Synthetic Benchmarks Overstate Forward-Forward Scaling: Real-Data Limits of Layer-Local Training
Pith reviewed 2026-06-28 02:11 UTC · model grok-4.3
The pith
Forward-Forward training trails backpropagation on real images once class count and resolution increase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
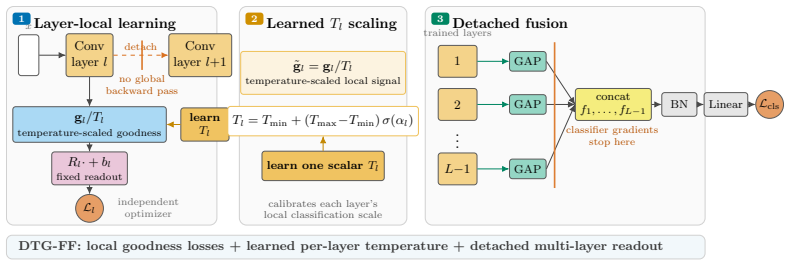
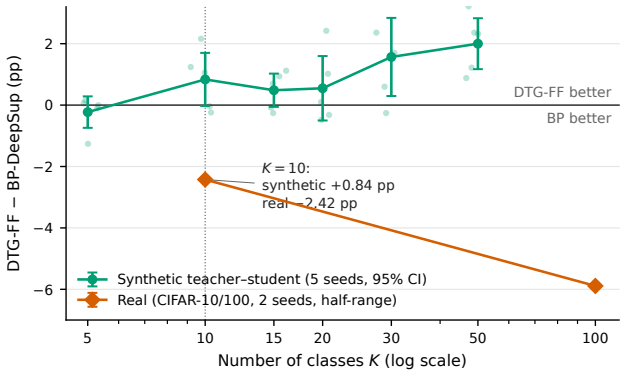
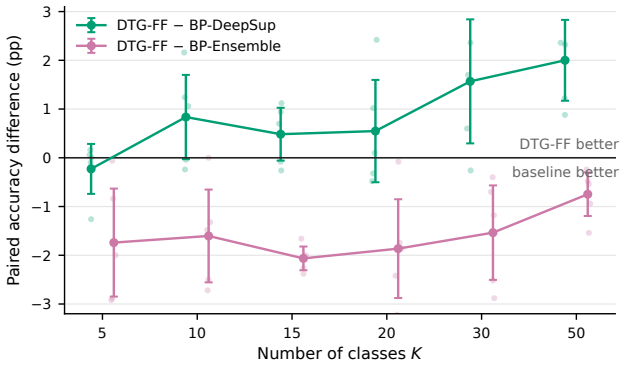
Layer-local Forward-Forward training reaches a performance ceiling on real data that remains hidden on 32 by 32 synthetic-style tasks. DTG-FF, built from dynamic temperature goodness, decoupled normalization, and multi-layer fusion, achieves 91.8 percent on CIFAR-10 and provides the first Forward-Forward result on ImageNet-100 at 224 by 224, yet still trails the backpropagation baseline by widening margins as class count grows; the same pattern appears when coarse versus fine labels are compared inside CIFAR-100.
What carries the argument
DTG-FF, the instrument that combines dynamic temperature goodness, decoupled normalization, and multi-layer fusion to raise the Forward-Forward state of the art.
If this is right
- The accuracy gap between Forward-Forward and backpropagation widens steadily with the number of classes on real images.
- Synthetic teacher-student tasks overstate Forward-Forward transferability because they tie class count to fine-grained discrimination difficulty.
- Forward-Forward offers no clear memory advantage on 8 GB hardware once gradient accumulation is allowed for the backpropagation baseline.
Where Pith is reading between the lines
- If the real-data ceiling holds, layer-local methods may need mechanisms outside pure goodness updates to match backpropagation at scale.
- Benchmark suites for alternative training should include controlled sweeps of class count and resolution to avoid the synthetic-real reversal shown here.
- The within-dataset coarse-fine probe offers a template for separating label hierarchy effects from image statistics in other training paradigms.
Load-bearing premise
That DTG-FF stands for the strongest possible member of the Forward-Forward family and that the backpropagation baseline receives no systematic help from global gradient flow.
What would settle it
A new Forward-Forward variant that closes the gap to the backpropagation baseline to within two points on CIFAR-100 or reaches above 70 percent at 224 by 224 resolution.
Figures
read the original abstract
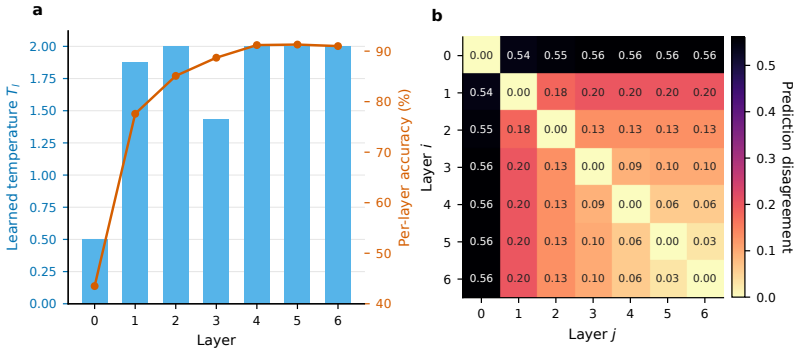
Forward-Forward (FF) learning [Hinton, 2022] replaces backpropagation with strictly layer-local goodness updates. Recent FF-CNN work has narrowed the gap to BP on 32x32 benchmarks, raising the question of whether layer-local training is becoming a viable alternative at realistic scale. To probe this rigorously, we develop DTG-FF -- dynamic temperature goodness, decoupled normalization, and multi-layer fusion -- as an instrument that sets FF-family state of the art across nine real-data benchmarks (91.8% CIFAR-10 and the first FF baseline at ImageNet-100 224x224), and use it to audit how far layer-local training actually scales. (1) Real-data scaling. Under identical recipe and backbone, an architecture-matched BP-DeepSup baseline beats DTG-FF by 2.40/5.93 pp on CIFAR-10/CIFAR-100, and the gap widens with class count. At 224x224 the same instrument reaches only 49.4% -- the first FF baseline at this scale, versus typical BP above 75% [Tian et al., 2020] -- exposing a real-data ceiling invisible at 32x32. (2) Synthetic vs. real K-conflict. DTG-FF increasingly outperforms BP as class count K grows on synthetic teacher-student tasks, yet on real images the FF-BP gap reverses sign and widens with K. A within-dataset CIFAR-100 coarse vs. fine probe isolates label-hierarchy from image distribution: synthetic K-sweeps confound output dimensionality with fine-grained discrimination difficulty and thereby overstate FF transferability. (3) Systems audit. FF can be implemented without storing depth-wide activations, but on commodity 8 GB hardware standard BP+gradient-accumulation reaches 4.18 GB / 157 imgs/s versus DTG-FF's 7.90 GB / 138 imgs/s, so a memory-based justification for FF at this scale is not supported under fair baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DTG-FF (dynamic temperature goodness, decoupled normalization, multi-layer fusion) as an enhanced Forward-Forward method that sets FF SOTA on nine real benchmarks (91.8% CIFAR-10; first FF result on ImageNet-100 at 224x224). Under identical recipe and backbone it trails an architecture-matched BP-DeepSup baseline by 2.40/5.93 pp on CIFAR-10/100 (gap widens with class count K); at 224x224 it reaches 49.4% versus typical BP >75%. Synthetic teacher-student tasks show FF outperforming BP with growing K, but real-data probes reverse this; a CIFAR-100 coarse/fine split isolates label hierarchy. Systems audit finds no memory advantage for FF on 8 GB hardware.
Significance. If the empirical comparisons hold, the work supplies the first controlled demonstration that layer-local training hits a ceiling on real images at realistic resolution and class count that is invisible on 32x32 or synthetic data. Credit is due for the within-dataset hierarchy probe, the architecture-matched CIFAR baselines, and the provision of the first 224x224 FF baseline.
major comments (1)
- [Abstract] Abstract (and corresponding results section): the 224x224 claim states DTG-FF reaches 49.4% 'versus typical BP above 75% [Tian et al., 2020]' without showing that the cited BP baseline matches backbone, depth, width, augmentation or schedule, in contrast to the explicitly architecture-matched BP-DeepSup baseline used for the CIFAR-10/100 numbers. Because this comparison is load-bearing for the headline assertion of a 'real-data ceiling invisible at 32x32', the gap cannot yet be unambiguously attributed to layer-local versus global training.
minor comments (2)
- [Methods] Methods: exact hyperparameter tables and a complete specification of DTG-FF components are missing; error bars are not reported on the claimed numerical gaps.
- [Results] Results: the synthetic K-sweep description should explicitly state whether output dimensionality is controlled independently of fine-grained discrimination difficulty.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The point about the ImageNet-100 comparison is well taken, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and corresponding results section): the 224x224 claim states DTG-FF reaches 49.4% 'versus typical BP above 75% [Tian et al., 2020]' without showing that the cited BP baseline matches backbone, depth, width, augmentation or schedule, in contrast to the explicitly architecture-matched BP-DeepSup baseline used for the CIFAR-10/100 numbers. Because this comparison is load-bearing for the headline assertion of a 'real-data ceiling invisible at 32x32', the gap cannot yet be unambiguously attributed to layer-local versus global training.
Authors: We agree that the 224x224 BP comparison is not architecture-matched in the same controlled manner as the CIFAR-10/100 experiments. The cited figure from Tian et al. (2020) reflects standard supervised BP performance on ImageNet-scale data rather than an identical backbone, depth, width, augmentation, or schedule. In the revised manuscript we will explicitly qualify this in both the abstract and results section, stating that the comparison is to typical BP results from the literature (in contrast to our matched CIFAR baselines) and noting that a fully architecture-matched BP-DeepSup run at 224x224 would be a valuable addition for future work. The core claim—that DTG-FF supplies the first published FF baseline at this resolution and that its absolute accuracy remains substantially below standard BP—remains intact, but the revision will remove any implication of direct attribution without matched controls. revision: yes
Circularity Check
No circularity: all claims are direct empirical comparisons on public benchmarks
full rationale
The paper reports measured accuracies of DTG-FF versus architecture-matched BP-DeepSup baselines on CIFAR-10/100 and a first-reported FF result at 224x224 ImageNet-100 scale. These are straightforward experimental outcomes against external datasets and literature numbers; no equations, parameter fits, or predictions are defined in terms of the reported quantities themselves. The single external citation [Tian et al., 2020] supplies a benchmark reference rather than a load-bearing uniqueness theorem or ansatz. No self-citation chain, self-definitional construction, or fitted-input-renamed-as-prediction appears in the derivation of the scaling claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The forward-forward algorithm: Some preliminary investigations
Geoffrey Hinton. The forward-forward algorithm: Some preliminary investigations. InNeurIPS 2022 Workshop,
2022
-
[2]
Yonglong Tian, Dilip Krishnan, and Phillip Isola
arXiv:2212.13345. Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. InEuropean Conference on Computer Vision (ECCV),
-
[3]
Local signal adaptation in the forward-forward algorithm.arXiv preprint arXiv:2305.12466,
Davide Tosato, Mark Shann, Halis Erdogan, and Bertrand Lebichot. Local signal adaptation in the forward-forward algorithm.arXiv preprint arXiv:2305.12466,
-
[4]
Yoshua Bengio. How auto-encoders could provide credit assignment in deep networks via target propagation.arXiv preprint arXiv:1407.7906,
-
[5]
Opening the black box of deep neural networks via information
Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810,
-
[6]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
-
[7]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
doi: 10.1371/journal.pone.0087357. Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16,
-
[8]
PyTorch FSDP: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277,
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. PyTorch FSDP: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277,
-
[9]
[2023], Zhao et al
for MLP; Tosato et al. [2023], Zhao et al
2023
-
[10]
When ml ≫1, K-way CE is well-defined and we adopt it
for FF-CNN), supported by a dimensionality argument: when ml =1, the linear readout ak =r lk gl/Tl +b lk from a scalar to K logits has rank 1 by construction (image is 1-dimensional), so softmax realizes only a 1-parameter family of class distributions and margin supervision is the natural choice. When ml ≫1, K-way CE is well-defined and we adopt it. We d...
2019
-
[11]
(PFF) combined FF with predictive coding, re-introducing partial inter-layer coordination. Spatial goodness attribution.We want to clearly credit prior work: spatial goodness vectors (as opposed to scalar goodness) originated in the FF-CNN literature, notably ASGE [Zhao et al., 2024] and LSFF [Tosato et al., 2023]. Our Pathway 1 (signal quality) in Sec. 3...
2024
-
[12]
retained information
showed predictive coding, EqProp, and contrastive Hebbian learning approximate BP in a unified limit. Predictive coding networks provide structured backward signals via prediction errors [Rao and Ballard, 1999, Whittington and Bogacz, 2017, Millidge et al., 2022, Salvatori et al., 2023]. Perturbation-based methods use input modulation [Dellaferrera and Kr...
1999
-
[13]
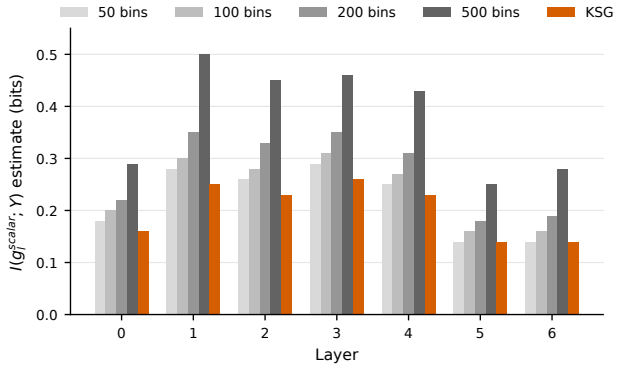
MI estimation in high dimensions is notoriously hard [Belghazi et al., 2018, Poole et al., 2019, McAllester and Stratos, 2020]
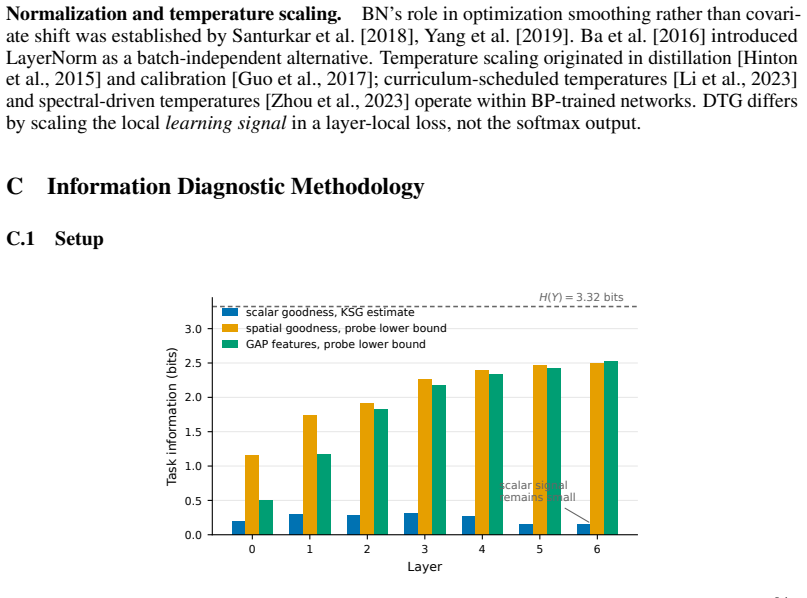
showed compression depends on activation function—ReLU networks do not compress in the same sense as tanh networks. MI estimation in high dimensions is notoriously hard [Belghazi et al., 2018, Poole et al., 2019, McAllester and Stratos, 2020]. Our measurements (App. C) avoid deep estimator reliance by using scalar KSG [Kraskov et al., 2004] and linear-pro...
2018
-
[14]
introduced LayerNorm as a batch-independent alternative. Temperature scaling originated in distillation [Hinton et al., 2015] and calibration [Guo et al., 2017]; curriculum-scheduled temperatures [Li et al., 2023] and spectral-driven temperatures [Zhou et al., 2023] operate within BP-trained networks. DTG differs by scaling the locallearning signalin a la...
2015
-
[15]
any layer correct
extension of KSG for continuous-feature/discrete-target MI. As a sensitivity check we also compute histogram-based MI with bin counts{50,100,200,500}. Vector MI lower bound.For gvec l and fGAP l , we train a linear probe (softmax regression) on an 80/20 split of the test set—50 epochs Adam, lr = 0.01, inputs standardized by training-split statistics. Let ...
2048
-
[16]
effective receptive fields
and applies 2×2 pooling at the first layer, while VGG8 retains full resolution through layer 1; VGG11 thus differs from VGG8 in depth (8 vs. 7 conv layers), early-channel width (64 vs. 128), and downsampling schedule. The accuracy drop reported here therefore bundles depth and width effects, and we cannot strictly attribute the cost to depth alone. A dept...
2025
-
[17]
Smaller models or larger device memory (e.g., RTX 409024 GB) push the cliff further out and the same-batch advantage shrinks to the modest in-VRAM numbers reported in the main text
to host-IO-bound (>8 s at batch 128). Smaller models or larger device memory (e.g., RTX 409024 GB) push the cliff further out and the same-batch advantage shrinks to the modest in-VRAM numbers reported in the main text. Fair BP baselines.We compare DTG-FF at batch 128 on VGG11 224×224 against three BP variants designed to recover memory headroom (all meas...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.