UrduMMLU: A Massive Multitask Benchmark for Urdu Language Understanding
Pith reviewed 2026-06-27 21:53 UTC · model grok-4.3
The pith
UrduMMLU shows LLMs reach at most 90% on native Urdu questions, with sharp drops on humanities and region-specific content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
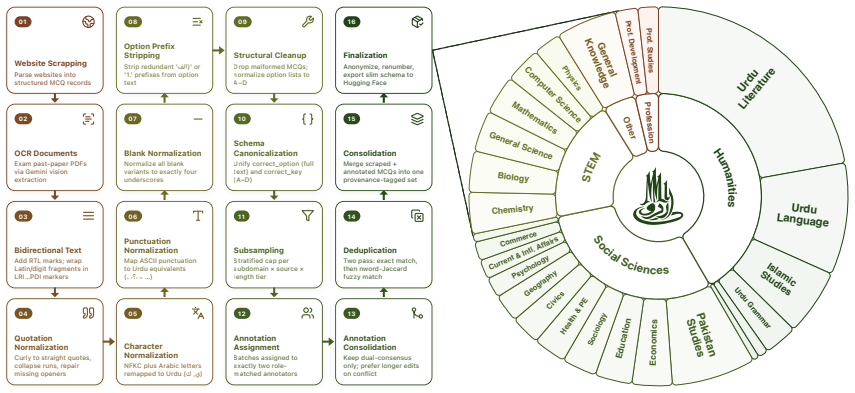
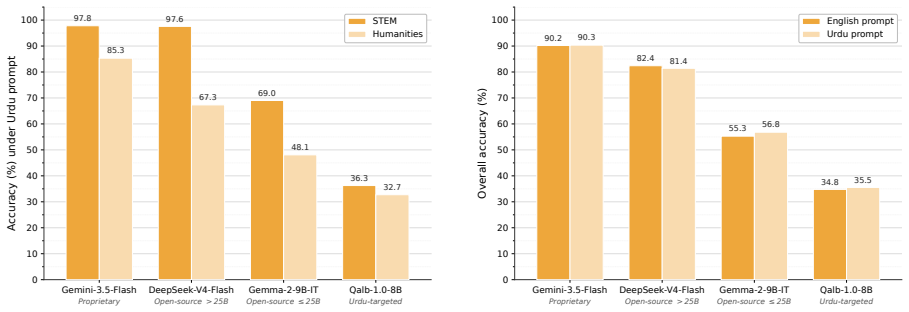
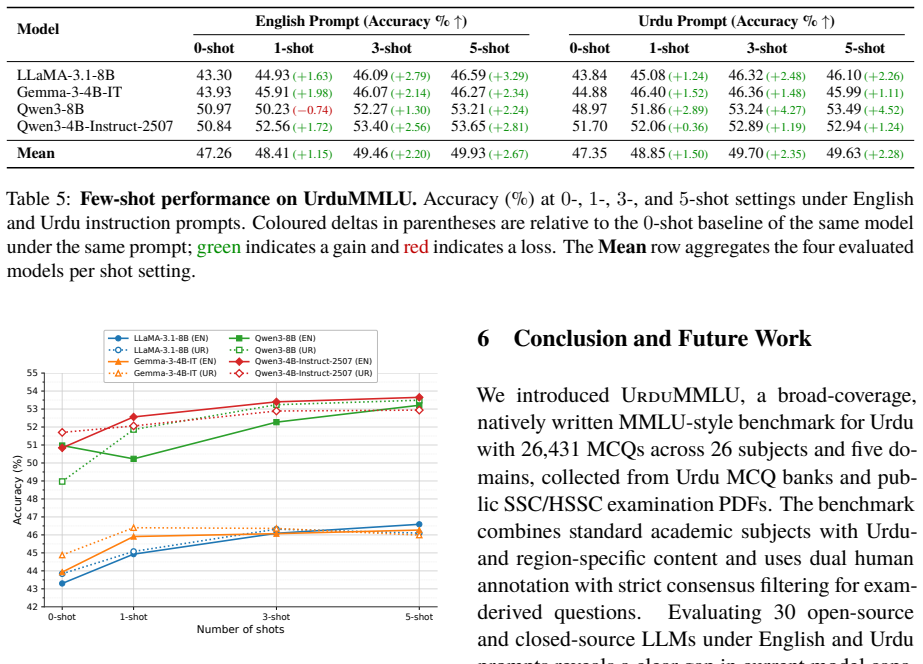
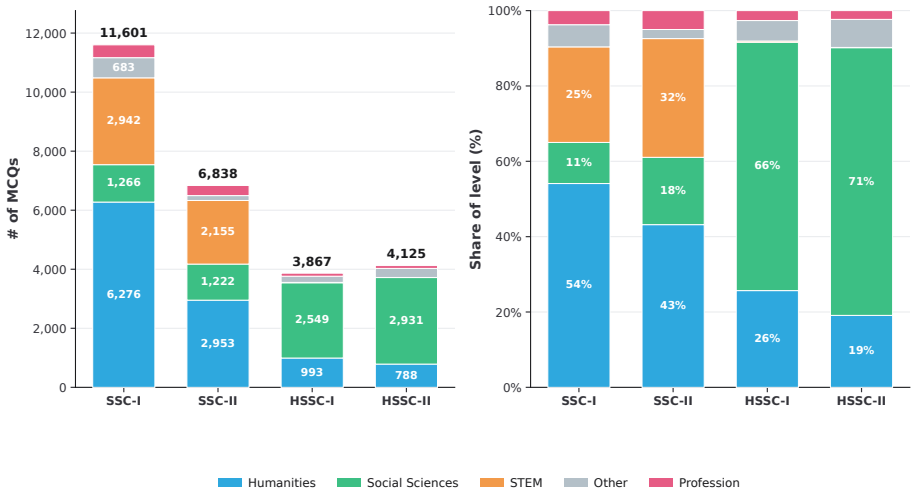
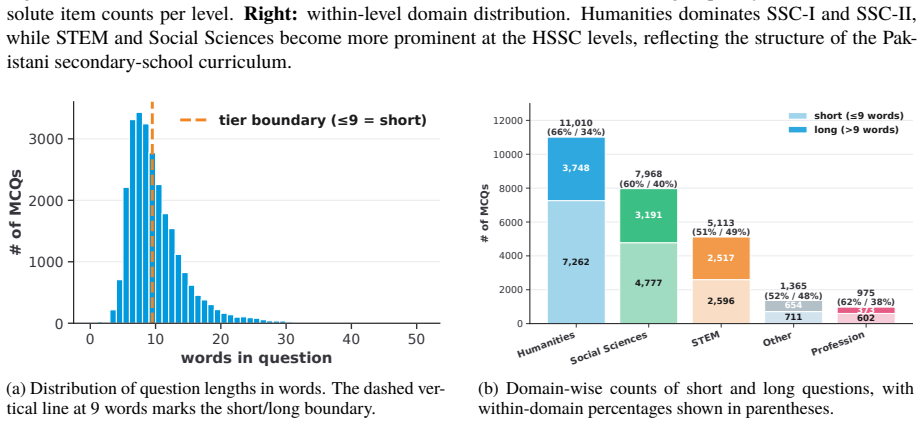
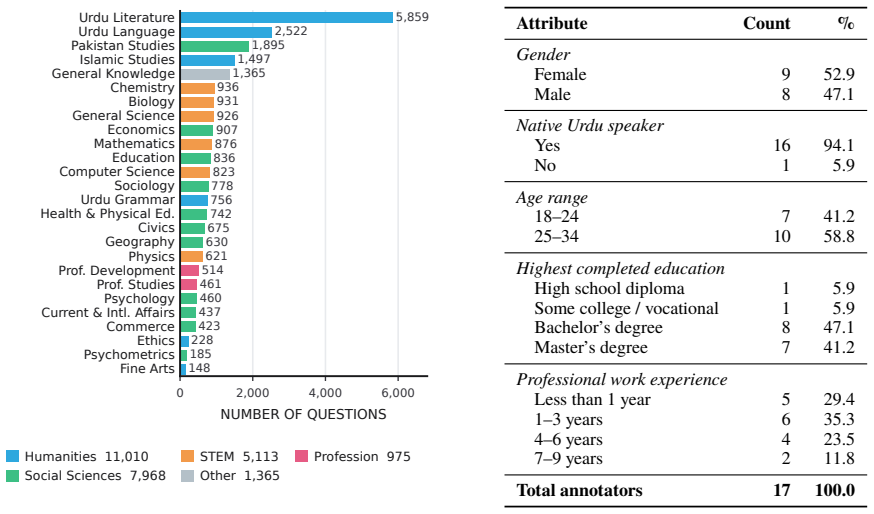
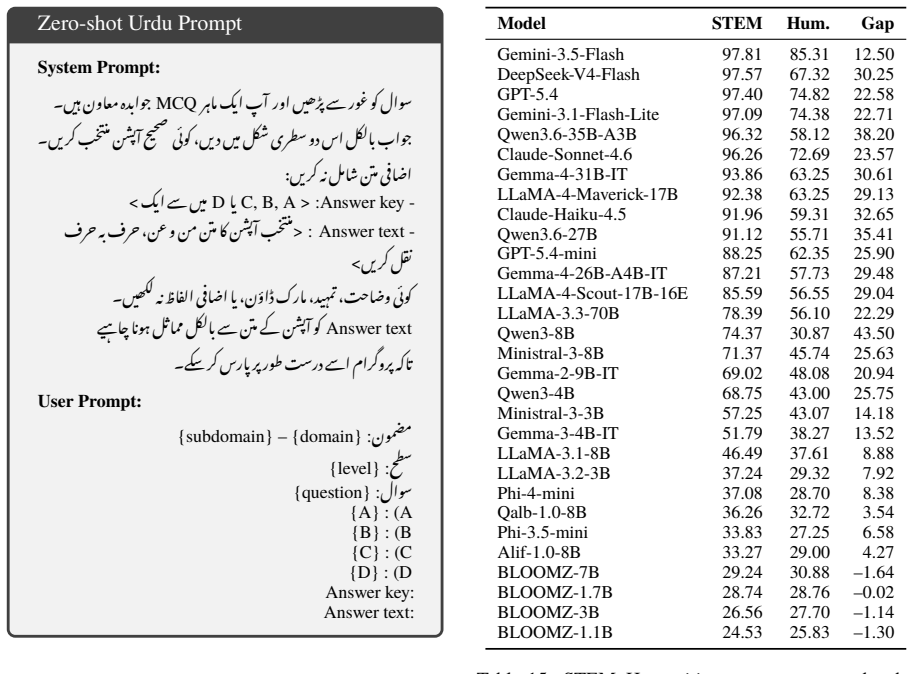
UrduMMLU supplies 26,431 Urdu MCQs spanning 26 subjects and five domains, sourced from native MCQ banks and public examination PDFs, with dual human annotation and consensus filtering applied to the exam-derived items. Zero-shot testing of 30 LLMs under English and Urdu prompts finds Gemini-3.5-Flash highest at 90.20 percent and 90.34 percent accuracy; no other model exceeds 85 percent. The strongest open-source model trails by 7.79 and 8.92 points. Many models lose 25 to 40 points on Urdu-centered humanities relative to STEM, and few-shot settings produce only small improvements.
What carries the argument
UrduMMLU, a native Urdu multitask MCQ benchmark built from local educational materials with dual human annotation and consensus filtering, used to run 60 zero-shot and additional few-shot evaluations across prompt languages.
If this is right
- Native-sourced benchmarks are required to detect performance shortfalls that translation-based tests miss.
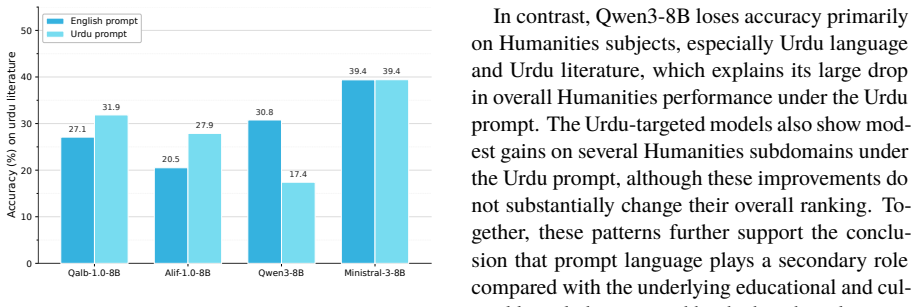
- Current LLMs need additional Urdu-region-specific training data to reduce large gaps on humanities subjects.
- Few-shot prompting alone does not close the observed deficits in Urdu understanding.
- Open-source models lag proprietary ones by roughly eight points on this benchmark.
- Urdu knowledge in LLMs remains uneven across domains, with STEM outperforming culture- and region-linked content.
Where Pith is reading between the lines
- Developers of multilingual models may benefit from systematically collecting native exam materials for other languages to surface similar hidden gaps.
- Real-world educational tools built on current LLMs could underperform for Urdu speakers on locally grounded topics.
- Performance differences between prompt languages suggest that evaluation protocols should routinely test both the target language and English.
- The modest few-shot gains imply that scaling native pretraining data may be more effective than prompting changes.
Load-bearing premise
The 26,431 questions gathered from native Urdu MCQ banks and public examination PDFs, after dual human annotation with consensus filtering, constitute a representative and reliable test of Urdu language understanding in its educational context.
What would settle it
If models achieve comparable accuracy on an English translation of the same questions as on the original Urdu version, the claim that native sources uniquely expose gaps would be weakened.
Figures




read the original abstract
Meaningful multilingual evaluation must test models in the target language and educational context. Urdu, spoken by more than 230 million people, lacks a broad MMLU-style benchmark built from native educational sources. We introduce UrduMMLU, a benchmark of 26,431 Urdu MCQs across 26 subjects and five domains, collected from native Urdu MCQ banks and public examination PDFs. Unlike translation-based resources, UrduMMLU covers both standard academic subjects and Urdu- and region-specific content. We label the exam-derived portion through dual human annotation with strict consensus filtering. We evaluate 30 LLMs under English and Urdu prompts, yielding 60 zero-shot evaluations, and further evaluate four open-source LLMs under multiple few-shot settings across both prompt languages. Gemini-3.5-Flash performs best, reaching 90.20% and 90.34% accuracy, while no other model exceeds 85%. The strongest open-source model trails by 7.79 and 8.92 points, and many models lose 25 to 40 points on Urdu-centered Humanities subjects compared with STEM. Few-shot prompting yields only modest gains. UrduMMLU shows that Urdu knowledge remains uneven in current LLMs, especially for regionally grounded content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UrduMMLU, a benchmark consisting of 26,431 Urdu-language multiple-choice questions spanning 26 subjects and five domains, sourced from native Urdu MCQ banks and public examination PDFs rather than translations. It describes a dual human annotation protocol with consensus filtering for the exam-derived portion, followed by zero-shot evaluation of 30 LLMs (and few-shot for four open-source models) under both English and Urdu prompts. The central empirical claims are that Gemini-3.5-Flash achieves the highest accuracies (90.20% and 90.34%), no other model exceeds 85%, the strongest open-source model trails by 7.79–8.92 points, and many models drop 25–40 points on Urdu-centered humanities subjects relative to STEM; few-shot prompting yields only modest gains.
Significance. If the benchmark construction and labels prove reliable, UrduMMLU would provide a valuable native-context resource for assessing LLM performance in a widely spoken but under-evaluated language, exposing gaps in region-specific and humanities knowledge that translation-based benchmarks may miss. The scale (26k questions) and coverage of both standard and Urdu-specific content strengthen its potential utility for future multilingual work.
major comments (3)
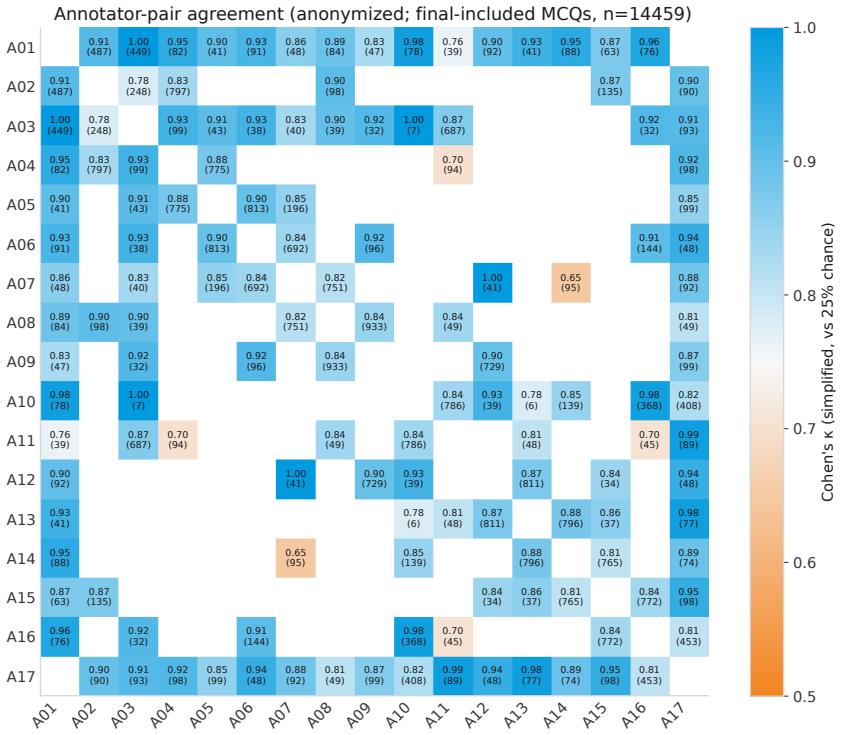
- [§3] §3 (Data Collection and Annotation): The dual-annotation protocol with consensus filtering is described, but no inter-annotator agreement statistics, disagreement rates, or resolution process details are reported. These metrics are load-bearing for the claim that the 26,431 questions constitute a reliable test set, as the performance gaps (e.g., humanities vs. STEM drops) could be inflated by label noise.
- [§5] §5 (Experiments): The zero-shot results for Gemini-3.5-Flash and the 7.79–8.92 point gap to the strongest open-source model are presented without statistical significance tests, confidence intervals, or error analysis across subjects. This weakens the central claim that Urdu knowledge remains uneven, particularly the 25–40 point humanities drops.
- [§2, §4] §2 and §4: The representativeness claim for the collected MCQs (native banks + exam PDFs) lacks discussion of coverage gaps, potential selection bias toward certain examination boards, or comparison to Urdu educational curricula; this directly affects whether the benchmark supports broad conclusions about LLM Urdu understanding.
minor comments (3)
- [Table 1] Table 1 or equivalent: Clarify the exact split between exam-derived and MCQ-bank questions, and report the number of questions per subject/domain for transparency.
- [§5.2] §5.2: The few-shot results for the four open-source models are mentioned only briefly; adding per-subject breakdowns or prompt templates would improve reproducibility.
- [References] References: Ensure all cited Urdu MCQ sources and prior multilingual benchmarks (e.g., MMLU, other language-specific variants) are fully listed with DOIs or URLs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the presentation of our benchmark's construction and evaluation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Data Collection and Annotation): The dual-annotation protocol with consensus filtering is described, but no inter-annotator agreement statistics, disagreement rates, or resolution process details are reported. These metrics are load-bearing for the claim that the 26,431 questions constitute a reliable test set, as the performance gaps (e.g., humanities vs. STEM drops) could be inflated by label noise.
Authors: We agree that inter-annotator agreement metrics are essential to substantiate label reliability. In the revised manuscript we will add the percentage of initial disagreements, the final agreement rate after consensus, and Cohen's kappa computed on the dual-annotated exam-derived subset, together with a brief description of the resolution procedure (third annotator review for persistent disagreements). These additions directly address the concern that label noise could exaggerate domain gaps. revision: yes
-
Referee: [§5] §5 (Experiments): The zero-shot results for Gemini-3.5-Flash and the 7.79–8.92 point gap to the strongest open-source model are presented without statistical significance tests, confidence intervals, or error analysis across subjects. This weakens the central claim that Urdu knowledge remains uneven, particularly the 25–40 point humanities drops.
Authors: We accept that statistical support is needed. The revision will include bootstrap-derived 95% confidence intervals for all reported accuracies, McNemar's tests for pairwise model comparisons, and an expanded per-subject error analysis that quantifies variance and highlights the humanities–STEM disparity with subject-level breakdowns. These additions will make the uneven-knowledge claim more robust. revision: yes
-
Referee: [§2, §4] §2 and §4: The representativeness claim for the collected MCQs (native banks + exam PDFs) lacks discussion of coverage gaps, potential selection bias toward certain examination boards, or comparison to Urdu educational curricula; this directly affects whether the benchmark supports broad conclusions about LLM Urdu understanding.
Authors: We will expand the relevant paragraphs in §2 and §4 to list the examination boards whose PDFs were used, note the proportion of questions drawn from each source, discuss alignment with the Pakistani national curriculum and Indian state-board syllabi where data permit, and explicitly acknowledge coverage limitations arising from the public availability of PDFs. The revised text will qualify the generalizability claim while retaining the argument that native sourcing captures regionally specific content missed by translations. revision: yes
Circularity Check
No significant circularity: empirical benchmark paper with direct measurements only
full rationale
This is a standard benchmark construction and model evaluation paper. The 26,431 questions are collected from native sources, labeled via dual human annotation with consensus filtering, and used for direct zero-shot and few-shot accuracy measurements on 30+ LLMs. No derivations, equations, fitted parameters, predictions, or self-citation chains appear in the abstract or described pipeline; all reported numbers (e.g., Gemini-3.5-Flash at 90.20%/90.34%) are raw empirical results on the collected data. The derivation chain is empty by construction, so no circular steps exist.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multiple-choice questions drawn from educational materials are a valid proxy for language understanding and subject knowledge.
- domain assumption Dual human annotation with strict consensus filtering produces reliable ground-truth labels.
Reference graph
Works this paper leans on
-
[1]
Shafique, Muhammad and Mehboob, Areej and Fiaz, Layba and Qadeer, Muhammad and Farooq, Hamza , year =
-
[2]
Kazi, Samreen and Khoja, Shakeel , title =. ACM Trans. Asian Low-Resour. Lang. Inf. Process. , month = feb, articleno =. 2026 , issue_date =. doi:10.1145/3759455 , abstract =
-
[3]
Crossing Language Boundaries: Evaluation of Large Language Models on U rdu- E nglish Question Answering
Kazi, Samreen and Rahim, Maria and Khoja, Shakeel Ahmed. Crossing Language Boundaries: Evaluation of Large Language Models on U rdu- E nglish Question Answering. Proceedings of the First Workshop on Natural Language Processing for Indo-Aryan and Dravidian Languages. 2025
2025
-
[4]
Adeeba, Farah and Dillon, Brian and Sajjad, Hassan and Bhatt, Rajesh , year =
-
[5]
Benchmarking the Performance of Pre-trained LLM s across U rdu NLP Tasks
Tahir, Munief Hassan and Shams, Sana and Fiaz, Layba and Adeeba, Farah and Hussain, Sarmad. Benchmarking the Performance of Pre-trained LLM s across U rdu NLP Tasks. Proceedings of the First Workshop on Challenges in Processing South Asian Languages (CHiPSAL 2025). 2025
2025
-
[6]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[7]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , title =. Proceedings of the 38th International Conference on Neural Information Proc...
2024
-
[8]
MMLU - CF : A Contamination-free Multi-task Language Understanding Benchmark
Zhao, Qihao and Huang, Yangyu and Lv, Tengchao and Cui, Lei and Sun, Qinzheng and Mao, Shaoguang and Zhang, Xin and Xin, Ying and Yin, Qiufeng and Li, Scarlett and Wei, Furu. MMLU - CF : A Contamination-free Multi-task Language Understanding Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long ...
-
[9]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[10]
Sankalp KJ and Ashutosh Kumar and Laxmaan Balaji and Nikunj Kotecha and Vinija Jain and Aman Chadha and Sreyoshi Bhaduri , year =. 2501.15747 , archivePrefix =
-
[11]
MMLU - P ro X : A Multilingual Benchmark for Advanced Large Language Model Evaluation
Xuan, Weihao and Yang, Rui and Qi, Heli and Zeng, Qingcheng and Xiao, Yunze and Feng, Aosong and Liu, Dairui and Xing, Yun and Wang, Junjue and Gao, Fan and Lu, Jinghui and Jiang, Yuang and Li, Huitao and Li, Xin and Yu, Kunyu and Dong, Ruihai and Gu, Shangding and Li, Yuekang and Xie, Xiaofei and Juefei-Xu, Felix and Khomh, Foutse and Yoshie, Osamu and C...
-
[12]
Angelika Romanou and Negar Foroutan and Anna Sotnikova and Sree Harsha Nelaturu and Shivalika Singh and Rishabh Maheshwary and Micol Altomare and Zeming Chen and Mohamed A. Haggag and Snegha A and Alfonso Amayuelas and Azril Hafizi Amirudin and Danylo Boiko and Michael Chang and Jenny Chim and Gal Cohen and Aditya Kumar Dalmia and Abraham Diress and Shara...
-
[13]
Hardalov, Momchil and Mihaylov, Todor and Zlatkova, Dimitrina and Dinkov, Yoan and Koychev, Ivan and Nakov, Preslav. EXAMS : A Multi-subject High School Examinations Dataset for Cross-lingual and Multilingual Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp...
-
[14]
MILU : A Multi-task I ndic Language Understanding Benchmark
Verma, Sshubam and Khan, Mohammed Safi Ur Rahman and Kumar, Vishwajeet and Murthy, Rudra and Sen, Jaydeep. MILU : A Multi-task I ndic Language Understanding Benchmark. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10...
-
[15]
A rabic MMLU : Assessing Massive Multitask Language Understanding in A rabic
Koto, Fajri and Li, Haonan and Shatnawi, Sara and Doughman, Jad and Sadallah, Abdelrahman and Alraeesi, Aisha and Almubarak, Khalid and Alyafeai, Zaid and Sengupta, Neha and Shehata, Shady and Habash, Nizar and Nakov, Preslav and Baldwin, Timothy. A rabic MMLU : Assessing Massive Multitask Language Understanding in A rabic. Findings of the Association for...
-
[16]
CMMLU : Measuring massive multitask language understanding in C hinese
Li, Haonan and Zhang, Yixuan and Koto, Fajri and Yang, Yifei and Zhao, Hai and Gong, Yeyun and Duan, Nan and Baldwin, Timothy. CMMLU : Measuring massive multitask language understanding in C hinese. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.671
-
[17]
Koto, Fajri and Aisyah, Nurul and Li, Haonan and Baldwin, Timothy. Large Language Models Only Pass Primary School Exams in I ndonesia: A Comprehensive Test on I ndo MMLU. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.760
-
[18]
KMMLU : Measuring Massive Multitask Language Understanding in K orean
Son, Guijin and Lee, Hanwool and Kim, Sungdong and Kim, Seungone and Muennighoff, Niklas and Choi, Taekyoon and Park, Cheonbok and Yoo, Kang Min and Biderman, Stella. KMMLU : Measuring Massive Multitask Language Understanding in K orean. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguist...
-
[19]
K az MMLU : Evaluating Language Models on K azakh, R ussian, and Regional Knowledge of K azakhstan
Togmanov, Mukhammed and Mukhituly, Nurdaulet and Turmakhan, Diana and Mansurov, Jonibek and Goloburda, Maiya and Sakip, Akhmed and Xie, Zhuohan and Wang, Yuxia and Syzdykov, Bekassyl and Laiyk, Nurkhan and Aji, Alham Fikri and Kochmar, Ekaterina and Nakov, Preslav and Koto, Fajri. K az MMLU : Evaluating Language Models on K azakh, R ussian, and Regional K...
-
[20]
Alif: Advancing U rdu Large Language Models via Multilingual Synthetic Data Distillation
Shafique, Muhammad Ali and Mehreen, Kanwal and Arham, Muhammad and Amjad, Maaz and Butt, Sabur and Farooq, Hamza. Alif: Advancing U rdu Large Language Models via Multilingual Synthetic Data Distillation. Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025). 2025. doi:10.18653/v1/2025.mrl-main.19
-
[21]
2026 , eprint=
Ministral 3 , author=. 2026 , eprint=
2026
-
[22]
Qalb: Largest State-of-the-Art
Muhammad Taimoor Hassan and Jawad Ahmed and Muhammad Awais , year=. Qalb: Largest State-of-the-Art. 2601.08141 , archivePrefix=
-
[23]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
-
[24]
Crosslingual Generalization through Multitask Finetuning
Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Le Scao, Teven and Bari, M Saiful and Shen, Sheng and Yong, Zheng Xin and Schoelkopf, Hailey and Tang, Xiangru and Radev, Dragomir and Aji, Alham Fikri and Almubarak, Khalid and Albanie, Samuel and Alyafeai, Zaid and Webson, Albert and Raff, Edward and Ra...
-
[25]
arXiv preprint arXiv:2503.19786 , year =
Gemma 3 Technical Report , author =. arXiv preprint arXiv:2503.19786 , year =
-
[26]
arXiv preprint arXiv:2403.08295 , year =
Gemma: Open Models Based on Gemini Research and Technology , author =. arXiv preprint arXiv:2403.08295 , year =
-
[27]
2026 , month =
Anthropic , title =. 2026 , month =
2026
-
[28]
2026 , howpublished =
Gemma 4 Model Card , author =. 2026 , howpublished =
2026
-
[29]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao ...
-
[30]
2024 , howpublished =
2024
-
[31]
2025 , howpublished =
2025
-
[32]
Marah Abdin and Jyoti Aneja and Hany Awadalla and Ahmed Awadallah and Ammar Ahmad Awan and Nguyen Bach and Amit Bahree and Arash Bakhtiari and Jianmin Bao and Harkirat Behl and Alon Benhaim and Misha Bilenko and Johan Bjorck and Sébastien Bubeck and Martin Cai and Qin Cai and Vishrav Chaudhary and Dong Chen and Dongdong Chen and Weizhu Chen and Yen-Chun C...
-
[33]
Microsoft and : and Abdelrahman Abouelenin and Atabak Ashfaq and Adam Atkinson and Hany Awadalla and Nguyen Bach and Jianmin Bao and Alon Benhaim and Martin Cai and Vishrav Chaudhary and Congcong Chen and Dong Chen and Dongdong Chen and Junkun Chen and Weizhu Chen and Yen-Chun Chen and Yi-ling Chen and Qi Dai and Xiyang Dai and Ruchao Fan and Mei Gao and ...
-
[34]
2026 , howpublished =
2026
-
[35]
2026 , howpublished =
Introducing. 2026 , howpublished =
2026
-
[36]
Gemma Team and Morgane Riviere and Shreya Pathak and Pier Giuseppe Sessa and Cassidy Hardin and Surya Bhupatiraju and Léonard Hussenot and Thomas Mesnard and Bobak Shahriari and Alexandre Ramé and Johan Ferret and Peter Liu and Pouya Tafti and Abe Friesen and Michelle Casbon and Sabela Ramos and Ravin Kumar and Charline Le Lan and Sammy Jerome and Anton T...
-
[37]
The Eleventh International Conference on Learning Representations , year=
Language models are multilingual chain-of-thought reasoners , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
C ommonsense QA : A question answering challenge targeting commonsense knowledge
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/...
-
[39]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1260
-
[41]
2021 , eprint =
Kazi, Samreen and Khoja, Shakeel , journal =. 2021 , eprint =
2021
-
[42]
Know What You Don ' t Know: Unanswerable Questions for SQ u AD
Rajpurkar, Pranav and Jia, Robin and Liang, Percy. Know What You Don ' t Know: Unanswerable Questions for SQ u AD. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2124
-
[43]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[44]
Aaditya Singh and Adam Fry and Adam Perelman and Adam Tart and Adi Ganesh and Ahmed El-Kishky and Aidan McLaughlin and Aiden Low and AJ Ostrow and Akhila Ananthram and Akshay Nathan and Alan Luo and Alec Helyar and Aleksander Madry and Aleksandr Efremov and Aleksandra Spyra and Alex Baker-Whitcomb and Alex Beutel and Alex Karpenko and Alex Makelov and Ale...
-
[45]
Ahmad, Sarfraz and Iqbal, Hasan and Ahsan, Momina and Naeem, Numaan and Khan, Muhammad Ahsan Riaz and Riaz, Arham and Manzoor, Muhammad Arslan and Wang, Yuxia and Nakov, Preslav. U rdu F act C heck: An Agentic Fact-Checking Framework for U rdu with Evidence Boosting and Benchmarking. Findings of the Association for Computational Linguistics: EMNLP 2025. 2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.