SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
Pith reviewed 2026-06-27 22:52 UTC · model grok-4.3
The pith
SlimSearcher reduces web agent tool calls by 17-58 percent while maintaining or improving accuracy on long tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
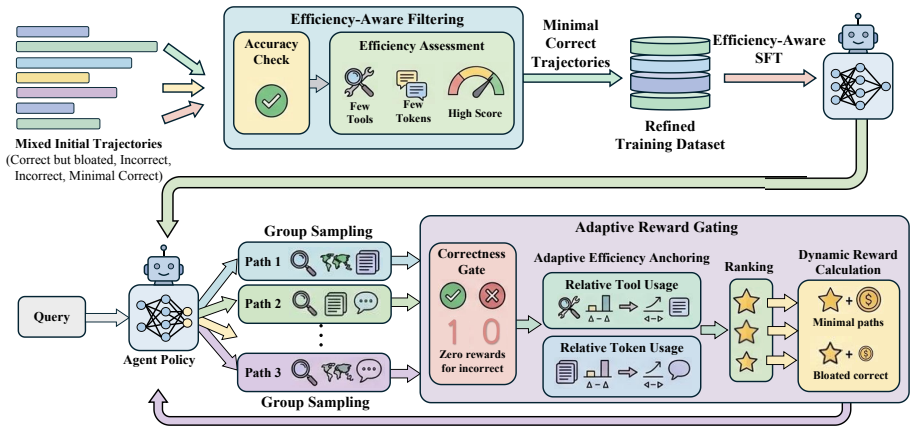
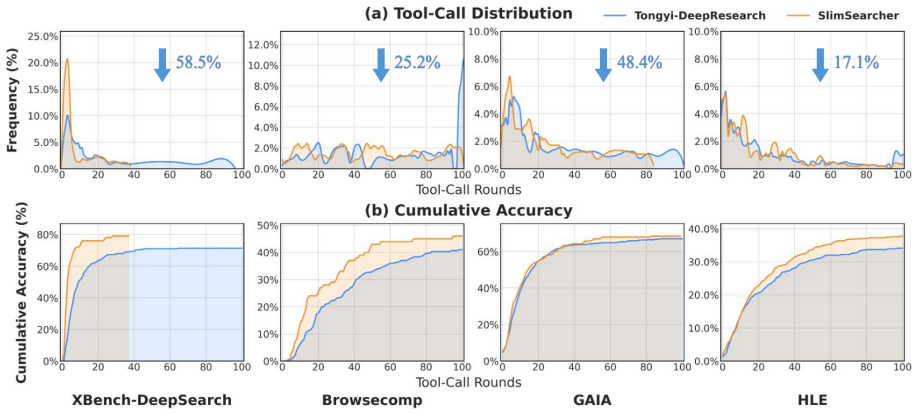
SlimSearcher pushes the Pareto frontier between accuracy and computational cost by applying Pareto-efficient filtration in the SFT stage to distill trajectories that are both successful and economical, and by introducing Adaptive Reward Gating in the RL stage, a mechanism that evaluates relative tool and token efficiency within a sampled cohort before cascading those metrics with a strict correctness gate to avoid brevity bias and reward hacking. Experiments on long-horizon benchmarks demonstrate reductions in average tool-call rounds of 17-58 percent while accuracy is maintained or improved.
What carries the argument
Adaptive Reward Gating, a dynamic reward-shaping mechanism that evaluates relative efficiency within cohorts and then applies a strict correctness gate.
If this is right
- Average tool-call rounds drop 17-58 percent on GAIA, BrowseComp, and XBenchDeepSearch.
- Accuracy stays the same or rises on those same benchmarks.
- The efficiency gains appear in both the SFT and RL stages of training.
- The gating approach limits reward hacking that absolute efficiency penalties often produce.
Where Pith is reading between the lines
- The cohort-relative comparison may transfer to other reinforcement learning settings that involve variable-length trajectories.
- Applying the same filtration-plus-gating pattern could reduce costs in agent domains outside web search, such as code or planning agents.
- If the method scales, it would make repeated long-horizon agent runs more affordable for smaller labs or repeated experimentation.
Load-bearing premise
That measuring efficiency relative to other attempts in the same cohort and then requiring full correctness will stop the model from learning overly brief or hacked behaviors.
What would settle it
Training a new set of agents with SlimSearcher and observing no reduction in tool-call rounds or a drop in accuracy on a held-out long-horizon benchmark relative to standard training.
Figures






read the original abstract
Deep research agents have demonstrated remarkable capabilities in complex information-seeking tasks, yet this power comes at a steep computational cost. Driven by accuracy-focused training paradigms, current models adopt brute-force strategies characterized by blind tool dependency and performative reasoning-generating long, redundant trajectories that are far from necessary for resolving these tasks, leading to wasteful tool calls and excessive token consumption. To overcome this efficiency trap, we propose SlimSearcher, a principled framework that pushes the Pareto frontier between accuracy and computational cost across both Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). In the SFT stage, SlimSearcher employs Pareto-efficient filtration to distill trajectories that are both successful and economical, guiding the model toward inherently efficiency-aware search behaviors. During RL, we introduce Adaptive Reward Gating, a dynamic reward-shaping mechanism that evaluates relative tool and token efficiency within a sampled cohort. By cascading these adaptive efficiency metrics with a strict correctness gate, our approach effectively avoids the brevity bias associated with absolute penalties and mitigates reward hacking. Extensive experiments on long-horizon benchmarks, including GAIA, BrowseComp, and XBenchDeepSearch, demonstrate that SlimSearcher reduces average tool-call rounds by 17%-58% while maintaining or improving accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SlimSearcher, a framework for training efficiency-aware web agents via two stages: (1) SFT with Pareto-efficient filtration to distill trajectories that are both successful and economical, and (2) RL with Adaptive Reward Gating, which evaluates relative tool/token efficiency within a sampled cohort and cascades these metrics with a strict correctness gate to avoid brevity bias and reward hacking. Experiments on long-horizon benchmarks (GAIA, BrowseComp, XBenchDeepSearch) claim 17%-58% reductions in average tool-call rounds while maintaining or improving accuracy.
Significance. If the results hold with proper validation, the work would meaningfully advance agent training by addressing the efficiency trap in accuracy-focused paradigms for deep research agents. The relative-metric approach in reward shaping offers a principled way to mitigate common RL issues like reward hacking, with potential for broader impact on practical deployment of web agents.
major comments (2)
- [Abstract] Abstract: The central empirical claim of 17%-58% tool-call reduction (with maintained accuracy) is reported without any baselines, error bars, dataset details, ablation results, or statistical tests, so the data-to-claim link cannot be evaluated.
- [RL stage] RL stage (Adaptive Reward Gating description): The claim that cascading cohort-relative efficiency metrics with a strict correctness gate avoids brevity bias and reward hacking is presented without formal analysis, proof of the property, or supporting ablations; this mechanism is load-bearing for the method's validity.
minor comments (1)
- The abstract would benefit from explicit definitions of the efficiency metrics (tool rounds, token consumption) and the exact Pareto filtration criteria used in SFT.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point-by-point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of 17%-58% tool-call reduction (with maintained accuracy) is reported without any baselines, error bars, dataset details, ablation results, or statistical tests, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract, as a high-level summary, does not embed the full experimental details. The manuscript body (Sections 4.1–4.3, Tables 1–3, and Appendix) contains the requested baselines (including comparisons to standard SFT/RL agents), error bars from multiple runs, dataset specifications for GAIA/BrowseComp/XBenchDeepSearch, ablation results, and statistical significance tests. To improve the abstract-to-evidence linkage, we will revise the abstract to explicitly reference the evaluation benchmarks and direct readers to the detailed experimental results and ablations. revision: partial
-
Referee: [RL stage] RL stage (Adaptive Reward Gating description): The claim that cascading cohort-relative efficiency metrics with a strict correctness gate avoids brevity bias and reward hacking is presented without formal analysis, proof of the property, or supporting ablations; this mechanism is load-bearing for the method's validity.
Authors: We acknowledge that the current description relies on design rationale and overall empirical gains rather than isolated formal analysis or component ablations. We will add a dedicated subsection in the RL stage (with new ablation tables) that isolates the correctness gate versus relative efficiency metrics, quantifies reductions in brevity bias and reward-hacking incidents across cohorts, and provides a step-by-step explanation of the cascading logic with supporting experimental evidence from our training runs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript proposes SlimSearcher as a training framework using Pareto-efficient filtration during SFT and Adaptive Reward Gating (relative cohort metrics cascaded with a correctness gate) during RL. No equations, derivations, or first-principles results are shown that reduce by construction to fitted inputs or self-citations. Claims rest on empirical benchmark results (GAIA, BrowseComp, XBenchDeepSearch) rather than any self-referential loop. The central efficiency gains are presented as outcomes of the described procedure, not as tautological renamings or fitted predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.04618 , year=
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models , author=. arXiv preprint arXiv:2510.04618 , year=
-
[2]
arXiv preprint , year=
DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning , author=. arXiv preprint , year=
-
[3]
arXiv preprint arXiv:2602.14234 , year=
REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents , author=. arXiv preprint arXiv:2602.14234 , year=
-
[4]
2026 , eprint=
WebClipper: Efficient Evolution of Web Agents with Graph-based Trajectory Pruning , author=. 2026 , eprint=
2026
-
[5]
Trends in cognitive sciences , volume=
Cognitive offloading , author=. Trends in cognitive sciences , volume=. 2016 , publisher=
2016
-
[6]
arXiv preprint arXiv:2503.23383 , year=
Torl: Scaling tool-integrated rl , author=. arXiv preprint arXiv:2503.23383 , year=
-
[7]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Webwalker: Benchmarking llms in web traversal , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
-
[9]
arXiv preprint arXiv:2506.10055 , year=
Taskcraft: Automated generation of agentic tasks , author=. arXiv preprint arXiv:2506.10055 , year=
-
[10]
arXiv preprint arXiv:2508.07976 , year=
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl , author=. arXiv preprint arXiv:2508.07976 , year=
-
[11]
arXiv preprint arXiv:2507.16812 , year=
Megascience: Pushing the frontiers of post-training datasets for science reasoning , author=. arXiv preprint arXiv:2507.16812 , year=
-
[12]
arXiv preprint arXiv:2505.22648 , year=
Webdancer: Towards autonomous information seeking agency , author=. arXiv preprint arXiv:2505.22648 , year=
-
[13]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[14]
2025 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
-
[16]
Deep Research System Card , author =
-
[17]
Gemini Deep Research , author=
-
[18]
Claude Research , author=
-
[19]
Perplexity Reseaarch , author=
-
[20]
2025 , eprint=
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Tongyi DeepResearch Technical Report , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
WebLeaper: Empowering Efficiency and Efficacy in WebAgent via Enabling Info-Rich Seeking , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
Step-DeepResearch Technical Report , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Can Pruning Improve Reasoning? Revisiting Long-CoT Compression with Capability in Mind for Better Reasoning , author=. 2025 , eprint=
2025
-
[25]
Advances in Neural Information Processing Systems , year=
A-mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , year=
-
[26]
2025 , eprint=
WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
TaskCraft: Automated Generation of Agentic Tasks , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
WebDancer: Towards Autonomous Information Seeking Agency , author=. 2025 , eprint=
2025
-
[29]
2025 , url =
Open Deep Research , title =. 2025 , url =
2025
-
[30]
2025 , url =
GPT Research , title =. 2025 , url =
2025
-
[31]
2025 , eprint=
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
WebThinker: Empowering Large Reasoning Models with Deep Research Capability , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[34]
and Zhang, Wen and Chen, Huajun
Wang, Junjie and Chen, Mingyang and Hu, Binbin and Yang, Dan and Liu, Ziqi and Shen, Yue and Wei, Peng and Zhang, Zhiqiang and Gu, Jinjie and Zhou, Jun and Pan, Jeff Z. and Zhang, Wen and Chen, Huajun. Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs. Findings of the Association for Computational Linguistics: EMNLP 2024...
-
[35]
Learning to Reason with
-
[36]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal=
-
[37]
Token-Budget-Aware LLM Reasoning
Han, Tingxu and Wang, Zhenting and Fang, Chunrong and Zhao, Shiyu and Ma, Shiqing and Chen, Zhenyu. Token-Budget-Aware LLM Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1274
-
[38]
2025 , eprint=
Chain of Draft: Thinking Faster by Writing Less , author=. 2025 , eprint=
2025
-
[39]
Brevity is the soul of sustainability: Characterizing LLM response lengths
Poddar, Soham and Koley, Paramita and Misra, Janardan and Ganguly, Niloy and Ghosh, Saptarshi. Brevity is the soul of sustainability: Characterizing LLM response lengths. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1125
-
[40]
C o T -Valve: Length-Compressible Chain-of-Thought Tuning
Ma, Xinyin and Wan, Guangnian and Yu, Runpeng and Fang, Gongfan and Wang, Xinchao. C o T -Valve: Length-Compressible Chain-of-Thought Tuning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.300
-
[41]
Self-Training Elicits Concise Reasoning in Large Language Models
Munkhbat, Tergel and Ho, Namgyu and Kim, Seo Hyun and Yang, Yongjin and Kim, Yujin and Yun, Se-Young. Self-Training Elicits Concise Reasoning in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1289
-
[42]
Cui, Yingqian and He, Pengfei and Zeng, Jingying and Liu, Hui and Tang, Xianfeng and Dai, Zhenwei and Han, Yan and Luo, Chen and Huang, Jing and Li, Zhen and Wang, Suhang and Xing, Yue and Tang, Jiliang and He, Qi. Stepwise Perplexity-Guided Refinement for Efficient Chain-of-Thought Reasoning in Large Language Models. Findings of the Association for Compu...
-
[43]
2025 , eprint=
O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning , author=. 2025 , eprint=
2025
-
[45]
C oncise RL : Conciseness-Guided Reinforcement Learning for Efficient Reasoning Models
Dumitru, Razvan-Gabriel and Peteleaza, Darius and Yadav, Vikas and Pan, Liangming. C oncise RL : Conciseness-Guided Reinforcement Learning for Efficient Reasoning Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.927
-
[46]
2023 , html =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , html =
2023
-
[47]
arXiv preprint arXiv:2504.12516 , year=
Browsecomp: A simple yet challenging benchmark for browsing agents , author=. arXiv preprint arXiv:2504.12516 , year=
-
[48]
arXiv preprint arXiv:2501.14249 , year=
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
-
[49]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[50]
Xbench-DeepSearch , author =
-
[51]
SerpAPI: Google Search API , author =
-
[52]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[53]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[54]
Introducing Claude 4 , author =
-
[55]
Introducing OpenAI o3 and o4-mini , author =
-
[56]
Machine learning , volume=
F*: an interpretable transformation of the F-measure , author=. Machine learning , volume=. 2021 , publisher=
2021
-
[57]
arXiv preprint arXiv:2510.18939 , year=
Lost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search , author=. arXiv preprint arXiv:2510.18939 , year=
-
[58]
arXiv preprint arXiv:2312.10003 , year=
Rest meets react: Self-improvement for multi-step reasoning llm agent , author=. arXiv preprint arXiv:2312.10003 , year=
-
[59]
arXiv preprint arXiv:2503.09516 , year=
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[60]
Self-dc: When to reason and when to act? self divide-and-conquer for compositional unknown questions , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[61]
arXiv preprint arXiv:2507.02592 , year=
Websailor: Navigating super-human reasoning for web agent , author=. arXiv preprint arXiv:2507.02592 , year=
-
[62]
Webshaper: Agentically data synthesizing via information-seeking formalization, 2025 , author=
2025
-
[63]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Cot-valve: Length-compressible chain-of-thought tuning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[64]
Chain of draft: Thinking faster by writing less, 2025 , author=. URL https://arxiv. org/abs/2502.18600 , year=
arXiv 2025
-
[65]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Token-budget-aware llm reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[66]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Self-training elicits concise reasoning in large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[67]
L1: Controlling how long a reasoning model thinks with reinforcement learning, 2025 , author=. URL https://arxiv. org/abs/2503.04697 , volume=
Pith/arXiv arXiv 2025
-
[68]
arXiv preprint arXiv:2504.21776 , year=
Webthinker: Empowering large reasoning models with deep research capability , author=. arXiv preprint arXiv:2504.21776 , year=
-
[69]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[70]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[71]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[72]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[73]
2024 , eprint=
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning , author=. 2024 , eprint=
2024
-
[74]
2025 , howpublished=
rLLM: A Framework for Post-Training Language Agents , author=. 2025 , howpublished=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.