FAIR-Calib: Frontier-Aware Instability-Reweighted Calibration for Post-Training Quantization of Diffusion Large Language Models
Pith reviewed 2026-06-28 02:31 UTC · model grok-4.3
The pith
FAIR-Calib protects fragile early token decisions in diffusion LLMs during quantization by reweighting calibration around a frontier position prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
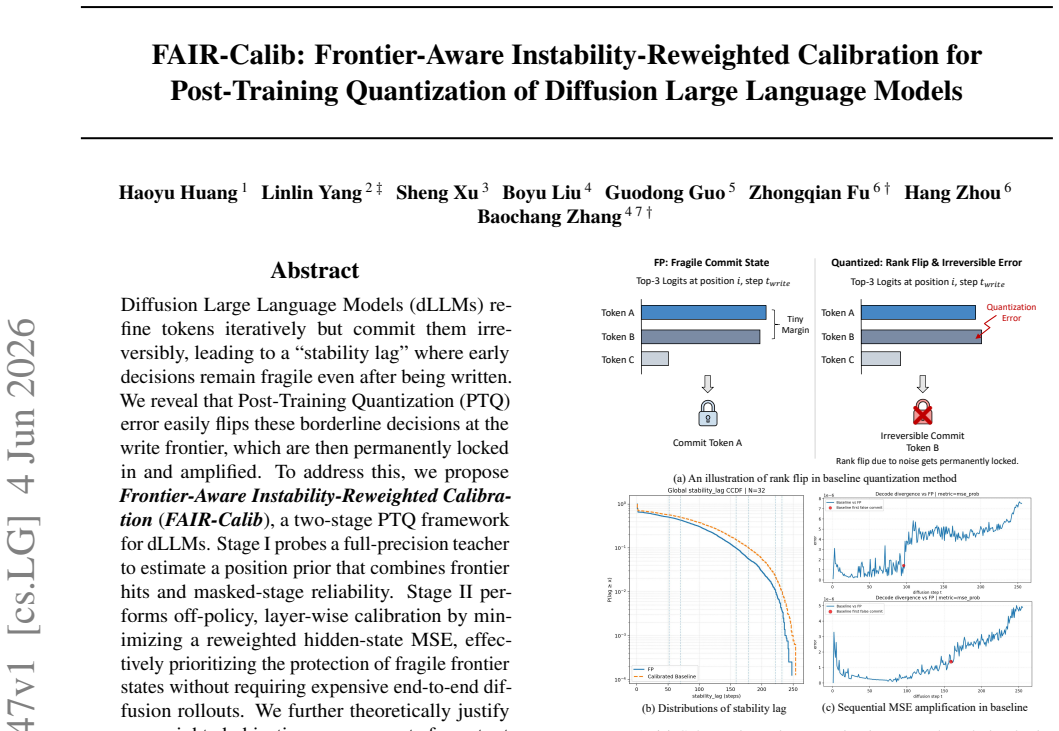
The authors establish that post-training quantization errors in diffusion LLMs disproportionately affect the write frontier due to stability lag in token commitment, and that a frontier-aware instability-reweighted calibration using a position prior from the teacher model minimizes a surrogate for output KL divergence, leading to fewer flips and better quantized performance.
What carries the argument
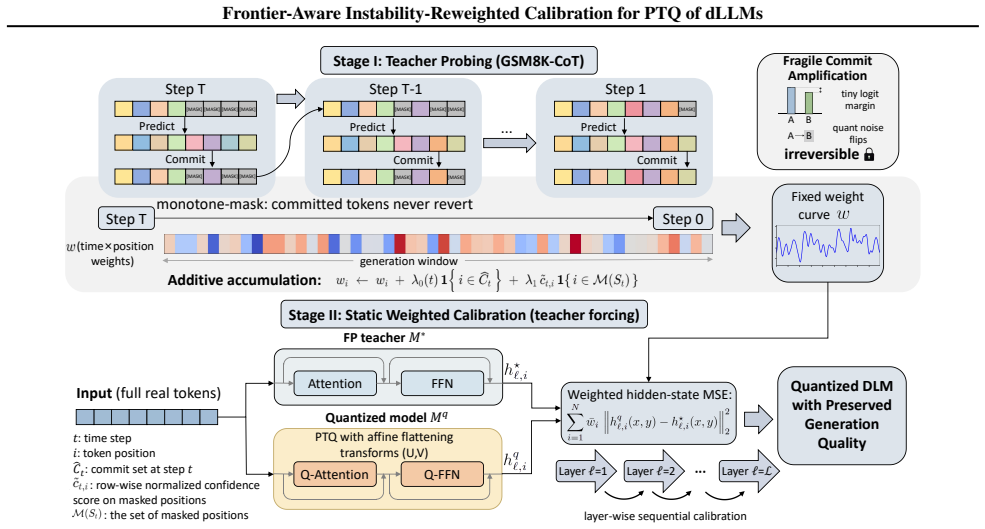
Frontier-Aware Instability-Reweighted Calibration (FAIR-Calib), a two-stage PTQ framework that estimates a position prior of frontier hits and reliability then applies reweighted hidden-state MSE to prioritize fragile states.
If this is right
- Consistently outperforms state-of-the-art PTQ baselines on LLaDA and Dream under W4A4 settings.
- Significantly reduces frontier decision flips in the quantized model outputs.
- Suppresses post-commit mismatches across diverse benchmarks.
- Enables effective layer-wise calibration without requiring expensive end-to-end diffusion rollouts.
- The reweighted hidden-state MSE objective serves as a surrogate for minimizing output KL divergence.
Where Pith is reading between the lines
- The two-stage prior-plus-reweighting structure could transfer to other iterative token-generation settings where early commitments affect later quality.
- If the teacher-derived prior proves robust, similar lightweight position estimates might support quantization or pruning in non-diffusion autoregressive models.
- Lower bit widths such as W3A3 become more feasible once frontier states receive explicit protection during calibration.
- Dynamic updating of the position prior during inference could further reduce mismatches on long sequences.
Load-bearing premise
The position prior estimated from the full-precision teacher in Stage I accurately identifies the fragile frontier states that matter most for final output quality, without needing end-to-end diffusion rollouts during calibration.
What would settle it
Running the same LLaDA or Dream models with a calibration procedure that includes full end-to-end diffusion rollouts and measuring whether it produces lower frontier flip rates or higher benchmark scores than FAIR-Calib would settle whether the prior is sufficient.
Figures
read the original abstract
Diffusion Large Language Models (dLLMs) refine tokens iteratively but commit them irreversibly, leading to a "stability lag" where early decisions remain fragile even after being written. We reveal that Post-Training Quantization (PTQ) error easily flips these borderline decisions at the write frontier, which are then permanently locked in and amplified. To address this, we propose Frontier-Aware Instability-Reweighted Calibration (FAIR-Calib), a two-stage PTQ framework for dLLMs. Stage I probes a full-precision teacher to estimate a position prior that combines frontier hits and masked-stage reliability. Stage II performs off-policy, layer-wise calibration by minimizing a reweighted hidden-state MSE, effectively prioritizing the protection of fragile frontier states without requiring expensive end-to-end diffusion rollouts. We further theoretically justify our weighted objective as a surrogate for output KL divergence. Empirically, FAIR-Calib consistently outperforms state-of-the-art baselines on LLaDA and Dream (W4A4), significantly reducing frontier decision flips and suppressing post-commit mismatches across diverse benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FAIR-Calib, a two-stage PTQ framework for diffusion LLMs (dLLMs). Stage I uses a full-precision teacher to compute a position prior from frontier hits and masked-stage reliability. Stage II performs layer-wise off-policy calibration via a reweighted hidden-state MSE objective that prioritizes fragile frontier states, without end-to-end rollouts. The weighted objective is claimed to be a theoretical surrogate for output KL divergence. Empirically, it outperforms baselines on LLaDA and Dream under W4A4 quantization by reducing frontier decision flips and post-commit mismatches.
Significance. If the central claims hold, the work offers a practical solution to stability issues in quantized dLLMs arising from irreversible token commitment. The off-policy, rollout-free calibration is a notable engineering strength for large models. The focus on frontier states is well-motivated by the diffusion process. However, the absence of verifiable derivation for the KL surrogate and direct evidence linking the Stage-I prior to output quality limits the assessed significance.
major comments (3)
- [Stage I] Abstract and Stage I description: the position prior (frontier hits + masked-stage reliability) is asserted to identify fragile states whose protection reduces final decision flips, but no correlation analysis or end-to-end validation against post-quantization KL or flip rates is provided; this is load-bearing for the claim that the reweighted MSE is an effective surrogate.
- [Theoretical justification] Theoretical justification: the abstract states that the reweighted hidden-state MSE is a surrogate for output KL divergence, yet no derivation, equations, or proof sketch is shown, leaving open whether the weighting reduces to a fitted quantity or introduces circularity.
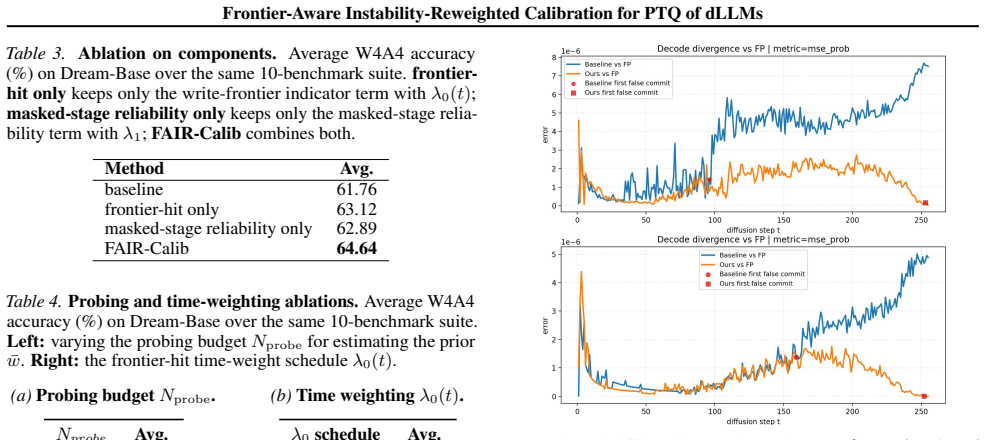
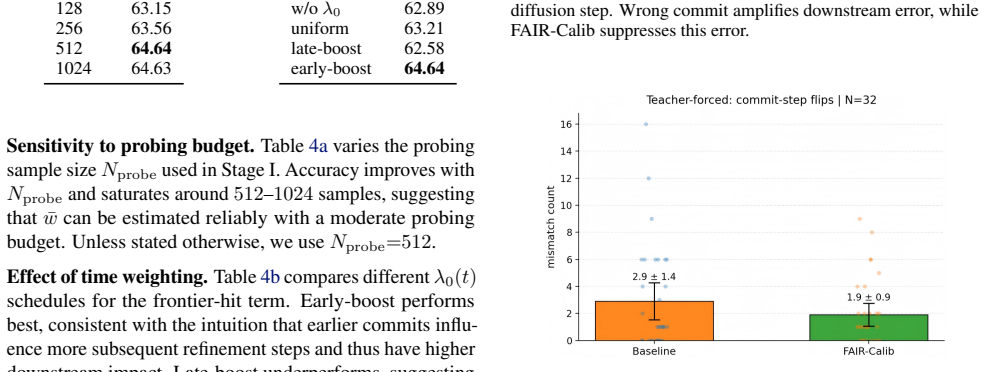
- [Experiments] Empirical evaluation: the claim of consistent outperformance on LLaDA and Dream (W4A4) with reduced frontier flips lacks reported baselines, exact metrics for decision flips, error bars, or ablation on the prior's contribution, preventing assessment of whether gains generalize beyond the tested setups.
minor comments (2)
- [Stage I] Notation for 'frontier hits' and 'masked-stage reliability' should be defined with explicit formulas in Stage I to improve reproducibility.
- [Experiments] The manuscript would benefit from a table comparing decision-flip rates and KL values across all baselines rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to improve clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [Stage I] Abstract and Stage I description: the position prior (frontier hits + masked-stage reliability) is asserted to identify fragile states whose protection reduces final decision flips, but no correlation analysis or end-to-end validation against post-quantization KL or flip rates is provided; this is load-bearing for the claim that the reweighted MSE is an effective surrogate.
Authors: We agree that the manuscript would be strengthened by explicit correlation analysis linking the Stage I position prior to post-quantization outcomes. In the revision we will add a new subsection with quantitative correlation results (Pearson coefficients and scatter plots) between the frontier-hit + masked-stage reliability scores and observed reductions in frontier decision flips and output KL, computed on the same calibration data used for Stage II. This analysis remains off-policy and does not require end-to-end rollouts. revision: yes
-
Referee: [Theoretical justification] Theoretical justification: the abstract states that the reweighted hidden-state MSE is a surrogate for output KL divergence, yet no derivation, equations, or proof sketch is shown, leaving open whether the weighting reduces to a fitted quantity or introduces circularity.
Authors: The current manuscript contains a brief justification but lacks a self-contained derivation. We will expand the theoretical section to include a step-by-step derivation starting from the output KL between full-precision and quantized diffusion trajectories, showing under the stated diffusion-process assumptions how the instability-reweighted hidden-state MSE serves as a tractable surrogate. The expanded section will contain the explicit equations and a short proof sketch to address concerns about circularity or fitting. revision: yes
-
Referee: [Experiments] Empirical evaluation: the claim of consistent outperformance on LLaDA and Dream (W4A4) with reduced frontier flips lacks reported baselines, exact metrics for decision flips, error bars, or ablation on the prior's contribution, preventing assessment of whether gains generalize beyond the tested setups.
Authors: We will revise the experimental section to include: (i) complete baseline tables with all compared methods and exact numerical scores, (ii) a precise definition and reported values for the frontier decision-flip metric, (iii) error bars computed over multiple random seeds, and (iv) an ablation study that isolates the contribution of the Stage I prior. These additions will be placed in the main results and supplementary material. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a two-stage PTQ method: Stage I estimates a position prior (frontier hits + masked-stage reliability) from the full-precision teacher, and Stage II minimizes a reweighted hidden-state MSE claimed to be a surrogate for output KL divergence. The abstract states the justification exists, but the provided text contains no equations or reductions showing that the weighted objective or prior is equivalent to its inputs by construction, a fitted parameter renamed as prediction, or dependent on self-citation chains. The central empirical claims rest on outperformance on LLaDA/Dream (W4A4) and the assumption that the prior identifies fragile states, which is an external hypothesis rather than a self-referential definition. No load-bearing step reduces to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Position prior from full-precision teacher accurately identifies fragile frontier states
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Chen, M. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pre- trained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Ghazvininejad, M., Levy, O., Liu, Y ., and Zettlemoyer, L. Mask-predict: Parallel decoding of conditional masked language models.arXiv preprint arXiv:1904.09324,
-
[7]
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Gong, S., Li, M., Feng, J., Wu, Z., and Kong, L. Diffuseq: Sequence to sequence text generation with diffusion mod- els.arXiv preprint arXiv:2210.08933,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
9 Frontier-Aware Instability-Reweighted Calibration for PTQ of dLLMs Lin, H., Xu, H., Wu, Y ., Guo, Z., Zhang, R., Lu, Z., Wei, Y ., Zhang, Q., and Sun, Z. Quantization meets dllms: A sys- tematic study of post-training quantization for diffusion llms.arXiv preprint arXiv:2508.14896,
-
[10]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Shao, W., Chen, M., Zhang, Z., Xu, P., Zhao, L., Li, Z., Zhang, K., Gao, P., Qiao, Y ., and Luo, P. Omniquant: Omnidirectionally calibrated quantization for large lan- guage models.arXiv preprint arXiv:2308.13137,
-
[13]
Shi, J. and Titsias, M. K. Demystifying diffusion objectives: Reweighted losses are better variational bounds.arXiv preprint arXiv:2511.19664,
-
[14]
Flatquant: Flatness matters for llm quantization.arXiv preprint arXiv:2410.09426,
Sun, Y ., Liu, R., Bai, H., Bao, H., Zhao, K., Li, Y ., Hu, J., Yu, X., Hou, L., Yuan, C., et al. Flatquant: Flatness matters for llm quantization.arXiv preprint arXiv:2410.09426,
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Tseng, A., Chee, J., Sun, Q., Kuleshov, V ., and De Sa, C. Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.arXiv preprint arXiv:2402.04396,
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Dream 7B: Diffusion Large Language Models
Ye, J., Xie, Z., Zheng, L., Gao, J., Wu, Z., Jiang, X., Li, Z., and Kong, L. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
HellaSwag: Can a Machine Really Finish Your Sentence?
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[20]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., et al. Llada 1.5: Variance- reduced preference optimization for large language diffu- sion models.arXiv preprint arXiv:2505.19223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
This motivates estimatingstructural importanceover (t, i) and then aggregating it into a static position prior
suggests an additive time×position structure that different positions contributeunequallyto the output divergence: a position matters only when it is updated, and its impact depends on both when it is updated and how sensitive its token distribution is to perturbations. This motivates estimatingstructural importanceover (t, i) and then aggregating it into...
2023
-
[22]
Unless stated otherwise, we use each model’s default inference-time commit policy for all accuracy evaluations (Dream: entropy-driven; LLaDA: confidence-driven)
andDream(Base/Instruct) (Ye et al., 2025). Unless stated otherwise, we use each model’s default inference-time commit policy for all accuracy evaluations (Dream: entropy-driven; LLaDA: confidence-driven). We report performance on a diverse benchmark suite covering commonsense reasoning and NLU (PIQA (Bisk et al., 2020), BoolQ (Clark et al., 2019), WinoGra...
2025
-
[23]
under the same W4A4 PTQ setting. All baselines use 128 calibration sequences from WikiText2 (Merity et al., 2016). QuaRot is calibrated with GPTQ, while FlatQuant and RTN use RTN-style reconstruction. Following the default settings of each method, QuaRot and FlatQuant calibrate with sequence length 2048 for Dream and 4096 for LLaDA; unless stated otherwis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.