Asuka-Bench: Benchmarking Code Agents on Underspecified User Intent and Multi-Round Refinement
Pith reviewed 2026-06-28 00:24 UTC · model grok-4.3
The pith
Asuka-Bench shows code agents complete only 52 percent of web projects after three rounds of feedback on underspecified tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
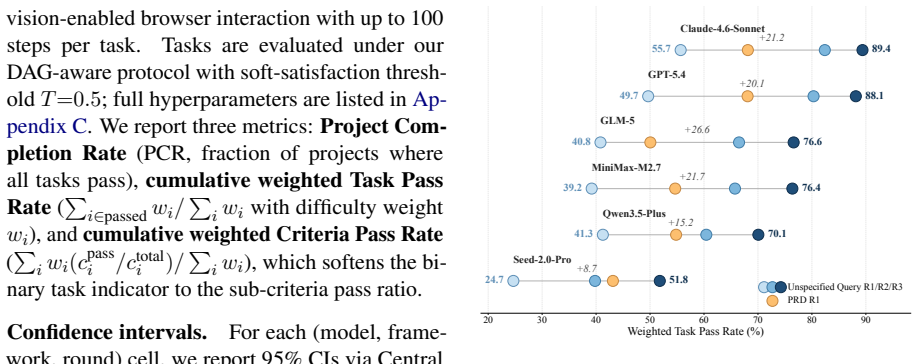
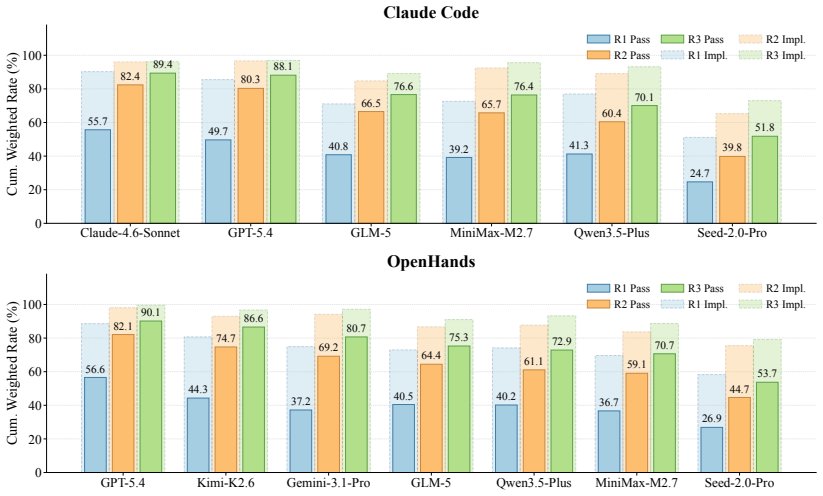
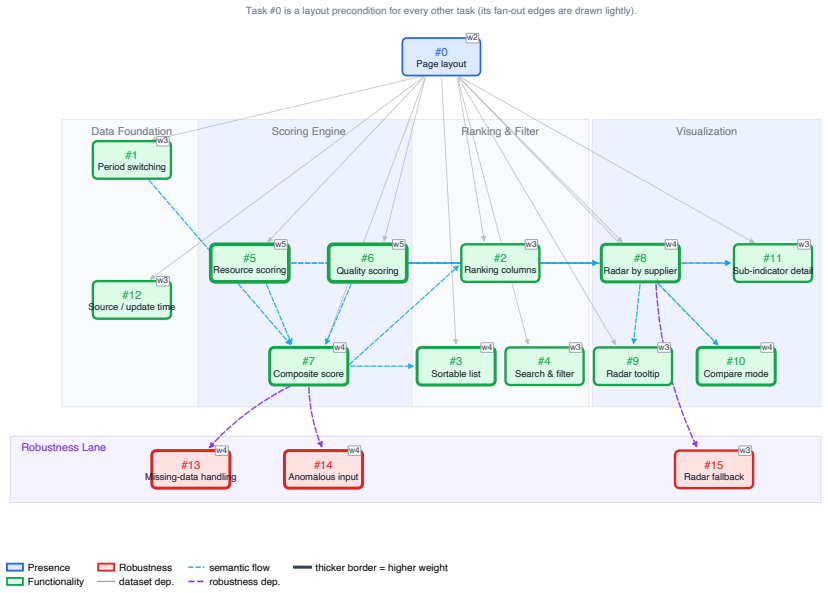
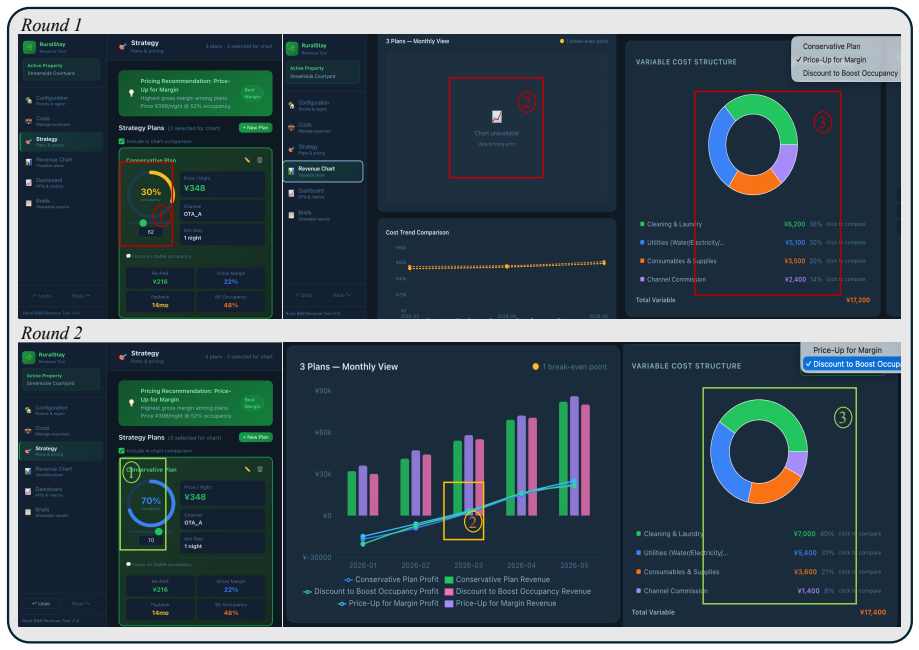
Asuka-Bench demonstrates that current code agents vary widely in their capacity to incorporate natural-language feedback and repair web projects over successive rounds, with weighted Task Pass Rate differing by 38 percentage points and the top model reaching only 52 percent completion after three iterations.
What carries the argument
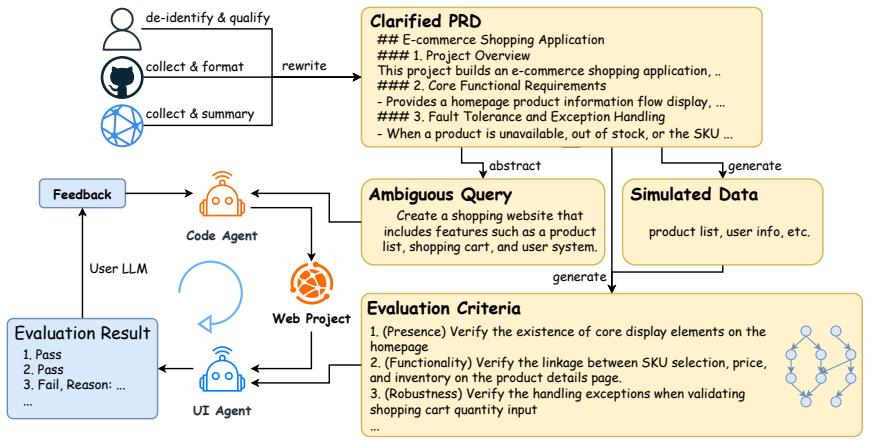
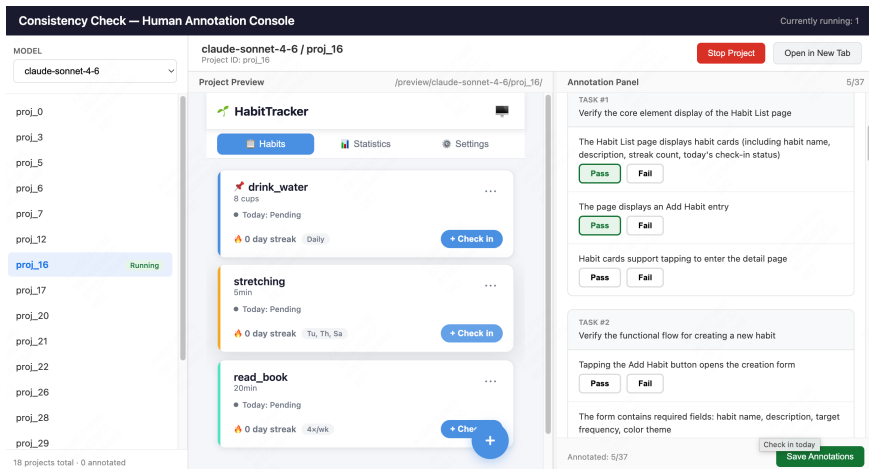
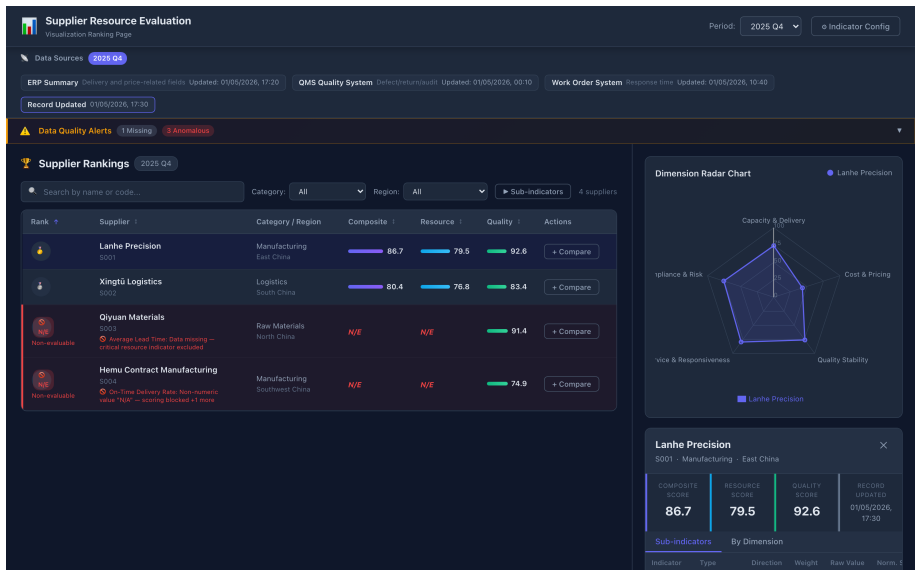
The closed loop of Code Agent generating web projects, UI Agent executing test cases on the deployed site, and User LLM converting evaluation outcomes into natural-language feedback for the next round.
If this is right
- Models differ substantially in their ability to repair projects from feedback.
- Performance gaps between models remain large even after multiple refinement rounds.
- The benchmark leaves substantial headroom, since the strongest model reaches only 52 percent completion.
- Weighted Task Pass Rate provides a finer separation than simple pass/fail metrics.
Where Pith is reading between the lines
- Agents that treat feedback as an explicit state update rather than a new prompt may close part of the observed gap.
- Extending the same closed-loop structure to non-web domains would test whether the refinement difficulty is web-specific or general.
- Task Pass Rate after one round versus after three rounds could serve as a direct measure of an agent's feedback incorporation skill.
Load-bearing premise
The closed loop of code agent, UI agent test execution, and user LLM feedback accurately captures real-world underspecified user intent and multi-round refinement in web development.
What would settle it
An experiment in which human users replace the User LLM and produce materially different feedback that changes model ranking or completion rates on the same 50 tasks.
Figures





read the original abstract
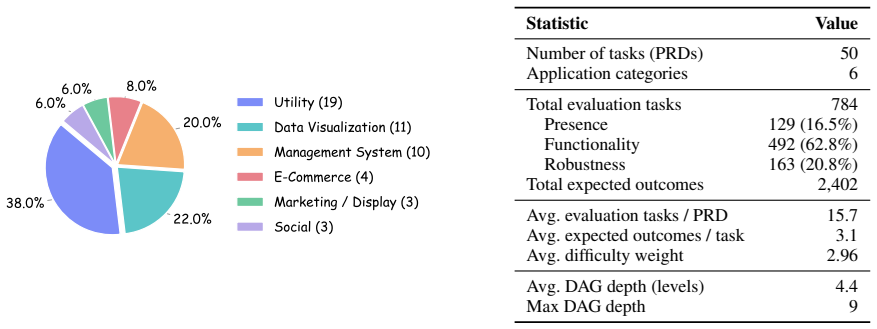
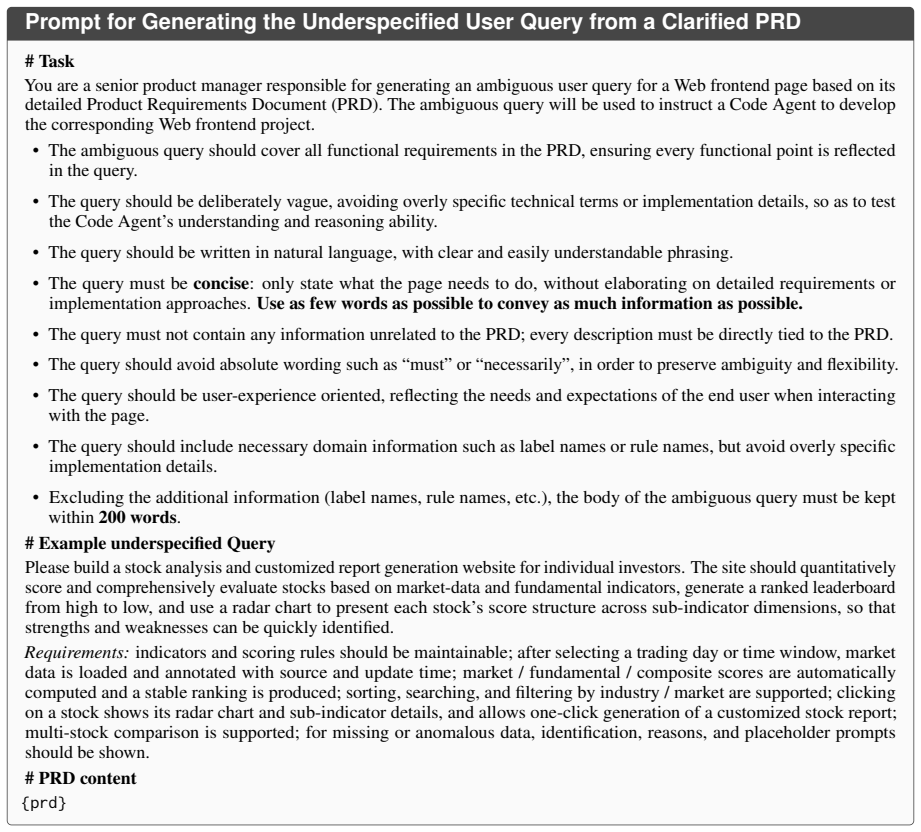
Existing code-generation benchmarks score a single mapping from a complete prompt to a one-shot output. However, real web development is different. Users seldom write a full spec at the start; many requirements only become clear once they look at an intermediate result and react to it. We present Asuka-Bench, a benchmark that pairs underspecified user intent with multi-round refinement, grounded in browser-rendered behavior. Each task is resolved through a closed loop: a Code Agent generates a web project, a UI Agent executes test cases on the deployed site, and a User LLM turns evaluation outcomes into natural-language feedback for the next round. The benchmark comprises 50 web tasks with 784 evaluation criteria and 2402 expected outcomes. We benchmark 8 LLMs across 2 agent frameworks. The results separate models clearly: weighted Task Pass Rate varies by 38 percentage points and models also differ substantially in their ability to repair from feedback. Asuka-Bench is also far from saturated: even the strongest model completes only 52% of projects after three rounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Asuka-Bench, a benchmark of 50 web development tasks (784 criteria, 2402 expected outcomes) that evaluates code agents on underspecified intents via a closed-loop protocol: Code Agent generates a project, UI Agent runs browser tests, and User LLM converts outcomes into natural-language feedback for up to three refinement rounds. Benchmarking eight LLMs across two frameworks shows clear separation, with weighted Task Pass Rate spanning 38 percentage points and the strongest model reaching only 52% project completion after three rounds.
Significance. If the simulation protocol is shown to be a faithful proxy, the benchmark would be a useful addition to code-agent evaluation by moving beyond one-shot generation to iterative, feedback-driven refinement grounded in rendered behavior. The reported performance gaps and low absolute scores provide concrete evidence that current agents struggle with repair from underspecified feedback, which could guide future work on multi-turn agent architectures.
major comments (2)
- [§3, §4] §3 (Benchmark Construction) and §4 (Evaluation Protocol): The central claim that Asuka-Bench measures real-world multi-round refinement rests on the User LLM converting UI Agent test outcomes into natural-language feedback. No human baseline, inter-rater agreement study, or ablation comparing LLM-generated feedback distributions to human developer responses after viewing rendered pages is reported. Without this, both absolute completion rates and model rankings risk being artifacts of the specific LLM feedback style rather than evidence about underspecified intent.
- [§5] §5 (Results): The headline separation of 38 pp in weighted Task Pass Rate and the 52% ceiling for the best model after three rounds are presented as evidence of benchmark utility, yet these quantities inherit the unvalidated feedback mechanism; any systematic difference in feedback precision or scope between the User LLM and actual users would directly alter both the reported numbers and the cross-model ordering.
minor comments (2)
- [Abstract, §2] The abstract and §2 would benefit from an explicit statement of how the 50 tasks were sampled and how the 784 criteria were derived to ensure they are representative rather than hand-curated.
- [Table 1] Table 1 (model results) should include per-round breakdown and variance across the 50 tasks to allow readers to assess whether the 38 pp gap is driven by a few outlier tasks.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the User LLM feedback mechanism. We address the two major comments point by point below, maintaining that the benchmark provides a reproducible evaluation of multi-round refinement while acknowledging the lack of human comparison data.
read point-by-point responses
-
Referee: [§3, §4] §3 (Benchmark Construction) and §4 (Evaluation Protocol): The central claim that Asuka-Bench measures real-world multi-round refinement rests on the User LLM converting UI Agent test outcomes into natural-language feedback. No human baseline, inter-rater agreement study, or ablation comparing LLM-generated feedback distributions to human developer responses after viewing rendered pages is reported. Without this, both absolute completion rates and model rankings risk being artifacts of the specific LLM feedback style rather than evidence about underspecified intent.
Authors: We agree that no human baseline or inter-rater study is present in the manuscript. The protocol deliberately employs an LLM for feedback generation to ensure full reproducibility and scalability across all 50 tasks and 784 criteria; human feedback would introduce non-deterministic variability and prohibitive cost for repeated evaluations. Feedback generation is constrained to the concrete outcomes returned by the UI Agent's browser tests (e.g., specific assertion failures), rather than open-ended interpretation of rendered pages. This design choice allows the benchmark to isolate differences in how code agents incorporate natural-language signals over multiple rounds. While a human validation study would strengthen claims of ecological validity, its absence does not render the reported separations meaningless within the defined closed-loop setting. revision: no
-
Referee: [§5] §5 (Results): The headline separation of 38 pp in weighted Task Pass Rate and the 52% ceiling for the best model after three rounds are presented as evidence of benchmark utility, yet these quantities inherit the unvalidated feedback mechanism; any systematic difference in feedback precision or scope between the User LLM and actual users would directly alter both the reported numbers and the cross-model ordering.
Authors: The 38-point spread and 52% ceiling are results obtained under the fixed Asuka-Bench protocol, including the specific User LLM. They demonstrate that even with consistent, test-derived feedback, current agents exhibit substantial differences in repair capability and remain far from saturation. We do not claim the numbers generalize directly to human users; any change in feedback style would affect absolute scores. However, because the same feedback generator is applied uniformly to all models, the relative ordering reflects differences in agent architectures' ability to handle iterative, underspecified signals. We will add a short paragraph in the limitations section noting this design decision and its implications for interpreting absolute performance. revision: partial
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper defines Asuka-Bench explicitly with 50 tasks, 784 criteria, and a closed-loop protocol using Code Agent, UI Agent, and User LLM. Reported metrics (weighted Task Pass Rate varying 38 pp, max 52% completion) are computed outcomes from executing the 8 LLMs on these fixed tasks across rounds. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation of the separation claims; results follow from running the stated protocol on the stated tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The closed loop using UI Agent test execution and User LLM feedback accurately represents real user refinement of underspecified web intents.
Reference graph
Works this paper leans on
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webmmu: A benchmark for multimodal multilingual website understanding and code generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[9]
Advances in neural information processing systems , volume=
Web2code: A large-scale webpage-to-code dataset and evaluation framework for multimodal llms , author=. Advances in neural information processing systems , volume=
-
[10]
Design2code: Benchmarking multimodal code generation for automated front-end engineering , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[11]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Webuibench: a comprehensive benchmark for evaluating multimodal large language models in webui-to-code , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[13]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Webvoyager: Building an end-to-end web agent with large multimodal models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
MiniMax-01: Scaling Foundation Models with Lightning Attention
MiniMax-01: Scaling Foundation Models with Lightning Attention , author=. arXiv preprint arXiv:2501.08313 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2025 , howpublished=
Introducing GPT-5.4 , author=. 2025 , howpublished=
2025
-
[20]
2025 , howpublished=
Gemini 3.1 Pro , author=. 2025 , howpublished=
2025
-
[21]
2025 , howpublished=
Introducing Claude Sonnet 4.6 , author=. 2025 , howpublished=
2025
-
[22]
2025 , howpublished=
Seed 2.0 , author=. 2025 , howpublished=
2025
-
[23]
2025 , howpublished=
MiniMax-M2.7 , author=. 2025 , howpublished=
2025
-
[24]
NeurIPS , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. NeurIPS , year=
-
[25]
NeurIPS , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. NeurIPS , year=
-
[26]
Zhang, Chenchen and Li, Yuhang and Xu, Can and others , booktitle=
-
[27]
Anthropic . 2025. Introducing claude sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6. Accessed: 2026
2025
-
[28]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and 1 others. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Rabiul Awal, Mahsa Massoud, Aarash Feizi, Zichao Li, Suyuchen Wang, Christopher Pal, Aishwarya Agrawal, David Vazquez, Siva Reddy, Juan A Rodriguez, and 1 others. 2025. Webmmu: A benchmark for multimodal multilingual website understanding and code generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages ...
2025
-
[30]
ByteDance Seed Team . 2025. Seed 2.0. https://seed.bytedance.com/en/seed2. Accessed: 2026
2025
-
[31]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [32]
-
[33]
Google DeepMind . 2025. Gemini 3.1 pro. https://deepmind.google/models/gemini/pro/. Accessed: 2026
2025
-
[34]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. Webvoyager: Building an end-to-end web agent with large multimodal models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6864--6890
2024
-
[35]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [36]
-
[37]
Zhiyu Lin, Zhengda Zhou, Zhiyuan Zhao, Tianrui Wan, Yilun Ma, Junyu Gao, and Xuelong Li. 2025. Webuibench: a comprehensive benchmark for evaluating multimodal large language models in webui-to-code. In Findings of the Association for Computational Linguistics: ACL 2025, pages 15780--15797
2025
- [38]
-
[39]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-refine: Iterative refinement with self-feedback. In NeurIPS
2023
-
[40]
MiniMax . 2025. Minimax-m2.7. https://huggingface.co/MiniMaxAI/MiniMax-M2.7. Accessed: 2026
2025
-
[41]
OpenAI . 2025. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/. Accessed: 2026
2025
-
[42]
Qwen Team . 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. In NeurIPS
2023
-
[44]
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. 2025. Design2code: Benchmarking multimodal code generation for automated front-end engineering. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pag...
2025
-
[45]
Team GLM . 2024. https://arxiv.org/abs/2406.12793 Chatglm: A family of large language models from glm-130b to glm-4 all tools . arXiv preprint arXiv:2406.12793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, and 5 others. 2024. https://arxiv.org/abs/2407.16741 Openhands: An open platform for ai software developer...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [47]
- [48]
-
[49]
Sukmin Yun, Haokun Lin, Rusiru Thushara, Mohammad Q Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, and 1 others. 2024. Web2code: A large-scale webpage-to-code dataset and evaluation framework for multimodal llms. Advances in neural information processing systems, 37:112134--112157
2024
- [50]
- [51]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.