MPCoT: Reward-Guided Multi-Path Latent Reasoning for Test-Time Scalable Vision-Language-Action
Pith reviewed 2026-06-28 01:06 UTC · model grok-4.3
The pith
Reward-guided multi-path latent reasoning lets VLA policies deliberate over multiple hypotheses at test time without extra tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
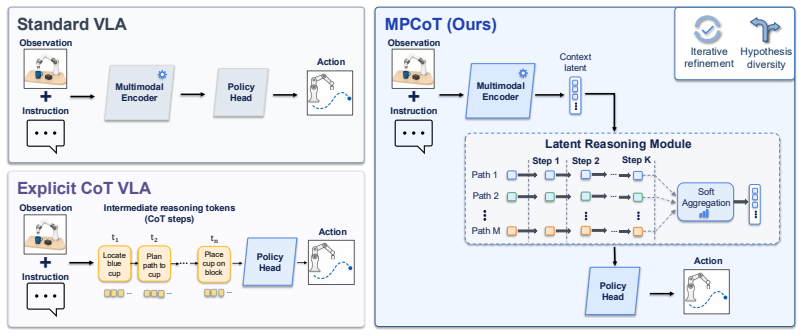
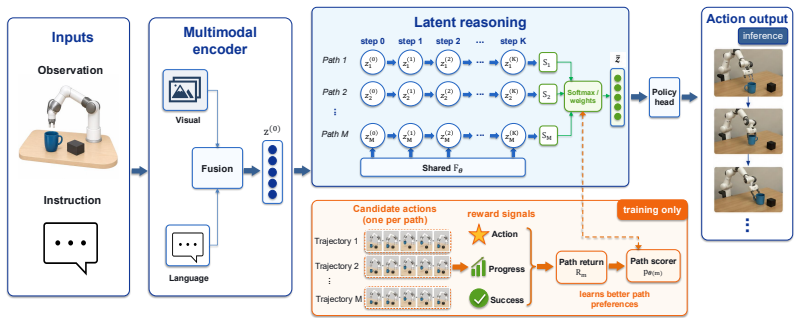
MPCoT initializes M hypotheses, refines them for K weight-tied steps, and softly aggregates them before action decoding. A training-only path-preference objective evaluates candidate action branches with expert-action consistency, world-model/VLM-based progress, and success feedback to align the latent path scorer with downstream execution quality. The method preserves the original 8-step action interface, generates zero reasoning tokens, and exposes configurable inference controls (K,M).
What carries the argument
The reward-guided multi-path latent reasoning process that initializes M hypotheses, refines them over K shared steps, and aggregates before decoding.
If this is right
- Long-horizon task success rates increase on LIBERO and CALVIN under matched evaluation protocols.
- Performance scales with the number of refinement steps K and hypothesis count M.
- Confidence-weighted aggregation of the paths improves final action quality.
- Reward-guided path supervision during training produces a scorer that favors higher-quality execution branches.
Where Pith is reading between the lines
- The separation of training supervision from inference-time path selection could let future work increase test-time compute independently of training cost.
- Similar multi-hypothesis refinement might transfer to other autoregressive control or generation settings where latent deliberation is cheaper than text tokens.
- Dynamic selection of M and K based on input uncertainty could further reduce average compute while preserving the reported gains.
Load-bearing premise
The training-only path-preference objective that scores branches by expert consistency, world-model progress, and success feedback succeeds in aligning the latent scorer with actual execution quality.
What would settle it
Running the LIBERO and CALVIN long-horizon suites with the path-preference objective removed and finding no gain over the one-pass baseline would falsify the central claim.
Figures
read the original abstract
Vision-Language-Action (VLA) policies remain brittle in long-horizon and high-uncertainty control, where one-pass action decoding provides limited inference-time deliberation. Explicit chain-of-thought can increase reasoning depth, but introduces token latency and an indirect text-to-action interface. We propose MPCoT, a reward-guided multi-path latent reasoning framework that initializes $M$ hypotheses, refines them for K weight-tied steps, and softly aggregates them before action decoding. A training-only path-preference objective evaluates candidate action branches with expert-action consistency, world-model/VLM-based progress, and success feedback to align the latent path scorer with downstream execution quality. MPCoT preserves the original 8-step action interface, generates zero reasoning tokens, and exposes configurable inference controls (K,M). Under matched protocols on LIBERO and CALVIN, MPCoT improves long-horizon performance, with ablations confirming depth-width effects, confidence-weighted aggregation, and reward-guided path supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MPCoT, a reward-guided multi-path latent reasoning framework for Vision-Language-Action (VLA) policies. It initializes M hypotheses, refines them over K weight-tied steps, and performs soft aggregation before action decoding. A training-only path-preference objective evaluates branches using expert-action consistency, world-model/VLM-based progress, and success feedback to train the latent path scorer. The paper claims improved long-horizon performance on LIBERO and CALVIN under matched protocols, with ablations confirming depth-width effects, confidence-weighted aggregation, and reward-guided path supervision, while preserving the original 8-step action interface and generating zero reasoning tokens.
Significance. If the alignment between the training-only path-preference objective and downstream execution quality holds, MPCoT offers a practical route to test-time scaling of deliberation in VLA models without modifying the policy interface or incurring token overhead. The exposure of K and M as configurable controls is a clear engineering strength.
major comments (2)
- [Abstract and §3] Abstract and §3 (path-preference objective): The performance gains rest on the claim that the training-only objective (expert consistency + world-model/VLM progress + success feedback) aligns the latent path scorer with realized execution quality. No direct diagnostic is reported that correlates scorer rankings of candidate paths against actual trajectory success rates after aggregation. Without this, gains could be explained by ensemble averaging or the extra K refinement steps alone.
- [Ablations (§4.3)] Ablations (likely §4.3): The manuscript states that ablations confirm the reward-guided path supervision effect, yet provides no quantitative breakdown showing that the surrogate signals (particularly noisy world-model progress estimates) predict long-horizon outcomes better than a non-reward baseline. This leaves the supervision contribution unisolated from distribution shift at test time.
minor comments (2)
- The definitions of M (number of hypotheses) and K (refinement steps) should be stated explicitly with their ranges in the main text rather than only in the abstract.
- Notation for the soft aggregation step and the path scorer output could be introduced with an equation for clarity.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments below regarding validation of the path-preference objective and isolation of its contribution.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (path-preference objective): The performance gains rest on the claim that the training-only objective (expert consistency + world-model/VLM progress + success feedback) aligns the latent path scorer with realized execution quality. No direct diagnostic is reported that correlates scorer rankings of candidate paths against actual trajectory success rates after aggregation. Without this, gains could be explained by ensemble averaging or the extra K refinement steps alone.
Authors: We agree that an explicit diagnostic correlating the trained path scorer's rankings against post-aggregation trajectory success would strengthen the alignment claim. The §4.3 ablations already compare full MPCoT against variants without the path-preference objective (and against pure ensembling or extra refinement steps), showing gains attributable to the scorer; however, these are indirect. We will add the requested correlation analysis on held-out trajectories in the revision. revision: yes
-
Referee: [Ablations (§4.3)] Ablations (likely §4.3): The manuscript states that ablations confirm the reward-guided path supervision effect, yet provides no quantitative breakdown showing that the surrogate signals (particularly noisy world-model progress estimates) predict long-horizon outcomes better than a non-reward baseline. This leaves the supervision contribution unisolated from distribution shift at test time.
Authors: The existing §4.3 ablations isolate the supervision effect via controlled variants (with vs. without each surrogate signal) and report the resulting long-horizon success deltas on LIBERO and CALVIN. We acknowledge the absence of per-signal predictive-power metrics (e.g., correlation of world-model progress estimates with realized outcomes) that would further separate supervision quality from test-time distribution shift. We will expand the ablation tables with these quantitative breakdowns in the revision. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper presents MPCoT as a framework that trains a latent path scorer via a training-only objective combining expert-action consistency, world-model/VLM progress estimates, and success feedback, then uses the scorer at inference for multi-path refinement and aggregation. Performance gains are reported on external benchmarks (LIBERO, CALVIN) under matched protocols, with ablations cited for depth-width, aggregation, and supervision effects. No equations, self-citations, or definitional steps are shown that reduce the claimed alignment between the surrogate objective and downstream execution quality to an input by construction, nor is any 'prediction' statistically forced from fitted parameters on the same metrics. The alignment is treated as an empirical claim rather than a definitional equivalence, leaving the central result independent of its training signals.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manju- nath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
2023
-
[2]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An embodied multimodal language model. InProc. Int. Conf. Mach. Learn. (ICML), 2023
2023
-
[3]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
2023
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProc. Conf. Robot Learn. (CoRL), 2024
2024
-
[5]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InProc. Robot.: Sci. Syst. (RSS), 2025
2025
-
[6]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowl- edge transfer for lifelong robot learning. InProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2023
2023
-
[7]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2022
2022
-
[8]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. CoT-VLA: Visual chain-of-thought rea- soning for vision-language-action models. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025
2025
-
[9]
Training Large Language Models to Reason in a Continuous Latent Space
Y . Hao and S. Sukbaatar. Training large language models to reason in a continuous latent space, 2024. arXiv:2412.06769
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Z. Shen, H. Yan, L. Zhang, Z. Hu, Y . Du, and Y . He. CODI: Compressing chain-of-thought into continuous space via self-distillation. InProc. Conf. Empir . Methods Nat. Lang. Process. (EMNLP), 2025
2025
-
[11]
Y . Xu, X. Guo, Z. Zeng, and C. Miao. SoftCoT: Soft chain-of-thought for efficient reasoning with LLMs. InProc. Annu. Meeting Assoc. Comput. Linguist. (ACL), 2025
2025
- [12]
-
[13]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. Ruano, K. Jeffrey, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Retti...
2022
-
[14]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2024. arXiv:2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
- [16]
- [17]
-
[18]
L. Xiao, J. Li, J. Gao, F. Ye, Y . Jin, J. Qian, J. Zhang, Y . Wu, and X. Yu. A V A-VLA: Improving vision-language-action models with active visual attention, 2025. arXiv:2511.18960
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daume, A. Kolobov, F. Huang, and J. Yang. TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InProc. Int. Conf. Learn. Represent. (ICLR), 2025
2025
-
[20]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, D. Zhao, and H. Chen. WorldVLA: Towards autoregressive action world model, 2025. arXiv:2506.21539
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
J. Cheng and B. V . Durme. Compressed chain of thought: Efficient reasoning through dense representations, 2024. arXiv:2412.13171
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
X. Shen, Y . Wang, X. Shi, Y . Wang, P. Zhao, and J. Gu. Efficient reasoning with hidden thinking, 2025. arXiv:2501.19201
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
D. Su, H. Zhu, Y . Xu, J. Jiao, Y . Tian, and Q. Zheng. Token assorted: Mixing latent and text tokens for improved language model reasoning. InProc. Int. Conf. Mach. Learn. (ICML), 2025
2025
- [24]
-
[25]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models, 2025. arXiv:2501.09747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring spatial representations for visual-language-action models. In Proc. Robot.: Sci. Syst. (RSS), 2025
2025
-
[27]
C.-Y . Hung, Q. Sun, P. Hong, A. Zadeh, C. Li, U.-X. Tan, N. Majumder, and S. Poria. NORA: A small open-sourced generalist vision language action model for embodied tasks,
-
[28]
arXiv:2504.19854. 10
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
W. Song, J. Chen, P. Ding, H. Zhao, W. Zhao, Z. Zhong, Z. Ge, Z. Li, D. Wang, J. Ma, L. Wang, and H. Li. PD-VLA: Accelerating vision-language-action model integrated with action chunking via parallel decoding. InProc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), 2025
2025
-
[30]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. UniVLA: Learning to act anywhere with task-centric latent actions, 2025. arXiv:2505.06111
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
S. Tan, K. Dou, Y . Zhao, and P. Krahenbuhl. Interactive post-training for vision-language- action models, 2025. arXiv:2505.17016
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. InProc. Int. Conf. Learn. Represent. (ICLR), 2025. 11 Appendix A Implementation and Experimental Settings We summarize implementation and training settings in Table A.1, followed by reward evaluation and opt...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.