TAM: Torque Adaptation Module for Robust Motion Transfer in Manipulation
Pith reviewed 2026-06-28 01:13 UTC · model grok-4.3
The pith
A learned torque adapter trained only in simulation enables zero-shot transfer of manipulation policies to real robots with unknown dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TAM is a module that adapts torque commands to match an ideal robot's behavior by embedding proprioceptive history into a latent state and computing residual corrections, trained via multi-robot pretraining and robot-specific fine-tuning in randomized simulation, allowing the same weights to adapt policies with different action spaces and enabling robust zero-shot real-robot execution on dynamic manipulation tasks.
What carries the argument
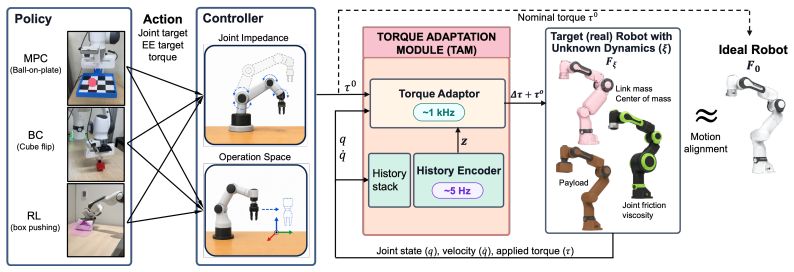
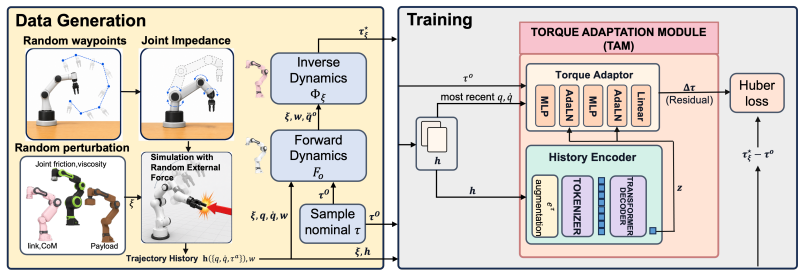
The Torque Adaptation Module (TAM), consisting of a history encoder that embeds proprioceptive history into a latent state and a torque adaptor that computes residual torque corrections, operating independently of policy observations and action space.
If this is right
- TAM can be reused across policies with different action spaces such as joint targets, end-effector targets, or direct torques.
- Training TAM in simulation with multi-robot pretraining and fine-tuning eliminates the need for domain randomization in the task policies themselves.
- Zero-shot real-robot performance improves over online system identification and RMA baselines on vision-based box pushing, flip policy, and MPC ball-on-plate balancing.
- Policies trained without randomization can still achieve robust dynamic manipulation when paired with a TAM.
Where Pith is reading between the lines
- If TAM generalizes as claimed, it could reduce the cost of deploying learned policies on new robot hardware by avoiding real-robot data collection.
- Extensions might include testing TAM on a wider range of contact-rich tasks or combining it with other adaptation methods for even greater robustness.
- Since TAM depends only on proprioception, it might apply to other control interfaces beyond torque commands.
Load-bearing premise
Randomized simulation with multi-robot pretraining and robot-specific fine-tuning produces a TAM that generalizes to real-robot dynamics, unknown payloads, and contact-rich interactions without any real-robot data or policy retraining.
What would settle it
Deploying the same TAM on a real robot with significantly different dynamics or a novel payload and observing whether motion tracking succeeds or fails in contact-rich tasks.
Figures

read the original abstract
A policy tuned for one robot often behaves differently on another, whether due to the sim-to-real gap, unknown payloads, or the differing dynamics of two instances of the same robot. In contact-rich, dynamic manipulation, even small motion discrepancies can result in failure to track reference motion, since they disrupt the timing and modes of contact. Common remedies, such as domain randomization or system identification, either produce overly conservative task policies or require data that must be recollected for each robot or payload. We introduce the Torque Adaptation Module (TAM), a learned module that adapts the torque commands sent to the robot to match the behavior of an ideal robot. TAM operates between the low-level controller that tracks the policy's actions and the robot's torque interface. It includes a history encoder that embeds proprioceptive history into a latent state and a torque adaptor that computes residual torque corrections. Because TAM depends only on proprioceptive history and not on policy observations, or the action space, the same TAM weights can be reused to adapt policies with different action spaces (joint targets, end-effector targets, or direct torques). The policies themselves do not need to be trained with domain randomization of robot parameters. Instead, we offload the need for domain randomization to TAM by training it entirely in randomized simulation, using multi-robot pretraining followed by a robot-specific fine-tuning step that still requires no real-robot data. We evaluate TAM zero-shot on a real Franka Panda robot across dynamic manipulation tasks that include a vision-based box pushing policy (from RL), a flip policy (from BC), and an MPC ball-on-plate balancing. Our experiments show that TAM improves zero-shot real-robot execution compared to online system identification and RMA baselines and enables robust dynamic manipulation performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Torque Adaptation Module (TAM), a learned module placed between the low-level controller and robot torque interface. TAM uses a proprioceptive history encoder to produce a latent state and a torque adaptor to output residual corrections. It is trained entirely in randomized simulation via multi-robot pretraining followed by robot-specific fine-tuning (no real-robot data or policy retraining required) and is policy-agnostic by construction. The central claim is that TAM enables improved zero-shot real-robot execution of dynamic manipulation policies (vision-based box pushing from RL, flip from BC, MPC ball-on-plate) on a Franka Panda relative to online system identification and RMA baselines.
Significance. If the reported zero-shot gains are reproducible and statistically supported, TAM would provide a practical, reusable mechanism for handling sim-to-real gaps, payload variation, and instance-specific dynamics without per-policy domain randomization or hardware-specific data collection. This could reduce the engineering cost of deploying manipulation policies across robot instances.
major comments (1)
- [Abstract] Abstract: the claim that TAM 'improves zero-shot real-robot execution compared to online system identification and RMA baselines' is load-bearing for the contribution, yet the abstract supplies no quantitative metrics, error bars, task success rates, or statistical tests; without these in the results section the strength of the central claim cannot be assessed.
minor comments (2)
- The description of the multi-robot pretraining step would benefit from explicit enumeration of the robots used and the exact randomization ranges applied to inertial and friction parameters.
- Notation for the latent state produced by the history encoder and the precise input/output dimensions of the torque adaptor should be defined in a dedicated methods subsection for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the feedback. We address the concern about quantitative support for the central claim below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that TAM 'improves zero-shot real-robot execution compared to online system identification and RMA baselines' is load-bearing for the contribution, yet the abstract supplies no quantitative metrics, error bars, task success rates, or statistical tests; without these in the results section the strength of the central claim cannot be assessed.
Authors: We agree the abstract would be strengthened by including quantitative metrics. In the revision we will add key results (task success rates for box pushing, flip, and ball-on-plate tasks; relative improvements over the system-ID and RMA baselines; and any reported error bars or statistical tests) directly into the abstract while preserving its length. The results section already presents these metrics in detail (tables and figures with per-task success rates, baseline comparisons, and variance information); the abstract revision will simply surface the most salient numbers for immediate assessment of the claim. revision: yes
Circularity Check
No significant circularity; method is self-contained
full rationale
The paper describes a learned module (TAM) trained entirely in randomized simulation via multi-robot pretraining and robot-specific fine-tuning, then evaluated zero-shot on physical hardware. No derivation reduces to its own inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing claims rest on self-citations. The central result is an empirical performance comparison (TAM vs. baselines on real-robot tasks), which is externally falsifiable and does not rely on internal redefinition or renaming of known results. The approach is internally consistent without circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Randomized simulation sufficiently captures the distribution of real-robot dynamics, payloads, and contact events for the adaptation module to generalize.
invented entities (1)
-
Torque Adaptation Module (TAM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Z. Xie, X. Da, M. van de Panne, B. Babich, and A. Garg. Dynamics randomization revisited: A case study for quadrupedal locomotion. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 4955–4961, 2021. doi:10.1109/ICRA48506.2021. 9560837. 1Code, the trained TAM weights for the Franka Panda, and the simulation training...
-
[2]
C. Gaz, M. Cognetti, A. Oliva, P. R. Giordano, and A. De Luca. Dynamic identification of the Franka Emika Panda robot with retrieval of feasible parameters using penalty-based optimization.IEEE Robotics and Automation Letters, 4(4):4147–4154, 2019. doi:10.1109/ LRA.2019.2931248
arXiv 2019
-
[3]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 1–8, 2018. doi:10.1109/ICRA.2018.8460528
-
[4]
H. W. Stone, A. C. Sanderson, and C. P. Neuman. Arm signature identification. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 41–48, April 1986
1986
-
[5]
S. Farsoni, C. T. Landi, F. Ferraguti, C. Secchi, and M. Bonf`e. Real-time identification of robot payload using a multirate quaternion-based kalman filter and recursive total least-squares. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 2103–2109, 2018. doi:10.1109/ICRA.2018.8461167
-
[6]
Swevers, C
J. Swevers, C. Ganseman, D. B. Tukel, J. De Schutter, and H. Van Brussel. Optimal robot excitation and identification.IEEE Transactions on Robotics and Automation, 13(5):730–740,
-
[7]
doi:10.1109/70.631234
-
[8]
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter. Learn- ing agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019. doi:10.1126/scirobotics.aau5872
-
[9]
Zhang, S
X. Zhang, S. Liu, P. Huang, W. J. Han, Y . Lyu, M. Xu, and D. Zhao. Dynamics as prompts: In-context learning for sim-to-real system identifications. InMARW at AAAI 2025, 2025. URL https://openreview.net/forum?id=8A4lYAGe4u
2025
-
[10]
F. Ramos, R. Possas, and D. Fox. BayesSim: Adaptive domain randomization via probabilistic inference for robotics simulators. InProceedings of Robotics: Science and Systems, Freiburg im Breisgau, Germany, June 2019. doi:10.15607/RSS.2019.XV .029
-
[11]
OpenAI, M. Andrychowicz, B. Baker, M. Chociej, R. J ´ozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba. Learning dexterous in-hand manipulation.The International Jour- nal of Robotics Research, 39(1):3–20, 2020. doi:10.1177/0278364919887447
-
[12]
F. Muratore, F. Ramos, G. Turk, W. Yu, M. Gienger, and J. Peters. Robot learning from randomized simulations: A review.Frontiers in Robotics and AI, 9:799893, 2022. doi:10. 3389/frobt.2022.799893
arXiv 2022
-
[13]
W. Yu, J. Tan, C. K. Liu, and G. Turk. Preparing for the unknown: Learning a universal policy with online system identification. InProceedings of Robotics: Science and Systems, Cambridge, Massachusetts, July 2017. doi:10.15607/RSS.2017.XIII.048
-
[14]
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. In Proceedings of Robotics: Science and Systems, Virtual, July 2021. doi:10.15607/RSS.2021. XVII.011
-
[15]
Z. Fu, X. Cheng, and D. Pathak. Deep whole-body control: Learning a unified policy for manipulation and locomotion. InProceedings of the Conference on Robot Learning (CoRL),
-
[16]
URLhttps://arxiv.org/abs/2210.10044
doi:10.48550/arXiv.2210.10044. URLhttps://arxiv.org/abs/2210.10044
-
[17]
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation
Y . Liang, K. Ellis, and J. F. Henriques. Rapid motor adaptation for robotic manipulator arms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16404–16413, June 2024. doi:10.1109/CVPR52733.2024.01552. 9
-
[18]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, pages 5998–6008, 2017
2017
-
[19]
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam. A time series is worth 64 words: Long- term forecasting with transformers. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://openreview.net/forum?id=Jbdc0vTOcol
2023
-
[20]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville. FiLM: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence,
-
[21]
URLhttps://arxiv.org/abs/1709.07871
-
[22]
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023. doi:10. 1109/ICCV51070.2023.00387
arXiv 2023
-
[23]
Zakka, B
K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y . Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrs, C. Sferrazza, Y . Tassa, and P. Abbeel. MuJoCo Playground. In Robotics: Science and Systems (RSS), 2025. URLhttps://playground.mujoco.org/
2025
-
[24]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProceedings of Robotics: Science and Systems, 2023. doi:10. 15607/RSS.2023.XIX.016
2023
-
[25]
T. Howell, N. Gileadi, S. Tunyasuvunakool, K. Zakka, T. Erez, and Y . Tassa. Predictive sam- pling: Real-time behaviour synthesis with MuJoCo.arXiv preprint arXiv:2212.00541, 2022. doi:10.48550/arXiv.2212.00541. URLhttps://arxiv.org/abs/2212.00541
-
[26]
Zakka, Y
K. Zakka, Y . Tassa, and MuJoCo Menagerie Contributors. MuJoCo Menagerie: A collec- tion of high-quality simulation models for MuJoCo, 2022. URLhttps://github.com/ google-deepmind/mujoco_menagerie
2022
- [27]
-
[28]
N. Fey, G. B. Margolis, M. Peticco, and P. Agrawal. Bridging the sim-to-real gap for athletic loco-manipulation.arXiv preprint arXiv:2502.10894, 2025. doi:10.48550/arXiv.2502.10894. URLhttps://arxiv.org/abs/2502.10894
-
[29]
X. Liu, H. Wang, and L. Yi. DexNDM: Closing the reality gap for dexterous in-hand rotation via joint-wise neural dynamics model.arXiv preprint arXiv:2510.08556, 2025. doi:10.48550/ arXiv.2510.08556
arXiv 2025
-
[30]
System Identification, 1999
Lennart Ljung. System Identification, 1999
1999
-
[31]
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik. In-hand object rotation via rapid motor adaptation. InProceedings of the Conference on Robot Learning (CoRL), pages 1722–1732,
-
[32]
URLhttps://proceedings.mlr.press/v205/qi23a.html
-
[33]
M. Liu, D. Pathak, and A. Agarwal. LocoFormer: Generalist locomotion via long-context adaptation.arXiv preprint arXiv:2509.23745, 2025. doi:10.48550/arXiv.2509.23745
-
[34]
Z. Zhang, J. Guo, C. Chen, J. Wang, C. Lin, Y . Lian, H. Xue, Z. Wang, M. Liu, H. Liu, H. Wang, and L. Yi. Track any motions under any disturbances.arXiv preprint arXiv:2509.13833, 2025. doi:10.48550/arXiv.2509.13833
-
[35]
J.-J. E. Slotine and W. Li. On the adaptive control of robot manipulators.The International Journal of Robotics Research, 6(3):49–59, 1987. doi:10.1177/027836498700600303. 10
-
[36]
S. Lyu, X. Lang, H. Zhao, H. Zhang, P. Ding, and D. Wang. RL2AC: Reinforcement learning- based rapid online adaptive control for legged robot robust locomotion. InProceedings of Robotics: Science and Systems, 2024. doi:10.15607/RSS.2024.XX.060
-
[37]
V . Joukov, V . Bonnet, G. Venture, and D. Kuli´c. Constrained dynamic parameter estimation using the extended kalman filter. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3654–3659, 2015. doi:10.1109/IROS.2015. 7353888
-
[38]
Hanna and P
J. Hanna and P. Stone. Grounded action transformation for robot learning in simulation. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, February 2017
2017
-
[39]
J. P. Hanna, S. Desai, H. Karnan, G. Warnell, and P. Stone. Grounded action transformation for sim-to-real reinforcement learning.Machine Learning, 110:2469–2499, 2021. doi:10.1007/ s10994-021-05982-z
2021
- [40]
- [41]
-
[42]
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 6023–6029, 2019. doi: 10.1109/ICRA.2019.8794127
-
[43]
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbabu, C. Pan, Z. Yi, G. Qu, K. Kitani, J. Hodgins, L. J. Fan, Y . Zhu, C. Liu, and G. Shi. ASAP: Aligning sim- ulation and real-world physics for learning agile humanoid whole-body skills.arXiv preprint arXiv:2502.01143, 2025
arXiv 2025
-
[44]
Jiang, C
Y . Jiang, C. Wang, R. Zhang, J. Wu, and L. Fei-Fei. TRANSIC: Sim-to-real policy transfer by learning from online correction. InProceedings of the Conference on Robot Learning (CoRL),
-
[45]
URLhttps://arxiv.org/abs/2405.10315
-
[46]
E. Todorov, T. Erez, and Y . Tassa. MuJoCo: A physics engine for model-based control. InPro- ceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026–5033, 2012. doi:10.1109/IROS.2012.6386109
-
[47]
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021. URLhttps://arxiv. org/abs/2104.09864
Pith/arXiv arXiv 2021
-
[48]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. PointNet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, 2017
2017
-
[49]
best in this sweep
S. Thrun, W. Burgard, and D. Fox.Probabilistic Robotics. MIT Press, Cambridge, MA, 2005. ISBN 9780262201629. 11 A Related Work A.1 Simulator and Actuator Adaptation A large body of sim-to-real work addresses the reality gap by constructing a simulator tailored to the target setup, and then training a policy or planning actions in that refined simulator fo...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.