Beyond Semantic Dominance: Cognitive Affective Reasoning and Empathetic Response Alignment in Audio Language Models
Pith reviewed 2026-06-27 21:14 UTC · model grok-4.3
The pith
Audio language models can generate more empathetic responses by decoupling acoustic emotion from textual semantics through psychological chain-of-thought reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
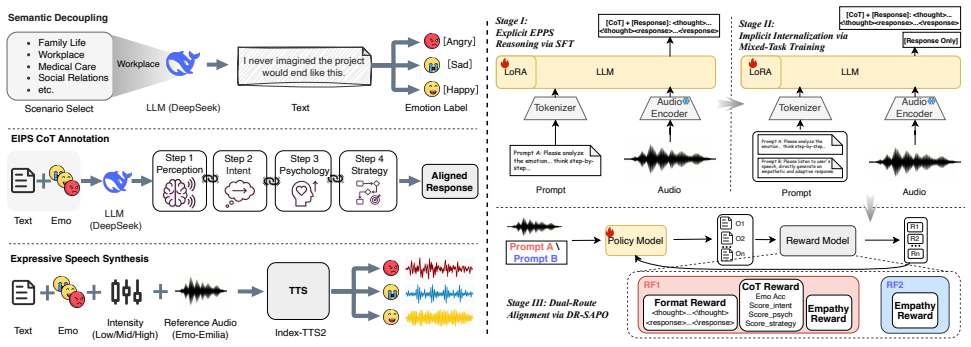
CogAudio-LLM mitigates semantic dominance in audio language models by constructing LIME-440K, a lexically-identical multi-emotion dataset that enables acoustic-semantic decoupling, introducing EIPS as a four-step chain-of-thought incorporating psychological reasoning, applying multi-stage training to establish then distill explicit reasoning into implicit generation, and designing DR-SAPO to dynamically balance the logical rigor of chain-of-thought with the empathetic quality of direct responses.
What carries the argument
EIPS, the four-step chain-of-thought mechanism that incorporates psychological reasoning steps to guide affective response generation while DR-SAPO balances it against direct empathetic output.
If this is right
- Multi-stage supervised fine-tuning followed by distillation produces efficient inference while retaining the effects of the psychological chain-of-thought.
- DR-SAPO enables dynamic trade-off between logical structure and empathetic tone during response generation.
- Training on the lexically identical dataset reduces reliance on textual semantics alone for emotion-related tasks.
- The overall pipeline yields responses that align better with acoustic emotional signals in complex affective interactions.
Where Pith is reading between the lines
- The same dataset construction and reasoning steps could be tested on other audio tasks such as intent detection where tone carries independent information.
- If the decoupling works, it suggests a general method for preventing one modality from dominating another in multimodal models.
- Real-world deployment would require checking whether the psychological steps generalize across languages or cultural expressions of emotion.
Load-bearing premise
That a dataset of lexically identical audio with varied emotions will enable models to separate acoustic features from semantic content, and that inserting psychological reasoning steps will measurably increase empathy without creating new response biases.
What would settle it
Test whether responses to identical lexical content spoken with contrasting emotions show statistically distinguishable empathy scores that track the acoustic emotion rather than defaulting to the same reply.
Figures

read the original abstract
While Audio Language Models (ALMs) demonstrate strong semantic understanding, they struggle with complex affective interactions. Specifically, textual semantic dominance often overshadows acoustic nuances, and a lack of cognitive depth leads to generic, emotion-agnostic responses. We propose CogAudio-LLM\footnote{ \urlstyle{same} https://github.com/zxzhao0/CogAudio-LLM, a novel cognitive affective reasoning framework. To mitigate semantic dominance, we build LIME-440K, a ``lexically-identical, multi-emotion'' dataset designed to facilitate acoustic-semantic decoupling. We introduce EIPS, a 4-step Chain-of-Thought (CoT) mechanism incorporating psychological reasoning. For inference efficiency, multi-stage training explicitly establishes EIPS via supervised fine-tuning, then distills this logic into an implicit generation process. Finally, we design DR-SAPO (Dual-Route Soft Adaptive Policy Optimization) to dynamically balance the logical rigor of the CoT with the empathetic quality of the direct response.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CogAudio-LLM, a cognitive affective reasoning framework for Audio Language Models to address textual semantic dominance and lack of cognitive depth in affective interactions. Key components include the LIME-440K 'lexically-identical, multi-emotion' dataset to enable acoustic-semantic decoupling, the EIPS 4-step Chain-of-Thought mechanism incorporating psychological reasoning, multi-stage supervised fine-tuning followed by distillation to an implicit process, and DR-SAPO (Dual-Route Soft Adaptive Policy Optimization) to balance CoT logical rigor with direct empathetic response quality.
Significance. If the proposed mechanisms were shown to work, the work could advance empathetic alignment in audio language models by providing concrete tools for decoupling acoustic cues from semantics and injecting structured cognitive reasoning. The LIME-440K construction and DR-SAPO dual-route policy represent potentially novel contributions to handling complex affective audio interactions, but the complete absence of any quantitative results, ablations, or human evaluations renders the significance speculative.
major comments (1)
- [Abstract] Abstract and full text: the manuscript describes the construction of LIME-440K, the EIPS steps, multi-stage SFT+distillation, and DR-SAPO but reports no quantitative results, ablation studies, metrics (e.g., acoustic-semantic correlation, empathy scores), or human evaluations demonstrating that these components achieve decoupling or measurably improve empathetic outputs. This absence is load-bearing for all central claims about improved alignment.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the central limitation in our submission. We address the major comment directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract and full text: the manuscript describes the construction of LIME-440K, the EIPS steps, multi-stage SFT+distillation, and DR-SAPO but reports no quantitative results, ablation studies, metrics (e.g., acoustic-semantic correlation, empathy scores), or human evaluations demonstrating that these components achieve decoupling or measurably improve empathetic outputs. This absence is load-bearing for all central claims about improved alignment.
Authors: We agree that the manuscript as submitted contains no quantitative results, ablation studies, or human evaluations. The current text focuses on the design of LIME-440K, the EIPS reasoning steps, the multi-stage training procedure, and the DR-SAPO objective without empirical validation of their impact on acoustic-semantic decoupling or empathetic response quality. This is a substantive limitation that prevents strong claims about improved alignment. We will revise the manuscript to incorporate the requested evaluations, including quantitative metrics for acoustic-semantic correlation, empathy scores, and ablation studies on each component. revision: yes
Circularity Check
No circularity in proposed framework construction
full rationale
The paper describes the design of LIME-440K dataset, EIPS 4-step CoT, multi-stage SFT+distillation, and DR-SAPO policy as new components to address semantic dominance and empathy. No equations, fitted parameters, or derivations are presented that reduce by construction to the same inputs (e.g., no parameter fitted on LIME-440K then renamed as a prediction of decoupling success). No self-citations appear as load-bearing for uniqueness or ansatz smuggling. The central claims remain proposals whose success is to be validated externally rather than tautological by definition.
Axiom & Free-Parameter Ledger
invented entities (3)
-
LIME-440K dataset
no independent evidence
-
EIPS 4-step CoT
no independent evidence
-
DR-SAPO optimization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction By extending Large Language Models (LLMs) into the au- dio modality, Audio Language Models (ALMs) have signifi- cantly advanced natural spoken dialogue interaction [1, 2, 3]. Specifically, to meet the strong demands for emotional compan- ionship in real-world scenarios, recent research primarily fol- lows two trajectories: general-purpose spe...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Semantic Dominance
LIME-440K Dataset To address the fundamental limitations of existing speech datasets, where textual semantics and acoustic emotions are highly coupled and explicit reasoning paths are lacking, we construct LIME-440K (Lexically-Identical,Multi-Emotion), a large-scale bilingual dataset. As shown in Table 1, this dataset comprises approximately 440,000 speec...
-
[3]
explicit guidance and im- plicit internalization
CogAudio-LLM To balance detailed affective reasoning with fluid conversational interaction, we propose a three-stage “explicit guidance and im- plicit internalization” training paradigm, as shown in Fig. 2. Furthermore, we design a Dual-Route Soft Adaptive Policy Op- timization (DR-SAPO) algorithm to align complex emotional cognition with human preference...
-
[4]
Conflict
Experiments and Results 4.1. Experimental Setup Datasets and Evaluation:We train on LIME-440K and eval- uate on two distinct benchmarks: (1) ESD-Test contains 1000 real human utterances from 2 strictly held-out speakers (5 emo- tions) to evaluate zero-shot speaker generalization; and (2) Humdial-EIBench2 [27, 28] Task4 comprises 200 bilingual ut- 2 https:...
-
[5]
semantic dominance
Conclusion We propose CogAudio-LLM, a framework designed to miti- gate the “semantic dominance” bias in ALMs and enhance cog- nitive depth during affective interactions. By leveraging the large-scale LIME-440K dataset, embedding the EIPS Chain- of-Thought, and applying the DR-SAPO algorithm, our frame- work effectively incorporates and streamlines empathe...
-
[6]
The authors are fully responsible and accountable for the final content of this paper
Generative AI Use Disclosure Generative AI models, including DeepSeek-V3/R1, Index- TTS2, and Gemini 2.5 Pro, were used for data generation, EIPS CoT annotation, and response evaluation. The authors are fully responsible and accountable for the final content of this paper. All authors agree with the submission of this paper
-
[7]
Osum-echat: Enhancing end-to-end empathetic spoken chatbot via understanding-driven spoken dialogue,
X. Geng, Q. Shao, H. Xue, S. Wang, H. Xie, Z. Guo, Y . Zhao, G. Li, W. Tian, C. Wang, Z. Zhaoet al., “Osum-echat: Enhancing end-to-end empathetic spoken chatbot via understanding-driven spoken dialogue,”arXiv preprint arXiv:2508.09600, 2025
-
[8]
E-chat: Emotion-sensitive spoken dialogue system with large language models,
H. Xue, Y . Liang, B. Mu, S. Zhang, M. Chen, Q. Chen, and L. Xie, “E-chat: Emotion-sensitive spoken dialogue system with large language models,” inProc. ISCSLP, 2024, pp. 586–590
2024
-
[9]
EMOV A: empowering language models to see, hear and speak with vivid emotions,
K. Chen, Y . Gou, R. Huang, Z. Liu, D. Tan, J. Xu, C. Wanget al., “EMOV A: empowering language models to see, hear and speak with vivid emotions,” inProc. CVPR, 2025, pp. 5455–5466
2025
-
[10]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understand- ing via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guoet al., “Qwen2- audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
SALMONN: towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: towards generic hearing abilities for large language models,” inProc. ICLR, 2024
2024
-
[13]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Songet al., “Kimi-audio technical report,”arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
EmoOmni: Bridging emotional understanding and expression in omni-modal LLMs,
W. Tian, Z. Zhao, J. Hu, H. Chen, H. Liu, B. Mu, and L. Xie, “EmoOmni: Bridging emotional understanding and expression in omni-modal LLMs,”arXiv preprint arXiv:2602.21900, 2026
-
[15]
AudioPaLM: A Large Language Model That Can Speak and Listen
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsoset al., “Audiopalm: A large language model that can speak and listen,”arXiv preprint arXiv:2306.12925, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Listen, think, and understand,
Y . Gong, H. Luo, A. H. Liu, L. Karlinsky, and J. R. Glass, “Listen, think, and understand,” inProc. ICLR, 2024
2024
-
[17]
D. Huang, Y . Lv, R. Xiong, C. Jin, and X. Peng, “When tone and words disagree: Towards robust speech emotion recognition un- der acoustic-semantic conflict,”arXiv preprint arXiv:2601.04564, 2026
-
[18]
J. Chen, Z. Guo, J. Chun, P. Wang, A. Perrault, and M. El- sner, “Do audio llms really listen, or just transcribe? measur- ing lexical vs. acoustic emotion cues reliance,”arXiv preprint arXiv:2510.10444, 2025
-
[19]
Integrating fine-grained audio-visual evidence for robust multimodal emotion reasoning,
Z. Zhao, W. Tian, X. Tian, J. Zhang, and L. Xie, “Integrating fine-grained audio-visual evidence for robust multimodal emotion reasoning,”arXiv preprint arXiv:2601.18321, 2026
-
[20]
Steering language model to stable speech emotion recog- nition via contextual perception and chain of thought,
Z. Zhao, X. Zhu, X. Wang, S. Wang, X. Geng, W. Tian, and L. Xie, “Steering language model to stable speech emotion recog- nition via contextual perception and chain of thought,”IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 415–426, 2025
2025
-
[21]
Emotionthinker: Prosody-aware reinforcement learning for explainable speech emotion reasoning,
D. Wang, S. Liu, T. Zhang, Y . Chen, J. Li, and H. Meng, “Emotionthinker: Prosody-aware reinforcement learning for explainable speech emotion reasoning,”arXiv preprint arXiv:2601.15668, 2026
-
[22]
To- wards emotionally consistent text-based speech editing: Introduc- ing emocorrector and the ECD-TSE dataset,
R. Liu, P. Gao, J. Xi, B. Sisman, C. Busso, and H. Li, “To- wards emotionally consistent text-based speech editing: Introduc- ing emocorrector and the ECD-TSE dataset,” inProc. Interspeech, 2025
2025
-
[23]
Seen and unseen emo- tional style transfer for voice conversion with A new emotional speech dataset,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Seen and unseen emo- tional style transfer for voice conversion with A new emotional speech dataset,” inProc. ICASSP, 2021, pp. 920–924
2021
-
[24]
Advancing large language models to capture varied speaking styles and respond properly in spoken conversations,
G. Lin, C. Chiang, and H. Lee, “Advancing large language models to capture varied speaking styles and respond properly in spoken conversations,” inProc. ACL, 2024, pp. 6626–6642
2024
-
[25]
DeepSeek-AI, “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capa- bility in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech,” arXiv preprint arXiv:2506.21619, 2025
-
[28]
J. Xu, Z. Guo, J. He, H. Hu, T. Heet al., “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, vol. abs/2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Soft Adaptive Policy Optimization
C. Gao, C. Zheng, X.-H. Chen, K. Dang, S. Liu, B. Yu, A. Yang, S. Bai, J. Zhou, and J. Lin, “Soft adaptive policy optimization,” arXiv preprint arXiv:2511.20347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdevaet al., “Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next genera- tion agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
S. Wang, Z. Zhao, H. Xue, C. Wang, S. Wang, H. Bu, X. Xu, and L. Xie, “Humdial-eibench: A human-recorded multi-turn emo- tional intelligence benchmark for audio language models,”arXiv preprint arXiv: 2604.11594, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
The ICASSP 2026 humdial challenge: Bench- marking human-like spoken dialogue systems in the LLM era,
Z. Zhao, S. Wang, G. Li, H. Xue, C. Wang, S. Wang, L. Xiao, Z. Zhang, H. Bu, X. Xu, X. Wang, H. Liu, E. S. Chng, H. Lee, H. Li, and L. Xie, “The ICASSP 2026 humdial challenge: Bench- marking human-like spoken dialogue systems in the LLM era,” arXiv preprint arXiv: 2601.05564, 2026
-
[35]
Freeze-omni: A smart and low latency speech-to- speech dialogue model with frozen LLM,
X. Wang, Y . Li, C. Fu, Y . Zhang, Y . Shen, L. Xie, K. Li, X. Sun, and L. Ma, “Freeze-omni: A smart and low latency speech-to- speech dialogue model with frozen LLM,” inProc. ICML, vol. 267, 2025
2025
-
[36]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “Glm-4-voice: Towards intelligent and human-like end- to-end spoken chatbot,”arXiv preprint arXiv:2412.02612, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wanget al., “Qwen3- omni technical report,”arXiv preprint arXiv:2509.17765, vol. abs/2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelmanet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.