EasyLens: A Training-Free Plug-and-Play Subtle-Lesion Representation Amplifier for Medical Vision-Language Models
Pith reviewed 2026-06-28 01:45 UTC · model grok-4.3
The pith
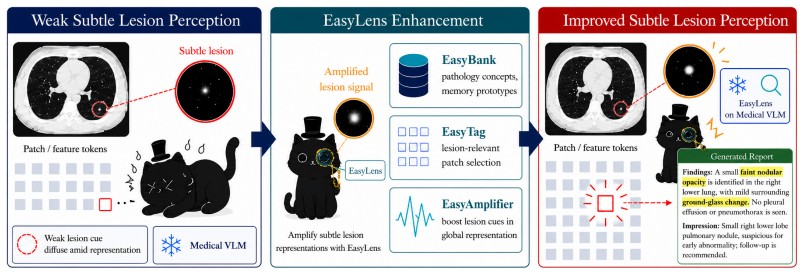
EasyLens amplifies subtle lesion cues in frozen medical vision-language models by building a prototype space, selecting patches through counterfactual reasoning, and applying morphology-guided residual boosts without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
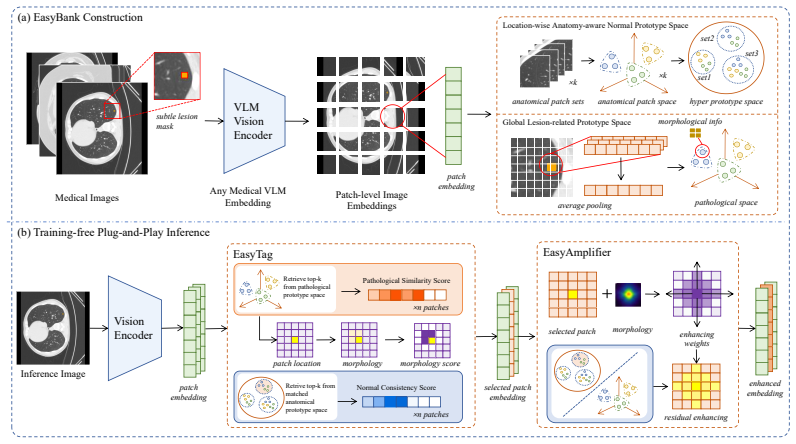
EasyLens constructs EasyBank, a pathology-anatomy prototype space that supplies both lesion-related prototypes and normal anatomical references; EasyTag then uses counterfactual prototype reasoning to select lesion-relevant patches and avoid amplifying normal tissue; EasyAmplifier applies morphology-guided residual enhancement to increase the weight of those patches in the global image embedding, raising the model's ability to detect subtle lesions across multiple datasets and backbones while remaining plug-and-play on frozen models.
What carries the argument
EasyLens three-part module that compares image patches against an EasyBank of pathology-anatomy prototypes, selects via counterfactual reasoning in EasyTag, and strengthens selected representations through morphology-guided residual enhancement in EasyAmplifier.
If this is right
- Subtle-lesion detection performance improves on multiple medical image datasets when the module is added to existing frozen VLMs.
- The approach outperforms prior encoder-enhancement methods that require training or model-specific changes.
- No additional training or adaptation is needed, so the same module can attach to arbitrary medical VLMs.
- Overfitting to particular disease morphologies is avoided because the prototype space and selection step operate without parameter updates.
Where Pith is reading between the lines
- The same patch-selection and residual-boost logic could extend to other imaging domains where weak local signals are diluted in global representations, such as satellite or industrial inspection.
- Because the method adds no trainable parameters, it might lower the barrier to testing new VLMs on rare or low-contrast conditions that lack large labeled sets.
- If the prototype space can be updated with new examples on the fly, the module could support continual adaptation to emerging lesion types without full model retraining.
Load-bearing premise
A prototype space built without training from pathology and anatomy examples can reliably separate subtle lesion patches from normal anatomy so that only the lesions get amplified without adding false signals or losing other image information.
What would settle it
Apply EasyLens to a frozen medical VLM on a dataset containing known subtle lesions and measure whether detection metrics such as sensitivity or F1 score rise compared with the unmodified model or whether false-positive rates increase.
Figures

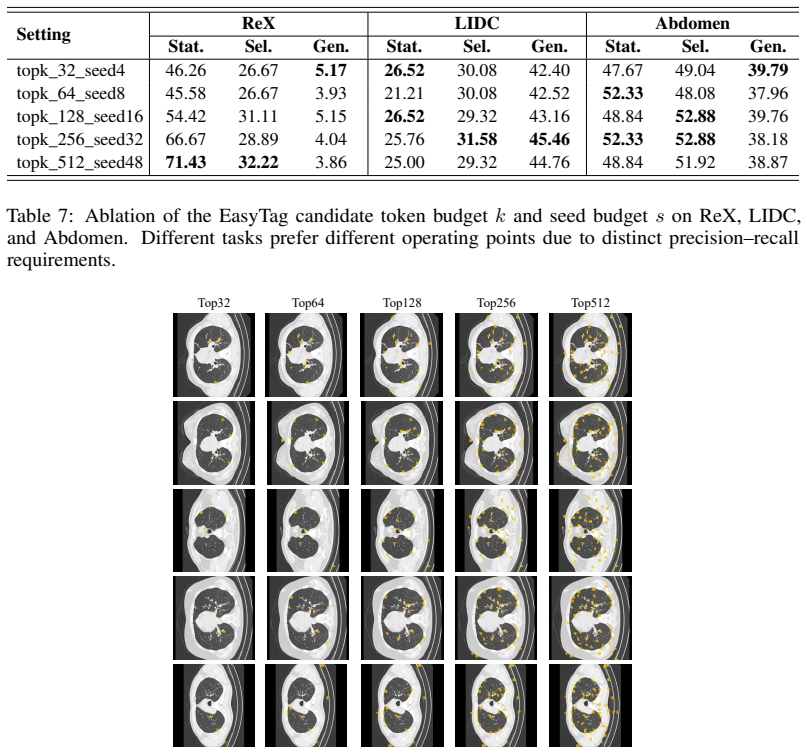
read the original abstract
Medical vision-language models (VLMs) have shown increasing potential for clinical image interpretation, including lesion detection and report generation. However, their practical utility remains limited by insufficient sensitivity to subtle lesions, whose visual evidence is often sparse, low-contrast, and embedded within complex anatomical context. As local visual tokens are aggregated, these weak lesion cues can become underrepresented in global image representations, making them difficult for medical VLMs to recognize. Existing efforts to improve lesion sensitivity mainly rely on medical-domain vision-encoder pre-training, clinical-term-guided alignment, or trainable pathological representation enhancement. Although effective, these approaches usually require additional training or model-specific adaptation and may overfit to particular disease morphologies, limiting their applicability to frozen medical VLMs. To address these limitations, we propose EasyLens, a training-free plug-and-play subtle-lesion representation amplifier for medical VLMs. EasyLens first constructs EasyBank, a pathology-anatomy prototype space that provides lesion-related prototypes and anatomy-aware normal references for comparing suspicious patches against both pathological and normal anatomical patterns. To avoid blindly amplifying normal tissues, EasyTag selects lesion-relevant patches through counterfactual prototype reasoning. To counteract the dilution of subtle lesion cues in global image representations, EasyAmplifier strengthens the selected lesion-relevant patch representations through morphology-guided residual enhancement, thereby increasing their contribution to the global image embedding. Experiments on multiple medical image datasets and frozen medical VLM backbones show that EasyLens improves subtle-lesion detection and outperforms existing encoder-enhancement baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EasyLens, a training-free plug-and-play subtle-lesion representation amplifier for medical vision-language models. It constructs EasyBank as a pathology-anatomy prototype space, applies EasyTag for lesion-relevant patch selection via counterfactual prototype reasoning, and uses EasyAmplifier for morphology-guided residual enhancement of selected patches to increase their contribution to global image embeddings. The central claim is that this pipeline improves subtle-lesion detection on multiple medical image datasets with frozen VLM backbones and outperforms existing encoder-enhancement baselines.
Significance. If the empirical results hold, the work would be significant for enabling enhanced sensitivity to subtle lesions in existing frozen medical VLMs without requiring training or model-specific adaptation. The training-free design addresses a practical limitation of prior approaches that rely on pre-training or fine-tuning and may overfit to particular disease morphologies.
major comments (2)
- [Abstract] Abstract: The central claim that 'experiments on multiple medical image datasets and frozen medical VLM backbones show that EasyLens improves subtle-lesion detection and outperforms existing encoder-enhancement baselines' is stated without any quantitative metrics, error bars, dataset names/sizes, ablation results, or statistical significance tests. This absence is load-bearing because the paper's contribution rests entirely on the asserted empirical gains.
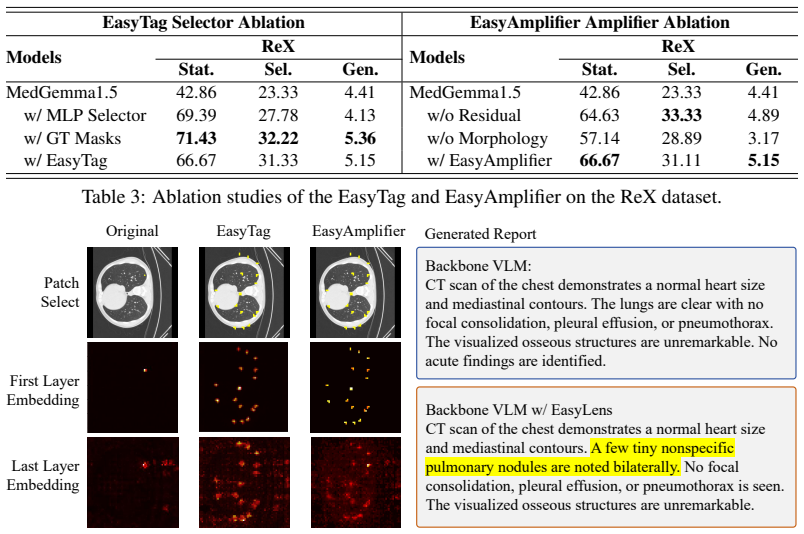
- [Abstract] Abstract: The description of EasyTag (counterfactual prototype reasoning) and EasyAmplifier (morphology-guided residual enhancement) assumes these steps can reliably identify and amplify subtle lesion cues without measurable false-positive inflation or dilution of other anatomical information, yet no analysis, failure-case discussion, or supporting results are provided to substantiate this assumption.
minor comments (1)
- [Abstract] The component names EasyBank, EasyTag, and EasyAmplifier are introduced without initial expansion or brief functional definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the abstract with concrete empirical support and to provide additional validation for the core assumptions of EasyTag and EasyAmplifier. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experiments on multiple medical image datasets and frozen medical VLM backbones show that EasyLens improves subtle-lesion detection and outperforms existing encoder-enhancement baselines' is stated without any quantitative metrics, error bars, dataset names/sizes, ablation results, or statistical significance tests. This absence is load-bearing because the paper's contribution rests entirely on the asserted empirical gains.
Authors: We agree that the abstract should include quantitative support for the central claim. The experiments section of the manuscript reports results on multiple datasets (including specific medical imaging benchmarks with sizes and splits) using frozen VLM backbones, with comparisons to encoder-enhancement baselines, ablations, and statistical significance. In the revision we will condense key metrics, error bars, dataset identifiers, and significance indicators into the abstract while preserving its length constraints. revision: yes
-
Referee: [Abstract] Abstract: The description of EasyTag (counterfactual prototype reasoning) and EasyAmplifier (morphology-guided residual enhancement) assumes these steps can reliably identify and amplify subtle lesion cues without measurable false-positive inflation or dilution of other anatomical information, yet no analysis, failure-case discussion, or supporting results are provided to substantiate this assumption.
Authors: We acknowledge that the abstract does not include supporting analysis for the reliability assumptions. The full manuscript contains ablation studies and comparative results demonstrating that EasyTag reduces irrelevant amplification relative to baselines and that EasyAmplifier improves lesion sensitivity without degrading overall anatomical representation. In the revision we will add a concise statement in the abstract referencing these empirical checks and will expand the main text with a dedicated failure-case analysis subsection. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes a training-free plug-and-play pipeline (EasyBank prototype space, EasyTag counterfactual selection, EasyAmplifier morphology-guided residuals) whose components are constructed and applied without training, fitted parameters, or equations that reduce outputs to inputs by definition. Claims rest on empirical results across datasets and frozen VLMs rather than self-referential derivations or load-bearing self-citations. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Making the most of text semantics to improve biomedical vision–language processing
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, et al. Making the most of text semantics to improve biomedical vision–language processing. In European conference on computer vision, pages 1–21. Springer, 2022
2022
-
[2]
Fine-grained image-text alignment in medical imaging enables explainable cyclic image-report generation
Wenting Chen, Linlin Shen, Jingyang Lin, Jiebo Luo, Xiang Li, and Yixuan Yuan. Fine-grained image-text alignment in medical imaging enables explainable cyclic image-report generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9494–9509, 2024
2024
-
[3]
Mimo: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output
Yanyuan Chen, Dexuan Xu, Yu Huang, Songkun Zhan, Hanpin Wang, Dongxue Chen, Xueping Wang, Meikang Qiu, and Hang Li. Mimo: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24732–24741, 2025
2025
-
[4]
Large language model with region-guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
Zhixuan Chen, Yequan Bie, Haibo Jin, and Hao Chen. Large language model with region-guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
2025
-
[5]
Understanding the robustness of vision-language models to medical image artefacts.NPJ Digital Medicine, 8(1):727, 2025
Zijie Cheng, Ariel Yuhan Ong, Siegfried K Wagner, David A Merle, Lie Ju, Hanyuan Zhang, Ruinian Chen, Linze Pang, Boxuan Li, Tiantian He, et al. Understanding the robustness of vision-language models to medical image artefacts.NPJ Digital Medicine, 8(1):727, 2025
2025
-
[6]
MedRAX: Medical reasoning agent for chest x-ray
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. MedRAX: Medical reasoning agent for chest x-ray. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste- Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine...
2025
-
[7]
Ziqing Fan, Cheng Liang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Chestx- reasoner: Advancing radiology foundation models with reasoning through step-by-step verifica- tion.arXiv preprint arXiv:2504.20930, 2025
-
[8]
Chengyu Fang, Heng Guo, Zheng Jiang, Chunming He, Xiu Li, and Minfeng Xu. Photon: Speedup volume understanding with efficient multimodal large language models.arXiv preprint arXiv:2603.25155, 2026
-
[9]
Ibrahim Ethem Hamamci, Sezgin Er, Suprosanna Shit, Hadrien Reynaud, Dong Yang, Pengfei Guo, Marc Edgar, Daguang Xu, Bernhard Kainz, and Bjoern Menze. Better tokens for better 3d: Advancing vision-language modeling in 3d medical imaging.arXiv preprint arXiv:2510.20639, 2025
-
[10]
Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelligence, 7:1430984, 2024
Iryna Hartsock and Ghulam Rasool. Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelligence, 7:1430984, 2024
2024
-
[11]
Kinhei Lee, Peiyuan Jing, Zhenxuan Zhang, Yue Yang, Tao Wang, Dominic C Marshall, Yingying Fang, and Guang Yang. Seeing through experts eyes a foundational vision language model trained on radiologists gaze and reasoning.arXiv preprint arXiv:2604.14316, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Anatomical structure-guided medical vision-language pre- training
Qingqiu Li, Xiaohan Yan, Jilan Xu, Runtian Yuan, Yuejie Zhang, Rui Feng, Quanli Shen, Xiaobo Zhang, and Shujun Wang. Anatomical structure-guided medical vision-language pre- training. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 80–90. Springer, 2024
2024
-
[13]
Qingqiu Li, Zihang Cui, Seongsu Bae, Jilan Xu, Runtian Yuan, Yuejie Zhang, Rui Feng, Quanli Shen, Xiaobo Zhang, Junjun He, et al. Aor: Anatomical ontology-guided reasoning for medical large multimodal model in chest x-ray interpretation.arXiv preprint arXiv:2505.02830, 2025
-
[14]
Argus: benchmarking and enhancing vision-language models for 3d radiology report generation
Che Liu, Zhongwei Wan, Yuqi Wang, Hui Shen, Haozhe Wang, Kangyu Zheng, Mi Zhang, and Rossella Arcucci. Argus: benchmarking and enhancing vision-language models for 3d radiology report generation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 16448–16460, 2025. 11
2025
-
[15]
Mlip: medical language-image pre-training with masked local representation learning
Jiarun Liu, Hong-Yu Zhou, Cheng Li, Weijian Huang, Hao Yang, Yong Liang, Guangming Shi, Hairong Zheng, and Shanshan Wang. Mlip: medical language-image pre-training with masked local representation learning. In2024 IEEE International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2024
2024
-
[16]
Kang Liu, Zhuoqi Ma, Siyu Liang, Yunan Li, Xiyue Gao, Chao Liang, Kun Xie, and Qiguang Miao. Seeing like radiologists: Context-and gaze-guided vision-language pretraining for chest x-rays.arXiv preprint arXiv:2603.26049, 2026
-
[17]
Vividmed: Vision language model with versatile visual grounding for medicine
Lingxiao Luo, Bingda Tang, Xuanzhong Chen, Rong Han, and Ting Chen. Vividmed: Vision language model with versatile visual grounding for medicine. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1800–1821, 2025
2025
-
[18]
Abnormality detection in chest x-ray images using uncertainty prediction autoencoders
Yifan Mao, Fei-Fei Xue, Ruixuan Wang, Jianguo Zhang, Wei-Shi Zheng, and Hongmei Liu. Abnormality detection in chest x-ray images using uncertainty prediction autoencoders. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 529–538. Springer, 2020
2020
-
[19]
Radzero: Similarity-based cross-attention for explainable vision-language alignment in radiology with zero-shot multi-task capability.arXiv e-prints, pages arXiv–2504, 2025
Jonggwon Park, Soobum Kim, Byungmu Yoon, and Kyoyun Choi. Radzero: Similarity-based cross-attention for explainable vision-language alignment in radiology with zero-shot multi-task capability.arXiv e-prints, pages arXiv–2504, 2025
2025
-
[20]
Corentin Royer, Bjoern Menze, and Anjany Sekuboyina. Multimedeval: A benchmark and a toolkit for evaluating medical vision-language models.arXiv preprint arXiv:2402.09262, 2024
-
[21]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Task-driven ct image quality optimization for low-contrast lesion detectability with tunable neural networks
Matthew Tivnan, Tzu-Cheng Lee, Ruoqiao Zhang, Kirsten Boedeker, Liang Cai, Jeremias Sulam, and J Webster Stayman. Task-driven ct image quality optimization for low-contrast lesion detectability with tunable neural networks. InMedical Imaging 2023: Physics of Medical Imaging, volume 12463, pages 338–343. SPIE, 2023
2023
-
[23]
Improving medical visual representation learning with pathological-level cross-modal alignment and correlation exploration.IEEE Journal of Biomedical and Health Informatics, 2025
Jun Wang, Lixing Zhu, Xiaohan Yu, Abhir Bhalerao, and Yulan He. Improving medical visual representation learning with pathological-level cross-modal alignment and correlation exploration.IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[24]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3876–3887, 2022
2022
-
[25]
Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis. InProceedings of the IEEE/CVF international conference on computer vision, pages 21372–21383, 2023
2023
-
[26]
Kohei Yamamoto and Tomohiro Kikuchi. Totalfm: An organ-separated framework for 3d-ct vision foundation models.arXiv preprint arXiv:2601.00260, 2026
work page internal anchor Pith review arXiv 2026
-
[27]
Knowledge-enhanced visual-language pre-training on chest radiology images.Nature Communications, 14(1):4542, 2023
Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Weidi Xie, and Yanfeng Wang. Knowledge-enhanced visual-language pre-training on chest radiology images.Nature Communications, 14(1):4542, 2023
2023
-
[28]
Yabin Zhang, Chong Wang, Yunhe Gao, Jiaming Liu, Maya Varma, Justin Xu, Sophie Ostmeier, Jin Long, Sergios Gatidis, Seena Dehkharghani, et al. A reasoning-enabled vision-language foundation model for chest x-ray interpretation.arXiv preprint arXiv:2604.00493, 2026
-
[29]
From single to universal: tiny lesion detection in medical imaging.Artificial Intelligence Review, 57(8):192, 2024
Yi Zhang, Yiji Mao, Xuanyu Lu, Xingyu Zou, Hao Huang, Xinyang Li, Jiayue Li, and Haixian Zhang. From single to universal: tiny lesion detection in medical imaging.Artificial Intelligence Review, 57(8):192, 2024. 12
2024
-
[30]
Contrastive learning of medical visual representations from paired images and text
Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. InMachine learning for healthcare conference, pages 2–25. PMLR, 2022
2022
-
[31]
Improving medical large vision-language models with abnormal-aware feedback
Yucheng Zhou, Lingran Song, and Jianbing Shen. Improving medical large vision-language models with abnormal-aware feedback. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12994–13011, 2025
2025
-
[32]
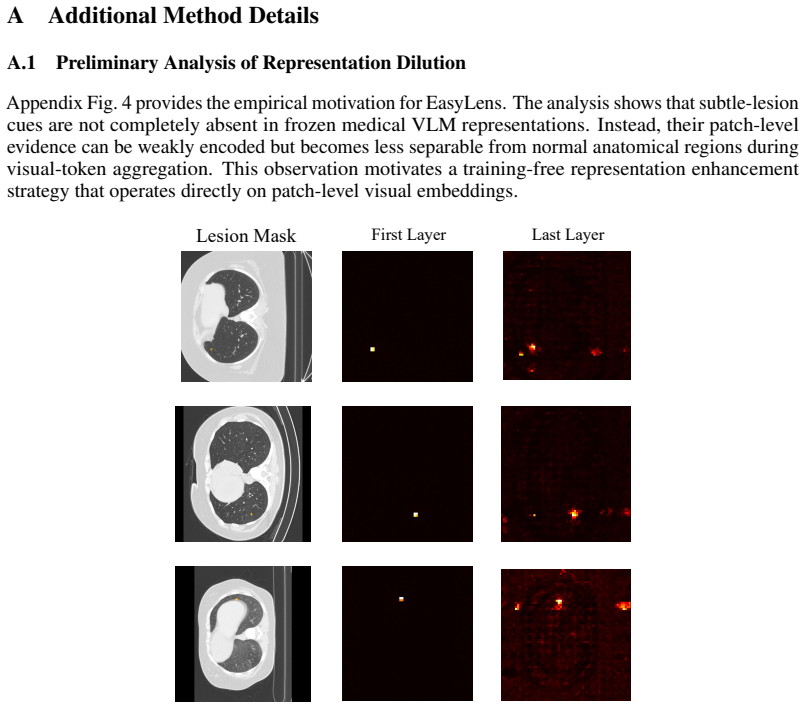
Kangyu Zhu, Peng Xia, Yun Li, Hongtu Zhu, Sheng Wang, and Huaxiu Yao. Mmedpo: Aligning medical vision-language models with clinical-aware multimodal preference optimization.arXiv preprint arXiv:2412.06141, 2024. 13 A Additional Method Details A.1 Preliminary Analysis of Representation Dilution Appendix Fig. 4 provides the empirical motivation for EasyLens...
-
[33]
Justification: The study does not collect new human-subject data and uses existing medical imaging datasets under their corresponding access and usage policies
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.