T-GMP: Terrain-conditioned Generative Motion Priors for Versatile and Natural Humanoid Locomotion
Pith reviewed 2026-06-27 22:14 UTC · model grok-4.3
The pith
Terrain-conditioned generative motion priors enable a single policy to produce natural, adaptive humanoid locomotion across varied terrains from limited expert data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
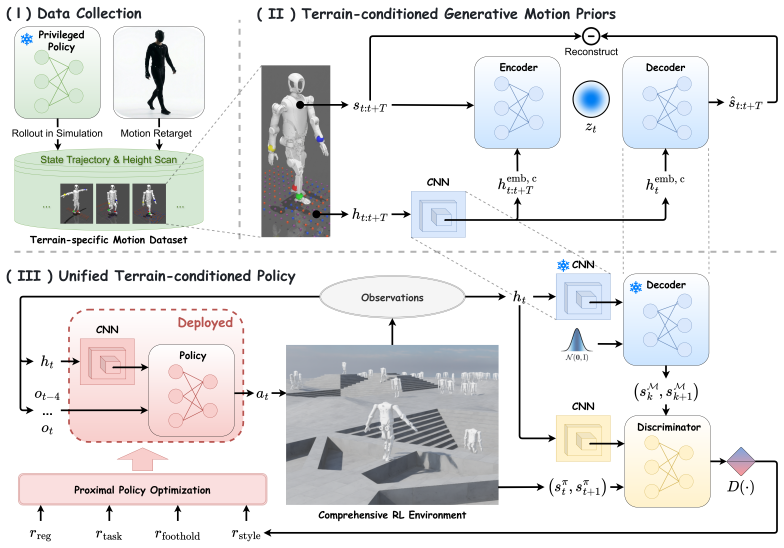
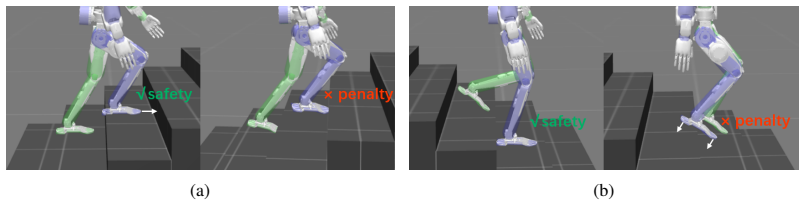
A Conditional Variational Autoencoder learns a latent motion manifold conditioned on terrain features from a small set of expert demonstrations; when this manifold is placed inside an adversarial training pipeline that includes a terrain-conditioned discriminator and a foothold penalty, the resulting policy generates versatile yet biomimetically natural and physically coordinated humanoid locomotion that adapts to terrain changes.
What carries the argument
The T-GMP module, a Conditional Variational Autoencoder that encodes a terrain-conditioned latent space of expert motions to support style transitions inside a unified policy.
If this is right
- A single policy adapts to terrain variations through smooth motion-style transitions.
- Traversal success rate and motion smoothness exceed those of prior fixed-prior baselines.
- Biomimetically natural and physically coordinated motions are maintained without separate controllers.
- The discriminator adjusts naturalness constraints dynamically according to local terrain features.
Where Pith is reading between the lines
- The same conditioning structure could reduce the number of demonstrations required when transferring locomotion skills to new robot morphologies.
- Latent-space interpolation might allow handling of terrain combinations never shown in the original expert set.
- If the learned manifold proves robust, the framework could be tested on physical hardware to check sim-to-real transfer of the terrain-conditioned priors.
- Analogous terrain or environment conditioning could be applied to other whole-body tasks such as carrying objects while walking.
Load-bearing premise
A small collection of expert state-terrain demonstrations is sufficient for the conditional variational autoencoder to produce a manifold that, together with the discriminator and foothold penalty, yields reliable natural motion on unseen terrains.
What would settle it
Deploy the trained policy on a test terrain sequence that differs in slope, step height, or roughness from all demonstration examples and measure whether traversal success drops sharply or motions lose natural coordination.
Figures




read the original abstract
Achieving both anthropomorphic naturalness and robust terrain traversal remains a fundamental challenge in humanoid locomotion. Existing Reinforcement Learning (RL) approaches typically rely on fixed motion priors, limiting their adaptability to varying environments. We propose Terrain-conditioned Generative Motion Priors (T-GMP), a module that captures a terrain-conditioned latent motion manifold from a few expert state-terrain demonstrations using a Conditional Variational Autoencoder (CVAE). The learned priors enable smooth style transitions, facilitating a unified policy that adapts to terrain variations. We integrate T-GMP into an adversarial learning pipeline with our proposed Foothold Penalty, where a discriminator dynamically modulates naturalness constraints conditioned on local terrain features, guiding the generation of versatile and human-like motions. Experimental results demonstrate that our method outperforms existing baselines in traversal success rate and motion smoothness, while preserving biomimetically natural and physically coordinated motions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Terrain-conditioned Generative Motion Priors (T-GMP), a CVAE trained on a small set of expert state-terrain demonstrations to learn a latent motion manifold. This prior is integrated into an adversarial RL pipeline that includes a terrain-conditioned discriminator and a proposed Foothold Penalty, with the goal of producing a single policy capable of smooth style transitions and versatile, natural humanoid locomotion across varying terrains. The central empirical claim is that T-GMP outperforms existing baselines in traversal success rate and motion smoothness while preserving biomimetic naturalness and physical coordination.
Significance. If the experimental claims hold with adequate controls and generalization tests, the work would offer a data-efficient route to terrain-adaptive motion priors that avoid the rigidity of fixed libraries, which is a recurring limitation in humanoid RL. The combination of CVAE-based conditioning with adversarial naturalness modulation is a plausible technical direction, but its value hinges on whether the learned manifold actually extrapolates beyond the training distribution.
major comments (3)
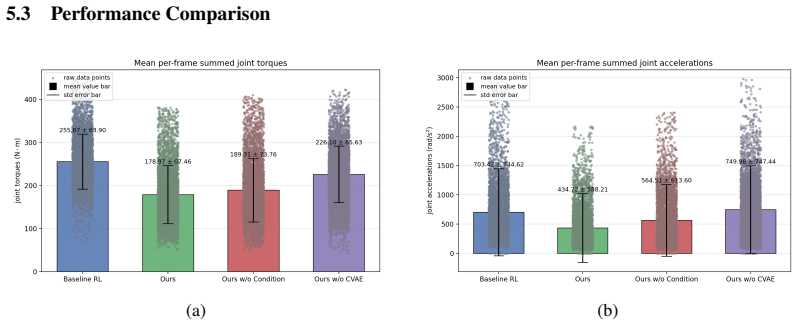
- [Abstract and §4] Abstract and §4 (Experiments): the assertion that the method 'outperforms existing baselines in traversal success rate and motion smoothness' is presented without any numerical results, baseline names, metric definitions, number of trials, error bars, or data-exclusion criteria. This absence renders the central performance claim impossible to evaluate and directly undermines the paper's primary contribution statement.
- [§3] §3 (Method): the CVAE is described as trained on 'a few' expert demonstrations to produce a terrain-conditioned manifold supporting generalization and smooth transitions, yet no details are given on the number of demonstrations, terrain feature dimensionality, latent dimension, KL weighting schedule, or any mechanism (e.g., reconstruction loss weighting or coverage regularization) to mitigate posterior collapse or limited support. Because the entire pipeline rests on this manifold's coverage of unseen terrains, the lack of these specifics is load-bearing.
- [§3.2] §3.2 (Discriminator and Foothold Penalty): the terrain-conditioned discriminator and foothold penalty are claimed to 'dynamically modulate naturalness constraints' and ensure physical coordination, but no ablation is referenced that isolates their contribution versus the CVAE prior alone, nor is there a quantitative analysis showing that these terms do not simply trade off success rate for naturalness on out-of-distribution terrain.
minor comments (2)
- [§3.1] Notation for the CVAE conditioning variables (terrain features vs. state) is introduced without an explicit table or diagram clarifying which quantities are observed at training versus test time.
- [Abstract] The abstract refers to 'biomimetically natural' motions; the manuscript should cite the specific human motion dataset or biomechanical metrics used to support this description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity, reproducibility, and empirical rigor. We address each major comment below and commit to revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the assertion that the method 'outperforms existing baselines in traversal success rate and motion smoothness' is presented without any numerical results, baseline names, metric definitions, number of trials, error bars, or data-exclusion criteria. This absence renders the central performance claim impossible to evaluate and directly undermines the paper's primary contribution statement.
Authors: We agree that the abstract offers only a qualitative summary and that §4 requires expanded quantitative reporting to substantiate the claims. In the revised manuscript we will add a results table in §4 that explicitly lists all baseline methods, defines each metric (traversal success rate and smoothness), reports mean values with standard errors over a stated number of trials (e.g., 100 rollouts per terrain), and documents any data-exclusion rules. The abstract will be updated to reference these concrete results. revision: yes
-
Referee: [§3] §3 (Method): the CVAE is described as trained on 'a few' expert demonstrations to produce a terrain-conditioned manifold supporting generalization and smooth transitions, yet no details are given on the number of demonstrations, terrain feature dimensionality, latent dimension, KL weighting schedule, or any mechanism (e.g., reconstruction loss weighting or coverage regularization) to mitigate posterior collapse or limited support. Because the entire pipeline rests on this manifold's coverage of unseen terrains, the lack of these specifics is load-bearing.
Authors: The referee is correct that these implementation details are missing. The revised §3 will specify the exact number of expert demonstrations, terrain feature dimensionality, latent dimension, KL weighting schedule, and any additional loss weighting or regularization used to avoid posterior collapse. A new appendix will tabulate all CVAE hyperparameters and training settings to allow assessment of manifold coverage. revision: yes
-
Referee: [§3.2] §3.2 (Discriminator and Foothold Penalty): the terrain-conditioned discriminator and foothold penalty are claimed to 'dynamically modulate naturalness constraints' and ensure physical coordination, but no ablation is referenced that isolates their contribution versus the CVAE prior alone, nor is there a quantitative analysis showing that these terms do not simply trade off success rate for naturalness on out-of-distribution terrain.
Authors: We acknowledge that the submitted manuscript lacks ablations isolating the discriminator and Foothold Penalty. The revised version will add an ablation subsection in §4 that compares the full model against variants without each component. Quantitative results on both in-distribution and out-of-distribution terrains will be reported for success rate and naturalness metrics to demonstrate individual contributions and confirm the absence of detrimental trade-offs. revision: yes
Circularity Check
No significant circularity; method relies on external demonstrations and standard CVAE/adversarial training
full rationale
The paper trains a CVAE on a small set of expert state-terrain demonstrations to capture a latent motion manifold, then integrates the resulting T-GMP module into an RL pipeline augmented by a terrain-conditioned discriminator and a proposed Foothold Penalty. No equations, derivations, or self-citations are shown that reduce the claimed outputs (smooth style transitions, traversal success) to the inputs by construction. The central claims rest on empirical training from external data rather than self-definition or fitted-input renaming. This is the most common honest finding for a data-driven robotics paper whose pipeline does not contain load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using mas- sively parallel deep reinforcement learning. In A. Faust, D. Hsu, and G. Neumann, ed- itors,Proceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 91–100. PMLR, 08–11 Nov 2022. URLhttps: //proceedings.mlr.press/v...
2022
-
[3]
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath. Reinforcement learn- ing for versatile, dynamic, and robust bipedal locomotion control.The International Journal of Robotics Research, 44:840 – 888, 2024. URLhttps://api.semanticscholar.org/ CorpusID:267320454
2024
-
[4]
Y . Zhou, J. Qiu, W. Zhang, and F. Ni. Humanoidmamba: Generalized mamba-based policy learning with next-action prediction for humanoid locomotion.IEEE Transactions on Cogni- tive and Developmental Systems, pages 1–13, 2026. doi:10.1109/TCDS.2026.3678742
-
[5]
D. Hoeller, N. Rudin, D. Sako, and M. Hutter. Anymal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, 9(88):eadi7566, 2024. doi:10.1126/scirobotics.adi7566. URLhttps://www.science.org/doi/abs/10.1126/scirobotics.adi7566
-
[6]
I. Radosavovic, S. Kamat, T. Darrell, and J. Malik. Learning humanoid locomotion over chal- lenging terrain.ArXiv, abs/2410.03654, 2024. URLhttps://api.semanticscholar.org/ CorpusID:273162639
arXiv 2024
-
[8]
Q. Ben, B. Xu, K. Li, F. Jia, W. Zhang, J. Wang, J. Wang, D. Lin, and J. Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains.arXiv preprint arXiv:2511.14625, 2025
arXiv 2025
-
[9]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. Deepmimic: example-guided deep reinforcement learning of physics-based character skills.ACM Transactions on Graphics, 37 (4):1–14, July 2018. ISSN 1557-7368. doi:10.1145/3197517.3201311. URLhttp://dx. doi.org/10.1145/3197517.3201311
-
[10]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion, 2025. URLhttps: //arxiv.org/abs/2508.08241
Pith/arXiv arXiv 2025
-
[11]
Allshire, H
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa. Visual imitation enables contextual humanoid control. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 794–815. PMLR, 27–30 Sep 20...
2025
-
[12]
J. Ni, Z. Wang, W. Lin, A. Bar, Y . LeCun, T. Darrell, J. Malik, and R. Herzig. From generated human videos to physically plausible robot trajectories, 2025. URLhttps://arxiv.org/ abs/2512.05094. 9
arXiv 2025
-
[13]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal locomotion over challenging terrain.Science Robotics, 5(47):eabc5986, 2020. doi: 10.1126/scirobotics.abc5986. URLhttps://www.science.org/doi/abs/10.1126/ scirobotics.abc5986
-
[14]
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid Motor Adaptation for Legged Robots. InProceedings of Robotics: Science and Systems, Virtual, July 2021. doi:10.15607/RSS.2021. XVII.011
-
[15]
J. Long, Z. Wang, Q. Li, L. Cao, J. Gao, and J. Pang. Hybrid internal model: Learning agile legged locomotion with simulated robot response. InThe Twelfth International Con- ference on Learning Representations, 2024. URLhttps://openreview.net/forum?id= 93LoCyww8o
2024
-
[16]
I. M. Aswin Nahrendra, B. Yu, and H. Myung. Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5078–5084, 2023. doi: 10.1109/ICRA48891.2023.10161144
-
[17]
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath. Real-world hu- manoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024. doi:10.1126/scirobotics.adi9579. URLhttps://www.science.org/doi/abs/10.1126/ scirobotics.adi9579
-
[18]
I. M. A. Nahrendra, B. Yu, M. Oh, D. Lee, S. Lee, H. Lee, H. Lim, and H. Myung. Dreamwaq++: Obstacle-aware quadrupedal locomotion with resilient multi-modal reinforce- ment learning.IEEE Transactions on Robotics, pages 1–17, 2026. doi:10.1109/TRO.2026. 3653774
-
[19]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 403–415. PMLR, 14–18 Dec 2023. URLhttps://proceedings.mlr.press/v205/ agarwal23a.html
2023
-
[20]
Zhuang, Z
Z. Zhuang, Z. Fu, J. Wang, C. G. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao. Robot parkour learning. In J. Tan, M. Toussaint, and K. Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 73–92. PMLR, 06–09 Nov 2023. URLhttps://proceedings.mlr.press/v229/ zhuang23a.html
2023
-
[21]
Zhuang, S
Z. Zhuang, S. Yao, and H. Zhao. Humanoid parkour learning. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 1975–1991. PMLR, 06–09 Nov 2025. URLhttps://proceedings.mlr.press/v270/zhuang25a.html
1975
-
[22]
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao. Hiking in the wild: A scalable perceptive parkour framework for humanoids, 2026. URLhttps://arxiv.org/abs/2601.07718
arXiv 2026
-
[23]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust per- ceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62), Jan. 2022. ISSN 2470-9476. doi:10.1126/scirobotics.abk2822. URLhttp://dx.doi.org/10.1126/ scirobotics.abk2822
-
[24]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 403–415. PMLR, 14–18 Dec 2023. URLhttps://proceedings.mlr.press/v205/ agarwal23a.html. 10
2023
- [25]
-
[26]
O. A. V . Maga ˜na, V . Barasuol, M. Camurri, L. Franceschi, M. Focchi, M. Pontil, D. G. Caldwell, and C. Semini. Fast and continuous foothold adaptation for dynamic locomo- tion through cnns.IEEE Robotics and Automation Letters, 4(2):2140–2147, 2019. doi: 10.1109/LRA.2019.2899434
-
[27]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9997–10003, 2025. doi:10.1109/ICRA55743.2025.11128333
-
[28]
H. Wang, Z. Wang, J. Ren, Q. Ben, T. Huang, W. Zhang, and J. Pang. BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.068
-
[29]
F. Jenelten, J. He, F. Farshidian, and M. Hutter. Dtc: Deep tracking control.Science Robotics, 9 (86):eadh5401, 2024. doi:10.1126/scirobotics.adh5401. URLhttps://www.science.org/ doi/abs/10.1126/scirobotics.adh5401
-
[30]
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter. Attention-based map encoding for learning generalized legged locomotion.Science Robotics, 10(105):eadv3604,
-
[31]
URLhttps://www.science.org/doi/abs/10
doi:10.1126/scirobotics.adv3604. URLhttps://www.science.org/doi/abs/10. 1126/scirobotics.adv3604
-
[32]
Zhang, V
C. Zhang, V . Klemm, F. Yang, and M. Hutter. Ame-2: Agile and generalized legged locomo- tion via attention-based neural map encoding, 2026. URLhttps://arxiv.org/abs/2601. 08485
2026
-
[33]
Serifi, R
A. Serifi, R. Grandia, E. Knoop, M. Gross, and M. B ¨acher. Vmp: Versatile motion priors for robustly tracking motion on physical characters.Computer Graphics Forum, 43(8):e15175,
-
[34]
URLhttps://onlinelibrary.wiley.com/ doi/abs/10.1111/cgf.15175
doi:https://doi.org/10.1111/cgf.15175. URLhttps://onlinelibrary.wiley.com/ doi/abs/10.1111/cgf.15175
-
[35]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system, 2025. URLhttps: //arxiv.org/abs/2511.02832
arXiv 2025
-
[36]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Trans. Graph., 40(4), July 2021. doi:10. 1145/3450626.3459670. URLhttp://doi.acm.org/10.1145/3450626.3459670
-
[37]
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler. Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters.ACM Trans. Graph., 41(4), July 2022
2022
-
[38]
Z. Dou, X. Chen, Q. Fan, T. Komura, and W. Wang. C·ase: Learning conditional ad- versarial skill embeddings for physics-based characters. InSIGGRAPH Asia 2023 Confer- ence Papers, SA ’23, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 9798400703157. doi:10.1145/3610548.3618205. URLhttps://doi.org/10.1145/ 3610548.3618205
-
[39]
H. Wang, W. Zhang, R. Yu, T. Huang, J. Ren, F. Jia, Z. Wang, X. Niu, X. Chen, J. Chen, Q. Chen, J. Wang, and J. Pang. Physhsi: Towards a real-world generalizable and natural humanoid-scene interaction system.ArXiv, abs/2510.11072, 2025. URLhttps://api. semanticscholar.org/CorpusID:282057062
arXiv 2025
-
[40]
J. Wang, Y . Jiang, H. Zhang, C. Tessler, D. Rempe, J. Hodgins, and X. B. Peng. Hil: Hybrid imitation learning of diverse parkour skills from videos.ArXiv, abs/2505.12619, 2025. URL https://api.semanticscholar.org/CorpusID:278741010. 11
arXiv 2025
-
[41]
Resource-efficient affordance grounding with complementary depth and semantic prompts
H. Zhang, L. Zhang, Z. Chen, L. Chen, Y . Wang, and R. Xiong. Natural humanoid robot locomotion with generative motion prior. In2025 IEEE/RSJ International Conference on In- telligent Robots and Systems (IROS), pages 6622–6629, 2025. doi:10.1109/IROS60139.2025. 11247682
-
[42]
Q. Li, C. Zhu, Y . Wu, X. Yuan, Z. Zhang, J. Yang, and Y . Liu. Run: Residual pol- icy for natural humanoid locomotion.ArXiv, abs/2509.20696, 2025. URLhttps://api. semanticscholar.org/CorpusID:281526091
arXiv 2025
-
[43]
Y . Fan, T. Gui, K. Ji, S. Ding, C. Zhang, J. Gu, J. Yu, J. Wang, and Y . Shi. One policy but many worlds: A scalable unified policy for versatile humanoid locomotion, 2025. URL https://arxiv.org/abs/2505.18780
Pith/arXiv arXiv 2025
-
[44]
Z. Zhang, K. Wen, M. Xu, J. He, C. Li, T. Miki, C. Schwarke, C. Zhang, X. B. Peng, and M. Hutter. Learning whole-body humanoid locomotion via motion generation and motion tracking, 2026. URLhttps://arxiv.org/abs/2604.17335
Pith/arXiv arXiv 2026
-
[45]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking, 2025. URLhttps://arxiv.org/abs/2510.02252
arXiv 2025
-
[46]
Higgins, L
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Ler- chner. beta-V AE: Learning basic visual concepts with a constrained variational framework. In International Conference on Learning Representations, 2017. URLhttps://openreview. net/forum?id=Sy2fzU9gl
2017
-
[47]
van der Maaten and G
L. van der Maaten and G. Hinton. Visualizing data using t-sne.Journal of Ma- chine Learning Research, 9(86):2579–2605, 2008. URLhttp://jmlr.org/papers/v9/ vandermaaten08a.html
2008
-
[48]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[49]
NVIDIA, :, M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G....
Pith/arXiv arXiv 2025
-
[50]
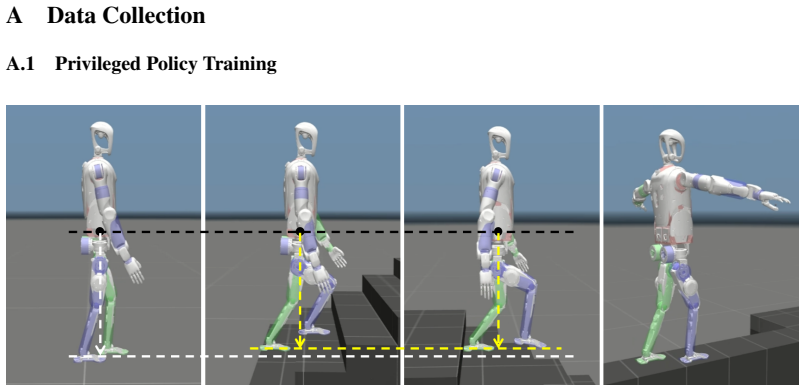
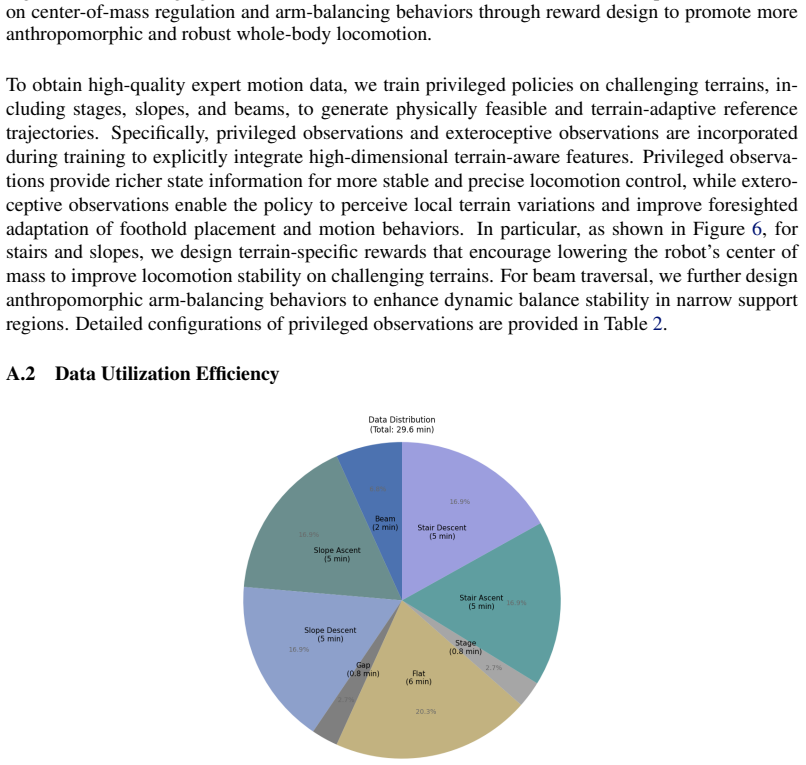
T. Miki, L. Wellhausen, R. Grandia, F. Jenelten, T. Homberger, and M. Hutter. Elevation mapping for locomotion and navigation using gpu, 2022. URLhttps://arxiv.org/abs/ 2204.12876. 12 A Data Collection A.1 Privileged Policy Training Figure 6: For challenging terrains such as stairs and beams, we introduce terrain-specific constraints on center-of-mass reg...
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.