Merging model-based control with multi-agent reinforcement learning for multi-agent cooperative teaming strategies
Pith reviewed 2026-06-28 01:45 UTC · model grok-4.3
The pith
Merging multi-agent reinforcement learning with model-predictive control produces safe cooperative actions that reach 100 percent hardware success where pure neural policies reach only 60 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
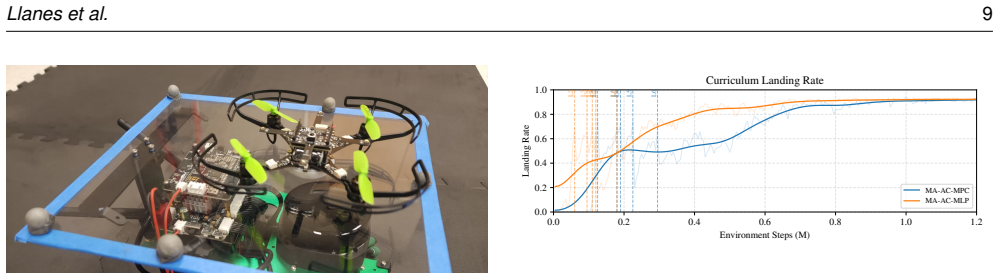
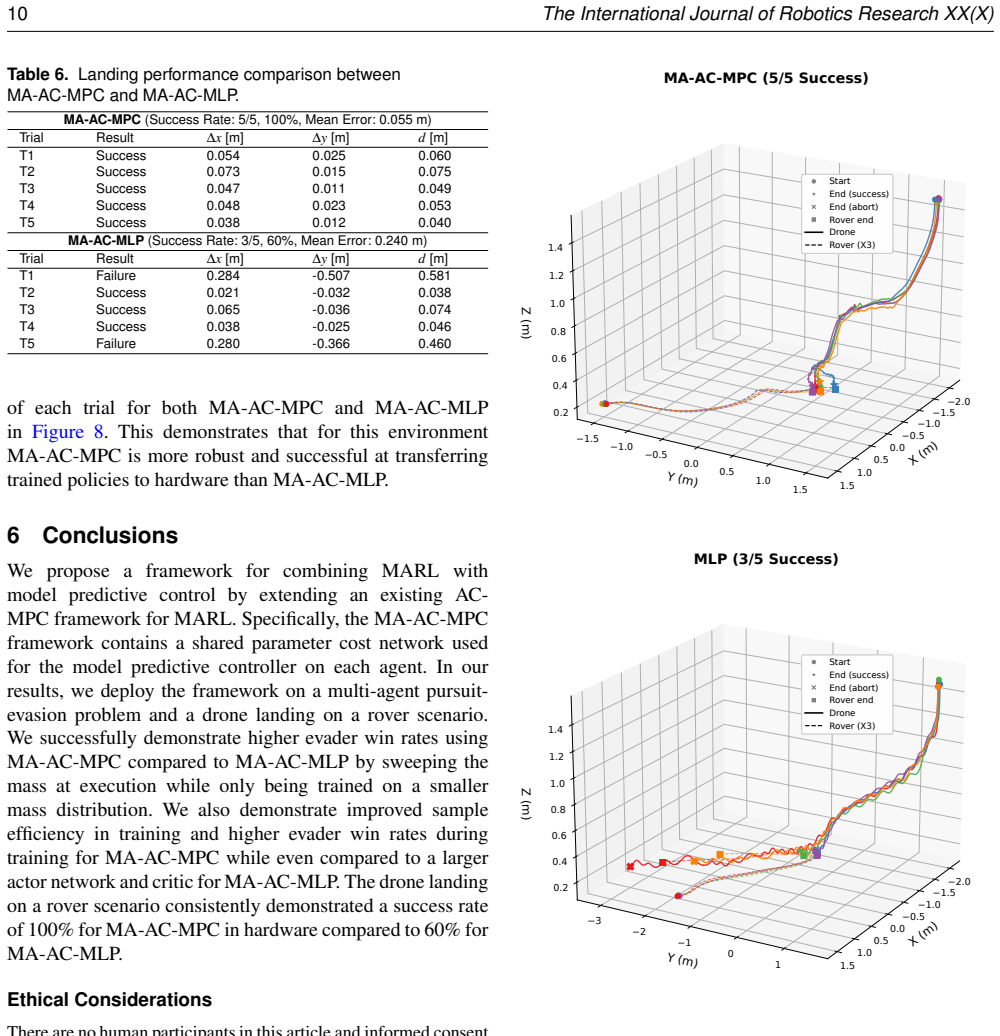
The multi-agent actor-critic model predictive control (MA-AC-MPC) algorithm couples a learned multi-agent policy with short-horizon model-predictive control to generate safe, dynamically feasible actions; in hardware it achieves a 100 percent success rate on a cooperative drone-rover landing task versus 60 percent for the multi-layer perceptron baseline, and it maintains performance against augmented proportional navigation in pursuit-evasion scenarios.
What carries the argument
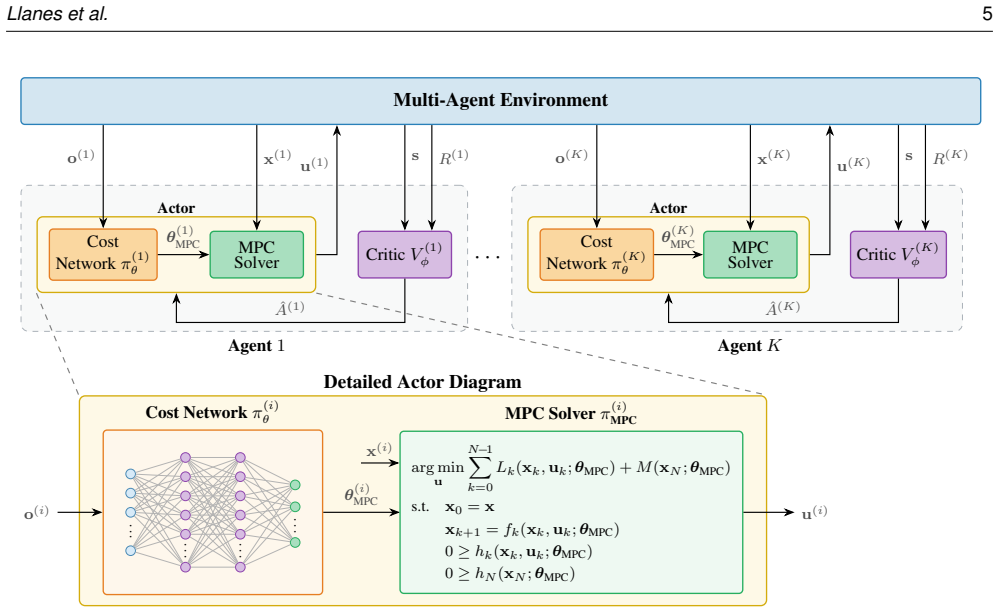
The MA-AC-MPC algorithm, which places the learned multi-agent policy inside a receding-horizon model-predictive controller that replans feasible trajectories at each step.
If this is right
- Actions generated by MA-AC-MPC remain both cooperative across long horizons and dynamically feasible within short replanning windows.
- The same controller succeeds against established adversarial laws such as augmented proportional navigation.
- Heterogeneous teams achieve repeatable, successful hardware landings without further policy retraining.
Where Pith is reading between the lines
- The separation of long-horizon cooperation learning from short-horizon safety enforcement may reduce the reward-shaping burden typical in pure MARL.
- The same coupling structure could be tested on additional cooperative tasks such as formation flight or joint manipulation where dynamic constraints are tight.
Load-bearing premise
A short-horizon model-predictive controller can be stably coupled to the learned multi-agent policy without introducing instability or requiring extensive additional tuning.
What would settle it
A hardware trial in which the MA-AC-MPC controller produces control inputs that violate vehicle dynamics or cause collisions during the landing maneuver.
Figures

read the original abstract
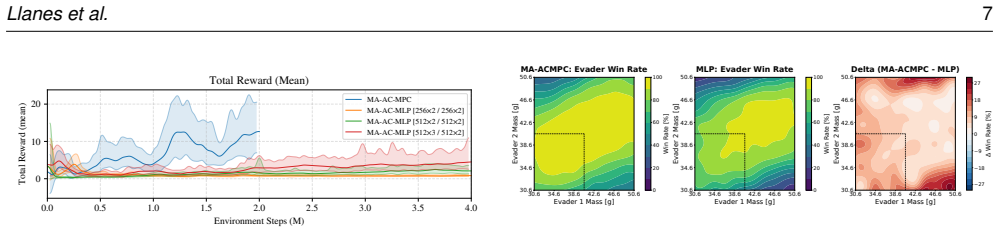
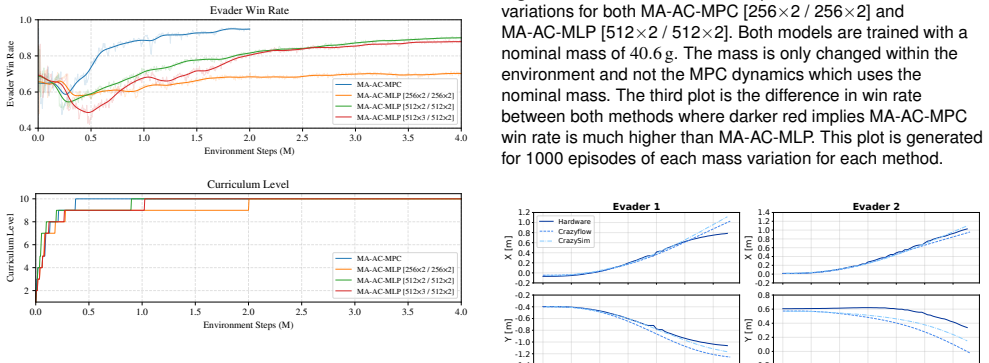
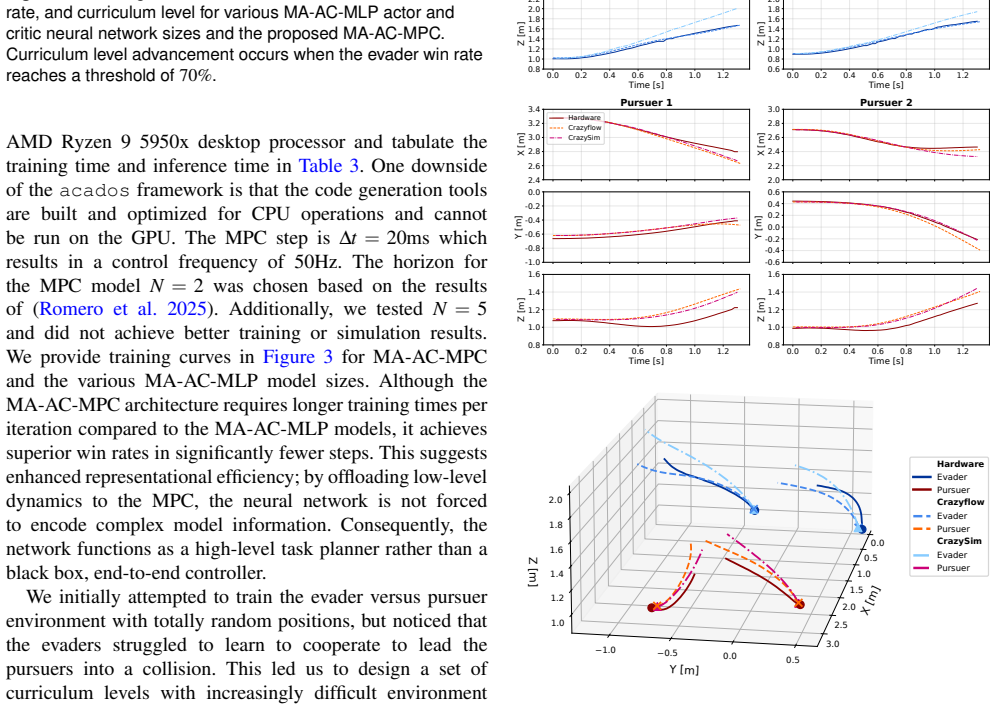
In this work, we propose a framework that combines multi-agent reinforcement learning (MARL) with model-based control to achieve safe, dynamically feasible actions in cooperative multi-agent tasks. Multi-agent reinforcement learning provides the advantage of learning cooperative policies for multi-agent teams from discrete non-differentiable rewards in a long planning horizon. Model-predictive control is robust and offers safe, dynamically feasible actions in a fast replanning framework for short horizons. We propose an algorithm that extends actor-critic model predictive control for MARL which we refer to as multi-agent actor-critic model predictive control (MA-AC-MPC). We demonstrate the capabilities of this algorithm by applying it to a multi-agent pursuit-evasion scenario. Specifically, we compare the evader team's strategy using the MA-AC-MPC model and a multi-layer perceptron model (MA-AC-MLP). The pursuer team uses augmented proportional navigation as it is accepted as an advanced adversarial control law. We also provide an example with a heterogeneous environment where a drone and omni-wheeled rover cooperate to achieve repeatable and successful landing with 100% success rate in hardware for MA-AC-MPC compared to 60% for MA-AC-MLP. We demonstrate the robustness of the proposed MA-AC-MPC algorithm in hardware for both environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MA-AC-MPC, an extension of actor-critic model-predictive control to multi-agent reinforcement learning settings. It combines MARL for learning cooperative long-horizon policies from non-differentiable rewards with short-horizon MPC for generating safe, dynamically feasible actions. The approach is demonstrated in a multi-agent pursuit-evasion scenario (evader team vs. augmented proportional navigation pursuers) and a heterogeneous drone-rover landing task, where MA-AC-MPC achieves 100% hardware success compared to 60% for MA-AC-MLP.
Significance. If the coupling between the learned multi-agent policy and the MPC layer proves stable under model mismatch and varying replanning rates, the framework could offer a practical route to safe cooperative behaviors in robotics without requiring fully differentiable rewards or long-horizon optimization. The hardware demonstration in a heterogeneous team is a positive step, but the absence of supporting analysis limits assessment of generality.
major comments (2)
- [Abstract] Abstract: The central claim that MA-AC-MPC produces safe, dynamically feasible cooperative actions rests on the 100% vs. 60% hardware landing success comparison, yet the text supplies no number of trials, variance, or statistical test; without these, the performance difference cannot be distinguished from tuning or sampling effects.
- [Abstract] Abstract and hardware results: No analysis is provided on the stability of feeding the actor-critic output into the short-horizon MPC (e.g., sensitivity to model mismatch, replanning frequency, or closed-loop eigenvalues), which directly governs whether the reported success generalizes beyond the specific tested conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that MA-AC-MPC produces safe, dynamically feasible cooperative actions rests on the 100% vs. 60% hardware landing success comparison, yet the text supplies no number of trials, variance, or statistical test; without these, the performance difference cannot be distinguished from tuning or sampling effects.
Authors: We agree that the hardware results require additional statistical detail to support the reported success rates. In the revised manuscript we will specify the number of trials conducted for each method, report observed variance or standard deviation, and include a statistical test (e.g., two-proportion z-test) to evaluate whether the 100% versus 60% difference is significant. These details will be added to the abstract and the hardware results section. revision: yes
-
Referee: [Abstract] Abstract and hardware results: No analysis is provided on the stability of feeding the actor-critic output into the short-horizon MPC (e.g., sensitivity to model mismatch, replanning frequency, or closed-loop eigenvalues), which directly governs whether the reported success generalizes beyond the specific tested conditions.
Authors: We acknowledge that the manuscript lacks a dedicated analysis of the learned policy to MPC interface. While the hardware demonstrations show reliable performance under the tested conditions, we agree this restricts assessment of broader applicability. In revision we will add simulation-based sensitivity studies on model mismatch and replanning frequency, together with a qualitative discussion of observed stability margins. A full closed-loop eigenvalue analysis lies outside the present scope and will not be included. revision: partial
Circularity Check
No circularity; empirical validation of MA-AC-MPC extension stands independent of inputs.
full rationale
The paper proposes MA-AC-MPC as an extension of actor-critic MPC to the multi-agent setting and validates it via hardware experiments (100% landing success for MA-AC-MPC vs 60% for MA-AC-MLP). No equations, fitted parameters, or self-citations are presented that reduce the performance claims to quantities defined by the authors' own inputs or prior results. The derivation consists of an algorithmic combination followed by direct empirical comparison; no self-definitional, fitted-input-called-prediction, or uniqueness-imported patterns appear. The central claims rest on observable hardware outcomes rather than any closed mathematical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Comprehensive Survey of Multiagent Reinforcement Learning , year=
Busoniu, Lucian and Babuska, Robert and De Schutter, Bart , journal=. A Comprehensive Survey of Multiagent Reinforcement Learning , year=
-
[2]
Development of an industrial Internet of Things (IIoT) based smart robotic warehouse management system , author=
-
[3]
and Katz, Benjamin and Di Carlo, Jared and Wensing, Patrick M
Bledt, Gerardo and Powell, Matthew J. and Katz, Benjamin and Di Carlo, Jared and Wensing, Patrick M. and Kim, Sangbae , booktitle=. MIT Cheetah 3: Design and Control of a Robust, Dynamic Quadruped Robot , year=
-
[4]
Champion-level drone racing using deep reinforcement learning , journal=
Kaufmann, Elia and Bauersfeld, Leonard and Loquercio, Antonio and M. Champion-level drone racing using deep reinforcement learning , journal=. 2023 , month=. doi:10.1038/s41586-023-06419-4 , url=
-
[5]
Toward a Fully Autonomous UAV: Research Platform for Indoor and Outdoor Urban Search and Rescue , year=
Tomic, Teodor and Schmid, Korbinian and Lutz, Philipp and Domel, Andreas and Kassecker, Michael and Mair, Elmar and Grixa, Iris Lynne and Ruess, Felix and Suppa, Michael and Burschka, Darius , journal=. Toward a Fully Autonomous UAV: Research Platform for Indoor and Outdoor Urban Search and Rescue , year=
-
[6]
Samvelyan, Mikayel and Rashid, Tabish and Schroeder de Witt, Christian and Farquhar, Gregory and Nardelli, Nantas and Rudner, Tim G. J. and Hung, Chia-Man and Torr, Philip H. S. and Foerster, Jakob and Whiteson, Shimon , title =. Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages =. 2019 , isbn =
2019
-
[7]
Stanley: The Robot That Won the DARPA Grand Challenge
Thrun, Sebastian and Montemerlo, Mike and Dahlkamp, Hendrik and Stavens, David and Aron, Andrei and Diebel, James and Fong, Philip and Gale, John and Halpenny, Morgan and Hoffmann, Gabriel and Lau, Kenny and Oakley, Celia and Palatucci, Mark and Pratt, Vaughan and Stang, Pascal and Strohband, Sven and Dupont, Cedric and Jendrossek, Lars-Erik and Koelen, C...
2005
-
[8]
and Blackmore, Lars , journal=
Açıkmeşe, Behçet and Carson, John M. and Blackmore, Lars , journal=. Lossless Convexification of Nonconvex Control Bound and Pointing Constraints of the Soft Landing Optimal Control Problem , year=
-
[9]
IEEE Transactions on Robotics , year=
Actor-Critic Model Predictive Control: Differentiable Optimization meets Reinforcement Learning for Agile Flight , author=. IEEE Transactions on Robotics , year=
-
[10]
and Wu, Xinzhou , booktitle=
Lubars, Joseph and Gupta, Harsh and Chinchali, Sandeep and Li, Liyun and Raja, Adnan and Srikant, R. and Wu, Xinzhou , booktitle=. Combining Reinforcement Learning with Model Predictive Control for On-Ramp Merging , year=
-
[11]
2025 , eprint=
Synthesis of Model Predictive Control and Reinforcement Learning: Survey and Classification , author=. 2025 , eprint=
2025
-
[12]
Safe Reinforcement Learning Using Robust MPC , year=
Zanon, Mario and Gros, Sebastien , journal=. Safe Reinforcement Learning Using Robust MPC , year=
-
[13]
2024 , eprint=
DeepSafeMPC: Deep Learning-Based Model Predictive Control for Safe Multi-Agent Reinforcement Learning , author=. 2024 , eprint=
2024
-
[14]
Zico , title =
Amos, Brandon and Rodriguez, Ivan Dario Jimenez and Sacks, Jacob and Boots, Byron and Kolter, J. Zico , title =. Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages =. 2018 , publisher =
2018
-
[15]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Yu, Chao and Velu, Akash and Vinitsky, Eugene and Gao, Jiaxuan and Wang, Yu and Bayen, Alexandre and Wu, Yi , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[16]
and Drew, Daniel S
Lambert, Nathan O. and Drew, Daniel S. and Yaconelli, Joseph and Levine, Sergey and Calandra, Roberto and Pister, Kristofer S. J. , journal=. Low-Level Control of a Quadrotor With Deep Model-Based Reinforcement Learning , year=
-
[17]
and Yuan, Zhaocong and Zhou, Siqi and Panerati, Jacopo and Schoellig, Angela P
Brunke, Lukas and Greeff, Melissa and Hall, Adam W. and Yuan, Zhaocong and Zhou, Siqi and Panerati, Jacopo and Schoellig, Angela P. Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning. Annual Review of Control, Robotics, and Autonomous Systems. 2022. doi:https://doi.org/10.1146/annurev-control-042920-020211
-
[18]
Proceedings of the 6th Annual Learning for Dynamics & Control Conference , pages =
Hoffmann, Jasper and Clausen, Diego Fernandez and Brosseit, Julien and Bernhard, Julian and Esterle, Klemens and Werling, Moritz and Karg, Michael and B\". Proceedings of the 6th Annual Learning for Dynamics & Control Conference , pages =. 2024 , editor =
2024
-
[19]
Learning When to Trust the Expert for Guided Exploration in
Felix Schulz and Jasper Hoffmann and Yuan Zhang and Joschka Boedecker , booktitle=. Learning When to Trust the Expert for Guided Exploration in. 2024 , url=
2024
-
[20]
A Painless Deterministic Policy Gradient Method for Learning-based MPC , year=
Anand, Akhil S and Reinhardt, Dirk and Sawant, Shambhuraj and Gravdahl, Jan Tommy and Gros, Sebastien , booktitle=. A Painless Deterministic Policy Gradient Method for Learning-based MPC , year=
-
[21]
Imitation Learning from Nonlinear MPC via the Exact Q-Loss and its Gauss-Newton Approximation , year=
Ghezzi, Andrea and Hoffman, Jasper and Frey, Jonathan and Boedecker, Joschka and Diehl, Moritz , booktitle=. Imitation Learning from Nonlinear MPC via the Exact Q-Loss and its Gauss-Newton Approximation , year=
-
[22]
Policy Search for Model Predictive Control With Application to Agile Drone Flight , year=
Song, Yunlong and Scaramuzza, Davide , journal=. Policy Search for Model Predictive Control With Application to Agile Drone Flight , year=
-
[23]
Shankar Sastry and Claire Tomlin , keywords =
Anil Aswani and Humberto Gonzalez and S. Shankar Sastry and Claire Tomlin , keywords =. Provably safe and robust learning-based model predictive control , journal =. 2013 , issn =. doi:https://doi.org/10.1016/j.automatica.2013.02.003 , url =
-
[24]
Predictive Control with Learning-Based Terminal Costs Using Approximate Value Iteration , journal =
Francisco Moreno-Mora and Lukas Beckenbach and Stefan Streif , keywords =. Predictive Control with Learning-Based Terminal Costs Using Approximate Value Iteration , journal =. 2023 , note =. doi:https://doi.org/10.1016/j.ifacol.2023.10.1320 , url =
-
[25]
and Diehl, Moritz , journal=
Reiter, Rudolf and Ghezzi, Andrea and Baumgärtner, Katrin and Hoffmann, Jasper and McAllister, Robert D. and Diehl, Moritz , journal=. AC4MPC: Actor-Critic Reinforcement Learning for Guiding Model Predictive Control , year=
-
[26]
DiffTune-MPC: Closed-Loop Learning for Model Predictive Control , year=
Tao, Ran and Cheng, Sheng and Wang, Xiaofeng and Wang, Shenlong and Hovakimyan, Naira , journal=. DiffTune-MPC: Closed-Loop Learning for Model Predictive Control , year=
-
[27]
Annual Conference on Learning for Dynamics and Control , author =
Safe Reinforcement Learning with Chance-constrained Model Predictive Control: , url =. Annual Conference on Learning for Dynamics and Control , author =
-
[28]
Proceedings of Robotics: Science and Systems , YEAR =
Alex Oshin AND Hassan Almubarak AND Evangelos Theodorou , TITLE =. Proceedings of Robotics: Science and Systems , YEAR =
-
[29]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Lowe, Ryan and Wu, Yi and Tamar, Aviv and Harb, Jean and Abbeel, Pieter and Mordatch, Igor , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[30]
Mallick and F
S. Mallick and F. Airaldi and A. Dabiri and B. Multi-agent reinforcement learning via distributed. Automatica , volume=. 2024 , doi=
2024
-
[31]
2024 , eprint=
An Introduction to Centralized Training for Decentralized Execution in Cooperative Multi-Agent Reinforcement Learning , author=. 2024 , eprint=
2024
-
[32]
Gronauer, Sven and Diepold, Klaus , title=. Artificial Intelligence Review , year=. doi:10.1007/s10462-021-09996-w , url=
-
[33]
and Amato, Christopher , title =
Oliehoek, Frans A. and Amato, Christopher , title =. 2016 , isbn =
2016
-
[34]
2024 , eprint=
Fully Decentralized Cooperative Multi-Agent Reinforcement Learning: A Survey , author=. 2024 , eprint=
2024
-
[35]
Pedro P. Santos and Diogo S. Carvalho and Miguel Vasco and Alberto Sardinha and Pedro A. Santos and Ana Paiva and Francisco S. Melo , keywords =. Centralized training with hybrid execution in multi-agent reinforcement learning via predictive observation imputation , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.artint.2025.104404 , url =
-
[36]
Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =
Sukhbaatar, Sainbayar and Szlam, Arthur and Fergus, Rob , title =. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =. 2016 , isbn =
2016
-
[37]
and Assael, Yannis M
Foerster, Jakob N. and Assael, Yannis M. and de Freitas, Nando and Whiteson, Shimon , title =. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =. 2016 , isbn =
2016
-
[38]
and Egorov, Maxim and Kochenderfer, Mykel
Gupta, Jayesh K. and Egorov, Maxim and Kochenderfer, Mykel. Cooperative Multi-agent Control Using Deep Reinforcement Learning. Autonomous Agents and Multiagent Systems. 2017
2017
-
[39]
2025 , eprint=
Differentiable Nonlinear Model Predictive Control , author=. 2025 , eprint=
2025
-
[40]
2022 , eprint=
Differentiable Optimal Control via Differential Dynamic Programming , author=. 2022 , eprint=
2022
-
[41]
2025 , eprint=
Differentiable Model Predictive Control on the GPU , author=. 2025 , eprint=
2025
-
[42]
2021 , eprint=
Pontryagin Differentiable Programming: An End-to-End Learning and Control Framework , author=. 2021 , eprint=
2021
-
[43]
Leveraging Proximal Optimization for Differentiating Optimal Control Solvers , year=
Bounou, Oumayma and Ponce, Jean and Carpentier, Justin , booktitle=. Leveraging Proximal Optimization for Differentiating Optimal Control Solvers , year=
-
[44]
Mathematical Programming Computation , Year =
acados -- a modular open-source framework for fast embedded optimal control , Author =. Mathematical Programming Computation , Year =
-
[45]
Fast integrators with sensitivity propagation for use in
Frey, Jonathan and De Schutter, Jochem and Diehl, Moritz , Booktitle = ECC, Year =. Fast integrators with sensitivity propagation for use in
-
[46]
doi:10.5281/zenodo.17244101 , url =
Leonard Fichtner and dirkpr and JasperHoffmann and Filippo Airaldi and Jonathan Frey and Josip Kir Hromatko and Katrin Baumgaertner and Mazen Amria and RudolfReiter and Shambhuraj Sawant , title =. doi:10.5281/zenodo.17244101 , url =
-
[47]
and Jensen, Spencer W
Llanes, Christian and Williams, Kyle A. and Jensen, Spencer W. and Coogan, Samuel , title =. To appear in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =
-
[48]
2018 , eprint=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. 2018 , eprint=
2018
-
[49]
skrl: Modular and Flexible Library for Reinforcement Learning , journal =
Antonio Serrano. skrl: Modular and Flexible Library for Reinforcement Learning , journal =. 2023 , volume =
2023
-
[50]
2009 , eprint=
Multi-Agent Model Predictive Control: A Survey , author=. 2009 , eprint=
2009
-
[51]
and Hua, Yufei and Goudar, Abhishek and Zhou, SiQi and Schoellig, Angela P
Schuck, Martin and Rath, Marcel P. and Hua, Yufei and Goudar, Abhishek and Zhou, SiQi and Schoellig, Angela P. , title =. 2026 , note =
2026
-
[52]
Preiss* and Wolfgang H\"onig* and Gaurav S
James A. Preiss* and Wolfgang H\"onig* and Gaurav S. Sukhatme and Nora Ayanian , title =. 2017 , url =. doi:10.1109/ICRA.2017.7989376 , note =
-
[53]
CrazySim: A Software-in-the-Loop Simulator for the Crazyflie Nano Quadrotor , year=
Llanes, Christian and Kakish, Zahi and Williams, Kyle and Coogan, Samuel , booktitle=. CrazySim: A Software-in-the-Loop Simulator for the Crazyflie Nano Quadrotor , year=
-
[54]
N. A. Shneydor , title =
-
[55]
Paul Zarchan , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.