Auditing Training Data in Domain-adapted LLMs: LoRA-MINT
Pith reviewed 2026-06-27 21:51 UTC · model grok-4.3
The pith
LoRA-MINT infers if samples were used in LoRA fine-tuning of LLMs by checking perplexity differences, reaching 0.77-0.92 precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
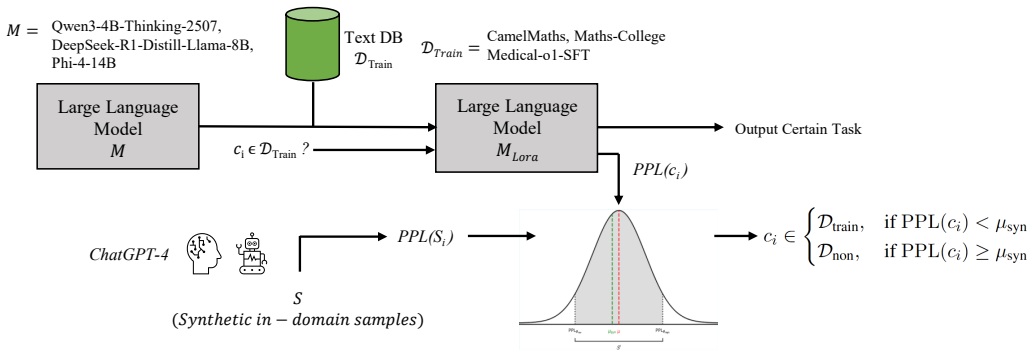
LoRA-MINT establishes that membership status in the training data of a LoRA-adapted LLM can be recovered from perplexity signals, delivering precision between 0.77 and 0.92 on standard NLP benchmarks and exceeding state-of-the-art alternatives.
What carries the argument
The perplexity-membership relationship that serves as the detection signal after LoRA adaptation.
If this is right
- Auditing tools become feasible for checking training data in LoRA-adapted LLMs.
- Data exposure estimates improve for fine-tuned models used in NLP tasks.
- Transparency around intellectual property and sensitive data in adapted models increases.
- The framework supports scalable checks across multiple models and datasets.
Where Pith is reading between the lines
- Similar perplexity signals might be tested on full fine-tuning or other adaptation techniques.
- Regulators could require disclosure of training sources if such inference methods prove reliable.
- Model providers might deliberately alter training to weaken these signals and protect data.
Load-bearing premise
Perplexity differences continue to mark membership status even after LoRA fine-tuning and are not erased by task-specific effects or dataset traits.
What would settle it
A controlled test on a LoRA-adapted model with fully known training and non-training samples that yields precision no higher than chance would show the perplexity signal does not work.
Figures


read the original abstract
We present LoRA-MINT, a new methodology for Membership Inference Test (MINT) applied to recent Large Language Models (LLMs) fine-tuned for specific Natural Language Processing (NLP) tasks through Low-Rank Adaptation (LoRA). The primary goal is to assess whether individual samples were part of the training data of these adapted models, providing a useful auditing tool for the management of intellectual property and sensitive data. Our analysis explores the relationship between model perplexity and membership status, providing a systematic framework for estimating data exposure in fine-tuned LLMs. We conducted experiments on four models and three benchmark datasets, obtaining precision values in determining if given data were used for training ranging from 0.77 to 0.92, which outperform state-of-the-art baselines and demonstrate the robustness and generality of the proposed method. In general, our findings underscore the potential of LoRA-MINT as an effective and scalable framework for auditing LLMs, improving transparency, and fostering the ethical and responsible deployment of AI and NLP technologies. For the sake of concreteness and current relevance, our discussion and experiments are centered on LoRAadjusted LLMs, but note that most of the presented methodology is easily applicable for auditing training data given any other technique for adapting LLMs or, more generally, any other domain-adapted AI models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoRA-MINT, a membership inference method for LoRA-adapted LLMs that relies on perplexity differences to determine whether individual samples were part of the fine-tuning data. It reports experiments across four models and three benchmark datasets, claiming precision values of 0.77–0.92 that outperform state-of-the-art baselines, and positions the approach as a scalable auditing tool for intellectual property and data exposure in domain-adapted models.
Significance. If the perplexity signal can be shown to isolate membership status rather than task-domain effects after LoRA adaptation, the method would offer a practical, low-overhead auditing technique for fine-tuned LLMs. The work highlights an important application area (auditing adapted models) but currently provides limited evidence that the reported performance reflects membership inference rather than domain detection.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the reported precision range (0.77–0.92) is presented without any description of how non-member samples were drawn (same task/domain vs. out-of-domain), any statistical significance tests, or exact baseline implementations. This directly affects the central claim that perplexity differences reliably indicate membership after LoRA adaptation rather than task-domain shift.
- [Abstract] Abstract: the weakest assumption—that perplexity remains a membership signal post-LoRA rather than being dominated by whether a sample belongs to the fine-tuning task distribution—is not tested or controlled for, making the outperformance claim load-bearing on an unverified premise.
minor comments (2)
- [Abstract] The abstract states results on 'four models and three benchmark datasets' but provides no table or section reference listing the specific models, datasets, or exact precision per configuration.
- [Abstract] Notation for the membership inference threshold and how it is chosen is not defined in the provided abstract, complicating reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of experimental clarity and the need to isolate membership signals from domain effects. We address each major comment below and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported precision range (0.77–0.92) is presented without any description of how non-member samples were drawn (same task/domain vs. out-of-domain), any statistical significance tests, or exact baseline implementations. This directly affects the central claim that perplexity differences reliably indicate membership after LoRA adaptation rather than task-domain shift.
Authors: We agree that these details are essential for interpreting the results and will strengthen the central claim. In the manuscript, non-member samples are drawn from the same benchmark datasets used for fine-tuning but are held out from the training split, ensuring they are from the identical task and domain distribution. We will revise the abstract to briefly note this sampling approach and expand the Experiments section to include: (1) explicit description of non-member selection, (2) statistical significance testing on the reported precision values, and (3) precise implementation details or references for the baselines. These additions will make the controls transparent and support that the signal targets membership within the domain. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that perplexity remains a membership signal post-LoRA rather than being dominated by whether a sample belongs to the fine-tuning task distribution—is not tested or controlled for, making the outperformance claim load-bearing on an unverified premise.
Authors: This concern is well-taken, as distinguishing membership from domain/task effects is fundamental. Our design samples both members and non-members from the same task-specific benchmark datasets, which provides a control for domain shift. However, we acknowledge that an explicit test of the assumption (e.g., via additional in-domain vs. out-of-domain comparisons) is not currently present. We will add a new analysis subsection that directly examines whether perplexity differences persist after controlling for domain, and we will incorporate any necessary supporting experiments or clarifications in the revision. revision: partial
Circularity Check
No significant circularity; core signal is independent perplexity
full rationale
The paper's central method applies standard perplexity (a quantity defined independently of membership labels) to detect training data exposure after LoRA adaptation. Reported precisions (0.77-0.92) are empirical results on benchmarks, not quantities forced by fitting parameters to the same data or by self-citation chains. No equations or steps reduce the claimed prediction to a tautology or to a fitted input renamed as output. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Natural Language Processing in medicine: a review,
S. Locke, A. Bashall, S. Al-Adely, J. Moore, A. Wilson, and G. B. Kitchen, “Natural Language Processing in medicine: a review,”Trends in Anaesthesia and Critical Care, vol. 38, pp. 4–9, 2021
2021
-
[2]
Benchmarking graph neural networks for document layout analysis in public affairs,
M. Lopez-Duranet al., “Benchmarking graph neural networks for document layout analysis in public affairs,” inICDAR Workshops, 2026
2026
-
[3]
NLP techniques for automating responses to customer queries: a systematic review,
P. A. Olujimi and A. Ade-Ibijola, “NLP techniques for automating responses to customer queries: a systematic review,”Discover Artificial Intelligence, vol. 3, no. 1, p. 20, 2023
2023
-
[4]
Natural Language Processing in finance: A survey,
K. Duet al., “Natural Language Processing in finance: A survey,” Information Fusion, vol. 115, p. 102755, 2025
2025
-
[5]
Addressing bias in LLMs: Strategies and application to fair AI-based recruitment,
A. Pe ˜naet al., “Addressing bias in LLMs: Strategies and application to fair AI-based recruitment,” vol. 8, no. 2, Oct. 2025, p. 1976–1987
2025
-
[6]
EduEV AL-DB: A role-based dataset for pedagogical risk evaluation in educational explanations,
J. Irigoyenet al., “EduEV AL-DB: A role-based dataset for pedagogical risk evaluation in educational explanations,” inACM/SoLAR Intl. Conf. on Learning Analytics & Knowledge Workshops (LAKw), 2026
2026
-
[7]
Ethical AI: Towards defining a collective evaluation framework,
A. K. Sharmaet al., “Ethical AI: Towards defining a collective evaluation framework,” inIEEE COMPSAC, 2025, pp. 1665–1670
2025
-
[8]
Human-centric multimodal machine learning: Recent advances and testbed on AI-based recruitment,
A. Pe ˜naet al., “Human-centric multimodal machine learning: Recent advances and testbed on AI-based recruitment,”SN Computer Science, vol. 4, no. 5, p. 434, June 2023
2023
-
[9]
Privacy-preserving comparison of variable- length data with application to biometric template protection,
M. Gomez-Barreroet al., “Privacy-preserving comparison of variable- length data with application to biometric template protection,”IEEE Access, vol. 5, pp. 8606–8619, June 2017
2017
-
[10]
Differential privacy preservation in robust con- tinual learning,
A. Hassanpouret al., “Differential privacy preservation in robust con- tinual learning,”IEEE Access, vol. 10, February 2022
2022
-
[11]
The digital double: Data privacy,
P. Omid and F. Soren, “The digital double: Data privacy,”Security, and Consent in AI Implants West J Dent Sci, vol. 2, no. 1, p. 108, 2025
2025
-
[12]
Busch, R
C. Busch, R. Veldhuiset al.,Privacy and Security Matters in Biometric Technologies. Springer, 2026
2026
-
[13]
Data-owning democracy or digital socialism?
J. Muldoon, “Data-owning democracy or digital socialism?”Critical Review Intl. Social & Political Phil., vol. 28, no. 4, pp. 570–591, 2025
2025
-
[14]
Active membership inference test (aMINT): En- hancing model auditability with multi-task learning,
D. DeAlcalaet al., “Active membership inference test (aMINT): En- hancing model auditability with multi-task learning,” inIEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2025, pp. 647–656
2025
-
[15]
(2024) Memorandum on Advancing the United States’ Leadership in Artificial Intelligence
The White House. (2024) Memorandum on Advancing the United States’ Leadership in Artificial Intelligence. [Online]. Available: https: //www.whitehouse.gov/briefing-room/presidential-actions/2024/10/24/
2024
-
[16]
A survey on privacy risks and protection in Large Language Models,
K. Chenet al., “A survey on privacy risks and protection in Large Language Models,”Journal of King Saud University Computer and Information Sciences, vol. 37, no. 7, p. 163, 2025
2025
-
[17]
A Survey of Large Language Models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Minet al., “A survey of large language models,”arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
HealAI: A healthcare LLM for effective medical documentation,
S. Goyalet al., “HealAI: A healthcare LLM for effective medical documentation,” inProc. ACM WSDM, 2024, pp. 1167–1168
2024
-
[19]
Financial analysis: Intelligent financial data analysis system based on LLM-RAG,
J. Wanget al., “Financial analysis: Intelligent financial data analysis system based on LLM-RAG,”arXiv:2504.06279, 2025
-
[20]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman et al., “GPT-4 technical report,”arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Continuous document layout analysis: Human-in-the- loop AI-based data curation, database, and evaluation in the domain of public affairs,
A. Pe ˜naet al., “Continuous document layout analysis: Human-in-the- loop AI-based data curation, database, and evaluation in the domain of public affairs,”Information Fusion, vol. 108, p. 102398, 2024
2024
-
[22]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Lianget al., “Carbon emissions and large neural network training,”arXiv:2104.10350, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
LoRA: Low-rank adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Liet al., “LoRA: Low-rank adaptation of Large Language Models.”Proc. ICLR, 2022
2022
-
[24]
QLoRA: Efficient finetuning of quantized LLMs,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,”Advances in Neural Informa- tion Processing Systems (NIPS), vol. 36, pp. 10 088–10 115, 2023
2023
-
[25]
Extracting training data from Large Language Mod- els,
N. Carliniet al., “Extracting training data from Large Language Mod- els,” inUSENIX Security Symposium, 2021, pp. 2633–2650
2021
-
[26]
PBa-LLM: Privacy-and bias-aware NLP using Named-Entity Recognition (NER),
G. Mancera, A. Moraleset al., “PBa-LLM: Privacy-and bias-aware NLP using Named-Entity Recognition (NER),” inProc. ICDAR, 2025
2025
-
[27]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” inIEEE Symposium on Security and Privacy (SP), 2017, pp. 3–18
2017
-
[28]
A comprehensive analysis of factors impacting membership inference,
D. Dealcalaet al., “A comprehensive analysis of factors impacting membership inference,” inCVPR Workshops, 2024, pp. 3585–3593
2024
-
[29]
Is my data in your AI? Membership Inference Test (MINT) applied to face biometrics,
D. DeAlcala, A. Morales, J. Fierrez, G. Mancera, R. Tolosana, and J. Ortega-Garcia, “Is my data in your AI? Membership Inference Test (MINT) applied to face biometrics,”IEEE Access, 2025
2025
-
[30]
gMINT: Gradient-based membership inference test applied to image models,
D. DeAlcalaet al., “gMINT: Gradient-based membership inference test applied to image models,” inIEEE/CVF Conf. on Computer Vision and Pattern Recognition Workshops (CVPRw), 2025, pp. 2781–2790
2025
-
[31]
Is my text in your AI model? Gradient-based membership inference test applied to LLMs,
G. Mancera, D. DeAlcala, J. Fierrez, R. Tolosana, and A. Morales, “Is my text in your AI model? Gradient-based membership inference test applied to LLMs,”IEEE Conf. on AI Workshops (CAIw), 2026
2026
-
[32]
MINT-Demo: membership inference test demonstrator,
D. DeAlcala, A. Morales, J. Fierrez, G. Mancera, R. Tolosanaet al., “MINT-Demo: membership inference test demonstrator,” inAAAI Work- shop on AI Governance: Alignment, Morality, and Law (AIGOV), 2025
2025
-
[33]
Is my Vision-Language data in your AI? Member- ship inference test (MINT) Demo 2,
D. DeAlcalaet al., “Is my Vision-Language data in your AI? Member- ship inference test (MINT) Demo 2,” inIEEE COMPSAC, 2026
2026
-
[34]
Mem- bership Inference Attacks from first principles,
N. Carlini, S. Chien, M. Nasr, S. Song, A. Terzis, and F. Tramer, “Mem- bership Inference Attacks from first principles,” inIEEE Symposium on Security and Privacy (SP), 2022, pp. 1897–1914
2022
-
[35]
A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly,
Y . Yao, J. Duan, K. Xu, Y . Cai, Z. Sun, and Y . Zhang, “A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly,”High-Confidence Computing, vol. 4, no. 2, 2024
2024
-
[36]
Do membership inference attacks work on large language models? InarXiv:2402.07841, 2024
M. Duan, A. Suri, N. Mireshghallahet al., “Do Membership Inference Attacks work on Large Language Models?”arXiv:2402.07841, 2024
-
[37]
arXiv preprint arXiv:2305.18462 , year=
J. Mattern, F. Mireshghallah, Z. Jin, B. Sch ¨olkopfet al., “Membership Inference Attacks against Language Models via neighbourhood compar- ison,”arXiv:2305.18462, 2023
-
[38]
User inference attacks on Large Language Models,
N. Kandpal, K. Pillutla, A. Oprea, P. Kairouz, C. A. Choquette-Choo, and Z. Xu, “User inference attacks on Large Language Models,”arXiv preprint arXiv:2310.09266, 2023
-
[39]
Detecting pretraining data from large language models,
W. Shi, A. Ajith, M. Xia, Y . Huang, D. Liu, T. Blevins, D. Chen, and L. Zettlemoyer, “Detecting pretraining data from large language models,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 51 826–51 843
2024
-
[40]
Min-k%++: Improved baseline for pre-training data detection from large language models,
J. Zhang, J. Sun, E. Yeats, Y . Ouyang, M. Kuo, J. Zhang, H. Yang, and H. Li, “Min-k%++: Improved baseline for pre-training data detection from large language models,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 64 845–64 862
2025
-
[41]
MoPe: Model perturbation based privacy attacks on language models,
M. Li, J. Wang, J. Wang, and S. Neel, “MoPe: Model perturbation based privacy attacks on language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 13 647–13 660
2023
-
[42]
SoK: Membership Inference Attacks on LLMs are rushing nowhere (and how to fix it),
M. Meeus, I. Shilov, S. Jain, M. Faysse, M. Rei, and Y .-A. de Montjoye, “SoK: Membership Inference Attacks on LLMs are rushing nowhere (and how to fix it),” inIEEE Conf. on Secure and Trustworthy Machine Learning (SaTML), 2025, pp. 385–401
2025
-
[43]
Quantifying privacy risks of masked Language Models using Membership Inference Attacks,
F. Mireshghallah, K. Goyal, A. Uniyal, T. Berg-Kirkpatrick, and R. Shokri, “Quantifying privacy risks of masked Language Models using Membership Inference Attacks,”arXiv preprint arXiv:2203.03929, 2022
-
[44]
Balancing tails when comparing distributions: Com- prehensive equity index (CEI) with application to bias evaluation in operational face biometrics,
I. Solanoet al., “Balancing tails when comparing distributions: Com- prehensive equity index (CEI) with application to bias evaluation in operational face biometrics,”Pattern Recognition, vol. 179, 2026
2026
-
[45]
Measuring bias in AI models: An statistical approach introducing n-sigma,
D. DeAlcalaet al., “Measuring bias in AI models: An statistical approach introducing n-sigma,” inIEEE Conf. on Computers, Software, and Applications (COMPSAC), June 2023, pp. 1167–1172
2023
-
[46]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huanget al., “Qwen3 technical report,”arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,”arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
M. Abdinet al., “Phi-4 technical report,”arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
SensitiveNets: Learning agnostic representations with application to face recognition,
A. Moraleset al., “SensitiveNets: Learning agnostic representations with application to face recognition,”IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 43, no. 6, pp. 2158–2164, June 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.