ThinkBooster: A Unified Framework for Seamless Test-Time Scaling of LLM Reasoning
Pith reviewed 2026-06-27 21:59 UTC · model grok-4.3
The pith
ThinkBooster unifies fragmented test-time compute scaling strategies into a single modular library, benchmark, and deployment service for LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
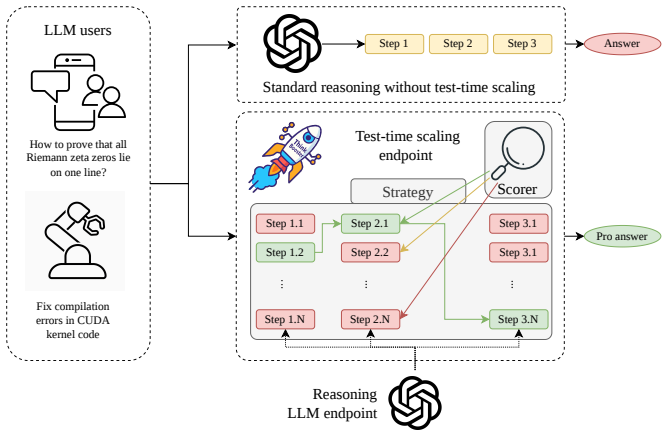
The central discovery is a framework called ThinkBooster that packages existing TTC scaling methods into reusable components, measures their efficiency alongside performance, and supplies a ready-to-use service for integration, thereby making it practical to apply and compare these scaling techniques on reasoning tasks.
What carries the argument
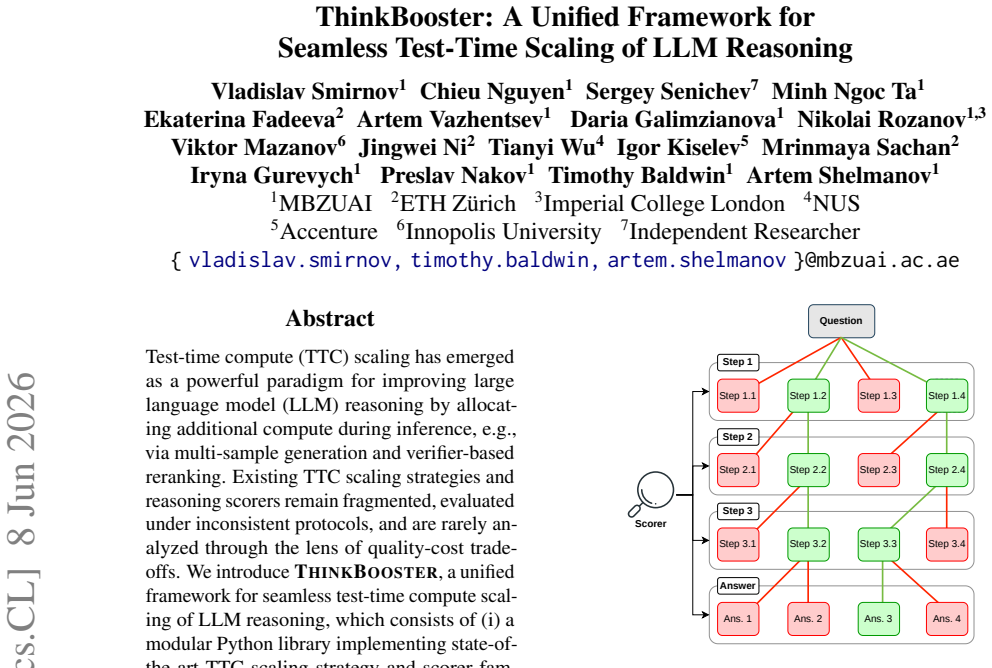
A modular Python library implementing families of test-time compute scaling strategies and reasoning scorers.
If this is right
- Consistent benchmarks become possible across different TTC methods.
- Real-world apps can add adaptive reasoning via the OpenAI-compatible proxy.
- Trade-offs between performance gains and added compute can be quantified for math and coding tasks.
- Visual inspection of reasoning paths aids in understanding selection decisions.
Where Pith is reading between the lines
- Adoption of this framework could lead to more reproducible research on inference-time scaling.
- Similar unification approaches might apply to other areas of LLM optimization like fine-tuning or retrieval.
- Practitioners could use the trade-off data to choose scaling methods that fit their resource constraints.
Load-bearing premise
That wrapping the original TTC strategies in the modular library does not change their behavior or results.
What would settle it
Running a published TTC method both natively and through ThinkBooster on identical inputs and models, then checking if accuracy and runtime match exactly.
Figures


read the original abstract
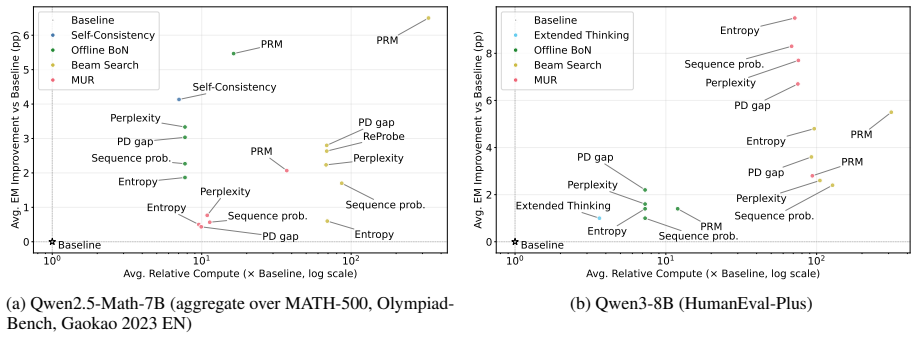
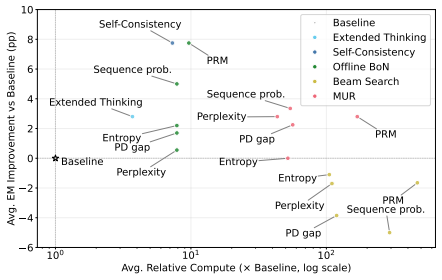
Test-time compute (TTC) scaling has emerged as a powerful paradigm for improving large language model (LLM) reasoning by allocating additional compute during inference, e.g., via multi-sample generation and verifier-based reranking. Existing TTC scaling strategies and reasoning scorers remain fragmented, evaluated under inconsistent protocols, and are rarely analyzed through the lens of quality-cost trade-offs. We introduce ThinkBooster, a unified framework for seamless test-time compute scaling of LLM reasoning, which consists of (i) a modular Python library implementing state-of-the-art TTC scaling strategy and scorer families, (ii) a benchmark that jointly evaluates performance and computational efficiency, and (iii) a deployable OpenAI-compatible proxy service that enables drop-in integration of adaptive reasoning into real-world applications. We further provide a demo visual debugger for inspecting the reasoning trajectories, intermediate selection decisions, and alternative reasoning paths. Empirical results on mathematical and coding tasks reveal the performance-compute trade-offs of TTC scaling strategies and scoring methods and demonstrate that ThinkBooster provides practical gains in real-world tasks. The code is available online under an MIT license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ThinkBooster, a unified framework for test-time compute (TTC) scaling of LLM reasoning. It consists of (i) a modular Python library implementing state-of-the-art TTC scaling strategy and scorer families, (ii) a benchmark that jointly evaluates performance and computational efficiency, and (iii) a deployable OpenAI-compatible proxy service for drop-in integration. A demo visual debugger is also provided. The authors claim that empirical results on mathematical and coding tasks reveal the performance-compute trade-offs of TTC scaling strategies and scoring methods and demonstrate practical gains in real-world tasks.
Significance. If the modular implementations are validated to match original strategy performance and the benchmark yields reproducible, comparable results under a consistent protocol, the framework could help address fragmentation in TTC research by enabling standardized comparisons of quality-cost trade-offs. The proxy service and open-source release (MIT license) would support practical deployment and community use. However, the current lack of visible quantitative support limits the assessed significance.
major comments (2)
- [Abstract] Abstract: the central claim that 'empirical results on mathematical and coding tasks reveal the performance-compute trade-offs ... and demonstrate that ThinkBooster provides practical gains' is presented without any numbers, error bars, dataset details, baselines, or tables. This assertion-without-evidence is load-bearing for the paper's contribution as a framework with demonstrated utility.
- [Library and benchmark sections] Library and benchmark description: no validation is described showing that the modular re-implementations of prior TTC strategies and scorers reproduce the performance numbers reported in the source papers on the same tasks. Divergence would mean the reported trade-off curves cannot be attributed to the strategies themselves.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming the specific mathematical and coding tasks, the number of runs, and at least one key quantitative result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the presentation of empirical support and implementation fidelity can be strengthened. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'empirical results on mathematical and coding tasks reveal the performance-compute trade-offs ... and demonstrate that ThinkBooster provides practical gains' is presented without any numbers, error bars, dataset details, baselines, or tables. This assertion-without-evidence is load-bearing for the paper's contribution as a framework with demonstrated utility.
Authors: We agree that the abstract would benefit from greater specificity. In the revision we will replace the general claim with concrete quantitative highlights drawn from the experimental sections, including accuracy deltas on GSM8K and HumanEval, efficiency metrics (tokens or wall-clock time), and explicit baseline comparisons, together with a brief reference to the datasets and number of runs. revision: yes
-
Referee: [Library and benchmark sections] Library and benchmark description: no validation is described showing that the modular re-implementations of prior TTC strategies and scorers reproduce the performance numbers reported in the source papers on the same tasks. Divergence would mean the reported trade-off curves cannot be attributed to the strategies themselves.
Authors: This concern is valid. The current manuscript does not contain a dedicated reproduction study. We will add an appendix (or short subsection) that reports side-by-side performance numbers for the re-implemented strategies and scorers against the figures published in the original papers on the same benchmarks (e.g., MATH, GSM8K, HumanEval), thereby confirming that the modular library faithfully reproduces the source results before presenting the new trade-off curves. revision: yes
Circularity Check
No circularity: software framework and benchmark release with no derivations or fitted predictions.
full rationale
The paper introduces a modular library, benchmark protocol, and proxy service for TTC scaling strategies. It reports empirical results on math/coding tasks but contains no equations, first-principles derivations, parameter fits, or predictions that could reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing for any claim. The work is self-contained as an engineering release; any validity concerns (e.g., re-implementation fidelity) fall under empirical correctness rather than circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , editor =
Ouyang, Anne and Guo, Simon and Arora, Simran and Zhang, Alex L and Hu, William and Re, Christopher and Mirhoseini, Azalia , booktitle =. 2025 , editor =
2025
-
[2]
Uncertainty-guided chain-of-thought for code generation with
Zhu, Yuqi and Li, Ge and Jiang, Xue and Li, Jia and Mei, Hong and Jin, Zhi and Dong, Yihong , journal =. Uncertainty-guided chain-of-thought for code generation with. 2025 , eprint =
2025
-
[3]
ArXiv preprint , volume =
Program synthesis with large language models , author =. ArXiv preprint , volume =. 2021 , eprint =
2021
-
[4]
ArXiv preprint , volume =
Evaluating large language models trained on code , author =. ArXiv preprint , volume =. 2021 , eprint =
2021
-
[5]
Is Your Code Generated by
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and ZHANG, LINGMING , booktitle =. Is Your Code Generated by. 2023 , address =
2023
-
[6]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =. 2022 , address =
2022
-
[7]
Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Peiyi Wang and Qihao Zhu and Runxin Xu and Ruoyu Zhang and Shirong Ma and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Chengda Lu and Chen...
2025
-
[8]
Towards end-to-end automation of
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Yamada, Yutaro and Hu, Shengran and Foerster, Jakob and Ha, David and Clune, Jeff , journal =. Towards end-to-end automation of. 2026 , doi =
2026
-
[9]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , booktitle =. Scaling. 2025 , address =
2025
-
[10]
ArXiv preprint , volume =
Training verifiers to solve math word problems , author =. ArXiv preprint , volume =. 2021 , eprint =
2021
-
[11]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , url =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Tom and Cao, Yuan and Narasimhan, Karthik , booktitle =. Tree of Thoughts: Deliberate Problem Solving with Large Language Models , url =. 2023 , address =
2023
-
[12]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. The Eleventh International Conference on Learning Representations , series =. 2023 , url =
2023
-
[13]
Large Language Models are Better Reasoners with Self-Verification
Weng, Yixuan and Zhu, Minjun and Xia, Fei and Li, Bin and He, Shizhu and Liu, Shengping and Sun, Bin and Liu, Kang and Zhao, Jun. Large Language Models are Better Reasoners with Self-Verification. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.167
-
[14]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author =. ArXiv preprint, arXiv:2207.05221 , year =. doi:10.48550/arXiv.2207.05221 , url =. 2207.05221 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.05221
-
[15]
2025 , eprint =
Yan, Hang and Xu, Fangzhi and Xu, Rongman and Li, Yifei and Zhang, Jian and Luo, Haoran and Wu, Xiaobao and Tuan, Luu Anh and Zhao, Haiteng and Lin, Qika and Liu, Jun , journal =. 2025 , eprint =
2025
-
[16]
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM -Polygraph
Vashurin, Roman and Fadeeva, Ekaterina and Vazhentsev, Artem and Rvanova, Lyudmila and Vasilev, Daniil and Tsvigun, Akim and Petrakov, Sergey and Xing, Rui and Sadallah, Abdelrahman and Grishchenkov, Kirill and Panchenko, Alexander and Baldwin, Timothy and Nakov, Preslav and Panov, Maxim and Shelmanov, Artem. Benchmarking Uncertainty Quantification Method...
-
[17]
2026 , address =
Ni, Jingwei and Fadeeva, Ekaterina and Wu, Tianyi and Akhtar, Mubashara and Zhang, Jiaheng and Ash, Elliott and Leippold, Markus and Baldwin, Timothy and Ng, See-Kiong and Shelmanov, Artem and Sachan, Mrinmaya , booktitle =. 2026 , address =
2026
-
[18]
LM -Polygraph: Uncertainty Estimation for Language Models
Fadeeva, Ekaterina and Vashurin, Roman and Tsvigun, Akim and Vazhentsev, Artem and Petrakov, Sergey and Fedyanin, Kirill and Vasilev, Daniil and Goncharova, Elizaveta and Panchenko, Alexander and Panov, Maxim and Baldwin, Timothy and Shelmanov, Artem. LM -Polygraph: Uncertainty Estimation for Language Models. Proceedings of the 2023 Conference on Empirica...
-
[19]
Entropy-based Exploration Conduction for Multi-step Reasoning
Zhang, Jinghan and Wang, Xiting and Mo, Fengran and Zhou, Yeyang and Gao, Wanfu and Liu, Kunpeng. Entropy-based Exploration Conduction for Multi-step Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.201
-
[20]
The Fourteenth International Conference on Learning Representations , year=
Deep Think with Confidence , author=. The Fourteenth International Conference on Learning Representations , year=
-
[21]
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Zhang, Zhenru and Zheng, Chujie and Wu, Yangzhen and Zhang, Beichen and Lin, Runji and Yu, Bowen and Liu, Dayiheng and Zhou, Jingren and Lin, Junyang. The Lessons of Developing Process Reward Models in Mathematical Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.547
-
[22]
ArXiv preprint , volume =
Improve Mathematical Reasoning in Language Models by Automated Process Supervision , author =. ArXiv preprint , volume =. 2024 , eprint =
2024
-
[23]
Uesato, Jonathan and Kushman, Nate and Kumar, Ramana and Song, Francis and Siegel, Noah and Wang, Lisa and Creswell, Antonia and Irving, Geoffrey and Higgins, Irina , journal =. Solving. 2022 , eprint =
2022
-
[24]
Making Language Models Better Reasoners with Step-Aware Verifier , author = "Li, Yifei and Lin, Zeqi and Zhang, Shizhuo and Fu, Qiang and Chen, Bei and Lou, Jian-Guang and Chen, Weizhu", editor = "Rogers, Anna and Boyd-Graber, Jordan and Okazaki, Naoaki", booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics"...
-
[25]
Self-Evaluation Guided Beam Search for Reasoning , url =
Xie, Yuxi and Kawaguchi, Kenji and Zhao, Yiran and Zhao, James Xu and Kan, Min-Yen and He, Junxian and Xie, Michael , booktitle =. Self-Evaluation Guided Beam Search for Reasoning , url =. 2023 , address =
2023
-
[26]
2024 , eprint =
Yang, An and Zhang, Beichen and Hui, Binyuan and Gao, Bofei and Yu, Bowen and Li, Chengpeng and Liu, Dayiheng and Tu, Jianhong and Zhou, Jingren and Lin, Junyang and Lu, Keming and Xue, Mingfeng and Lin, Runji and Liu, Tianyu and Ren, Xingzhang and Zhang, Zhenru , journal =. 2024 , eprint =
2024
-
[27]
2025 , eprint =
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
2025
-
[28]
Li, Zongqian and Shareghi, Ehsan and Collier, Nigel. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2025. doi:10.18653/v1/2025.acl-demo.14
-
[29]
Muennighoff, Niklas and Yang, Zitong and Shi, Weijia and Li, Xiang Lisa and Fei-Fei, Li and Hajishirzi, Hannaneh and Zettlemoyer, Luke and Liang, Percy and Cand \`e s, Emmanuel and Hashimoto, Tatsunori. s1: Simple test-time scaling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1025
-
[30]
Large Language Models are Zero-Shot Reasoners , url =
Kojima, Takeshi and Gu, Shixiang (Shane) and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , booktitle =. Large Language Models are Zero-Shot Reasoners , url =. 2022 , address =
2022
-
[31]
ArXiv preprint , volume =
Scaling laws for neural language models , author =. ArXiv preprint , volume =. 2020 , eprint =
2020
-
[32]
An empirical analysis of compute-optimal large language model training , url =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Thomas and Noland, Eric and Millican, Katherine and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and...
2022
-
[33]
Let s Verify Step by Step , url =
Lightman, Hunter and Kosaraju, Vineet and Burda, Yuri and Edwards, Harrison and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , booktitle =. Let s Verify Step by Step , url =. 2024 , address =
2024
-
[34]
doi: 10.18653/v1/2024.acl-long.211
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong. O lympiad B ench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. Proceedings of the ...
-
[35]
Evaluating the performance of large language models on
Zhang, Xiaotian and Li, Chunyang and Zong, Yi and Ying, Zhengyu and He, Liang and Qiu, Xipeng , journal =. Evaluating the performance of large language models on. 2023 , eprint =
2023
-
[36]
2024 , address =
Hao, Shibo and Gu, Yi and Luo, Haotian and Liu, Tianyang and Shao, Xiyan and Wang, Xinyuan and Xie, Shuhua and Ma, Haodi and Samavedhi, Adithya and Gao, Qiyue and Wang, Zhen and Hu, Zhiting , booktitle =. 2024 , address =
2024
-
[37]
Sandhini Agarwal and Lama Ahmad and Jason Ai and Sam Altman and Andy Applebaum and Edwin Arbus and Rahul K. Arora and Yu Bai and Bowen Baker and Haiming Bao and Boaz Barak and Ally Bennett and Tyler Bertao and Nivedita Brett and Eugene Brevdo and Greg Brockman and Sebastien Bubeck and Che Chang and Kai Chen and Mark Chen and Enoch Cheung and Aidan Clark a...
2025
-
[38]
2026 , howpublished =
2026
-
[39]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[40]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[41]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[42]
-Decoding: Adaptive Foresight Sampling for Balanced Inference-Time Exploration and Exploitation
Xu, Fangzhi and Yan, Hang and Ma, Chang and Zhao, Haiteng and Liu, Jun and Lin, Qika and Wu, Zhiyong. -Decoding: Adaptive Foresight Sampling for Balanced Inference-Time Exploration and Exploitation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.647
-
[43]
Asankhaya Sharma , year =
-
[44]
and Yang, Linyi and Wen, Ying and Zhang, Weinan , journal =
Wang, Jun and Fang, Meng and Wan, Ziyu and Wen, Muning and Zhu, Jiachen and Liu, Anjie and Gong, Ziqin and Song, Yan and Chen, Lei and Ni, Lionel M. and Yang, Linyi and Wen, Ying and Zhang, Weinan , journal =. 2024 , eprint =
2024
-
[45]
2024 , howpublished =
Edward Beeching and Lewis Tunstall and Sasha Rush , title =. 2024 , howpublished =
2024
-
[46]
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search , url =
Inoue, Yuichi and Misaki, Kou and Imajuku, Yuki and Kuroki, So and Nakamura, Taishi and Akiba, Takuya , booktitle =. Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search , url =. 2025 , address =
2025
-
[47]
Nature , volume=
Optimizing generative AI by backpropagating language model feedback , author=. Nature , volume=. 2025 , url=
2025
-
[48]
Training Language Models to Self-Correct via Reinforcement Learning , url =
Kumar, Aviral and Zhuang, Vincent and Agarwal, Rishabh and Su, Yi and Co-Reyes, JD and Singh, Avi and Baumli, Kate and Iqbal, Shariq and Bishop, Colton and Roelofs, Rebecca and Zhang, Lei and McKinney, Kay and Shrivastava, Disha and Paduraru, Cosmin and Tucker, George and Precup, Doina and Behbahani, Feryal and Faust, Aleksandra , booktitle =. Training La...
2025
-
[49]
Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards , url =
Liu, Xiaoyuan and Liang, Tian and He, Zhiwei and Xu, Jiahao and Wang, Wenxuan and He, Pinjia and Tu, Zhaopeng and Mi, Haitao and Yu, Dong , booktitle =. Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards , url =. 2025 , address =
2025
-
[50]
Pawan Kumar, Emilien Dupont, Francisco J
Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Balog, Matej and Kumar, M. Pawan and Dupont, Emilien and Ruiz, Francisco J. R. and Ellenberg, Jordan S. and Wang, Pengming and Fawzi, Omar and Kohli, Pushmeet and Fawzi, Alhussein , title =. Nature , year =. doi:10.1038/s41586-023-06924-6 , url =
-
[51]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , title =. Proceedings of the 37th Internatio...
2023
-
[52]
Shelmanov, Artem and Fadeeva, Ekaterina and Tsvigun, Akim and Tsvigun, Ivan and Xie, Zhuohan and Kiselev, Igor and Daheim, Nico and Zhang, Caiqi and Vazhentsev, Artem and Sachan, Mrinmaya and Nakov, Preslav and Baldwin, Timothy. A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Output...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.