Recognition: no theorem link
AVA-VLA: Improving Vision-Language-Action models with Active Visual Attention
Pith reviewed 2026-05-17 06:23 UTC · model grok-4.3
The pith
Conditioning VLA actions on a recurrent history state and active visual attention improves robotic manipulation performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reformulating VLA policy learning from a partially observable Markov decision process perspective, with a recurrent state as a neural approximation to the agent's belief over task history and active visual attention that dynamically reweights visual tokens based on the instruction and execution history, enables improved action generation in robotic sequential decision-making.
What carries the argument
Active Visual Attention (AVA), which uses the recurrent state and instruction to dynamically reweight visual tokens from the current observation and focus on regions most relevant to the task history.
Load-bearing premise
A recurrent neural state provides a sufficient approximation to the agent's belief over task history and dynamically reweighting visual tokens based on this state and the instruction improves action generation.
What would settle it
A controlled ablation on the LIBERO or CALVIN benchmarks that removes the recurrent state and active visual attention and finds equal or higher success rates would show the additions do not drive the reported gains.
Figures








read the original abstract
Vision-Language-Action (VLA) models have shown remarkable progress in embodied tasks recently, but most methods process visual observations independently at each timestep. This history-agnostic design treats robot manipulation as a Markov Decision Process, even though real-world robotic control is inherently partially observable and requires reasoning over past interactions. To address this mismatch, we reformulate VLA policy learning from a Partially Observable Markov Decision Process perspective and propose AVA-VLA, a framework that conditions action generation on a recurrent state that serves as a neural approximation to the agent's belief over task history. Built on this recurrent state, we introduce Active Visual Attention (AVA), which dynamically reweights visual tokens in the current observation to focus on regions most relevant given both the instruction and execution history. Extensive experiments show that AVA-VLA achieves state-of-the-art performance on standard robotic benchmarks, including LIBERO and CALVIN, and transfers effectively to real-world dual-arm manipulation tasks. These results demonstrate the effectiveness of temporally grounded active visual processing for improving VLA performance in robotic sequential decision-making. The project page is available at https://liauto-dsr.github.io/AVA-VLA-Page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by reformulating Vision-Language-Action (VLA) models as Partially Observable Markov Decision Processes (POMDPs) and using a recurrent neural state to approximate the agent's belief over task history, their proposed Active Visual Attention (AVA) mechanism can dynamically reweight visual tokens to improve action generation. They report achieving state-of-the-art performance on the LIBERO and CALVIN benchmarks and effective transfer to real-world dual-arm robotic manipulation tasks.
Significance. If the central results hold under scrutiny, this contribution would be significant as it directly tackles the partial observability issue in robotic control that standard VLA models ignore by processing each timestep independently. The combination of recurrent belief approximation and instruction-conditioned active attention represents a logical extension of current architectures, and successful real-world transfer would strengthen the case for such temporally grounded approaches in embodied AI. The work provides a clear framework that could be built upon for more complex, long-horizon tasks.
major comments (2)
- [§3.2] §3.2: The recurrent state is introduced as a neural approximation to the belief state in the POMDP formulation, but the manuscript provides no empirical or theoretical analysis showing that this state retains relevant history information over the multi-step horizons present in the LIBERO and CALVIN tasks; without such validation, the performance improvements attributed to AVA may not stem from the intended mechanism.
- [§4.2] §4.2: In the ablation studies, while removing AVA degrades performance, there is no control experiment that uses a non-recurrent memory (e.g., a fixed-size buffer of past features) with equivalent parameter count; this leaves open the possibility that gains are due to additional capacity rather than the specific recurrent belief approximation.
minor comments (2)
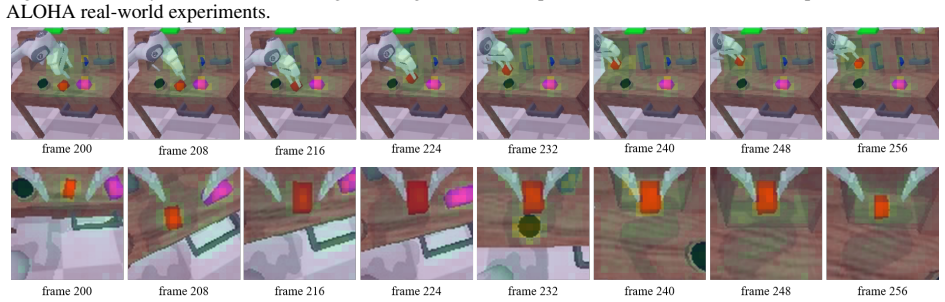
- [Figure 4] Figure 4: The real-world experiment figures would benefit from including failure cases or attention maps to provide more insight into when the method succeeds or fails.
- [Notation] Notation: The notation for the recurrent state h_t and the attention weights should be consistently defined across equations to avoid confusion.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive major comments. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2: The recurrent state is introduced as a neural approximation to the belief state in the POMDP formulation, but the manuscript provides no empirical or theoretical analysis showing that this state retains relevant history information over the multi-step horizons present in the LIBERO and CALVIN tasks; without such validation, the performance improvements attributed to AVA may not stem from the intended mechanism.
Authors: We agree that the manuscript would benefit from explicit validation that the recurrent state functions as an effective belief approximation over the relevant horizons. In the revision we will add an analysis section that probes the recurrent state, for example by measuring how its hidden activations change when historical observations are masked or truncated at different lengths, and by reporting task performance as a function of history length on LIBERO and CALVIN. This will provide direct evidence that the state retains task-relevant information and that the AVA improvements are tied to this mechanism. revision: yes
-
Referee: [§4.2] §4.2: In the ablation studies, while removing AVA degrades performance, there is no control experiment that uses a non-recurrent memory (e.g., a fixed-size buffer of past features) with equivalent parameter count; this leaves open the possibility that gains are due to additional capacity rather than the specific recurrent belief approximation.
Authors: We acknowledge that the current ablations do not include a capacity-matched non-recurrent baseline, which leaves the source of the gains partially ambiguous. We will add this control experiment in the revised manuscript: a fixed-size buffer of past visual features (with the same total parameter count as the recurrent module) that is concatenated or attended to in the same manner as the recurrent state. Performance differences between this baseline and the recurrent version will isolate the benefit attributable to the recurrent belief approximation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reformulates VLA policy learning as a POMDP and introduces a recurrent neural state as a standard approximation to the belief over task history, then builds Active Visual Attention on top of it. No equations, derivations, or self-citations are shown that reduce any central claim or prediction to fitted parameters or prior inputs by construction. Performance is evaluated on external benchmarks (LIBERO, CALVIN) and real-world tasks, rendering the approach self-contained and falsifiable without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world robotic control is inherently partially observable and requires reasoning over past interactions.
Forward citations
Cited by 1 Pith paper
-
OA-WAM: Object-Addressable World Action Model for Robust Robot Manipulation
OA-WAM uses persistent address vectors and dynamic content vectors in object slots to enable addressable world-action prediction, improving robustness on manipulation benchmarks under scene changes.
Reference graph
Works this paper leans on
-
[1]
RT-H: Action Hierarchies Using Language
Suneel Belkhale, Tianli Ding, Ted Xiao, Pierre Sermanet, Quon Vuong, Jonathan Tompson, Yevgen Chebotar, Debidatta Dwibedi, and Dorsa Sadigh. Rt-h: Action hierarchies using language.arXiv preprint arXiv:2403.01823, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, pp. 19–35. Springer, 2024
work page 2024
-
[9]
Pali-3 vision language models: Smaller, faster, stronger
Xi Chen, Xiao Wang, Lucas Beyer, Alexander Kolesnikov, Jialin Wu, Paul V oigtlaender, Basil Mustafa, Sebastian Goodman, Ibrahim Alabdulmohsin, Piotr Padlewski, et al. Pali-3 vision language models: Smaller, faster, stronger. arXiv preprint arXiv:2310.09199, 2023
-
[10]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction. arXiv preprint arXiv:2505.20279, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[13]
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U Tan, Navonil Majumder, Soujanya Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Anqing Jiang, Yu Gao, Yiru Wang, Zhigang Sun, Shuo Wang, Yuwen Heng, Hao Sun, Shichen Tang, Lijuan Zhu, Jinhao Chai, et al. Irl-vla: Training an vision-language-action policy via reward world model.arXiv preprint arXiv:2508.06571, 2025a
-
[15]
Titong Jiang, Xuefeng Jiang, Yuan Ma, Xin Wen, Bailin Li, Kun Zhan, Peng Jia, Yahui Liu, Sheng Sun, and Xianpeng Lang. The better you learn, the smarter you prune: Towards efficient vision-language-action models via differentiable token pruning.arXiv preprint arXiv:2509.12594, 2025b
-
[16]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[17]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Partially observable markov decision processes in robotics: A survey
Mikko Lauri, David Hsu, and Joni Pajarinen. Partially observable markov decision processes in robotics: A survey. IEEE Transactions on Robotics, 39(1):21–40, 2022. 11 APREPRINT- DECEMBER3, 2025
work page 2022
-
[20]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. Cogvla: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification.arXiv preprint arXiv:2508.21046, 2025a
-
[22]
Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, Shutao Xia, Zhi Wang, and Wenwu Zhu. Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration.arXiv preprint arXiv:2506.12723, 2025b
-
[23]
Reviving and improving recurrent back-propagation
Renjie Liao, Yuwen Xiong, Ethan Fetaya, Lisa Zhang, KiJung Yoon, Xaq Pitkow, Raquel Urtasun, and Richard Zemel. Reviving and improving recurrent back-propagation. InInternational conference on machine learning, pp. 3082–3091. PMLR, 2018
work page 2018
-
[24]
Shengsheng Lin, Weiwei Lin, Wentai Wu, Songbo Wang, and Yongxiang Wang. Petformer: Long-term time series forecasting via placeholder-enhanced transformer.IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
work page 2024
-
[25]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023a
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023b
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023b
-
[27]
Recurrent neural networks.Design and applications, 5(64-67):2, 2001
Larry R Medsker, Lakhmi Jain, et al. Recurrent neural networks.Design and applications, 5(64-67):2, 2001
work page 2001
-
[28]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7 (3):7327–7334, 2022
work page 2022
-
[29]
Semantic and sequential alignment for referring video object segmentation
Feiyu Pan, Hao Fang, Fangkai Li, Yanyu Xu, Yawei Li, Luca Benini, and Xiankai Lu. Semantic and sequential alignment for referring video object segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 19067–19076, 2025
work page 2025
-
[30]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. In International conference on machine learning, pp. 1310–1318. Pmlr, 2013
work page 2013
-
[31]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[32]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming long video understanding with large language models.Advances in Neural Information Processing Systems, 37: 119336–119360, 2024
work page 2024
-
[34]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34: 13937–13949, 2021
work page 2021
-
[36]
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies.arXiv preprint arXiv:2509.04996, 2025
-
[37]
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. Mome: Mixture of multimodal experts for generalist multimodal large language models.Advances in neural information processing systems, 37: 42048–42070, 2024
work page 2024
-
[38]
Richard D Smallwood and Edward J Sondik. The optimal control of partially observable markov processes over a finite horizon.Operations research, 21(5):1071–1088, 1973
work page 1973
-
[39]
Accelerating vision-language-action model integrated with action chunking via parallel decoding
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao, Zhide Zhong, Zongyuan Ge, Jun Ma, and Haoang Li. Accelerating vision-language-action model integrated with action chunking via parallel decoding. arXiv preprint arXiv:2503.02310, 2025. 12 APREPRINT- DECEMBER3, 2025
-
[40]
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, and Haoang Li. Reconvla: Reconstructive vision-language-action model as effective robot perceiver.arXiv preprint arXiv:2508.10333, 2025
-
[41]
Yizheng Sun, Yanze Xin, Hao Li, Jingyuan Sun, Chenghua Lin, and Riza Theresa Batista-Navarro. Lvpruning: An effective yet simple language-guided vision token pruning approach for multi-modal large language models. InFindings of the Association for Computational Linguistics: NAACL 2025, pp. 4299–4308, 2025
work page 2025
-
[42]
Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
-
[43]
Qwen Team et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3), 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024
-
[45]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Hanzhen Wang, Jiaming Xu, Jiayi Pan, Yongkang Zhou, and Guohao Dai. Specprune-vla: Accelerating vision- language-action models via action-aware self-speculative pruning.arXiv preprint arXiv:2509.05614, 2025a
-
[47]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 10510–10522, 2025b
-
[48]
Tiannan Wang, Wangchunshu Zhou, Yan Zeng, and Xinsong Zhang. Efficientvlm: Fast and accurate vision- language models via knowledge distillation and modal-adaptive pruning. InFindings of the association for computational linguistics: ACL 2023, pp. 13899–13913, 2023
work page 2023
-
[49]
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, et al. Vla-adapter: An effective paradigm for tiny-scale vision-language-action model.arXiv preprint arXiv:2509.09372, 2025
-
[50]
Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025c
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025c
-
[51]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025
work page 2025
-
[52]
Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, and Chang Xu. Vla-cache: Towards efficient vision- language-action model via adaptive token caching in robotic manipulation.arXiv preprint arXiv:2502.02175, 2025
-
[53]
Dynamically constructed (po) mdps for adaptive robot planning
Shiqi Zhang, Piyush Khandelwal, and Peter Stone. Dynamically constructed (po) mdps for adaptive robot planning. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
work page 2017
-
[54]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 1702–1713, 2025
work page 2025
-
[56]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[57]
https://global.agilex.ai/products/cobot-magic
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pp. 2165–2183. PMLR, 2023. 13 APREPRINT- DECEMBER3, 2025 Appendix A Implementation Details We report the implement...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.