Self-Augmenting Retrieval for Diffusion Language Models
Pith reviewed 2026-06-28 01:55 UTC · model grok-4.3
The pith
Discrete diffusion language models can use their own discarded low-confidence tokens as early signals to guide retrieval during generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The discarded tokens in the denoising trajectory of discrete diffusion language models serve as a useful lookahead signal for retrieval-augmented generation, allowing stronger evidence to be retrieved before the output is finalized.
What carries the argument
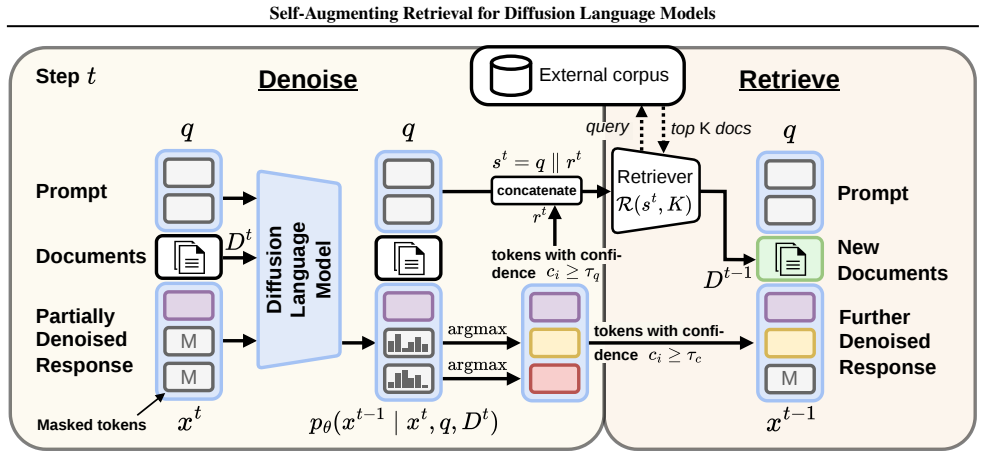
SARDI, a dynamic RAG framework that uses low-confidence lookahead tokens from the denoising process to guide retrieval.
If this is right
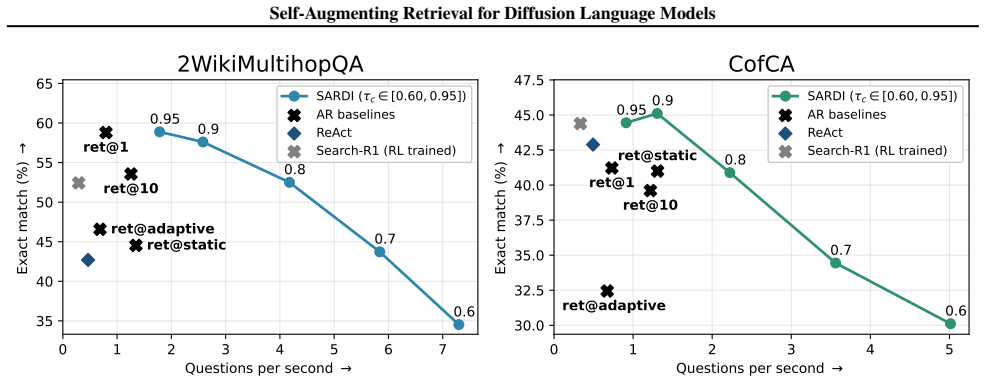
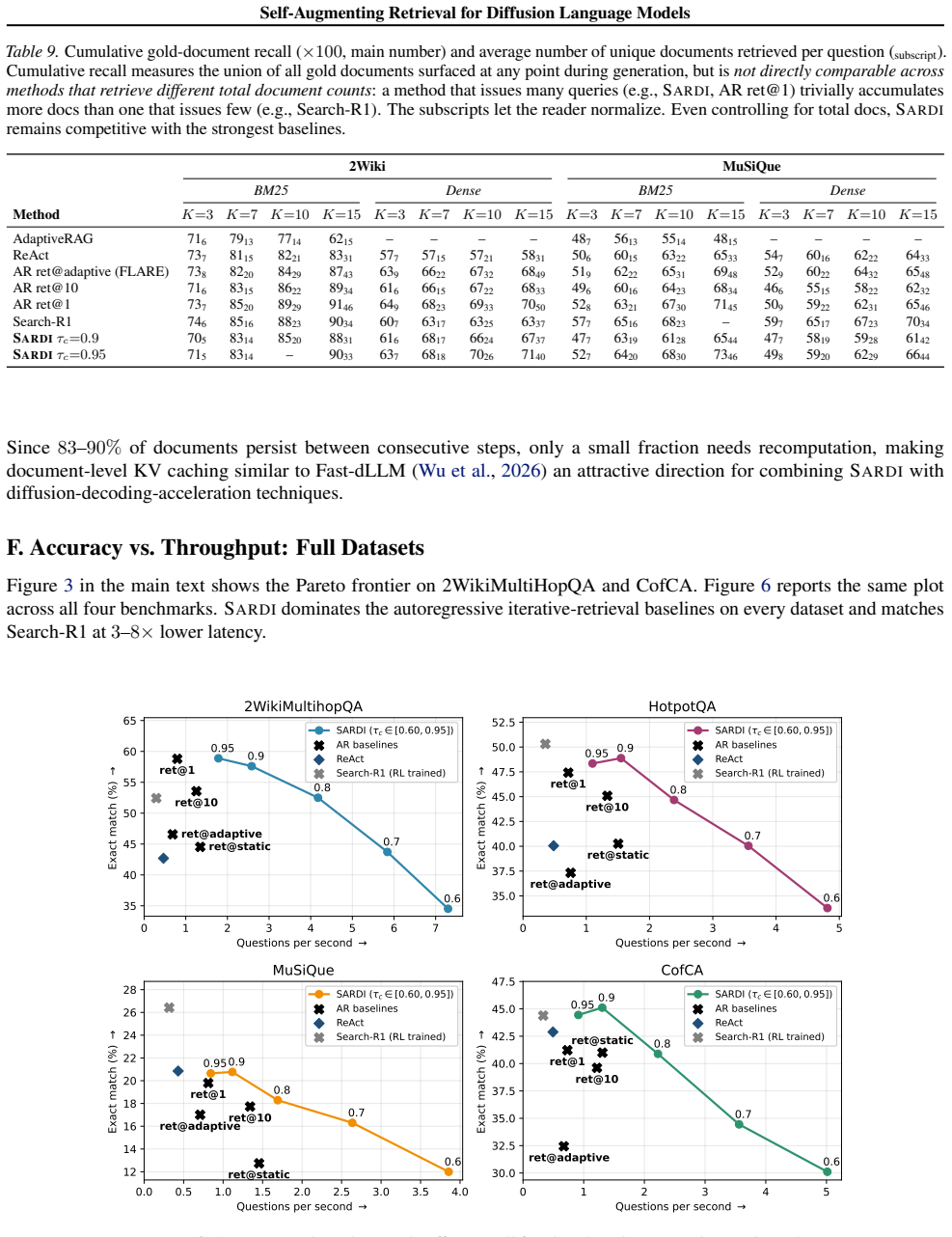
- SARDI outperforms current training-free diffusion and autoregressive retrieval baselines on five multi-hop QA benchmarks.
- SARDI achieves up to 8 times higher throughput than the compared baselines.
- SARDI is training-free and retriever-agnostic.
- SARDI applies to any reasoning-capable discrete diffusion language model.
Where Pith is reading between the lines
- The same internal uncertainty signal might be usable in other iterative text generation methods that produce intermediate predictions.
- Leveraging discarded tokens could reduce dependence on separate retriever modules in some generation pipelines.
- The timing of when entities appear in the low-confidence set could be measured to optimize retrieval timing across different diffusion schedules.
Load-bearing premise
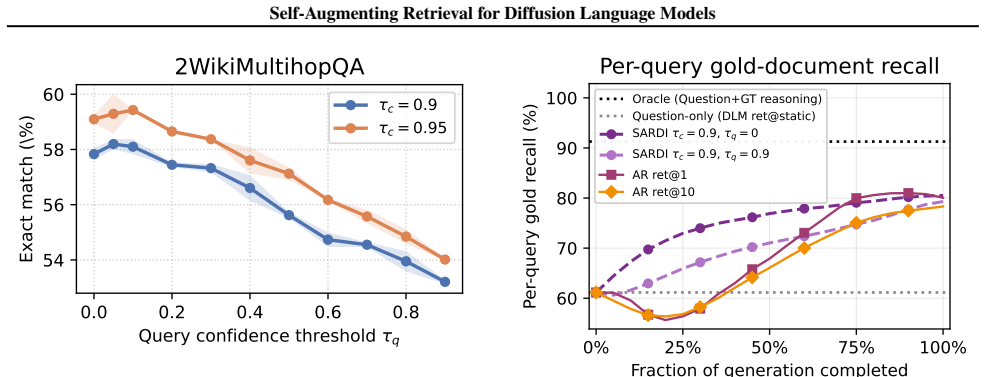
Low-confidence tokens discarded during denoising reliably surface salient entities early enough in the trajectory to enable useful retrieval before the output is finalized.
What would settle it
An experiment on the five multi-hop QA benchmarks where retrieving with the low-confidence tokens produces no accuracy gain or a loss relative to the non-retrieval diffusion baseline.
Figures

read the original abstract
Discrete diffusion language models generate text by iteratively denoising an entire response in parallel. At each step, they predict tentative tokens for every masked position, committing the confident predictions to the output and discarding the unconfident ones. We show that the discarded tokens are in fact a useful lookahead signal for retrieval-augmented generation: even low-confidence tokens often surface salient entities early in the denoising trajectory, enabling retrieval of stronger evidence before the output is finalized. We exploit this through Self-Augmenting Retrieval for Diffusion Language Models (SARDI), a dynamic RAG framework that uses these lookahead tokens to guide retrieval during denoising. SARDI is training-free, retriever-agnostic, and applicable to any reasoning-capable discrete diffusion language model. Across five multi-hop QA benchmarks, SARDI outperforms current training-free diffusion and autoregressive retrieval baselines at up to $8\times$ higher throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SARDI, a training-free dynamic retrieval-augmented generation framework for discrete diffusion language models. It exploits low-confidence tokens discarded during the iterative denoising process as early lookahead signals to retrieve relevant evidence before finalizing the output. The method is presented as retriever-agnostic and applicable to any reasoning-capable discrete diffusion LM. Across five multi-hop QA benchmarks, SARDI is claimed to outperform current training-free diffusion and autoregressive retrieval baselines while achieving up to 8× higher throughput.
Significance. If the performance claims are substantiated with adequate experimental controls, the work could be significant for enabling efficient RAG in non-autoregressive generative models without requiring retraining. The core idea of repurposing intermediate denoising states for retrieval is a constructive use of model internals, and the training-free, retriever-agnostic properties are explicit strengths that lower barriers to adoption. The reported throughput gains, if reproducible, address a practical limitation of diffusion-based generation relative to autoregressive baselines.
major comments (1)
- [Experimental Results] Experimental section: the manuscript states empirical gains on five multi-hop QA benchmarks but provides no information on the precise baselines (including their retrieval components and implementation details), number of runs, variance across seeds, statistical significance tests, or controls for retrieval corpus and retriever quality. These omissions are load-bearing for the central outperformance claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'up to 8× higher throughput' would benefit from a parenthetical specifying the exact comparison (e.g., against which baseline and under what hardware/sequence-length conditions).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental reporting. We agree that the current manuscript lacks sufficient detail on baselines, statistical controls, and implementation specifics, which are necessary to substantiate the performance claims. We will revise the paper accordingly.
read point-by-point responses
-
Referee: Experimental section: the manuscript states empirical gains on five multi-hop QA benchmarks but provides no information on the precise baselines (including their retrieval components and implementation details), number of runs, variance across seeds, statistical significance tests, or controls for retrieval corpus and retriever quality. These omissions are load-bearing for the central outperformance claim.
Authors: We acknowledge this gap in the submitted manuscript. In the revised version we will expand Section 4 (Experiments) with: (1) explicit descriptions of all baselines including their retrieval components (e.g., exact retriever models, top-k values, and corpus indexing details); (2) implementation details such as diffusion steps, confidence thresholds, and retrieval timing; (3) results averaged over 3 random seeds with reported standard deviations; (4) paired t-test p-values for all main comparisons; and (5) controls confirming identical retrieval corpora and retriever checkpoints across methods. A new table will summarize these settings for reproducibility. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents SARDI as a training-free composition of existing diffusion denoising steps with standard retrieval, without any equations, fitted parameters, or derivation chain. The core mechanism (using low-confidence tokens for lookahead retrieval) is described mechanistically and evaluated empirically on benchmarks; no step reduces to a self-definition, fitted input renamed as prediction, or load-bearing self-citation. The method is self-contained against external benchmarks with no internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-confidence tokens in the denoising trajectory contain salient entities usable for retrieval before final output.
Reference graph
Works this paper leans on
-
[1]
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =
-
[2]
Yang Song and Jascha Sohl-Dickstein and Diederik P Kingma and Abhishek Kumar and Stefano Ermon and Ben Poole , booktitle=
-
[3]
and Ho, Jonathan and Tarlow, Daniel and van den Berg, Rianne , booktitle =
Austin, Jacob and Johnson, Daniel D. and Ho, Jonathan and Tarlow, Daniel and van den Berg, Rianne , booktitle =
-
[4]
Hashimoto , title =
Xiang Lisa Li and John Thickstun and Ishaan Gulrajani and Percy Liang and Tatsunori B. Hashimoto , title =
-
[5]
2023 , paper =
Lovelace, Justin and Kishore, Varsha and Wan, Chao and Shekhtman, Eliot and Weinberger, Kilian Q , journal =. 2023 , paper =
2023
-
[6]
Ye, Jiacheng and Xie, Zhihui and Zheng, Lin and Gao, Jiahui and Wu, Zirui and Jiang, Xin and Li, Zhenguo and Kong, Lingpeng , journal=
-
[7]
Shen Nie and Fengqi Zhu and Zebin You and Xiaolu Zhang and Jingyang Ou and Jun Hu and JUN ZHOU and Yankai Lin and Ji-Rong Wen and Chongxuan Li , booktitle=
-
[8]
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K
-
[9]
Chengyue Wu and Hao Zhang and Shuchen Xue and Zhijian Liu and Shizhe Diao and Ligeng Zhu and Ping Luo and Song Han and Enze Xie , booktitle=. Fast-d
-
[10]
Chengyue Wu and Hao Zhang and Shuchen Xue and Shizhe Diao and Yonggan Fu and Zhijian Liu and Pavlo Molchanov and Ping Luo and Song Han and Enze Xie , booktitle=
-
[11]
Qingyan Wei and Yaojie Zhang and Zhiyuan Liu and Puyu Zeng and Yuxuan Wang and Biqing Qi and Dongrui Liu and Linfeng Zhang , booktitle=
-
[12]
Ma, Yuxin and Du, Lun and Wei, Lanning and Chen, Kun and Xu, Qian and Wang, Kangyu and Feng, Guofeng and Lu, Guoshan and Liu, Lin and Qi, Xiaojing and others , journal=
-
[13]
Marianne Arriola and Yair Schiff and Hao Phung and Aaron Gokaslan and Volodymyr Kuleshov , booktitle=
-
[14]
Amin Karimi Monsefi and Nikhil Bhendawade and Manuel Rafael Ciosici and Dominic Culver and Yizhe Zhang and Irina Belousova , booktitle=
-
[15]
Diffusion
Xu Wang and Chenkai Xu and Yijie Jin and Jiachun Jin and Hao Zhang and Kai Yu and Zhijie Deng , booktitle=. Diffusion. 2026 , url=
2026
-
[16]
Christopher, Jacob K and Bartoldson, Brian R and Ben-Nun, Tal and Cardei, Michael and Kailkhura, Bhavya and Fioretto, Ferdinando , booktitle=
-
[17]
Li, Guanghao and Fu, Zhihui and Fang, Min and Zhao, Qibin and Tang, Ming and Yuan, Chun and Wang, Jun , journal=
-
[18]
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick SH and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau , booktitle=
-
[19]
2020 , timestamp =
Kelvin Guu and Kenton Lee and Zora Tung and Panupong Pasupat and Ming. 2020 , timestamp =
2020
-
[20]
Izacard, Gautier and Grave, Edouard , booktitle=
-
[21]
2022 , organization=
Improving language models by retrieving from trillions of tokens , author=. 2022 , organization=
2022
-
[22]
Zhang, Jiahao and Zhang, Haiyang and Zhang, Dongmei and Yong, Liu and Huang, Shen , booktitle=
-
[23]
2024 , timestamp =
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , title =. 2024 , timestamp =
2024
-
[24]
Xu, Zhipeng and Liu, Zhenghao and Yan, Yukun and Wang, Shuo and Yu, Shi and Zeng, Zheni and Xiao, Chaojun and Liu, Zhiyuan and Yu, Ge and Xiong, Chenyan. T hink N ote: Enhancing Knowledge Integration and Utilization of Large Language Models via Constructivist Cognition Modeling. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026...
-
[25]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
Xiaoxi Li and Guanting Dong and Jiajie Jin and Yuyao Zhang and Yujia Zhou and Yutao Zhu and Peitian Zhang and Zhicheng Dou , editor =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , doi =
2025
-
[26]
Bowen Jin and Hansi Zeng and Zhenrui Yue and Jinsung Yoon and Sercan O Arik and Dong Wang and Hamed Zamani and Jiawei Han , booktitle=
-
[27]
Li and Huyền Chipman and Melody Y
Darren Edge and Ha Nguyen and Kevin J. Li and Huyền Chipman and Melody Y. Guan and Gabriele Corso and Daniel S. Weld and Yuliya Lierler and Jonathan Bragg , year=. 2404.16130 , archivePrefix=
-
[28]
Tao, Yufan and Xu, Yingqi and Li, Yizhong and others , booktitle=
-
[29]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=
-
[30]
2023 , doi =
Harsh Trivedi and Niranjan Balasubramanian and Tushar Khot and Ashish Sabharwal , editor =. 2023 , doi =
2023
-
[31]
Jiang, Zhengbao and Xu, Frank F and Gao, Luyu and Sun, Zhiqing and Liu, Qian and Dwivedi-Yu, Jane and Yang, Yiming and Callan, Jamie and Neubig, Graham , booktitle=
-
[32]
Constructing
Xanh Ho and Anh. Constructing. Proceedings of the 28th International Conference on Computational Linguistics,. 2020 , doi =
2020
-
[33]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D , booktitle=
-
[34]
2022 , publisher=
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=. 2022 , publisher=
2022
-
[35]
Gao, Yunfan and Xiong, Yun and Gao, Xinyu and Jia, Kangxiang and Pan, Jinliu and Bi, Yuxi and Dai, Yixin and Sun, Jiawei and Wang, Haofen and Wang, Haofen , journal=
-
[36]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik R and Cao, Yuan , booktitle=
-
[37]
Jian Wu and Linyi Yang and Zhen Wang and Manabu Okumura and Yue Zhang , booktitle=. Cof
-
[38]
Gu, Ken and Bhat, Advait and Merrill, Mike A and West, Robert and Liu, Xin and McDuff, Daniel and Althoff, Tim , journal=
-
[39]
Jin, Jiajie and Zhu, Yutao and Dou, Zhicheng and Dong, Guanting and Yang, Xinyu and Zhang, Chenghao and Zhao, Tong and Yang, Zhao and Wen, Ji-Rong , booktitle=
-
[40]
Prabhu, Venktesh V Deepali and Anand, Avishek , journal=
-
[41]
2009 , publisher=
Robertson, Stephen and Zaragoza, Hugo and others , journal=. 2009 , publisher=
2009
-
[42]
Yu, Chuanyue and Wang, Jiahui and Li, Yuhan and Chang, Heng and Lan, Ge and Sun, Qingyun and Li, Jia and Li, Jianxin and Zhang, Ziwei , journal=
-
[43]
Zhanqiu Hu and Jian Meng and Yash Akhauri and Mohamed S. Abdelfattah and Jae. CoRR , volume =. 2025 , doi =. 2505.21467 , timestamp =
arXiv 2025
-
[44]
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong , booktitle=
-
[45]
Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu , journal=
-
[46]
Proceedings of the Sixth Conference on Machine Learning and Systems, MLSys 2023, Miami, FL, USA, June 4-8, 2023 , publisher =
Reiner Pope and Sholto Douglas and Aakanksha Chowdhery and Jacob Devlin and James Bradbury and Jonathan Heek and Kefan Xiao and Shivani Agrawal and Jeff Dean , editor =. Proceedings of the Sixth Conference on Machine Learning and Systems, MLSys 2023, Miami, FL, USA, June 4-8, 2023 , publisher =. 2023 , timestamp =
2023
-
[47]
Database Systems for Advanced Applications
Fang, Yubo and Yu, Hai-Tao and Joho, Hideo and Fujita, Sumio. Database Systems for Advanced Applications. 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.