Operation-Guided Progressive Human-to-AI Text Transformation Benchmark for Multi-Granularity AI-Text Detection
Pith reviewed 2026-06-28 01:51 UTC · model grok-4.3
The pith
Progressive AI edits on human text produce non-monotonic detection patterns where mixed intermediate versions are often harder to spot than pure endpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
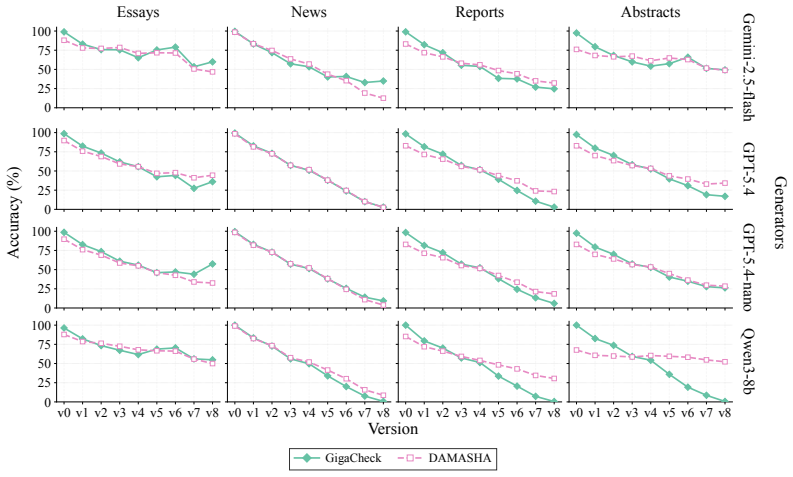
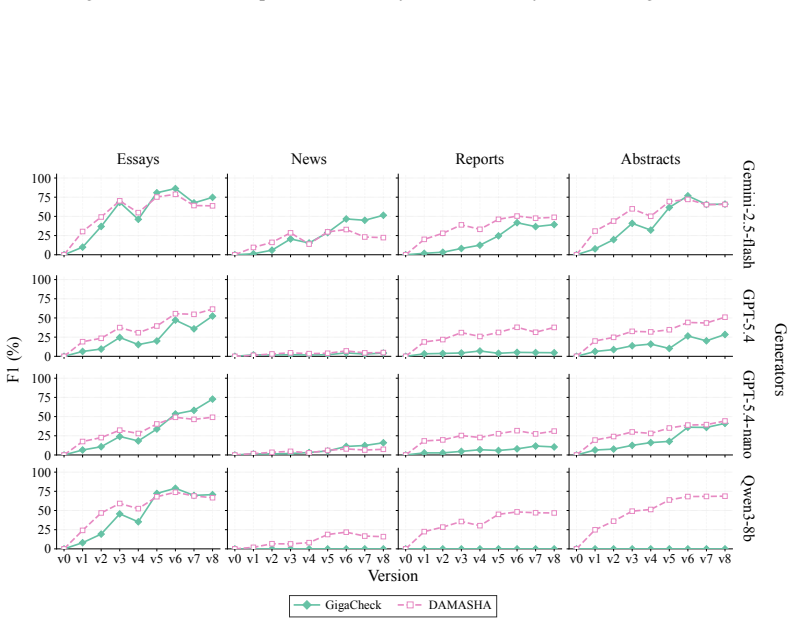
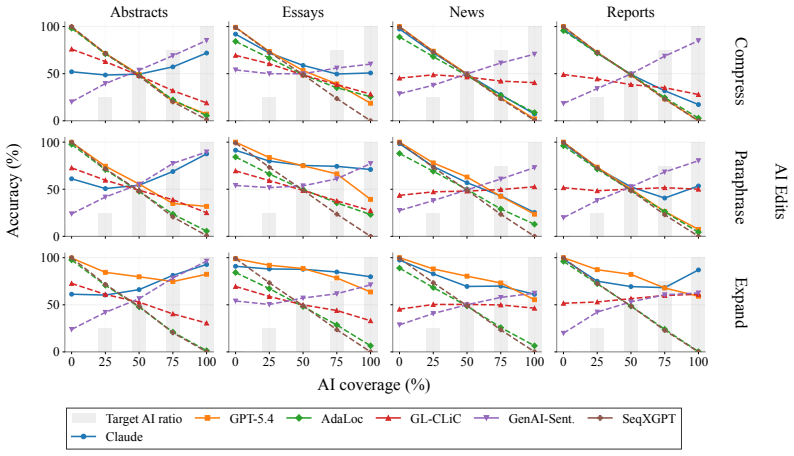
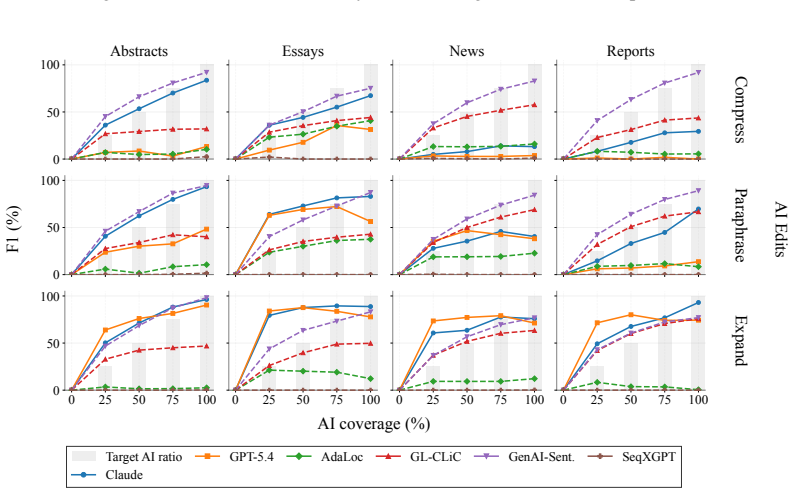
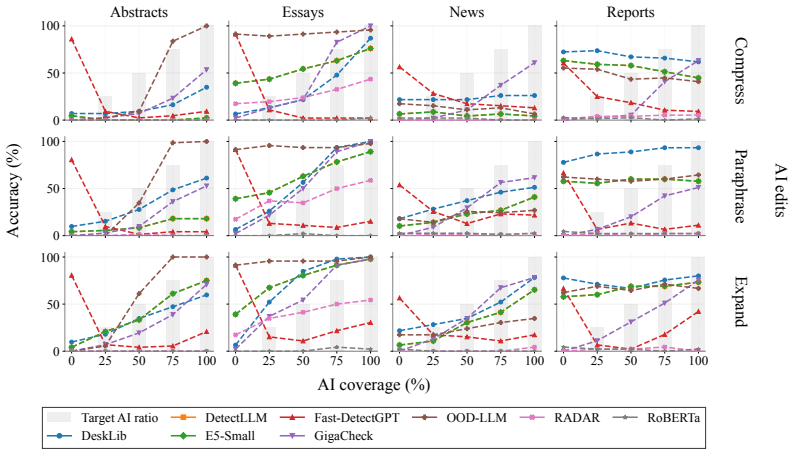
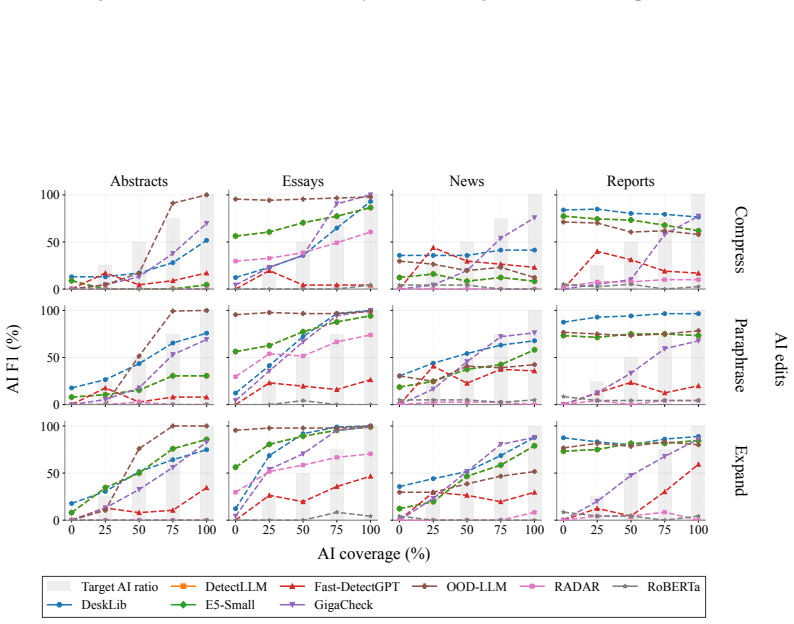
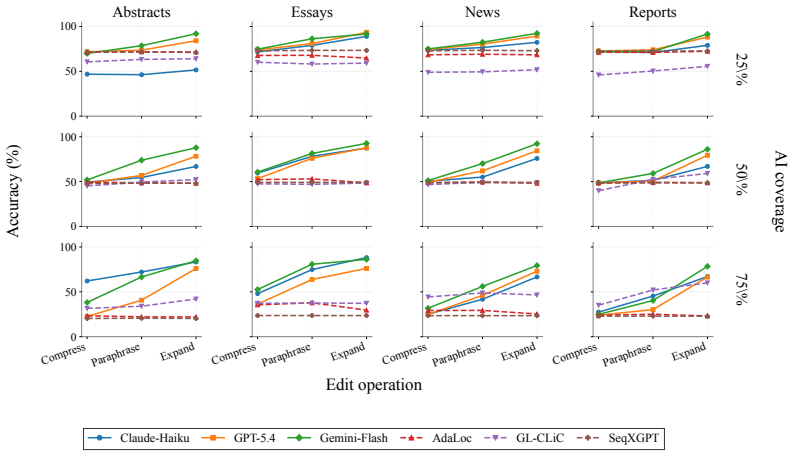
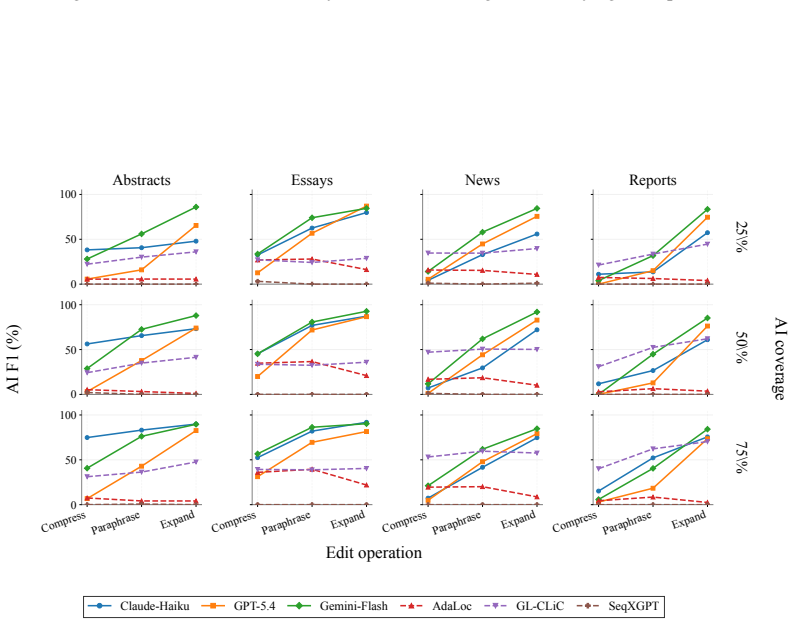
OpAI-Bench starts with human-written documents and generates nine sequentially revised versions per sample under controlled AI coverage levels using five representative edit operations across four domains, while retaining complete authorship provenance at multiple granularities. Experiments with eight document-level, seven sentence-level, and two fine-grained detectors establish that detectability is governed by edit operation, domain, and cumulative revision history in addition to the share of AI content, and that mixed-authorship intermediate versions are often harder to detect than both fully human and heavily AI-edited endpoints.
What carries the argument
OpAI-Bench, the operation-guided benchmark that generates sequential human-to-AI revisions with preserved multi-granularity authorship provenance.
If this is right
- Existing detectors must be evaluated on intermediate mixed versions rather than only pure human or pure AI text.
- Detection difficulty varies systematically with the type of edit performed and the domain of the document.
- Cumulative revision history affects signal strength, so single-pass tests miss important patterns.
- Multi-granularity labeling is required to observe how signals differ at document, sentence, and token scales.
- Benchmarks limited to final outputs cannot capture the non-monotonic detectability observed in progressive editing.
Where Pith is reading between the lines
- Detectors trained only on endpoint texts are likely to underperform on the mixed drafts common in actual use.
- The benchmark sequences could be used to train detectors that explicitly model edit history or operation type.
- Practical applications such as academic integrity checks may need to request earlier drafts when mixed versions are suspected.
- Extending the same progressive construction to other languages or additional edit operations would test whether the non-monotonic pattern generalizes.
Load-bearing premise
The five chosen AI edit operations and their ordered application at fixed coverage levels match the actual steps people take when revising text with AI tools.
What would settle it
A new collection of human-AI co-edited documents in which detection accuracy rises or falls steadily with AI coverage and shows no dependence on operation type, domain, or revision order would falsify the central claim.
Figures

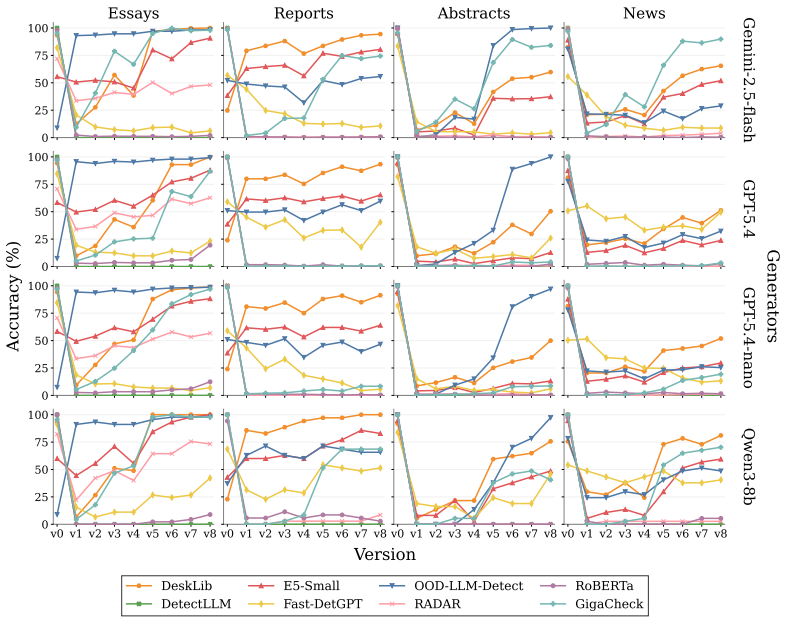
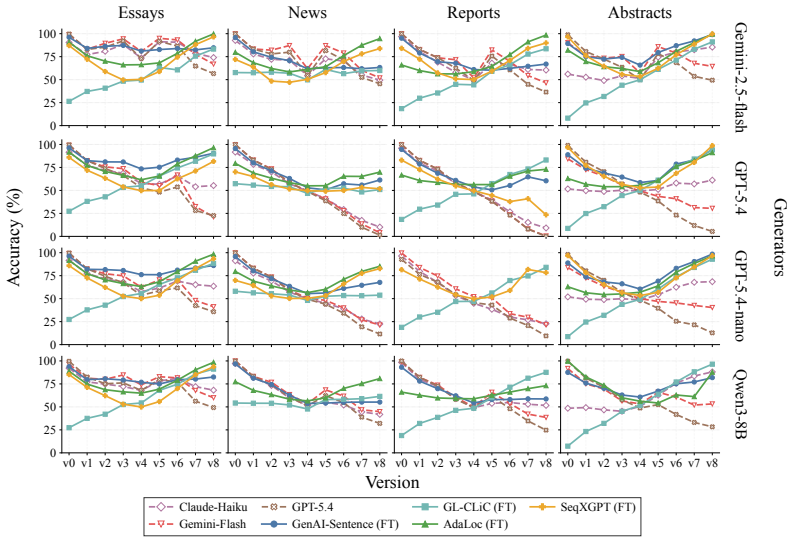

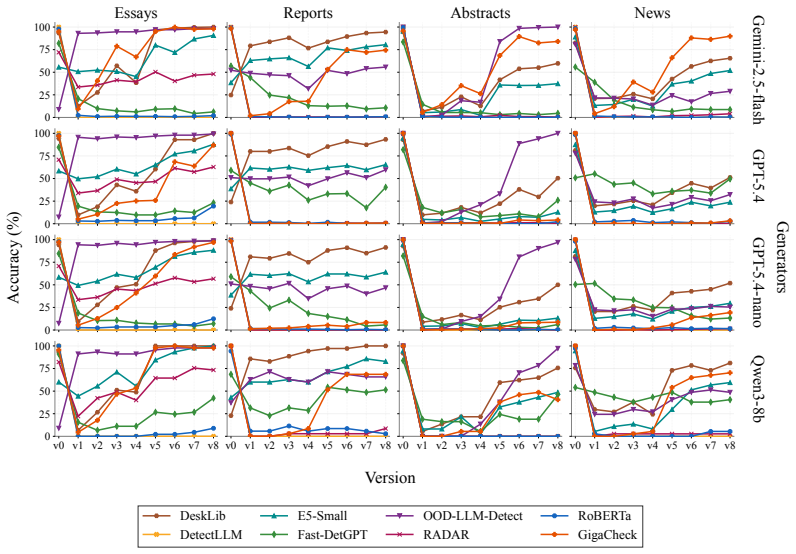
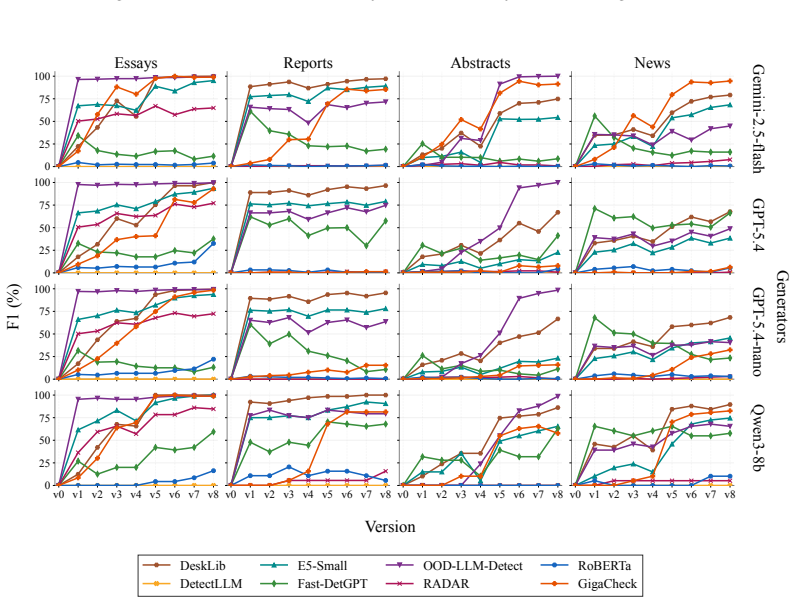
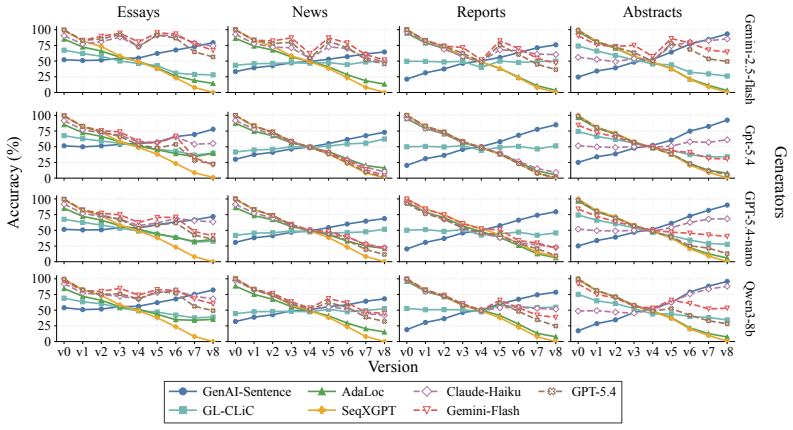
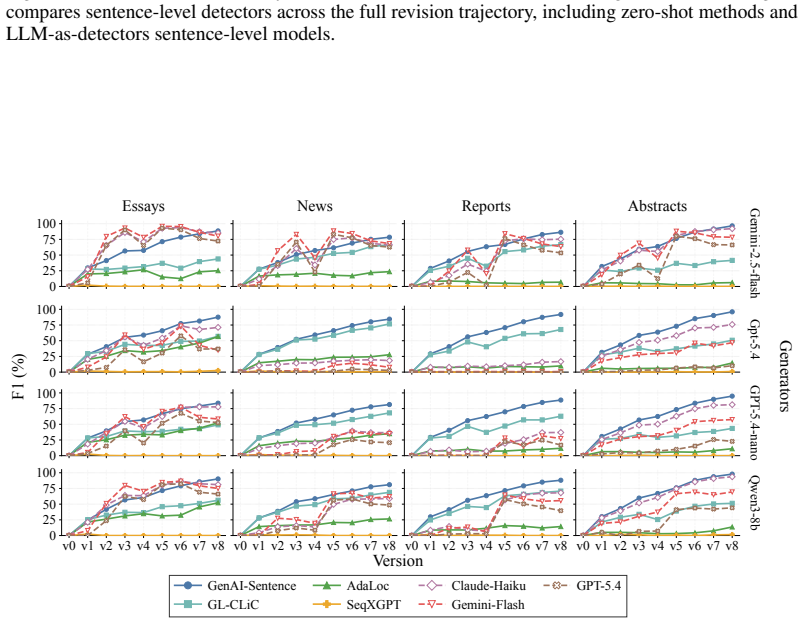
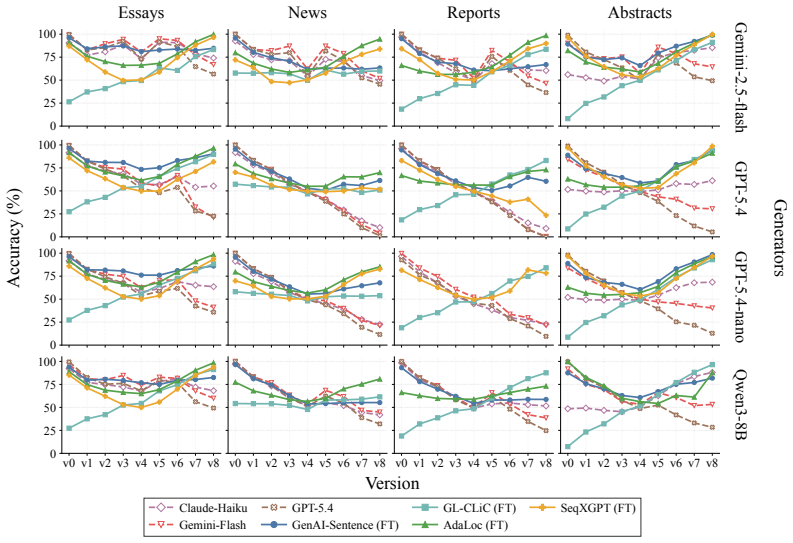
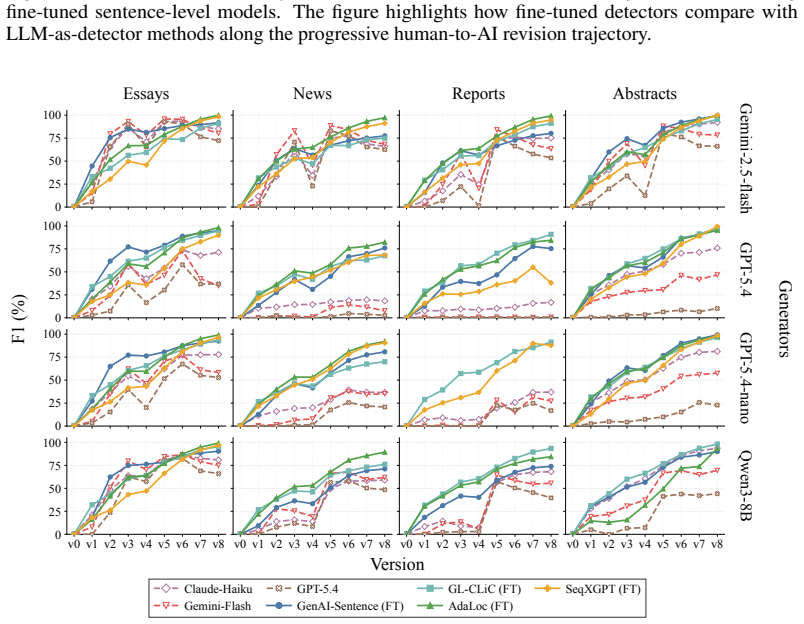
read the original abstract
As AI writing assistants become increasingly integrated into real-world drafting and revision workflows, many documents are no longer purely human-written or AI-generated, but instead result from progressive human-AI co-editing. However, existing AI-text detection benchmarks largely focus on final outputs and provide limited understanding of how AI authorship signals emerge, accumulate, or disappear throughout the revision process. We introduce OpAI-Bench, an operation-guided benchmark for studying progressive human-to-AI text transformation across document, sentence, token, and span granularities. Starting from human-written documents, OpAI-Bench constructs nine sequentially revised versions for each sample under predefined AI coverage levels and five representative AI edit operations, covering four domains while preserving complete authorship provenance at multiple granularities. The benchmark supports comprehensive evaluation with 8 document-level detectors, 7 sentence-level detectors, and 2 fine-grained token/span-level detectors. Experiments reveal that AI-text detectability is governed not only by the proportion of AI-edited content, but also by edit operation, domain, and cumulative revision history. Interestingly, we notice that mixed-authorship intermediate versions are often harder to detect than both fully human and heavily AI-edited endpoints, exposing non-monotonic detection patterns missed by existing benchmarks. OpAI-Bench provides a controlled testbed for analyzing whether, when, and how AI-assisted writing becomes detectable under realistic progressive editing scenarios. Our code and benchmark are available at https://github.com/VILA-Lab/OpAI-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OpAI-Bench, an operation-guided benchmark for multi-granularity AI-text detection during progressive human-to-AI text transformation. Starting from human-written documents in four domains, it generates nine sequentially revised versions per sample by applying five representative AI edit operations at predefined coverage levels while preserving complete authorship provenance at document, sentence, token, and span levels. The benchmark evaluates 8 document-level detectors, 7 sentence-level detectors, and 2 fine-grained detectors; experiments show detectability depends on edit operation, domain, and cumulative revision history, with the key observation that mixed-authorship intermediate versions are often harder to detect than fully human or heavily AI-edited endpoints, exposing non-monotonic patterns missed by prior benchmarks focused on final outputs.
Significance. If the non-monotonic patterns and operation/domain dependencies hold under the benchmark construction, the work provides a valuable controlled testbed for studying how AI signals emerge or diminish across revision steps, addressing a clear gap in existing AI-text detection evaluations. The public release of code and benchmark data is a clear strength that supports reproducibility and extension by the community.
major comments (1)
- [Benchmark construction] Benchmark construction (described in the abstract and methods): the central claim that findings apply to 'realistic progressive editing scenarios' rests on the sequential application of five fixed operations at predefined coverage levels. This controlled process does not incorporate variable human behaviors such as selective acceptance, contextual rewriting, or iterative back-and-forth, raising the possibility that observed non-monotonic patterns are artifacts of the generation procedure rather than intrinsic properties of mixed-authorship text.
minor comments (1)
- [Abstract] The abstract states that the benchmark 'supports comprehensive evaluation' but does not detail how provenance is verified or used in the detector evaluations at each granularity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our manuscript. We address the major comment regarding benchmark construction below.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (described in the abstract and methods): the central claim that findings apply to 'realistic progressive editing scenarios' rests on the sequential application of five fixed operations at predefined coverage levels. This controlled process does not incorporate variable human behaviors such as selective acceptance, contextual rewriting, or iterative back-and-forth, raising the possibility that observed non-monotonic patterns are artifacts of the generation procedure rather than intrinsic properties of mixed-authorship text.
Authors: We agree that our benchmark employs a controlled sequential application of fixed AI edit operations at predefined coverage levels, which does not fully replicate the variability of real human editing behaviors, including selective acceptance, contextual rewriting, or iterative back-and-forth interactions. This design was chosen to ensure complete authorship provenance tracking and to systematically vary edit operations and cumulative revision history in a reproducible manner. The non-monotonic detection patterns we observe are tied to these specific conditions and may indeed differ under more variable human behaviors; however, they demonstrate that such patterns can arise in progressive mixed-authorship scenarios, providing a valuable controlled testbed as noted in the referee summary. We will revise the manuscript to temper claims about applicability to all 'realistic progressive editing scenarios' by clarifying the controlled nature of the benchmark and adding a dedicated limitations subsection discussing this aspect. revision: partial
Circularity Check
No significant circularity; benchmark is explicitly constructed and findings are empirical observations
full rationale
The paper introduces OpAI-Bench by starting from human-written documents and applying five explicitly defined AI edit operations at predefined coverage levels to generate nine sequential versions per sample across domains. All central claims (non-monotonic detectability depending on operation, domain, and revision history) are presented as direct empirical results from evaluating detectors on this constructed dataset. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the provided text. The derivation chain is absent; the work is a controlled benchmark release with transparent construction rules, rendering it self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gl-clic: Global-local coherence and lexical complexity for sentence-level ai-generated text detection
Rizky Adi, Bassamtiano Renaufalgi Irnawan, Yoshimi Suzuki, and Fumiyo Fukumoto. Gl-clic: Global-local coherence and lexical complexity for sentence-level ai-generated text detection. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computation...
2025
-
[2]
Beemo: Benchmark of expert-edited machine-generated outputs
Ekaterina Artemova, Jason S Lucas, Saranya Venkatraman, Joo-Young Lee, Sergei Tilga, Adaku Uchendu, and Vladislav Mikhailov. Beemo: Benchmark of expert-edited machine-generated outputs. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long P...
2025
-
[3]
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. Fast-detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature. arXiv preprint arXiv:2310.05130, 2023
-
[4]
Desklib AI Text Detector v1.01
Desklib. Desklib AI Text Detector v1.01. Hugging Face model, 2024. URL https:// huggingface.co/desklib/ai-text-detector-v1.01 . Fine-tuned DeBERTa-v3-large for AI-generated text detection. Accessed: 2026-05-04
2024
-
[5]
Raid: A shared benchmark for robust evaluation of machine-generated text detectors
Liam Dugan, Alyssa Hwang, Filip Trhlík, Andrew Zhu, Josh Magnus Ludan, Hainiu Xu, Daphne Ippolito, and Chris Callison-Burch. Raid: A shared benchmark for robust evaluation of machine-generated text detectors. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12463–12492, 2024
2024
-
[6]
Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. How close is chatgpt to human experts? comparison corpus, evaluation, and detection.arXiv preprint arXiv:2301.07597, 2023
-
[7]
Mgtbench: Bench- marking machine-generated text detection
Xinlei He, Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. Mgtbench: Bench- marking machine-generated text detection. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 2251–2265, 2024
2024
-
[8]
Yongxin He, Shan Zhang, Yixuan Cao, Lei Ma, and Ping Luo. Detree: Detecting human- ai collaborative texts via tree-structured hierarchical representation learning.arXiv preprint arXiv:2510.17489, 2025
-
[9]
Radar: Robust ai-text detection via adversarial learning.Advances in neural information processing systems, 36:15077–15095, 2023
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. Radar: Robust ai-text detection via adversarial learning.Advances in neural information processing systems, 36:15077–15095, 2023
2023
-
[10]
Efficient attentions for long document summarization
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. Efficient attentions for long document summarization. InProceedings of the 2021 conference of the north American chapter of the association for computational linguistics: Human language technologies, pages 1419–1436, 2021
2021
-
[11]
Sendetex: Sentence-level ai-generated text detection for human-ai hybrid content via style and context fusion
Lei Jiang, Desheng Wu, and Xiaolong Zheng. Sendetex: Sentence-level ai-generated text detection for human-ai hybrid content via style and context fusion. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5287–5302, 2025
2025
-
[12]
Learning agency lab – automated essay scoring 2.0
Learning Agency Lab. Learning agency lab – automated essay scoring 2.0. Kaggle competition, 2024. URL https://www.kaggle.com/competitions/ learning-agency-lab-automated-essay-scoring-2. Accessed: 2026-05-07
2024
-
[13]
Pald: Detection of text partially written by large language models
Eric Lei, Hsiang Hsu, and Chun-Fu Chen. Pald: Detection of text partially written by large language models. InThe Thirteenth International Conference on Learning Representations, 2025. 10
2025
-
[14]
Multitude: Large-scale multi- lingual machine-generated text detection benchmark
Dominik Macko, Robert Moro, Adaku Uchendu, Jason Lucas, Michiharu Yamashita, Matúš Pikuliak, Ivan Srba, Thai Le, Dongwon Lee, Jakub Simko, et al. Multitude: Large-scale multi- lingual machine-generated text detection benchmark. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9960–9987, 2023
2023
-
[15]
Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization
Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 1797–1807, 2018
2018
-
[16]
arxiv paper abstracts
Sayak Paul. arxiv paper abstracts. Kaggle dataset, 2021. URL https://www.kaggle.com/ datasets/spsayakpaul/arxiv-paper-abstracts. Accessed: 2026-04-17
2021
-
[17]
Almost ai, almost human: The challenge of detecting ai- polished writing
Shoumik Saha and Soheil Feizi. Almost ai, almost human: The challenge of detecting ai- polished writing. InFindings of the Association for Computational Linguistics: ACL 2025, pages 25414–25431, 2025
2025
-
[18]
Release Strategies and the Social Impacts of Language Models
Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-V oss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, et al. Release strategies and the social impacts of language models.arXiv preprint arXiv:1908.09203, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[19]
Detectllm: Leveraging log rank infor- mation for zero-shot detection of machine-generated text
Jinyan Su, Terry Zhuo, Di Wang, and Preslav Nakov. Detectllm: Leveraging log rank infor- mation for zero-shot detection of machine-generated text. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412, 2023
2023
-
[20]
Haco-det: A study towards fine-grained machine-generated text detection under human-ai coauthoring
Zhixiong Su, Yichen Wang, Herun Wan, Zhaohan Zhang, and Minnan Luo. Haco-det: A study towards fine-grained machine-generated text detection under human-ai coauthoring. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22015–22036, 2025
2025
-
[21]
Fine-grained detection of ai-generated text using sentence-level segmentation
LDM S Sai Teja, Annepaka Yadagiri, Partha Pakray, Chukhu Chunka, and Mangadoddi Srikar Vardhan. Fine-grained detection of ai-generated text using sentence-level segmentation. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Lingu...
2025
-
[22]
Damasha: Detecting ai in mixed adversarial texts via segmentation with human-interpretable attribution
LDM S Sai Teja, N Siva Gopala Krishna, Ufaq Khan, Muhammad Haris Khan, and Atul Mishra. Damasha: Detecting ai in mixed adversarial texts via segmentation with human-interpretable attribution. InFindings of the Association for Computational Linguistics: EACL 2026, pages 6189–6206, 2026
2026
-
[23]
Editlens: Quantifying the extent of ai editing in text.arXiv preprint arXiv:2510.03154, 2025
Katherine Thai, Bradley Emi, Elyas Masrour, and Mohit Iyyer. Editlens: Quantifying the extent of ai editing in text.arXiv preprint arXiv:2510.03154, 2025
-
[24]
GigaCheck: Detecting LLM-generated Content via Object-Centric Span Localization
Irina Tolstykh, Aleksandra Tsybina, Sergey Yakubson, Aleksandr Gordeev, Vladimir Dokholyan, and Maksim Kuprashevich. Gigacheck: Detecting llm-generated content.arXiv preprint arXiv:2410.23728, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Turingbench: A benchmark environment for turing test in the age of neural text generation
Adaku Uchendu, Zeyu Ma, Thai Le, Rui Zhang, and Dongwon Lee. Turingbench: A benchmark environment for turing test in the age of neural text generation. InFindings of the association for computational linguistics: EMNLP 2021, pages 2001–2016, 2021
2021
-
[26]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Seqxgpt: Sentence-level ai-generated text detection
Pengyu Wang, Linyang Li, Ke Ren, Botian Jiang, Dong Zhang, and Xipeng Qiu. Seqxgpt: Sentence-level ai-generated text detection. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1144–1156, 2023
2023
-
[28]
M4gt- bench: Evaluation benchmark for black-box machine-generated text detection
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Osama Mohammed Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, et al. M4gt- bench: Evaluation benchmark for black-box machine-generated text detection. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
2024
-
[29]
M4: Multi-generator, multi-domain, and multi-lingual black-box machine-generated text detec- tion
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Chenxi Whitehouse, Osama Mohammed Afzal, Tarek Mahmoud, Toru Sasaki, et al. M4: Multi-generator, multi-domain, and multi-lingual black-box machine-generated text detec- tion. InProceedings of the 18th Conference of the European Chapter of the Association for Computationa...
2024
-
[30]
Detectrl: Benchmarking llm-generated text detection in real-world scenarios.Advances in Neural Information Processing Systems, 37:100369–100401, 2024
Junchao Wu, Runzhe Zhan, Derek F Wong, Shu Yang, Xinyi Yang, Yulin Yuan, and Lidia S Chao. Detectrl: Benchmarking llm-generated text detection in real-world scenarios.Advances in Neural Information Processing Systems, 37:100369–100401, 2024
2024
-
[31]
Cong Zeng, Shengkun Tang, Yuanzhou Chen, Zhiqiang Shen, Wenchao Yu, Xujiang Zhao, Haifeng Chen, Wei Cheng, and Zhiqiang Xu. Human texts are outliers: Detecting llm-generated texts via out-of-distribution detection.arXiv preprint arXiv:2510.08602, 2025
-
[32]
Llm-as-a-coauthor: Can mixed human-written and machine-generated text be detected? InFindings of the Association for Computational Linguistics: NAACL 2024, pages 409–436, 2024
Qihui Zhang, Chujie Gao, Dongping Chen, Yue Huang, Yixin Huang, Zhenyang Sun, Shilin Zhang, Weiye Li, Zhengyan Fu, Yao Wan, et al. Llm-as-a-coauthor: Can mixed human-written and machine-generated text be detected? InFindings of the Association for Computational Linguistics: NAACL 2024, pages 409–436, 2024
2024
-
[33]
Machine-generated text localization
Zhongping Zhang, Wenda Qin, and Bryan Plummer. Machine-generated text localization. In Findings of the Association for Computational Linguistics: ACL 2024, pages 8357–8371, 2024. 12 Appendix A Limitations OpAI-Bench provides a controlled benchmark for studying progressive human-to-AI text transforma- tion, but it still has several limitations. First, the ...
2024
-
[34]
AdaLoc[ 33] is a sentence-level classifier over RoBERTa-large with a sliding window of three adjacent sentences: every window position emits an AI/human label, and overlapping scores are averaged into one prediction per sentence
-
[35]
RADAR[ 9] is a Vicuna-7B classifier trained adversarially against a paraphraser: the para- phraser produces hard negatives during training, pushing the classifier to learn signals that survive paraphrasing
-
[36]
AI text has higher curvature than human text and the whole score is computed in a single forward pass
Fast-DetectGPT[ 3] is zero-shot and scores a candidate by itsconditional probability curvature: the likelihood of the observed tokens under a scoring LM is compared to the average likelihood of perturbed alternatives drawn from a sampling LM. AI text has higher curvature than human text and the whole score is computed in a single forward pass
-
[37]
DAMASHA[ 22] is a token-level CRF tagger over a dual encoder. RoBERTa-base and ModernBERT-base read the same input; their hidden states are fused by an Info-Mask layer driven by simple stylistic features, and the CRF decodes the per-token AI/human tag sequence. 13
-
[38]
GigaCheck[ 24] is a DETR-style span detector on top of Mistral-7B: the LM encodes tokens and a DETR decoder predicts a fixed-size set of character intervals, each labelled AI or human, alongside a coarse document-level head
-
[39]
Desklib[ 4] is a single-transformer document-level classifier; we use the public Hugging Face release out of the box, with no further training
-
[40]
We use the public weights directly as a document-level binary classifier
E5-small[ 26] is an E5-small encoder with a LoRA adapter trained for AI-text classification by the original authors. We use the public weights directly as a document-level binary classifier
-
[41]
OOD-LLM-Detect[ 31] treats AI-text detection as one-class classification: a Deep SVDD model is fitted to language-model embeddings of human text only, and a candidate is scored by its distance from the learnt human-text region
-
[42]
RoBERTa-OpenAI[ 18] is RoBERTa-base fine-tuned by OpenAI on GPT-2 outputs; we use the released document-level binary classifier as is
-
[43]
Both capture how unusually high-ranked the observed tokens are under the reference distribution
DetectLLM[ 19] is zero-shot and combines two ranking statistics under a single reference causal LM: the log-rank ratio (LRR) and the normalised perturbation rank (NPR). Both capture how unusually high-ranked the observed tokens are under the reference distribution
-
[44]
GL-CLiC[ 1] is a sentence-level classifier whose feature vector concatenates a DeBERTa contextual embedding, per-sentence global–local coherence scores, and per-sentence lexical complexity statistics; the resulting features are passed through a small classification head
-
[45]
A small CNN + Transformer + CRF stack reads this matrix and emits per-word labels, which are aggregated to sentence level
SeqXGPT[ 27] represents each token by its log-probability under four reference LMs (gpt2-xl, gpt-neo-2.7B, gpt-j-6B, llama-7B), yielding a (T,4) feature matrix. A small CNN + Transformer + CRF stack reads this matrix and emits per-word labels, which are aggregated to sentence level
-
[46]
GPT-5.4(reasoning level: none) is an API-based judge prompted with the candidate docu- ment and asked to return a per-sentence AI/human label list directly
-
[47]
Gemini 3 Flash(thinking level: minimal) is an API-based judge prompted with the candidate document and asked to return a per-sentence AI/human label list directly
-
[48]
Claude Haiku 4.5(reasoning level: minimal) is an API-based judge prompted with the candidate document and asked to return a per-sentence AI/human label list directly
-
[49]
"" [numbered_sentences]
GenAI-Sentence[ 21] is a token-level CRF tagger: a DeBERTa backbone feeds a BiGRU encoder, a linear classifier, and a CRF decoder that emits per-token AI/human labels; sentence labels are obtained by aggregation. E Implementation Details E.1 Text Normalization and Segmentation All source documents are normalized prior to processing: line endings are stand...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.