FIGMA: Towards FIne-Grained Music retrievAl
Pith reviewed 2026-06-27 23:30 UTC · model grok-4.3
The pith
FIGMA uses multi-view contrastive learning to retrieve music matching fine details such as tempo, key and chord progressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
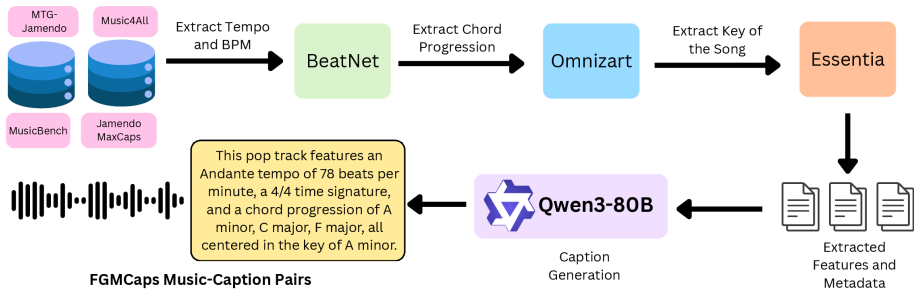
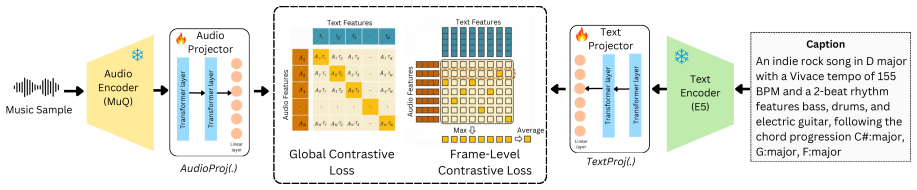
FIGMA is a multi-view contrastive architecture that jointly optimizes global audio-text alignment and frame-level, token-wise alignment. This design lets the model capture both high-level semantic context and fine-grained musical attributes such as tempo, key, chord progression, and rhythmic structure inside one representation space. The method is enabled by the new Fine-Grained Music Caption dataset of 380K training pairs and a 10K test set, both annotated with the listed musical attributes.
What carries the argument
multi-view contrastive architecture jointly optimizing global audio-text alignment together with frame-level and token-wise alignment
If this is right
- The model retrieves tracks that match specific tempo, key, chord and rhythm details supplied in natural language.
- Performance gains hold on out-of-domain music retrieval evaluations.
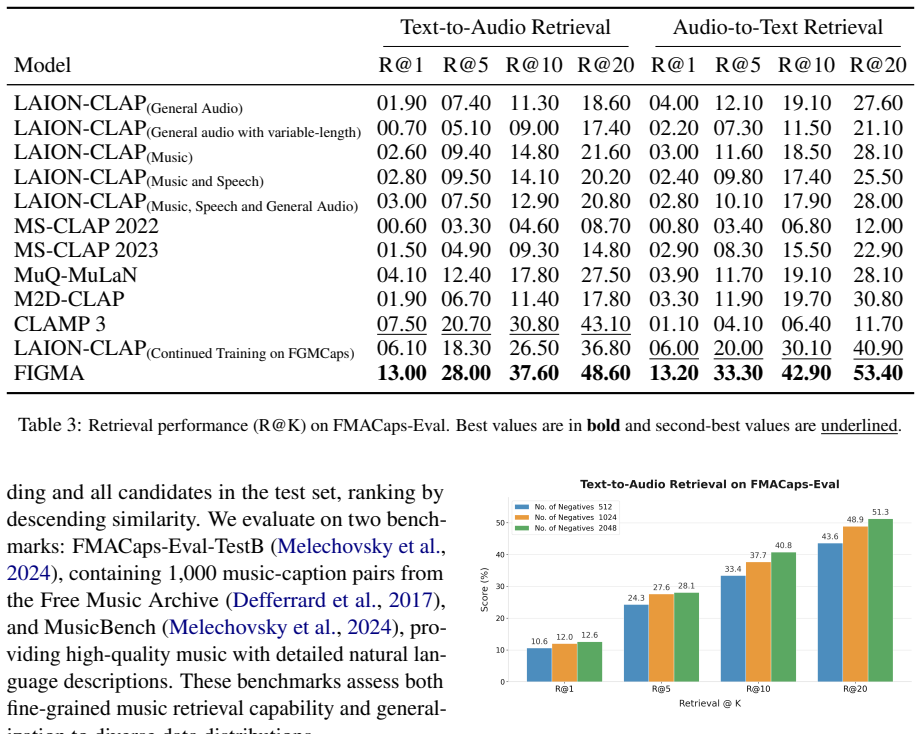
- Relative accuracy improvements reach 73.3 percent over existing CLAP-based systems on multiple benchmarks.
- The released FGMCaps dataset supplies training and test data annotated with tempo, key, chords and related attributes.
Where Pith is reading between the lines
- The same global-plus-token alignment pattern could be applied to other audio-text tasks that require fine detail, such as sound effect retrieval or speech command matching.
- The FGMCaps dataset could serve as a benchmark or pre-training resource for music generation models that must follow precise rhythmic or harmonic instructions.
- If the early-token bias is a general property of contrastive objectives on long sequences, similar multi-view designs may help in video-text or document retrieval settings.
Load-bearing premise
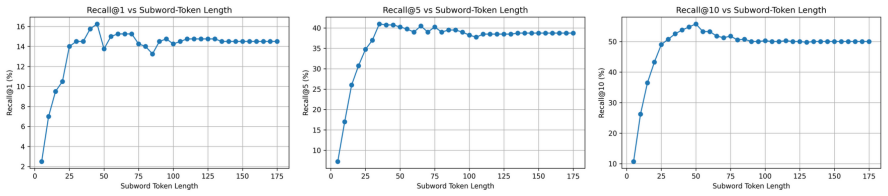
The main reason existing models fail on detailed music descriptions is that the contrastive objective itself causes them to ignore most tokens after the first few in long captions.
What would settle it
A measurement of token contribution or attention weights inside a trained CLAP model on long captions, showing whether later tokens receive negligible weight, or a controlled test where captions differ only in later tokens and retrieval accuracy is compared before and after the change.
Figures

read the original abstract
Retrieving music using natural language descriptions has improved with contrastive audio-text models such as CLAP, but current systems remain limited to coarse semantic queries. When descriptions specify fine-grained musical attributes such as tempo, key, chord progression, or rhythmic structure, existing models often fail to retrieve the correct audio. We show that this limitation stems from the contrastive learning objective itself: despite being trained on long captions, CLAP-based models effectively utilize only the first few tokens, discarding much of the information encoded in detailed prompts. Then, we propose FIGMA (FIne-Grained Music RetrievAl), a multi-view contrastive architecture that addresses this limitation by jointly optimizing global audio-text alignment and frame-level, token-wise alignment. This design enables FIGMA to capture both high-level semantic context and fine-grained musical attributes within a unified representation space. Moreover, we formalize the task of Fine-Grained Music Retrieval and construct Fine-Grained Music Caption dataset (FGMCaps), a large-scale dataset of 380K music-caption pairs for training along with a 10K test set, both annotated with tempo, key, chord progression, beat count, as well as genre and mood. Extensive experiments demonstrate that FIGMA consistently outperforms existing CLAP-based music retrieval models across multiple music retrieval benchmarks, including out-of-domain evaluations, with relative improvements of up to 73.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contrastive audio-text models like CLAP are limited to coarse music retrieval because they effectively use only the first few tokens of long captions, discarding fine-grained information on attributes such as tempo, key, and chords. It proposes FIGMA, a multi-view contrastive architecture that jointly optimizes global audio-text alignment and frame-level/token-wise alignment. The authors introduce the FGMCaps dataset (380K training pairs and 10K test pairs annotated with tempo, key, chord progression, beat count, genre, and mood) and report that FIGMA outperforms existing CLAP-based models on multiple benchmarks, including out-of-domain, with relative gains up to 73.3%.
Significance. If the gains can be isolated to the multi-view architecture rather than the new dataset, the work would advance fine-grained music retrieval by better capturing detailed musical attributes in a unified space. The FGMCaps dataset with its explicit annotations for tempo, key, chords, and other properties is a clear positive contribution that could support future research in the area.
major comments (2)
- [Abstract] Abstract: The claim of relative improvements up to 73.3% compares FIGMA (trained on the 380K FGMCaps pairs with fine-grained annotations) to 'existing CLAP-based music retrieval models' without stating whether the baselines were retrained on equivalent data or used original checkpoints. This is load-bearing for the central claim, as the skeptic correctly notes that data scale, annotation quality, or domain match could explain the gap independently of the diagnosed token-discarding mechanism or the new architecture.
- [Abstract] Abstract: The root-cause diagnosis that 'CLAP-based models effectively utilize only the first few tokens' is presented without reference to supporting analysis such as token-ablation studies, attention visualizations, or controlled experiments on identical data. This diagnosis directly motivates the multi-view design, so its verification is required to make the performance attribution load-bearing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The two major comments highlight the need for greater precision in attributing performance gains and in grounding the architectural motivation. We agree that both points require clarification and will revise the abstract (and add supporting details where needed) to address them directly. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of relative improvements up to 73.3% compares FIGMA (trained on the 380K FGMCaps pairs with fine-grained annotations) to 'existing CLAP-based music retrieval models' without stating whether the baselines were retrained on equivalent data or used original checkpoints. This is load-bearing for the central claim, as the skeptic correctly notes that data scale, annotation quality, or domain match could explain the gap independently of the diagnosed token-discarding mechanism or the new architecture.
Authors: We agree the abstract must be explicit on this point. The reported numbers compare FIGMA (trained on FGMCaps) against the original released CLAP checkpoints, which were trained on their respective pre-training corpora rather than FGMCaps. This setup reflects the practical reality that users of existing models employ the public checkpoints. To isolate the contribution of the multi-view architecture, we will add a controlled experiment in the revised manuscript that retrains a standard CLAP model on the identical FGMCaps training set and report the resulting gap. The abstract will be updated to state 'original CLAP checkpoints' and to note the controlled same-data comparison. revision: yes
-
Referee: [Abstract] Abstract: The root-cause diagnosis that 'CLAP-based models effectively utilize only the first few tokens' is presented without reference to supporting analysis such as token-ablation studies, attention visualizations, or controlled experiments on identical data. This diagnosis directly motivates the multi-view design, so its verification is required to make the performance attribution load-bearing.
Authors: The manuscript already contains the requested supporting evidence: Section 4.2 presents token-ablation experiments and attention-map analysis demonstrating that standard CLAP encoders attend predominantly to the initial tokens of long captions. We will revise the abstract to include a concise pointer to this analysis (e.g., 'as verified by token-ablation studies in Section 4.2') so that the motivation for the multi-view contrastive objective is self-contained and verifiable from the abstract itself. revision: yes
Circularity Check
No significant circularity; empirical architecture and dataset claims lack mathematical derivations or self-referential reductions.
full rationale
The paper introduces FIGMA as a multi-view contrastive model jointly optimizing global and frame-level alignments, along with the FGMCaps dataset of 380K pairs. No equations, parameter fits, or derivations are presented that could reduce a claimed result to its inputs by construction. The diagnosis of CLAP token discarding and the reported gains (up to 73.3%) are framed as empirical observations from experiments on new data, not as predictions derived from fitted quantities or self-citation chains. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear. The work is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Musiclm: Generating music from text.Preprint, arXiv:2301.11325. Dmitry Bogdanov, Nicolas Wack, Emilia Gómez Gutiér- rez, Sankalp Gulati, Perfecto Herrera Boyer, Oscar Mayor, Gerard Roma Trepat, Justin Salamon, José R. Zapata González, and Xavier Serra
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
The mtg-jamendo dataset for automatic music tagging. InProceed- ings of the Machine Learning for Music Discovery Workshop (ML4MD), co-located with the 36th Inter- national Conference on Machine Learning (ICML 2019), Long Beach, California, USA. Steven Davis and Paul Mermelstein
2019
-
[3]
Fma: A dataset for music analysis. InProceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR 2017), pages 316–323. Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Is- mail, and Huaming Wang. 2023a. Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Confer- ence on Aco...
-
[4]
InProceedings of the International Computer Music Conference, pages 464–467
Realtime chord recognition of musical sound: A system using common lisp music. InProceedings of the International Computer Music Conference, pages 464–467. Emilia Gómez. 2006.Tonal Description of Music Audio Signals. Ph.D. thesis, Universitat Pompeu Fabra. Mojtaba Heydari, Frank Cwitkowitz, and Zhiyao Duan
2006
-
[5]
Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel P
Beatnet: Crnn and particle filtering for online joint beat downbeat and meter tracking.Preprint, arXiv:2108.03576. Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel P. W. Ellis
- [6]
- [7]
-
[8]
Qwen3 technical report.Preprint, arXiv:2505.09388. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Learning Transferable Visual Models From Natural Language Supervision
Learn- ing transferable visual models from natural language supervision.Preprint, arXiv:2103.00020. Abhinaba Roy, Renhang Liu, Tongyu Lu, and Dorien Herremans
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Jamendomaxcaps: A large scale music-caption dataset with imputed metadata. Preprint, arXiv:2502.07461. Igor André Pegoraro Santana, Fabio Pinhelli, Ju- liano Donini, Leonardo Catharin, Rafael Biazus Mangolin, Yandre Maldonado e Gomes da Costa, Valéria Delisandra Feltrim, and Marcos Aurélio Domingues
-
[11]
InProceedings of the 27th In- ternational Conference on Systems, Signals and Im- age Processing (IWSSIP 2020), pages 1–6, Niterói, Brazil
Music4all: A new music database and its applications. InProceedings of the 27th In- ternational Conference on Systems, Signals and Im- age Processing (IWSSIP 2020), pages 1–6, Niterói, Brazil. Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei
2020
-
[12]
Multilingual E5 Text Embeddings: A Technical Report
Multilingual e5 text embeddings: A technical report.Preprint, arXiv:2402.05672. Shangda Wu, Dingyao Yu, Xu Tan, and Maosong Sun
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yu-Te Wu, Yin-Jyun Luo, Tsung-Ping Chen, I-Chieh Wei, Jui-Yang Hsu, Yi-Chin Chuang, and Li Su
Clamp: Contrastive language-music pre- training for cross-modal symbolic music information retrieval.Preprint, arXiv:2304.11029. Yu-Te Wu, Yin-Jyun Luo, Tsung-Ping Chen, I-Chieh Wei, Jui-Yang Hsu, Yi-Chin Chuang, and Li Su
-
[14]
Omnizart: A general toolbox for automatic music transcription.Preprint, arXiv:2106.00497. Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dubnov
-
[15]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation.Preprint, arXiv:2211.06687. Yusong Wu, Christos Tsirigotis, Ke Chen, Cheng- Zhi Anna Huang, Aaron Courville, Oriol Nieto, Prem Seetharaman, and Justin Salamon
-
[16]
MuQ: Self-supervised music representation learning with mel residual vector quantization,
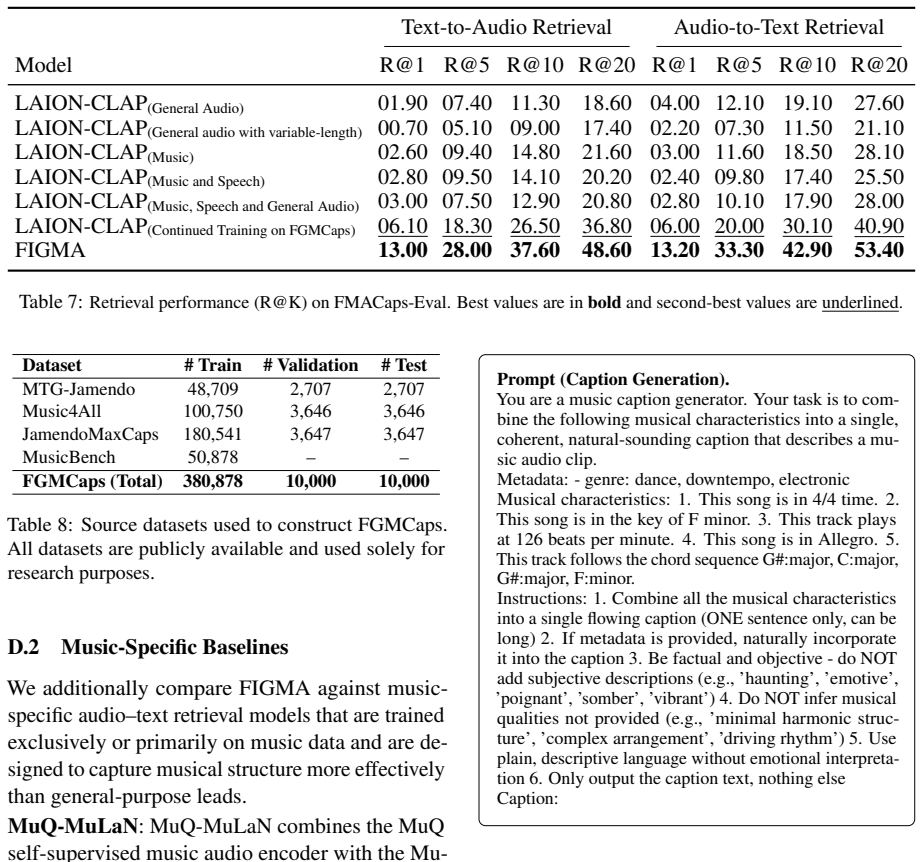
Muq: Self-supervised music represen- tation learning with mel residual vector quantization. Preprint, arXiv:2501.01108. A Additional Results A.1 Retrieval Performance on FGMCaps Test Set In addition to the MusicBench and FMACaps-Eval benchmarks reported in the main paper, we also evaluate all baselines and FIGMA on the FGM- Caps test set, consisting of 10...
-
[17]
Best values are inboldand second-best values are underlined
Text-to-Audio Retrieval Audio-to-Text Retrieval Model R@1 R@5 R@10 R@20 R@1 R@5 R@10 R@20 LAION-CLAP (General Audio) 00.09 00.40 00.68 01.30 00.24 00.92 01.55 02.95 LAION-CLAP (General audio with variable-length) 00.10 00.46 00.76 01.43 00.25 00.82 01.41 02.19 LAION-CLAP (Music) 00.18 00.62 01.17 02.18 00.29 01.43 02.47 03.94 LAION-CLAP (Music and Speech)...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.