of segmented units but does not include coherence metrics, human agreement scores, or an ablation that isolates the segmentation component. We will add an ablation comparing the full MemoryCard pipeline against a variant without self-reading segmentation, and include any available internal coherence scores from the process. Human agreement would require new annotations beyond the current scope. revision: yes
-
Referee: [Experiments] Experiments (assumed §4-5): The reported accuracy improvements lack details on exact baselines, statistical significance testing, dataset splits, or controls for segmentation quality. This makes it difficult to verify whether the gains hold under fixed token budgets after accounting for the unvalidated segmentation step.
Authors: We will revise the experimental section to specify the exact baselines, dataset splits used, and any statistical significance testing performed. We will also incorporate controls or additional ablations that address segmentation quality to allow verification of gains under fixed visual-token budgets. The current results already enforce comparable token budgets across methods. revision: yes
Circularity Check
No circularity; empirical framework with no derived quantities or self-referential reductions.
full rationale
The paper describes a proposed MemoryCard framework that performs self-reading segmentation into topic/event units, generates gists and moments, renders Memory Cards, and reports empirical accuracy gains (up to 21.8% relative) under fixed token budgets. No equations, fitted parameters, predictions derived from inputs, or self-citation chains are present in the provided text. The performance claim is framed as an experimental outcome on long-video QA benchmarks rather than a quantity forced by construction from the method's own definitions or prior self-citations. The segmentation premise is an assumption whose validity is left to empirical results, not a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , doi =
Kai Hu and Feng Gao and Xiaohan Nie and Peng Zhou and Son Tran and Tal Neiman and Lingyun Wang and Mubarak Shah and Raffay Hamid and Bing Yin and Trishul Chilimbi , title =. 2025 , doi =
2025
-
[2]
Qwen Team , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.21337 , eprinttype =. 2601.21337 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.21337 2026
-
[3]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[4]
Long-CLIP: Unlocking the Long-Text Capability of
Beichen Zhang and Pan Zhang and Xiaoyi Dong and Yuhang Zang and Jiaqi Wang , editor =. Long-CLIP: Unlocking the Long-Text Capability of. Computer Vision -. 2024 , url =. doi:10.1007/978-3-031-72983-6\_18 , timestamp =
-
[5]
Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos , booktitle =
Qirui Chen and Shangzhe Di and Weidi Xie , editor =. Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos , booktitle =. 2025 , url =. doi:10.1609/AAAI.V39I2.32214 , timestamp =
-
[6]
Video-bench: Human-aligned video generation benchmark
Jinhui Ye and Zihan Wang and Haosen Sun and Keshigeyan Chandrasegaran and Zane Durante and Crist. Re-thinking Temporal Search for Long-Form Video Understanding , booktitle =. 2025 , url =. doi:10.1109/CVPR52734.2025.00802 , timestamp =
-
[7]
Xuyi Yang and Wenhao Zhang and Hongbo Jin and Lin Liu and Hongbo Xu and Yongwei Nie and Fei Yu and Fei Ma , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.03009 , eprinttype =. 2508.03009 , timestamp =
-
[8]
Haidong Xin and Xinze Li and Zhenghao Liu and Yukun Yan and Shuo Wang and Cheng Yang and Yu Gu and Ge Yu and Maosong Sun , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.11182 , eprinttype =. 2602.11182 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.11182 2026
-
[9]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang and Xinle Deng and Haoming Xu and Ziyan Jiang and Yuqi Tang and Ziwen Xu and Shumin Deng and Yunzhi Yao and Mengru Wang and Shuofei Qiao and Huajun Chen and Ningyu Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.18866 , eprinttype =. 2510.18866 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18866 2025
-
[10]
Video-bench: Human-aligned video generation benchmark
Yujie Lu and Yale Song and William Wang and Lorenzo Torresani and Tushar Nagarajan , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.00795 , timestamp =
-
[11]
Jiaqi Xu and Cuiling Lan and Wenxuan Xie and Xuejin Chen and Yan Lu , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2312.04931 , eprinttype =. 2312.04931 , timestamp =
-
[12]
Nature Reviews Neuroscience , volume=
Attentional enhancement of spatial resolution: linking behavioural and neurophysiological evidence , author=. Nature Reviews Neuroscience , volume=. 2013 , publisher=
2013
-
[13]
Ruotong Liao and Max Erler and Huiyu Wang and Guangyao Zhai and Gengyuan Zhang and Yunpu Ma and Volker Tresp , editor =. VideoINSTA: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with LLMs , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-EMNLP.384 , timestamp =
-
[14]
Hang Zhang and Xin Li and Lidong Bing , editor =. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-DEMO.49 , timestamp =
-
[15]
The Thirteenth International Conference on Learning Representations,
Sicheng Yu and Chengkai Jin and Huanyu Wang and Zhenghao Chen and Sheng Jin and Zhongrong Zuo and Xiaolei Xu and Zhenbang Sun and Bingni Zhang and Jiawei Wu and Hao Zhang and Qianru Sun , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[16]
Video-bench: Human-aligned video generation benchmark
Anxhelo Diko and Tinghuai Wang and Wassim Swaileh and Shiyan Sun and Ioannis Patras , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.01282 , timestamp =
-
[17]
Ryoo , editor =
Kumara Kahatapitiya and Kanchana Ranasinghe and Jongwoo Park and Michael S. Ryoo , editor =. Language Repository for Long Video Understanding , booktitle =. 2025 , url =
2025
-
[18]
AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding , booktitle =
Xiao Wang and Qingyi Si and Shiyu Zhu and Jianlong Wu and Li Cao and Liqiang Nie , editor =. AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding , booktitle =. 2025 , url =
2025
-
[19]
Vbench: Comprehensive benchmark suite for video generative models
Reuben Tan and Ximeng Sun and Ping Hu and Jui. Koala: Key Frame-Conditioned Long Video-LLM , booktitle =. 2024 , url =. doi:10.1109/CVPR52733.2024.01289 , timestamp =
-
[20]
arXiv preprint arXiv:2406.04264 , volume=
Mlvu: A comprehensive benchmark for multi-task long video understanding , author=. arXiv preprint arXiv:2406.04264 , volume=. 2024 , url =
Pith/arXiv arXiv 2024
-
[21]
2025 , doi =
Chaoyou Fu and Yuhan Dai and Yongdong Luo and Lei Li and Shuhuai Ren and Renrui Zhang and Zihan Wang and Chenyu Zhou and Yunhang Shen and Mengdan Zhang and Peixian Chen and Yanwei Li and Shaohui Lin and Sirui Zhao and Ke Li and Tong Xu and Xiawu Zheng and Enhong Chen and Caifeng Shan and Ran He and Xing Sun , title =. 2025 , doi =
2025
-
[22]
Peiyuan Zhang and Kaichen Zhang and Bo Li and Guangtao Zeng and Jingkang Yang and Yuanhan Zhang and Ziyue Wang and Haoran Tan and Chunyuan Li and Ziwei Liu , title =. Trans. Mach. Learn. Res. , volume =. 2025 , url =
2025
-
[23]
LongVideoBench:
Haoning Wu and Dongxu Li and Bei Chen and Junnan Li , editor =. LongVideoBench:. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[24]
arXiv preprint arXiv:2601.23224 , year=
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning , author=. arXiv preprint arXiv:2601.23224 , year=
-
[25]
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models , booktitle =
Kaichen Zhang and Bo Li and Peiyuan Zhang and Fanyi Pu and Joshua Adrian Cahyono and Kairui Hu and Shuai Liu and Yuanhan Zhang and Jingkang Yang and Chunyuan Li and Ziwei Liu , editor =. LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models , booktitle =. 2025 , url =. doi:10.18653/V1/2025.FINDINGS-NAACL.51 , timestamp =
-
[26]
Yuanhan Zhang and Jinming Wu and Wei Li and Bo Li and Zejun Ma and Ziwei Liu and Chunyuan Li , title =. Trans. Mach. Learn. Res. , volume =. 2025 , url =
2025
-
[27]
Jiazheng Kang and Mingming Ji and Zhe Zhao and Ting Bai , editor =. Memory. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.1318 , timestamp =
-
[28]
arXiv preprint arXiv:2407.15841 , year=
Slowfast-llava: A strong training-free baseline for video large language models , author=. arXiv preprint arXiv:2407.15841 , year=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Shaojie Zhang and Jiahui Yang and Jianqin Yin and Zhenbo Luo and Jian Luan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2025 , publisher =
2025
-
[30]
Video-bench: Human-aligned video generation benchmark
Md Mohaiminul Islam and Tushar Nagarajan and Huiyu Wang and Gedas Bertasius and Lorenzo Torresani , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.02709 , timestamp =
-
[31]
VideoAgent: Long-Form Video Understanding with Large Language Model as Agent , booktitle =
Xiaohan Wang and Yuhui Zhang and Orr Zohar and Serena Yeung. VideoAgent: Long-Form Video Understanding with Large Language Model as Agent , booktitle =. 2024 , url =. doi:10.1007/978-3-031-72989-8\_4 , timestamp =
-
[32]
arXiv preprint arXiv:2312.05269 , year=
Lifelongmemory: Leveraging llms for answering queries in long-form egocentric videos , author=. arXiv preprint arXiv:2312.05269 , year=
-
[33]
arXiv preprint arXiv:2411.11066 , year=
Ts-llava: Constructing visual tokens through thumbnail-and-sampling for training-free video large language models , author=. arXiv preprint arXiv:2411.11066 , year=
-
[34]
arXiv preprint arXiv:2406.09396 , year=
Too many frames, not all useful: Efficient strategies for long-form video qa , author=. arXiv preprint arXiv:2406.09396 , year=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Building a mind palace: Structuring environment-grounded semantic graphs for effective long video analysis with llms , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
STORM: Token-Efficient Long Video Understanding for Multimodal LLMs , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[37]
arXiv preprint arXiv:2509.23724 , year=
Video Panels for Long Video Understanding , author=. arXiv preprint arXiv:2509.23724 , year=
-
[38]
Vbench: Comprehensive benchmark suite for video generative models
Bo He and Hengduo Li and Young Kyun Jang and Menglin Jia and Xuefei Cao and Ashish Shah and Abhinav Shrivastava and Ser. 2024 , url =. doi:10.1109/CVPR52733.2024.01282 , timestamp =
-
[39]
Vbench: Comprehensive benchmark suite for video generative models
Shuhuai Ren and Linli Yao and Shicheng Li and Xu Sun and Lu Hou , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.01357 , timestamp =
-
[40]
arXiv preprint arXiv:2603.15167 , year=
Question-guided Visual Compression with Memory Feedback for Long-Term Video Understanding , author=. arXiv preprint arXiv:2603.15167 , year=
-
[41]
Streaming Long Video Understanding with Large Language Models , booktitle =
Rui Qian and Xiaoyi Dong and Pan Zhang and Yuhang Zang and Shuangrui Ding and Dahua Lin and Jiaqi Wang , editor =. Streaming Long Video Understanding with Large Language Models , booktitle =. 2024 , url =
2024
-
[42]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
A simple llm framework for long-range video question-answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[43]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Omagent: A multi-modal agent framework for complex video understanding with task divide-and-conquer , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Video-xl: Extra-long vision language model for hour-scale video understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Encoding and controlling global semantics for long-form video question answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[46]
Kim and Bilge Soran and Raghuraman Krishnamoorthi and Mohamed Elhoseiny and Vikas Chandra , editor =
Xiaoqian Shen and Yunyang Xiong and Changsheng Zhao and Lemeng Wu and Jun Chen and Chenchen Zhu and Zechun Liu and Fanyi Xiao and Balakrishnan Varadarajan and Florian Bordes and Zhuang Liu and Hu Xu and Hyunwoo J. Kim and Bilge Soran and Raghuraman Krishnamoorthi and Mohamed Elhoseiny and Vikas Chandra , editor =. LongVU: Spatiotemporal Adaptive Compressi...
2025
-
[47]
Wei Han and Hui Chen and Min. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2307.04192 , eprinttype =. 2307.04192 , timestamp =
-
[48]
Mustafa Chasmai and Gauri Jagatap and Gouthaman KV and Grant Van Horn and Subhransu Maji and Andrea Fanelli , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.00033 , eprinttype =. 2507.00033 , timestamp =
-
[49]
Vbench: Comprehensive benchmark suite for video generative models
Bin Huang and Xin Wang and Hong Chen and Zihan Song and Wenwu Zhu , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.01353 , timestamp =
-
[50]
Self-Chained Image-Language Model for Video Localization and Question Answering , booktitle =
Shoubin Yu and Jaemin Cho and Prateek Yadav and Mohit Bansal , editor =. Self-Chained Image-Language Model for Video Localization and Question Answering , booktitle =. 2023 , url =
2023
-
[51]
Video-bench: Human-aligned video generation benchmark
Ziyang Wang and Shoubin Yu and Elias Stengel. VideoTree: Adaptive Tree-based Video Representation for. 2025 , url =. doi:10.1109/CVPR52734.2025.00311 , timestamp =
-
[52]
, author=
Event perception: a mind-brain perspective. , author=. Psychological bulletin , volume=. 2007 , publisher=
2007
-
[53]
Trends in cognitive sciences , volume=
Segmentation in the perception and memory of events , author=. Trends in cognitive sciences , volume=. 2008 , publisher=
2008
-
[54]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz and Hanoona Abdul Rasheed and Salman Khan and Fahad Khan , editor =. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.679 , timestamp =
-
[55]
Video-bench: Human-aligned video generation benchmark
Xi Tang and Jihao Qiu and Lingxi Xie and Yunjie Tian and Jianbin Jiao and Qixiang Ye , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.02711 , timestamp =
-
[56]
Generative Frame Sampler for Long Video Understanding , booktitle =
Linli Yao and Haoning Wu and Kun Ouyang and Yuanxing Zhang and Caiming Xiong and Bei Chen and Xu Sun and Junnan Li , editor =. Generative Frame Sampler for Long Video Understanding , booktitle =. 2025 , url =
2025
-
[57]
LongVLM: Efficient Long Video Understanding via Large Language Models , booktitle =
Yuetian Weng and Mingfei Han and Haoyu He and Xiaojun Chang and Bohan Zhuang , editor =. LongVLM: Efficient Long Video Understanding via Large Language Models , booktitle =. 2024 , url =. doi:10.1007/978-3-031-73414-4\_26 , timestamp =
-
[58]
Video-bench: Human-aligned video generation benchmark
Keda Tao and Can Qin and Haoxuan You and Yang Sui and Huan Wang , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.01769 , timestamp =
-
[59]
PruneVid: Visual Token Pruning for Efficient Video Large Language Models , booktitle =
Xiaohu Huang and Hao Zhou and Kai Han , editor =. PruneVid: Visual Token Pruning for Efficient Video Large Language Models , booktitle =. 2025 , url =
2025
-
[60]
Video-bench: Human-aligned video generation benchmark
Shyamal Buch and Arsha Nagrani and Anurag Arnab and Cordelia Schmid , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.02707 , timestamp =
-
[61]
Video-bench: Human-aligned video generation benchmark
Shuming Liu and Chen Zhao and Tianqi Xu and Bernard Ghanem , title =. 2025 , url =. doi:10.1109/CVPR52734.2025.00315 , timestamp =
-
[62]
2025 , url =
Bao Tran Gia and Khiem Le and Tien Do and Tien. 2025 , url =
2025
-
[63]
Vbench: Comprehensive benchmark suite for video generative models
Juhong Min and Shyamal Buch and Arsha Nagrani and Minsu Cho and Cordelia Schmid , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.01257 , timestamp =
-
[64]
arXiv preprint arXiv:2411.13093 (2024)
Yongdong Luo and Xiawu Zheng and Xiao Yang and Guilin Li and Haojia Lin and Jinfa Huang and Jiayi Ji and Fei Chao and Jiebo Luo and Rongrong Ji , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.13093 , eprinttype =. 2411.13093 , timestamp =
-
[65]
Vbench: Comprehensive benchmark suite for video generative models
Enxin Song and Wenhao Chai and Guanhong Wang and Yucheng Zhang and Haoyang Zhou and Feiyang Wu and Haozhe Chi and Xun Guo and Tian Ye and Yanting Zhang and Yan Lu and Jenq. MovieChat: From Dense Token to Sparse Memory for Long Video Understanding , booktitle =. 2024 , url =. doi:10.1109/CVPR52733.2024.01725 , timestamp =
-
[66]
MovieChat+: Question-Aware Sparse Memory for Long Video Question Answering , journal =
Enxin Song and Wenhao Chai and Tian Ye and Jenq. MovieChat+: Question-Aware Sparse Memory for Long Video Question Answering , journal =. 2026 , url =. doi:10.1109/TPAMI.2025.3604614 , timestamp =
-
[67]
Haoji Zhang and Yiqin Wang and Yansong Tang and Yong Liu and Jiashi Feng and Xiaojie Jin , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.23825 , eprinttype =. 2506.23825 , timestamp =
-
[68]
arXiv preprint arXiv:2510.12422 , url =
VideoLucy: Deep Memory Backtracking for Long Video Understanding , author=. arXiv preprint arXiv:2510.12422 , url =
-
[69]
The Thirteenth International Conference on Learning Representations,
Shi Yu and Chaoyue Tang and Bokai Xu and Junbo Cui and Junhao Ran and Yukun Yan and Zhenghao Liu and Shuo Wang and Xu Han and Zhiyuan Liu and Maosong Sun , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.